
論文まとめ:Replacing Labeled Real-Image Datasets With Auto-Generated Contours


- 論文:Replacing Labeled Real-Image Datasets With Auto-Generated Contours
- 著者:Hirokatsu Kataoka, Ryo Hayamizu, Ryosuke Yamada, Kodai Nakashima, Sora Takashima, Xinyu Zhang, Edgar Josafat Martinez-Noriega, Nakamasa Inoue, Rio Yokota
- カンファ:CVPR2022
- 論文URL:https://openaccess.thecvf.com/content/CVPR2022/html/Kataoka_Replacing_Labeled_Real-Image_Datasets_With_Auto-Generated_Contours_CVPR_2022_paper.html
- プロジェクトURL:https://hirokatsukataoka16.github.io/Replacing-Labeled-Real-Image-Datasets/
目次
ざっくり言うと
- 数式からフラクタル画像や輪郭画像のデータセットを作り、ViTの事前学習に使う、数式駆動教師あり学習(FDSL)の研究
- FDSLでは輪郭が重要で、フラクタル画像を学習させていくとViTのSelf Attentionが輪郭に着目することを発見
- フラクタル・輪郭画像のいずれの事前学習においても、ImageNet21kの教師あり学習を上回る分類精度を叩き出した。同一データ数の自己教師あり学習のほぼ上位互換。
- 数式なので、商用利用や著作権、プライバシーやラベリングコスト、実画像に潜在する社会的偏見によるデータセットの公開停止など様々な問題を回避可能
略語の説明
- SL:教師あり学習
- SSL:自己教師あり学習
- FDSL:数式駆動の教師あり学習(フラクタルDBなどがこれ)
- FractalDB:先行研究(片岡ら)の2次元のフラクタル画像のデータベース
- ExFractalDB:本研究で導入された、フラクタルを3次元に拡張し、2次元の投射画像を求めたもの
- RCDB:数式で生成した、輪郭に特化したデータセット
モチベーション
- 自己教師あり学習(SSL)が台頭しているが、数億画像のデータセットが必要でなんとかしたい
- FT-300M/3BやInstagram-3.5Bは公開されておらず、研究のアクセス性や再現性から問題がある
- DINOやMoCoV3など学習方法を工夫させれば、比較的小さなデータセットでも学習可能
- その一方で実画像を使用した場合はプライバシー、社会的偏見など様々な問題がある
- ImageNet (humanrelated labels)や80M Tiny Imagesは倫理的な問題があり、公開が停止された
- 自己教師あり学習はラベリングコストをなくせるが、倫理的な問題は残る
- ViTの事前学習の簡易化と、実画像の問題点の両面から、数式駆動の教師あり学習(FDSL)が注目されている
- ViTの事前学習に適した合成画像データセットを構成するための知見を提供したい
FDSLではどのように学習するか?
- 自然画像は使用しない。ランダムに決められた数式から、画像を大量に生成し、その画像でモデルを訓練する(教師あり学習)
- フラクタルや輪郭画像などを作るのに、データ作成時のハイパーパラメーターが存在する
- ハイパーパラメーターのレンジから、ランダムで1個の組み合わせを選択し、それを1つのクラスとして扱う
- 1つのクラス(ハイパラの組み合わせ)から1000枚程度画像を作成し、教師あり学習の要領で学習する
本論文で検証した仮説
「数式から合成画像を生成する際に最も影響力のある要因はなにか?」が主題
(1) FDSLデータセットではオブジェクトの輪郭が重要である
- 物体の輪郭を描画することに特化したデータセット(RCDB)を作成した
- このデータセットで訓練すると、FractalDBと同等の性能だった
(2) FDSLの事前学習では、ハイパラの組み合わせを大量にサンプリングし、クラス数を大量に作ってあげると、事前学習の難易度が向上し、Fine-tuning(ダウンストリームタスク)の性能が向上する
- 数学的に生成された画像の複雑度が高いほど、FDSLの精度が向上する
- 画像の複雑さは、数式駆動型画像生成のパラメータを調整することで高められる
- RCDBなら頂点数、輪郭の滑らかさ、ポリゴン数、半径
- FractalDBなら3次元のフラクタルを作り、ランダムな視点から2次元に投影した画像を作る
- ExFractalDBとRCDBにおいて画像を生成するために使用する方程式のパラメータ数を増やし、データセットのサイズを大きくして事前学習
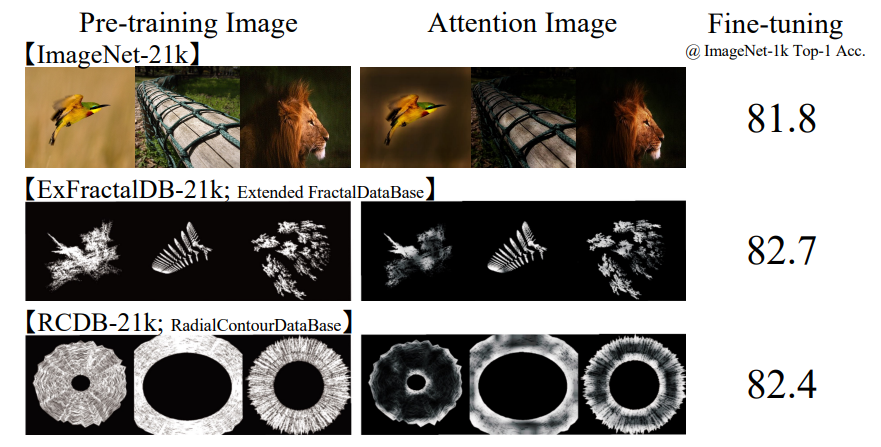
FractalDB-1kによる予備調査
- ベースラインとして、1,000クラスとクラスあたり1,000インスタンスを持つFractal-DB1k。ネットワークは16×16パッチのViT-Tiny

- FractalDB-1kを用いたViTの学習におけるAttention Mapが上図。フラクタル外側の輪郭に注意が向けられている
- フラクタルが自然界に見られる繰り返しパターンを生成できるため、実写の代替画像として利用できると考えていたが、今回の予備実験では、十分に複雑な物体の輪郭を生成することで、同様の効果が得られることが示唆された。
Radial Contour Database (RCDB)
フラクタルではなく、輪郭線からなる数式画像。以下のプロセスで作る
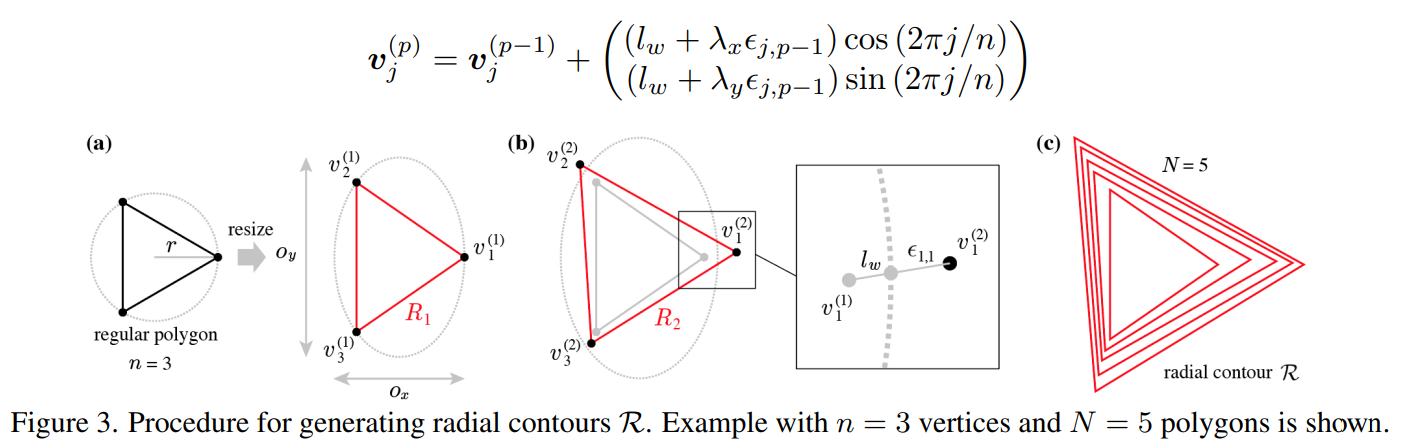
ハイパーパラメーターは、$\eta=(N, n, r, l_w, \mathbb{o}, \mathbb{\lambda})$。ハイパーパラメーターごとに1つのクラスとして、$\eta_y(y\in{1,2,\cdots,C})$個一様乱数から選択。
1クラスあたり1k枚。Cの数を変えれば2万クラス、5万クラスへスケールアップ可能。
Extended FractalDB (ExFractalDB)
先行研究のFractalDBは二次元のフラクタルだったが、ExFractalDBは、3次元のフラクタルを二次元に投射したもの。
ExFractalDBも、RCDB(輪郭線)の場合と同様にクラス数のスケールアップが可能。クラス数 Cを(おそらくハイパラを変えて)10k, 21k, 50kとスケールアップする。ExFractalDBも各クラス1000枚の画像を作るが、25個のインスタンスに対して、40個のランダムな視点からの投射画像を作る。
ExFractalDBの場合は、2Dのフラクタルではなく、一旦3Dの世界で考えることを念頭において読む必要がある。
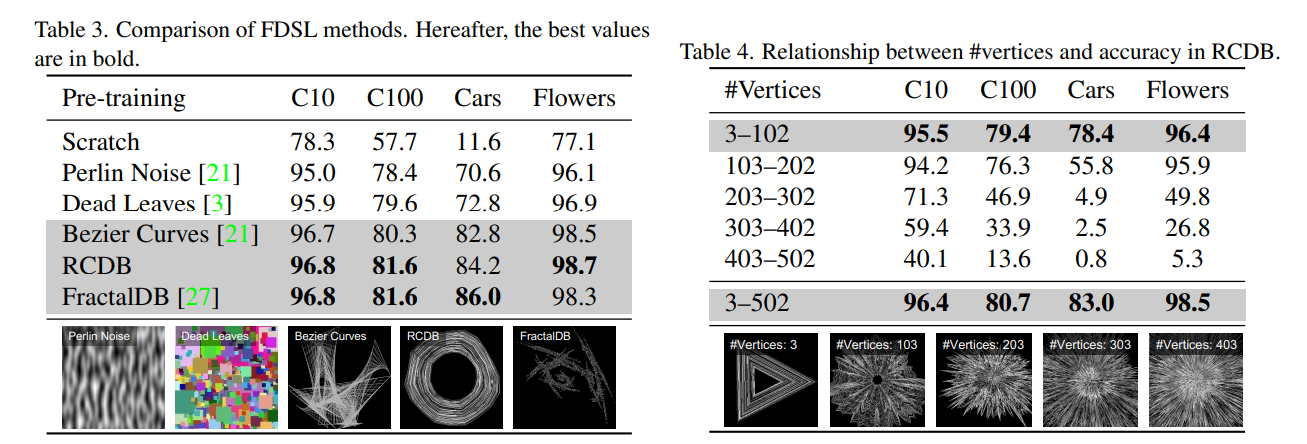
仮説1:FDSLにおいて重要なのはオブジェクトの輪郭
- FDSLデータセットによるViTの事前学習では、ViTのSelf Attentionが輪郭に集中する
- 大事なのは輪郭である
- 輪郭のデータセット(RCDB)はフラクタルの場合とほぼ同精度
- RCDBは2Dの画像で、3Dからの投射を考える必要がない
- その他の数式駆動のデータセットと比較しても、輪郭を学習したほうが精度が良い
仮説1:RCDBにおけるオブジェクトの輪郭の複雑さ
- 頂点の数を変えることで輪郭の複雑さをコントロールできる
- 上が100クラスの比較、下が500クラスの比較
- 複雑な輪郭(Cが大きいもの)だけ使うと精度が悪化する
仮説2:FDSLのデータセットをスケールアップすると精度が上がる
ハイパーパラメーターのスケールアップ
仮説1の場合と同様で、頂点以外の拡張とみなせる。Table5の小カッコはデータセット構築時のハイパーパラメーターを少なくした場合。
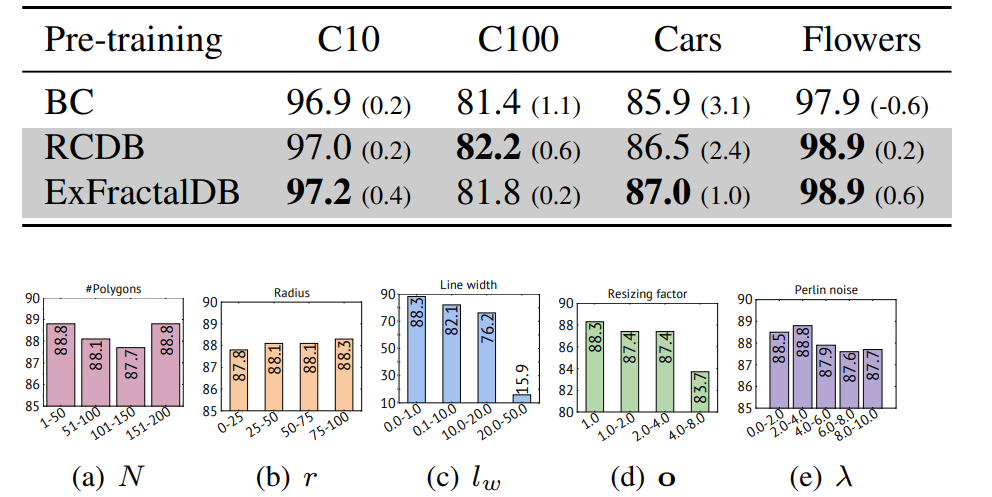
2D→3Dのスケールアップ
ExFractalDBの場合。2Dのフラクタルより3D→2Dの投射をしたほうが、事前訓練の難易度を高めて、Fine-tuningの精度が上がる。
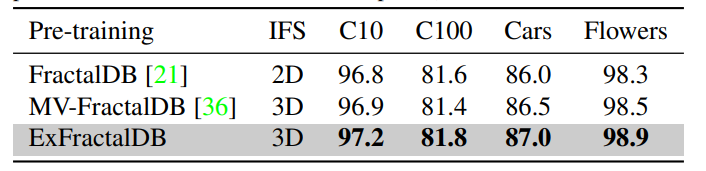
さらにAttentionも鋭くなる。上が3Dに拡張したExFractalDB、下が2DのFractalDB。
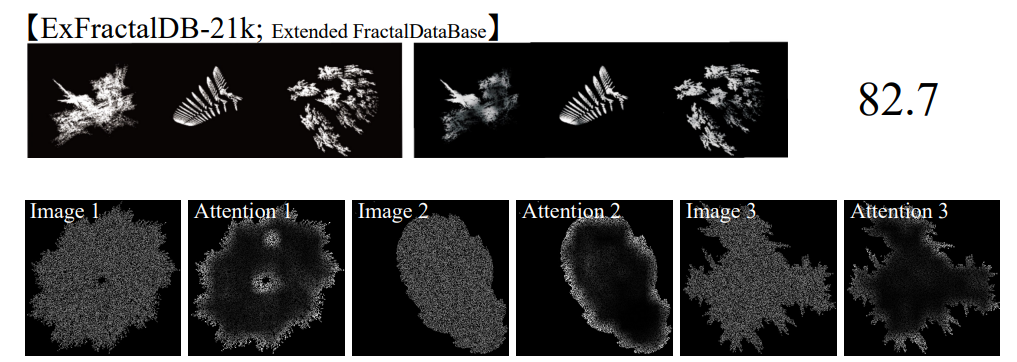
FDSLの失敗例
フラクタル画像の点の数を増やすと急激に精度が良くなるポイントがある
- FractalDB-1kから、レンダリングする点の数を変えて調べる
- フラクタル画像のマスクを徐々に解除しているような挙動
- レンダリングの点の数が50kを超えると、ダウンストリームの精度が急激によくなり、Attentionは輪郭を形成し始めている。
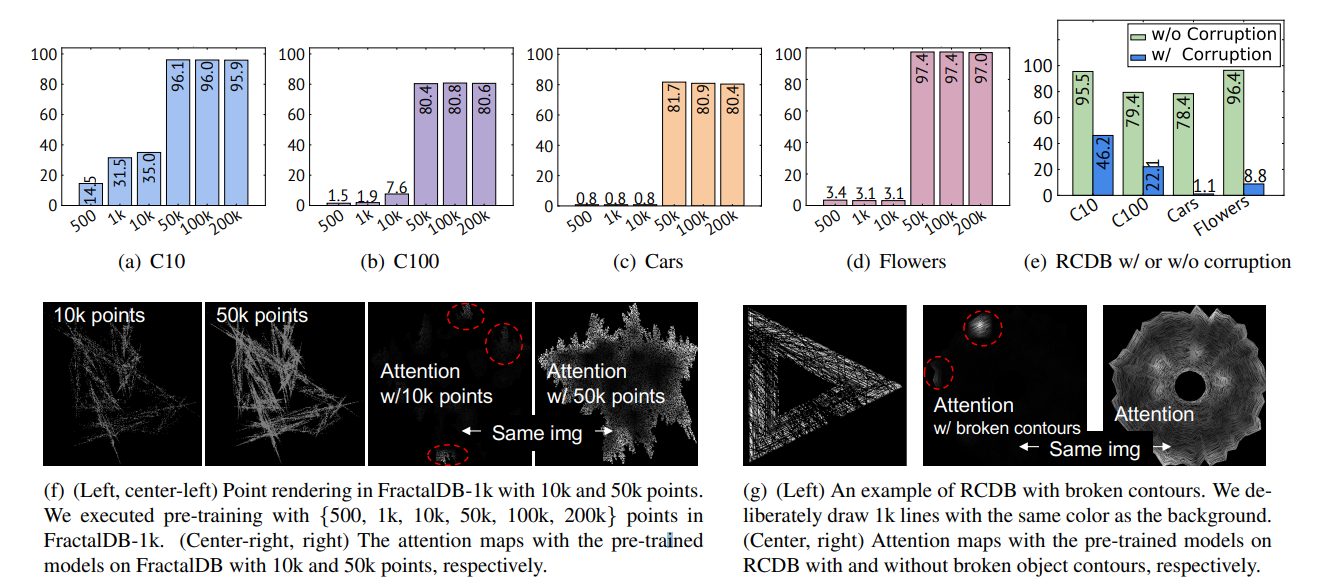
ダウンストリームの精度向上と、Attentionの輪郭形成は連動している。
RCDBの輪郭の一部を欠損させると急激に精度が悪化する
- メインフレームが消えない程度に輪郭を欠損させる
- 欠損があると急激に精度が悪化する
- Attentionが輪郭ではなく点になる
FDSLでは輪郭が大事という結果を支持している
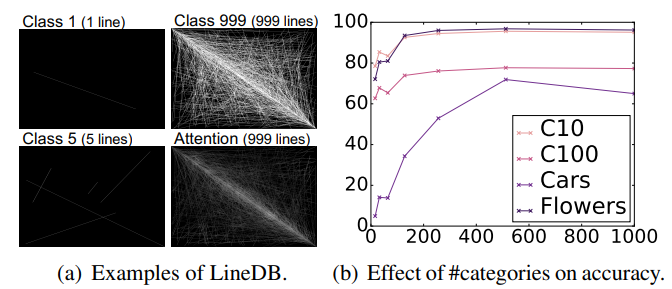
ViTの事前学習はランダムに線を引いた画像でもできる
- ランダムに画像内に線を引いたLineDBというのを作った
- 線の本数別(16, 32, …, 512, 1000)にクラスを定義し、事前学習させる
- 精度はクラス数と連動するが、本数が多すぎると精度がサチる
- 訓練に最適な輪郭の複雑さが存在するため
- 本数ごとにクラスを統一しなく、ランダムに入れ替えるとノイズレベルの精度になる
教師あり学習(SL)、自己教師あり学習(SSL)、数式駆動教師あり学習(FDSL)の比較
分類問題
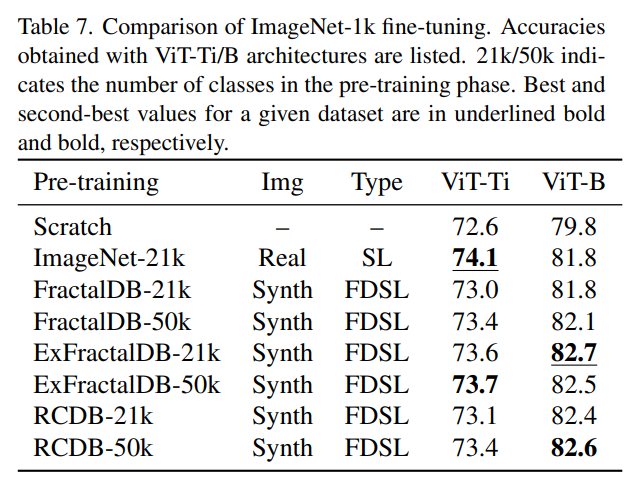
- ImageNet1kのファインチューニングの精度
- ImageNet21k(1300万枚)で訓練し、ImageNet1kでFine-tuningという教師あり学習が半分チートな設定に対しても、数式駆動のほうが良かった
- これは純粋にやばい
- 合成画像のほうが自然画像よりも良くなるケースがある
物体検出・インスタンス領域分割
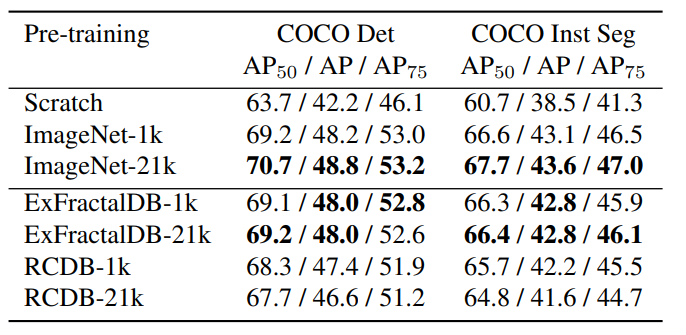
- ImageNet21k > ExFractalDB≒ImageNet1k > RCDB
- スクラッチの訓練よりは全然良い
自己教師あり学習との比較
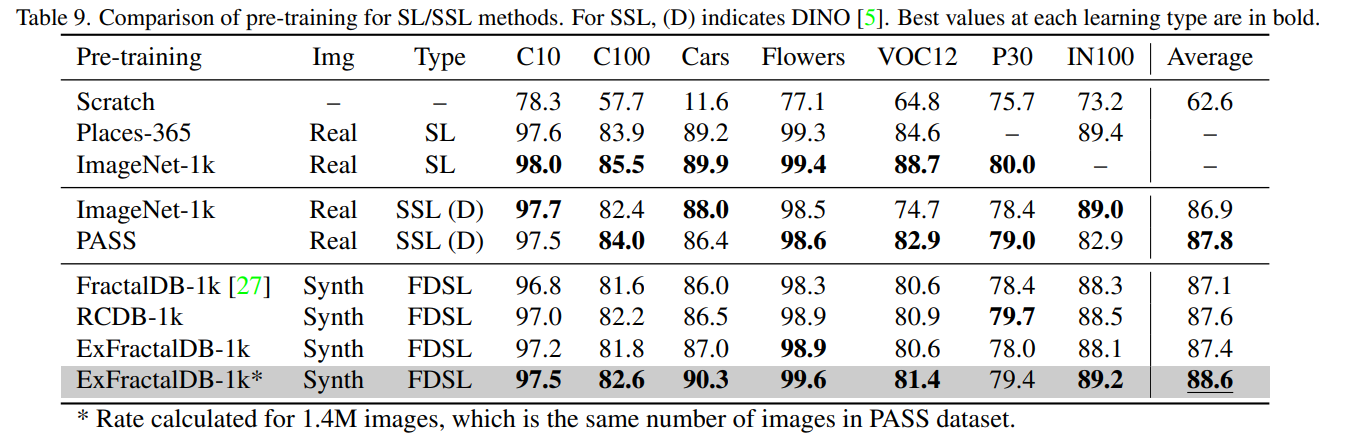
- 多くのケースで、PASS(ImageNetの代替)の自己教師あり学習より高い精度を誇っている
- 特にImageNet100で顕著
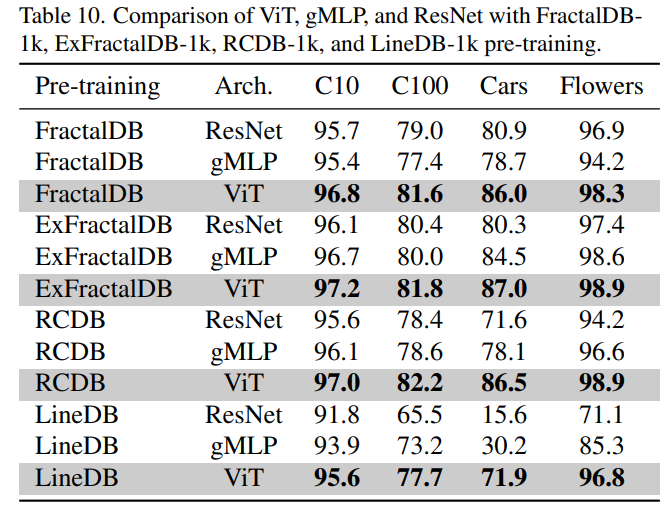
FDSLとネットワーク構造
- 他のアーキテクチャでもFDSLは有効か?
- 有効ではあるが、特にViTで効果を発揮する
- Self Attentionに着目して逆算的にデータを作っているから半ば当然か?
まとめと感想
- ViTの事前学習では、数式駆動の教師あり学習(FDSL)が有効
- この論文では2つの仮説を検証した
-
- FDSLの事前学習は輪郭が重要で、フラクタル画像をViTに学習させるとSelf Attentionは輪郭に着目する
-
- FDSLのフラクタルや輪郭の複雑さをスケールさせると、難易度が高い画像が学習され、Fine-tuningの性能が上がる
-
- ViTに特化した内容ではあるが、カラー画像でもモノクロ画像でも使えるPretrainモデルはあまりないので、医用画像に使うと便利ではないか?
- 輪郭に特化して学習しているなら、画像からの輪郭抽出やレーン検出(輪郭の抽出が大事なタスク)に持っていくと強そう
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー