
PDFのフォント埋め込み問題(T3フォント問題)を回避しながら入稿データを作るのに苦労した話

PDFは便利ですが、フォントの埋め込みが大きな問題になることがあります。T3フォント問題を回避しつつ印刷所に入稿できるデータを作るのにはどうすればよいのか、変換時に画質劣化を起こさないようにするにはどうすればよいのかを調べてみました。
目次
きっかけ
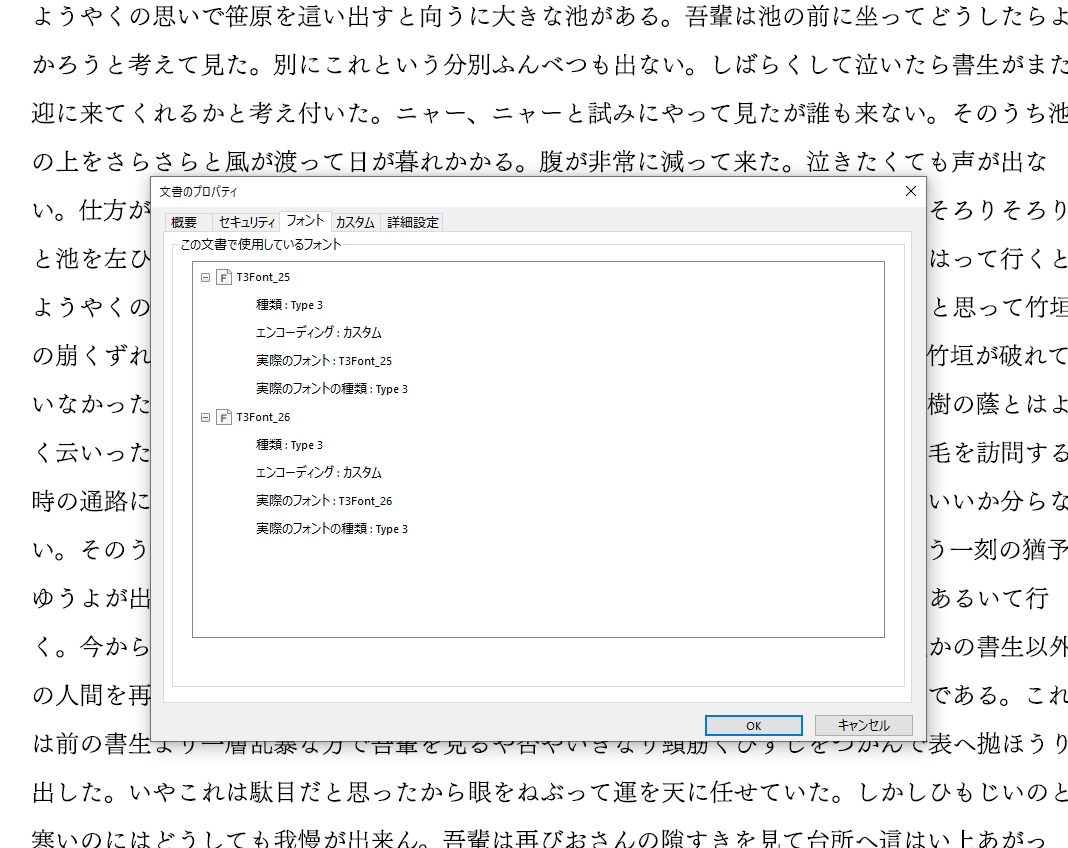
完全に自分用メモ。PDF入稿は便利ですが、フォントの埋め込みが大きな問題になることがあります。ちょっと例えばこんな状況。これは筑紫明朝を本文フォントに使った例です。
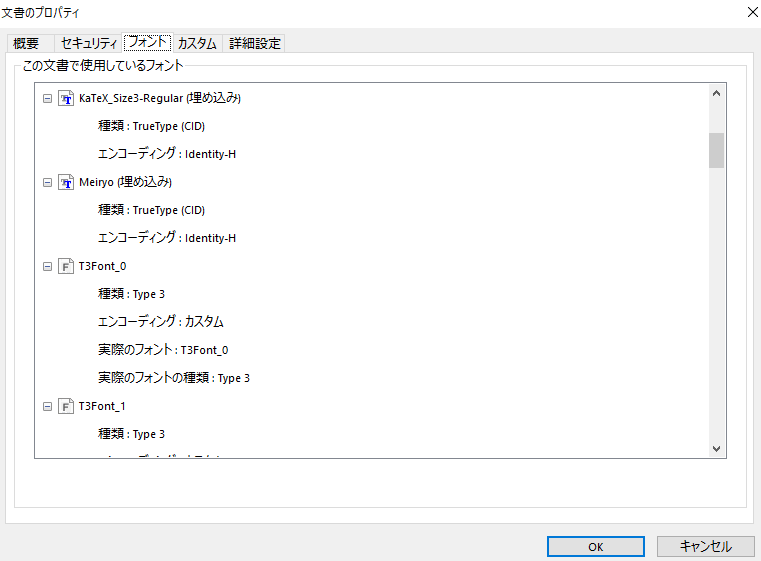
本当は(埋め込みサブセット)とついているのがベストなのですが、(埋め込み)が出ていればひとまずOK。ただこの「T3Font」というのがよくなく、印刷所の入稿時に嫌われます。このT3Fontは埋め込み成功していなく、自分のPCの環境と印刷所の環境で印刷に差が出てしまうのです。自分が入稿したケースでは、「埋め込み」でも数式がずれてしまうことがありました。
最終的に数式がずれたケースでは、印刷所のほうでPDFのアウトライン化をしてもらって解決したのですが、T3フォントはない状態だったのでたまたまできたのかもしれません。T3フォントは論文でもときどき問題になるそうです。
参考
アウトライン化ではまった
一番明快な解決方法は、PDFへの変換時にアウトライン化するように変換する方法です。これはフリーソフトのCube PDFを使えばできます。
埋め込めないフォントを埋め込みたい(PDF変換/CubePDF)
ただ、自分の場合PDFのPDF出力をMarkdown PDFというVS Codeの拡張機能を使ってやっていたため、細かいPDFの印刷設定までいじれなかったのです。内部的にはpuppeteerを通じてChromeのPDF変換機能を使っているそうです。いずれにしても、PDFを吐かせる作業をCube PDFにさせるというようなことが現時点ではできませんでした。
つまり、アウトライン化には「PDF→PDFへのアウトライン化」が必要になります。これをやるのは結構大変で、
- T3フォントが入ってる状態でアウトライン化をする
- Markdown PDFではhtmlを吐かせて、PDF化のヘッダー・フッターを挿入しながら独自にPDF変換をする
前者は自分で試した限り、フリーのPDF変換ソフトでは不可能でした。おそらくAcrobatに課金しないとどうにもならない(前に印刷所の方にアウトライン化してもらったときは印刷所のAcrobatでやってもらいました)。ただそのためだけにAcrobatを課金するのもバカバカしい。
後者はページ番号をどう入れるかが問題になります。CSSの「@page」や「@media print」を使って、ChromeのAPIに依存せずにページ番号を降っていく感じでしょうか。しかし、これでもT3フォントが残らずに埋め込まれるかどうかの保証はありません。最終的にはAcrobatに課金しなければいけないかもしれません。
後者について少し掘り下げると、例えば、Cube PDFで上記のアウトライン化の処理をふまえつつ、筑紫明朝をbodyのfont-familyで指定しただけのHTMLを作成し、ChromeからCube PDF経由でPDFを作成すると以下のようになります。
この通り見るだけなら問題ないのですが(筑紫明朝が入っていないスマホで読んでも普通に読める)、T3フォントが消えません。おそらく電子書籍だけなら特に問題なくても、印刷所に持ち込むとなると結構面倒くさい話になります。
画像というアプローチ
文字を文字のまま残しておくのは、(少なくとも)課金しないと無理筋っぽそうなので、画像に置き換えるというアプローチをとります。これはそこまで難しくなくて、PDF出力の際に「全体を画像として出力する」というオプションにチェック入れればいいだけです。
これはAcrobat Reader(課金しなくても使える版)ですが、印刷→詳細設定から、「画像として印刷」にチェックを入れるだけです。
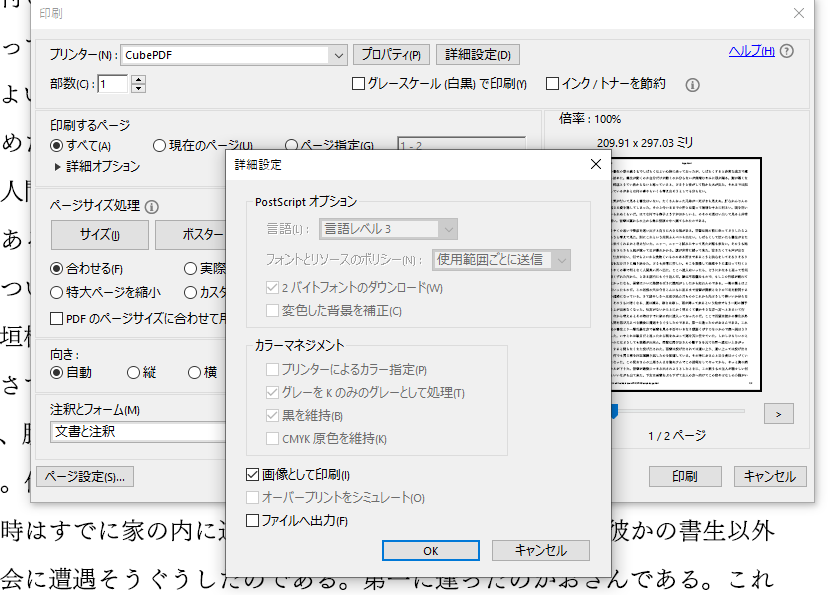
画像として保存するためdpiを上げて保存し(これは極端な設定ですが4000dpi)ました。Cube PDFの「その他→オプション」から「PDFファイル内の画像をJPEG形式で圧縮する」のチェックを外しておきます。
しかし、これも無課金の限界だからなのかもしれませんが、画質がdpiの割に良くないという問題が起こります。
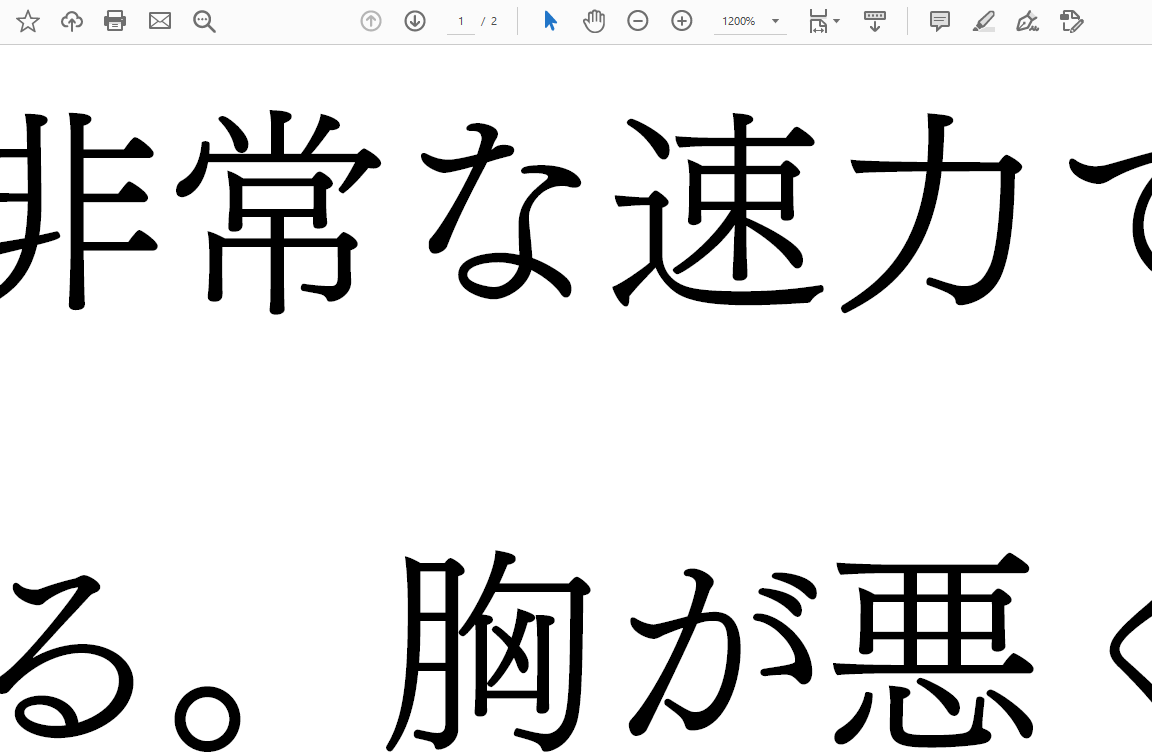
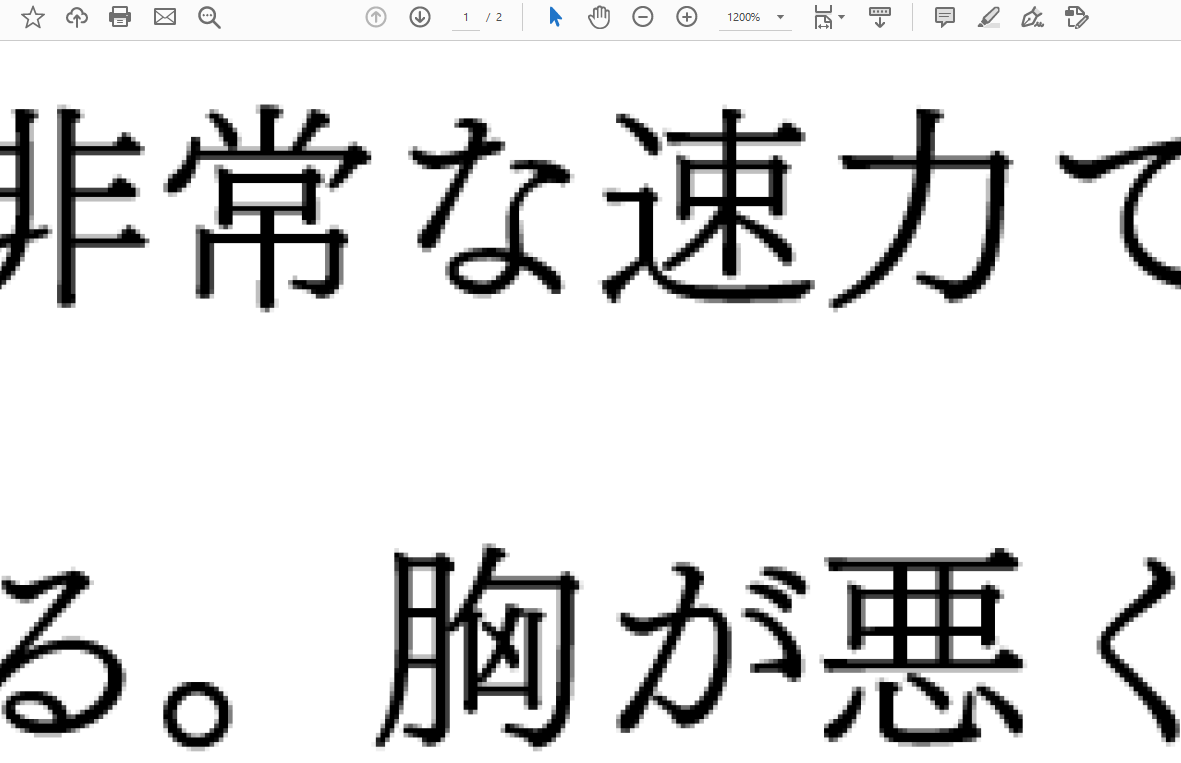
上が画像化する前で、下が画像化した後です。4000dpiで出力した割には画質が明らかに良くないですよね?
この例ではフォントサイズは16ptで作っていますが、72pt=1inchなので、もし4000dpiが正しいとしたら1文字あたり888ドットも割当られるはずです。これ888ドットの画質ではないですよね?? もし800ドットも割当られていたら12倍拡大で目に見えるようなノイズにはならないと思われます。
これではせっかくの筑紫明朝が台無しです。
Python経由でPDFを画像化し、画像ファイルで入稿する
最終的にこれが無課金ならベストではないかなという結論になりました。一旦Markdown PDFでフォント埋め込み不完全なPDFを吐いて、それを画像化して入稿するという方法です(同一のPCなら埋め込みの環境依存問題はおこらない、とたかをくくります)。
そもそも入稿データがPDFでないといけないという縛りはありません。例えば漫画だったらpsdやeps、aiといった画像処理ソフトのファイルですし、印刷所のスタンスとしては「サイズさえあってればPNGやTIFFでもOK(ただJPEGはノイズ出るからやめてほしい)」なので、文章だからといって画像入稿しても問題ないのです。画像として入稿しちゃえばフォント埋め込みの問題は一切起こりません。
ただCube PDFのような既成のPDF化ソフトだと画質の問題があるので、もっと低レベル層から変換を行います。探しているとPythonでPDFを画像化するツールがありました。
参考:
pdf2imageというPythonライブラリを使います。実はこれPopplerというライブラリのラッパーなので、Popplerのバイナリを落としておきます。解凍して作業ディレクトリの直下においておきましょう。
ここでは「poppler-0.68.0」のフォルダと、変換元のPDF「target.pdf」とPythonコードが同一ディレクトリにあるとします。
import os
import pdf2image
def main():
# 一時的にPATHを追加
poppler_dir = os.getcwd() + "/poppler-0.68.0/bin"
os.environ["PATH"] = poppler_dir
# PDFの画像化
pages = pdf2image.convert_from_path("target.pdf", 600) # dpiの指定
for i, p in enumerate(pages):
p.save(f"image_{i:02}.tiff", dpi=(600, 600),compression='tiff_lzw') # dpiの指定とTIFFの圧縮
if __name__ == "__main__":
main()
たったこれだけでできます。最初にpopplerのパスを通す必要がありますが、環境変数いじくるまでもないので、os.environで一時的にパスを追加するようにしています。
PDFの画像化は「pdf2image.convert_from_path」でできます。2つ目の引数が画像化するときのdpiになります。フォントはそもそもベクトルデータなのでdpiに応じた連続的な値を取得することができます。つまりここでのdpiはいわばサンプリングレートで、dpiを大きくするほど高画質な文字になります。
convert_from_pathの結果は内部的にはPILのImageのlistとなっているので、以降の扱い方はPILの普通の画像と同じです。例えばここに断ち切り用の余白を追加することもできます。今tiffで保存していますが、pngの場合でも保存の際にdpi=で指定すると保存後の画像のdpiを明示できます。これを明示しないと72dpiとして保存され、600dpiで画像化したものの保存時のdpiがおかしいせいで、印刷時に元のサイズの8.3倍の大きさになるということがおこります。dpiは必ず明示しましょう。
またtiffの場合は、デフォルトが無圧縮で(ビットマップとほぼ同じ感覚)ファイルサイズがえらい膨らむので、圧縮をかけてあげましょう。保存形式はPNGでも良いですが、JPEGのような不可逆圧縮は印刷時にはやめましょう。
できたものがこちら。スクショしたときに文字サイズが同じになるような倍率で見てみました。
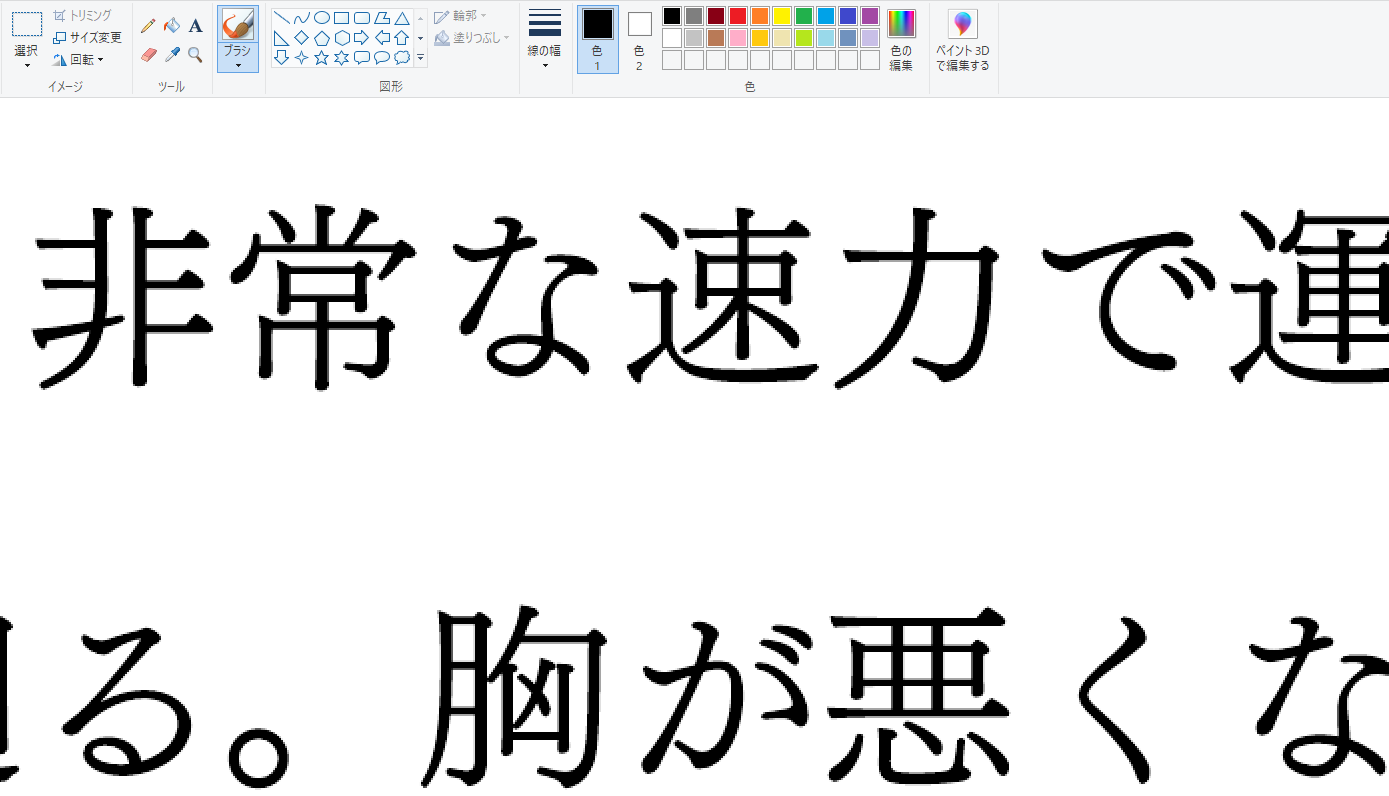
比較のためにCube PDFで画像として印刷したPDF。Python経由でtiff保存したほうが明らかにきれいなのがわかります。
ちなみに元の画像化していないPDF。細かい部分見れば気になるかもしれませんが、pdf2imageの変換で十分そうな気はします。これでも気になるのなら600dpiでなく1200dpiで保存すればいいだけですし。
まとめ
PDFのフォント埋め込み問題は画像化して入稿するのが解決の一案なのかもしれない。このときにCube PDFのようなPDFプリンターではなく、Poppler+pdf2imageのようなコマンドラインベースのほうが高画質の変換が出来ておすすめ。
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー