
配置をコントロール可能な生成モデルGLIGENを試す


Bounding Boxベースの生成や、背景写真を指定したInpaintingができるGLIGENを試してみます。実はControlNetと同様に、様々な条件ベースの生成が可能なモデルです。
目次
はじめに
配置をコントロール(空間コントロール)可能なモデルとして前回MultiDiffusionを試しましたが、今回は同じようにコントロールできるGLIGENを試してみます。
GLIGEN
論文までちゃんと追う気力が出なかったのですごい雑な解説をします。AbstractをDeepLにかけた結果がこのとおりです。
大規模なテキストから画像への拡散モデルは、驚くべき進歩を遂げています。しかし、現状はテキスト入力のみであり、制御性を阻害する可能性がある。本研究では、GLIGEN(Grounded-Language-to-Image Generation)を提案し、既存の事前学習済みテキスト-画像拡散モデルの機能を拡張し、接地入力にも条件付けできるようにする新しいアプローチを構築する。事前学習済みモデルの膨大な概念知識を保持するため、全ての重みを凍結し、ゲート機構を介して接地情報を新しい学習可能な層に注入します。このモデルは、キャプションとバウンディングボックスの条件入力で、オープンワールドの地に足のついたtext2img生成を達成し、その接地能力は、新しい空間構成や概念にうまく一般化する。COCOとLVISにおけるGLIGENのゼロショット性能は、既存の教師ありレイアウト画像生成のベースラインを大きく上回るものである。
テキストと画像のように異なるモダリティを融合させることをGrounding(直訳すると接地)といいますが、独自の「Gated Attention機構」を使ってGroundingを推し進めているようですね。公式サイトのティザー画像からです。

やっていることは、なにかを条件とした出力。Bounding Boxを条件としたり、ポーズを条件としたり、Depthを条件としたり、法線マップやエッジを条件としたり、なんかやっていることがControlNetに瓜二つな気がしますね。ただ論文として生まれたのはGLIGENのほうが先で、GLIGENがarXivでPublishされたのが2023/1/17、ControlNetが2023/2/10です。GLIGENのほうが研究的には先輩なわけです。
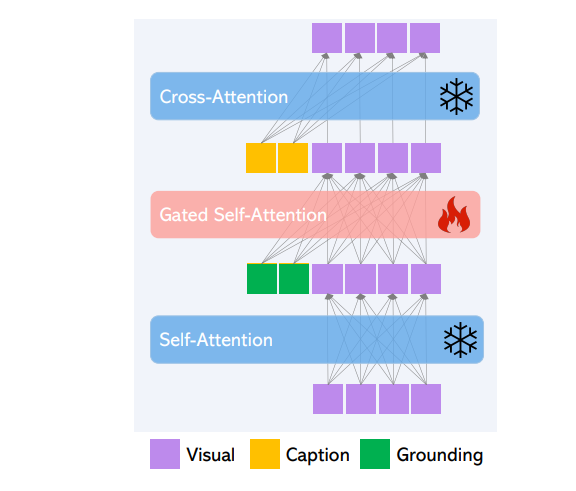
GLIGENはAttentionの注入でGroundingをするというもので、ControlNetが追加のネットワークを使って注入したのに対して、Attentionであるというのが違いです。個人的にはGLIGENのほうが、ControlNetよりも設計的にちゃんとしているような気がします。これだけ見るとLoRAやControlNetのように任意のモデルに注入できそうな気がしますが、公式で公開されているモデルがSD1.4と密結合の状態で配布されており、いまいち使い勝手がよくありません。このへんがControlNetやLoRAとくらべてあまり注目されない点なのかもしれません。
GLIGENの大きなポイントは、MultiDiffusionでできなかったInpaintingができるということです。つまり、背景をユーザーが与えた写真に固定して、その一部を書き換えることができます。MultiDiffusionはブートストラップの関係上、これが難しかったです。これを試していきましょう。
DiffuserフォークのDocker化
GLIGENは本家のDiffusersが3/31時点で対応していませんが、フォークされたDiffusersで対応してあります
https://github.com/gligen/diffusers/tree/gligen/examples/gligen
これをDockerイメージ内にインストールして起動してみます。Dockerfileとrequirements.txtは以下のようにします。
FROM nvidia/cuda:11.7.1-cudnn8-runtime-ubuntu20.04
RUN apt-get update
ENV TZ=Asia/Tokyo
RUN ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && echo $TZ > /etc/timezone
RUN apt-get install -yq --no-install-recommends python3-pip \
python3-dev \
wget \
git \
tzdata && apt-get upgrade -y && apt-get clean
RUN ln -s /usr/bin/python3 /usr/bin/python
COPY requirements.txt .
RUN pip install -U pip &&\
pip install --no-cache-dir -r requirements.txt
--extra-index-url https://download.pytorch.org/whl/cu117
torch==2.0.0+cu117
torchvision==0.15.1+cu117
accelerate==0.18.0
transformers==4.27.3
git+https://github.com/gligen/diffusers.git
ビルドして実行します
docker build -t gligen .
docker run --rm -it --gpus all \
-v <current_directory>:/GLIGEN gligen
ソースをコピーします。
root@3fdc921a977c:/# git clone https://github.com/gligen/diffusers
root@3fdc921a977c:/# cp -r /diffusers/examples/gligen/* /GLIGEN
root@3fdc921a977c:/# cd /GLIGEN
マウントしているWindows側のカレントディレクトリにソースがコピーされるはずです。2つのソースファイルがあり、
- generation_text_box.py : Bounding BoxのConditionつきのText2Image
- inpainting_text_box.py : Bounding BoxのConditionつきのImage2Image(Inpainting)
generation_text_box.py
こんなコードです
import os
import torch
import torchvision
from diffusers import StableDiffusionGLIGENPipeline
pipe = StableDiffusionGLIGENPipeline.from_pretrained("gligen/diffusers-generation-text-box", revision="fp16", torch_dtype=torch.float16)
pipe.to("cuda")
os.makedirs("images", exist_ok=True)
prompt = "a dog and an apple"
images = pipe(
prompt,
num_images_per_prompt=2,
gligen_phrases = ['a dog', 'an apple'],
gligen_boxes = [
[0.1387, 0.2051, 0.4277, 0.7090],
[0.4980, 0.4355, 0.8516, 0.7266],
],
gligen_scheduled_sampling_beta=0.3,
output_type="numpy",
num_inference_steps=50
).images
images = torch.stack([torch.from_numpy(image) for image in images]).permute(0, 3, 1, 2)
torchvision.utils.save_image(images, "images/generation_text_box.png", nrow=2, normalize=False)
背景のプロンプトが「a dog and an apple」で、gligen_boxesが各オブジェクトを配置するBounding Box、gligen_phrasesが対応するオブジェクトです。
Docker側から実行してみると、
root@3fdc921a977c:/GLIGEN# python generation_text_box.py

2枚生成されています。犬とりんごが対象領域に生成されています。空間コントロールとはこいうことです。
inpainting_text_box.py
こんなコードです。
import os
import torch
import torchvision
from diffusers import StableDiffusionGLIGENPipeline
from PIL import Image
pipe = StableDiffusionGLIGENPipeline.from_pretrained("gligen/diffusers-inpainting-text-box", revision="fp16", torch_dtype=torch.float16)
pipe.to("cuda")
os.makedirs("images", exist_ok=True)
prompt = "a dog and a birthday cake"
images = pipe(
prompt,
num_images_per_prompt=2,
gligen_phrases = ['a dog', 'a birthday cake'],
gligen_inpaint_image=Image.open("resources/arg_corgis.jpeg").convert('RGB'),
gligen_boxes = [
[0.1871, 0.3048, 0.4419, 0.5562],
[0.2152, 0.6792, 0.7671, 0.9482]
],
gligen_scheduled_sampling_beta=1,
output_type="numpy",
num_inference_steps=50
).images
images = torch.stack([torch.from_numpy(image) for image in images]).permute(0, 3, 1, 2)
torchvision.utils.save_image(images, "images/inpaint_text_box.png", nrow=2, normalize=False)
generation_text_boxとの違いは、元画像があるという点です。元の画像はこちら

実行すると(generationとinpaintで別個にDLスクリプトが走るのがちょっとアレですが)、
root@3fdc921a977c:/GLIGEN# python inpainting_text_box.py

犬とバースデーケーキが追加されました。
インスタンス数が増えたときの挙動
問題は乱数シードを固定して、インスタンス数が増えたとき、増える前のインスタンスの外観は変わらないか? ということです。例えば、「犬とバースデーケーキ」で生成したときと「犬とバースデーケーキと太陽」で生成したときで、犬やバースデーケーキの外観が変わってしまわないか? という点です。
こんな感じにprompt, gligen_phrases, gligen_boxesを変化させて、実験してみます。
prompt = "a dog and a birthday cake"
# prompt = "a dog, a birthday cake and a sun"
torch.manual_seed(0)
torch.cuda.manual_seed(0)
images = pipe(
prompt,
num_images_per_prompt=1,
gligen_phrases = ['a dog', 'a birthday cake', 'a sun'],
# gligen_phrases = ['a dog', 'a birthday cake'],
gligen_inpaint_image=Image.open("resources/arg_corgis.jpeg").convert('RGB'),
gligen_boxes = [
[0.1871, 0.3048, 0.4419, 0.5562],
[0.2152, 0.6792, 0.7671, 0.9482],
[0.6054, 0.1757, 0.7988, 0.3320]
],
gligen_scheduled_sampling_beta=1,
output_type="numpy",
num_inference_steps=50
).images
- prompt:”a dog and a birthday cake”
- gligen_phrases = ‘a dog’, ‘a birthday cake’

- prompt:”a dog and a birthday cake”
- gligen_phrases = ‘a dog’, ‘a birthday cake’, ‘a sun’

バースデーケーキの装飾部分が微妙に変わっています
- prompt:”a dog, a birthday cake and a sun”
- gligen_phrases = ‘a dog’, ‘a birthday cake’, ‘a sun’

やはりバースデーケーキの装飾部分が微妙に変わっています。
結論
インスタンスのプロンプトが追加されたときに、既存のインスタンスの外観が変わってしまう
このへんはちょっと扱いづらそうな気がしました。他にもGLIGENにはいろんなモデルがありますが、結構面白い研究だっただけにここらへんの扱いづらさがちょっと改善されるとうれしいなーと思いました
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー