
論文まとめ:NVIDIA Nemotron Nano V2 VL


NVIDIAの「Nemotron Nano V2 VL」は、12Bの軽量かつ高効率な視覚言語モデルです。MambaとTransformerのハイブリッド構成と、動画の静的領域を間引くEVS技術により、処理速度を大幅に向上させました。視覚学習で低下する論理思考力を「回復」させる独自の訓練工程が特徴で、OCRや動画理解で高い性能を発揮します。
- タイトル:NVIDIA Nemotron Nano V2 VL
- 著者:NVIDIAの方々
- 論文URL:https://research.nvidia.com/labs/adlr/files/NVIDIA-Nemotron-Nano-V2-VL-report.pdf
- モデル:https://huggingface.co/collections/nvidia/nvidia-nemotron-v2 (NVIDIA Open Model Licenseで商用利用可能)
目次
NotebookLMによるまとめ
この論文において解決したい課題は何?
本書は、実世界におけるドキュメント理解、長時間の動画理解、および推論タスクにおいて強力な性能を持つ、効率的な視覚・言語モデル(VLM)を開発することを目的としています,。具体的には、高いスループット(処理速度)を維持しながら、OCR(光学文字認識)、数学的推論、長いコンテキストを要するタスクでの精度向上を目指しています,。
先行研究だとどういう点が課題だった?
- テキスト能力の忘却: VLMのトレーニング(視覚情報の学習)を進めると、ベースとなる大規模言語モデル(LLM)が本来持っていた純粋なテキスト推論能力(特にコーディング能力など)が低下してしまう「破滅的忘却」の問題がありました,。
- 処理効率: 長時間の動画や複数ページのドキュメントを扱う際、従来のTransformerアーキテクチャでは計算コストが高く、スループットが低下するという課題がありました。
- 解像度の制約: 固定解像度での画像処理では、アスペクト比の異なる画像や高解像度のドキュメントの詳細を捉えきれない問題がありました。
先行研究と比較したとき、提案手法の独自性や貢献は何?
- ハイブリッド・アーキテクチャの採用: MambaとTransformerを組み合わせた「Nemotron Nano V2 (12B)」をLLMバックボーンに採用し、長文ドキュメント理解において旧モデル比で35%高いスループットを実現しました,。
- テキスト能力回復のための多段階トレーニング: 視覚的なトレーニングの後に、コード推論データのみを用いた「リカバリーステージ(Stage 3)」を導入し、低下したテキスト能力(LiveCodeBenchスコア等)を回復させました,。
- 推論モードの切り替え: 複雑な問題解決のための「Reasoning-on(思考)」モードと、効率重視の「Reasoning-off」モードの両方をサポートしています。
- 推論の高速化: 動画処理において、静的な(動きの少ない)領域を間引く「Efficient Video Sampling (EVS)」を採用し、精度を維持したまま2倍以上の高速化を可能にしました,。
提案手法の手法を初心者でもわかるように詳細に説明して
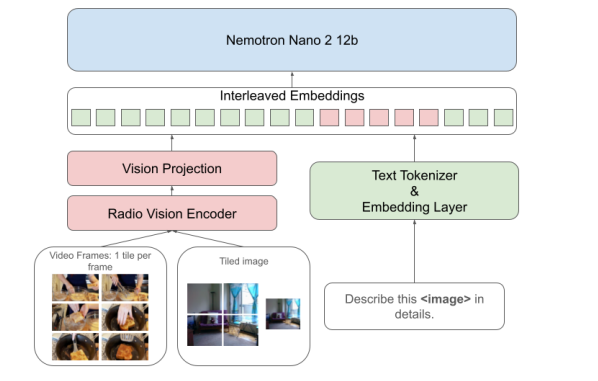
このモデルは、「目(画像認識)」と「脳(言語処理)」をつなぎ合わせ、段階的に教育していくアプローチをとっています。
- 目と脳の構造:
- 目(Vision Encoder): 画像の特徴を捉える部分には「RADIOv2.5」という高性能なモデルを使用しています,。
- つなぎ役(Projector): 目が見た情報を脳が理解できる言葉(トークン)に変換するコネクタです。
- 脳(LLM): 思考を行う中心部分には「Nemotron-Nano-V2 12B」を使用しています。
- 画像の読み方(Tiling):
- 大きな画像や細かい文字があるドキュメントは、そのまま縮小すると詳細が潰れてしまいます。そこで、画像を複数の「タイル(512×512ピクセル)」に分割して読み込み、さらに全体像を把握するためのサムネイル画像も併用することで、詳細と全体の文脈の両方を理解します。
- 教育カリキュラム(多段階トレーニング):
- Stage 0(準備運動): 目と脳をつなぐコネクタ部分だけを訓練し、画像と言葉の基礎的な対応関係を教えます。
- Stage 1(基礎学習): テキストと画像を使って、16,000トークンまでの長さで学習します。
- Stage 2(動画・長文): コンテキスト長を約49,000トークンに拡張し、動画や複数画像の理解を教えます。
- Stage 3(復習): 視覚の勉強で忘れてしまった「プログラミング等の論理的思考」を思い出すため、コード推論データだけで再学習します(これをText Recoveryと呼んでいます),。
- Stage 4(超長文): 最終的に約300,000トークンまで扱えるようにし、非常に長いドキュメントに対応させます。
提案手法の有効性をどのように定量・定性評価した?
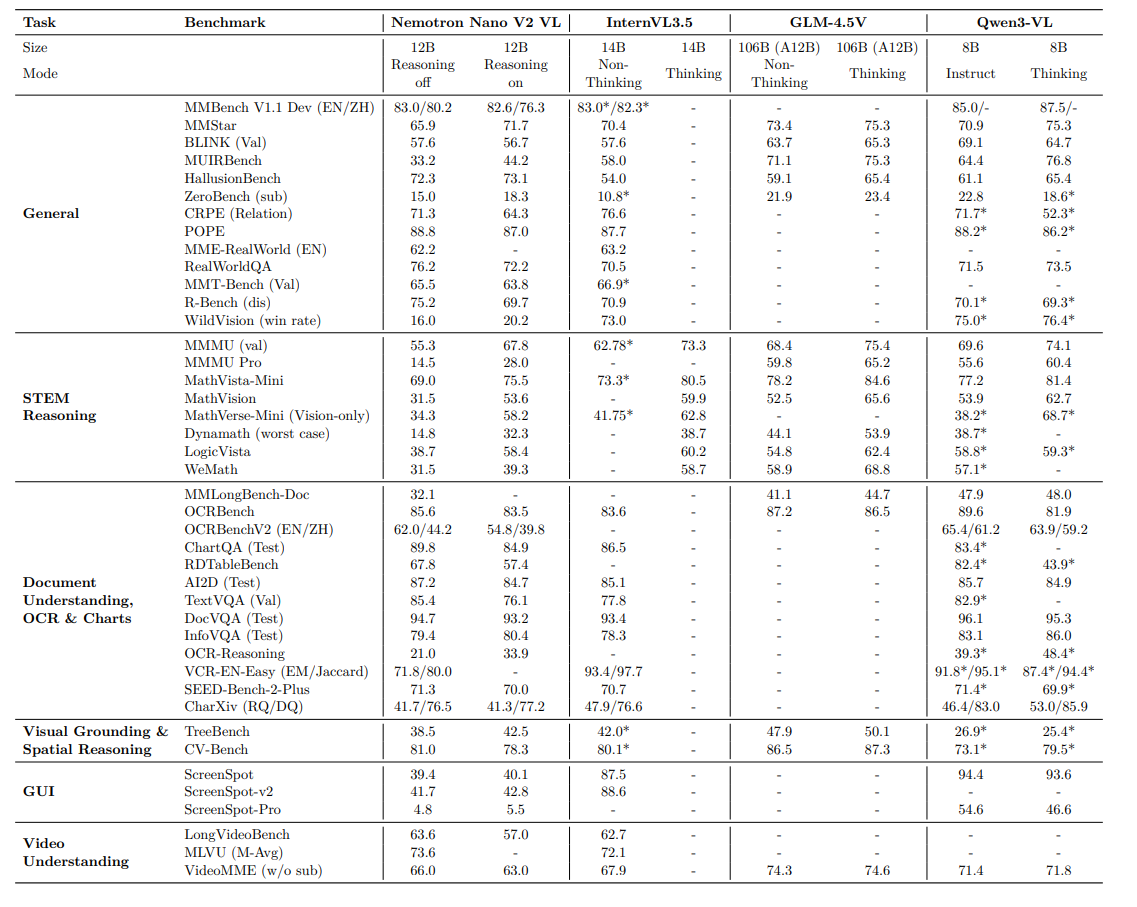
- ベンチマーク評価: OCRBench(文字認識)、Video-MME(動画理解)、MathVista(数学的推論)など、45種類の多様なベンチマークで評価を行いました,。
- 他モデルとの比較: 同規模のモデル(InternVL3.5-12Bなど)や、より大規模なモデル(GLM-4.5V、Qwen3-VL)と比較し、OCRや動画理解などのタスクで競争力のある、あるいは優れたスコアを達成しました。
- アブレーションスタディ(要因分析):
- トレーニングの各ステージごとの性能変化を測定し、Stage 3(テキスト回復)を入れることでコード生成ベンチマーク(LiveCodeBench)のスコアが50.9から69.8へ劇的に回復したことを実証しました。
- EVS(動画の間引き処理)の比率を変えて実験し、90%のトークンを削減しても精度低下が軽微であることを示しました。
この論文における限界は?
- 画像タイリングの副作用: 画像を分割して処理する「タイリング戦略」は概ね有効ですが、特定のOCRベンチマーク(OCRBench-V2 English)では、タイリングなし(ネイティブ解像度+圧縮)の手法に比べて精度が劣るケースが確認されました。これはリサイズ処理の影響と考えられています。
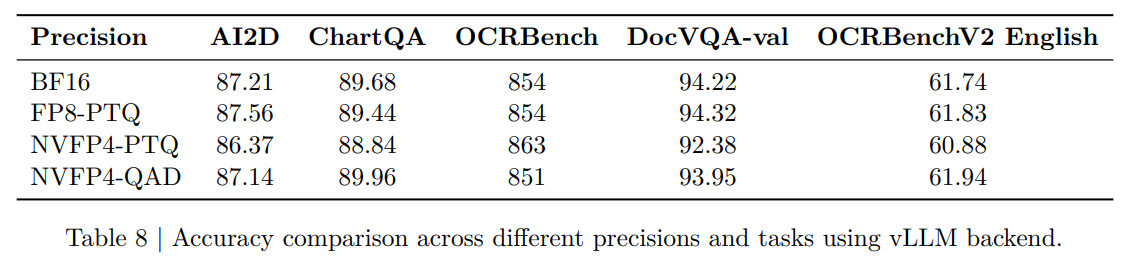
- 量子化による精度低下: 推論高速化のためにモデルを軽量化(FP8やNVFP4へ量子化)すると、わずかながら精度が低下します。特にNVFP4(4ビット)では蒸留(Distillation)を行わないと精度の落ち込みが見られました,。
次に読むべき論文は?
この研究の基盤技術や、比較対象として重要な以下の論文が推奨されます。
- NVIDIA et al. (2025) “NVIDIA Nemotron Nano 2…”: 本モデルの「脳」にあたるLLMバックボーンの詳細と、ハイブリッドMamba-Transformerアーキテクチャについて理解するために必要です。
- Heinrich et al. (2025) “RADIOv2.5”: 本モデルの「目」にあたるVision Encoderの詳細を知るために重要です。
- Bagrov et al. (2025) “Efficient Video Sampling”: 動画処理を高速化するEVS技術のアルゴリズム詳細について書かれています。
- Chen et al. (2025b) “InternVL 3.5” または Qwen2.5-VL / Qwen3-VL Technical Reports: 本論文内で主要な比較対象とされている最先端の競合モデルです。
MambaとTransformerを組み合わせた理由
「Nemotron Nano V2」の内容ではあるが、MambaとTransformerを組み合わせた主な理由は、長いドキュメントやビデオの処理における推論スループット(処理能力・速度)を向上させるためです。
具体的には、このハイブリッド構成により、従来のモデル(Llama-3.1-Nemotron-Nano-VL-8B)と比較して、長い複数ページのドキュメント理解において35%高いスループットを実現しています。
| アーキテクチャ | 単体での課題(資料に基づく解釈) | ハイブリッドでの解決策 |
|---|---|---|
| Transformer | 長い動画やドキュメント処理時にスループットが低い(遅い),。 | Mambaを組み込むことで、計算効率を高め、スループットを向上させる。 |
| Mamba | (暗に)複雑な推論や精度面でTransformerの補完が必要である可能性がある。 | Transformer層を維持することで、本来の言語モデルとしての推論能力と精度を担保する。 |
視覚の訓練を進めるとコーディング能力が落ちてしまう理由
視覚の訓練を進めるとコーディング能力が落ちてしまう理由は、新しい視覚能力(画像や動画の理解)への適応にモデルの容量が割かれ、元々持っていた純粋なテキスト推論能力(特に論理性が求められるコーディング)が「忘却」されてしまうためです。
具体的には以下の通りです。
- マルチモーダル学習による忘却: 画像や動画とテキストを結びつける学習(Stage 1〜2)を行うと、モデルは視覚情報の処理に最適化されますが、その副作用として、純粋なテキストベースの複雑な論理処理能力が低下します。
- 劇的なスコア低下: 実際に、視覚トレーニング(SFT Stage 1)を経た段階で、コーディングのベンチマーク(LiveCodeBench)は70.0から50.9へと大幅に急落しました。
- 単純なデータ混合では不十分: この低下は、視覚学習データにテキストデータを混ぜるだけでは防ぎきれず、コード推論データのみを学習させる専用の「回復(Recovery)」ステージを設けない限り、元の性能には戻らないことが確認されています。
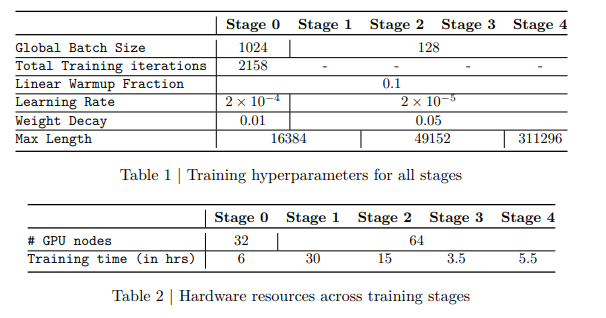
各ステージの根拠
1. 動画の訓練をStage2から始めた理由
動画や複数画像の処理には大量のトークンが必要であり、Stage 1のコンテキスト長(16,384トークン)では処理しきれなかったためです。Stage 2でコンテキスト長を49,152トークンまで拡張したことではじめて、動画理解に必要な容量が確保されました。
2. コード能力の訓練をStage3においた理由(最終ではない理由)
Stage 1(画像)とStage 2(動画)の訓練によって、モデルのコード推論能力が著しく低下(スコアが70.0から55.0へ急落)したため、これを「回復(Recovery)」させる必要があったからです。
これを最終段階にしなかった理由は、回復させた能力を基盤として、最後のStage 4でさらに長い30万トークン(約300K)へのコンテキスト拡張を行う手順が必要だったためです。つまり、「視覚学習による劣化の修復(Stage 3)」を完了させてから、「超長文脈への対応(Stage 4)」を行う順序となっています。
SFTだけで訓練
提供されたレポートによると、訓練プロセスではSFT(Supervised Fine-Tuning:教師あり微調整)のみが行われており、DPO(Direct Preference Optimization)やGRPO(Group Relative Policy Optimization)などの選好学習(Preference Optimization)手法が使用された記述はありません。
具体的には以下の通りです。
- 全ステージがSFT: レポートに記載されているStage 0からStage 4までの全ての訓練プロセスは、明確に「SFT」として定義されています。
- 推論能力の強化方法: 推論(Reasoning)能力の強化には、強化学習(RLHF/DPOなど)ではなく、「思考の過程(Reasoning traces)」を含むデータセットを用いたSFTによって対応しています。
- 量子化のための蒸留: モデルの軽量化(4ビット量子化)を行う際にのみ、「量子化アウェア蒸留(QAD: Quantization-aware Distillation)」という手法が使われていますが、これはDPOなどのアライメント手法とは異なります。
動画の訓練データ
動画の訓練データは、主にStage 2(コンテキスト拡張)で導入され、全てのデータをQA(質問・回答)形式に統一して用意されました。
具体的な作成手法は以下の通りです。
- テンプレートによる変換:
ビデオ分類(Classification)や時間的特定(Temporal Grounding)などのデータセットは、あらかじめ用意したテンプレート質問文を使ってQAペアに変換しました。 - LLMによる合成(Synthetic Data):
ビデオキャプション(動画の説明文)のみのデータについては、Qwen2.5などの外部LLMを使用し、そのキャプションに基づいて「質問」と「回答」の両方を自動生成させました。 - フレーム処理:
動画ファイルは1秒あたり2フレームで抽出され、1動画あたり最大128フレーム(64秒を超える場合は均等サンプリング)を入力データとして使用しました。
訓練データの言語
訓練データは英語が中心ですが、多言語(マルチリンガル)データも明確に含まれています。
資料に基づく詳細は以下の通りです。
- 多言語データ: ベースとなるLLMの学習データに「多言語理解」が含まれているほか、SFT Stage 1では多言語のウィキメディア・ダンプや、翻訳モデル(mBART-large-50)を用いて数カ国語に翻訳されたarXiv論文データなどが使用されています。
- 確認できる言語: ベンチマーク評価やデータセットの記述から、英語(English)と中国語(Chinese)が主要な対象であり、その他にポルトガル語、アラビア語、トルコ語、ロシア語などが含まれていることが確認できます,。
(※使ってみたところ日本語でも一応応答はできる)
Efficient Video Samplingの仕組み
Efficient Video Sampling (EVS) とは、動画データの処理において「時間的な変化」に注目し、冗長な情報を賢く削減することで、AIモデルの処理効率を劇的に高める技術です。
その具体的な仕組みとメリットは以下の3点に集約されます。
1. 「変化のない領域」を特定して間引き(プルーニング)
動画の連続するフレーム間において、背景などの「ほとんど変化がない静的な領域(Static Patches)」を自動的に検出します。この重複している領域のデータ(ビジュアルトークン)を削除することで、AIが処理すべきデータ量を大幅に削減します。
2. 文脈と意味の維持
単にデータを減らすのではなく、位置情報(Positional Identity)や意味的な一貫性(Semantic Consistency)を維持したまま圧縮を行います。これにより、モデルはデータ量が減っても動画の内容や文脈を見失うことなく、正しく理解し続けることができます。
3. 「再学習不要」で2倍以上の高速化
この手法の最大の特徴は、モデルの構造変更や再学習が一切不要である点です。既存の推論パイプラインにそのまま組み込むだけで、認識精度への影響を最小限(あるいはゼロ)に抑えつつ、処理速度(スループット)を2倍以上に向上させることが可能です。
Projectorのアーキテクチャ
Projector(プロジェクター)のアーキテクチャは、MLP(Multi-Layer Perceptron:多層パーセプトロン)です。
資料に基づく詳細は以下の通りです。
- 役割: 視覚エンコーダ(RADIOv2.5)とLLM(Nemotron Nano V2)の間をつなぐ「コネクタ」として機能します。
- 処理: 視覚エンコーダによって処理された画像や動画のフレーム(512×512のタイル)の特徴量を、LLMが理解できる埋め込み表現に変換し、テキストの埋め込みとインターリーブ(交互配置)させます。
- 学習: 学習の最初の段階(Stage 0)では、視覚と言語の連携(アライメント)を確立するために、このMLP部分のみがトレーニングされます。
推論時にどのぐらいのGPUが必要か?
推論時に必要なGPUスペックは、モデルの量子化(軽量化)レベルによって異なりますが、12B(120億)パラメータのモデルであるため、以下の目安となります。
提供された資料に基づき、推奨環境を簡潔にまとめます。
- FP4 (NVFP4) 量子化モデル:
- 必要VRAM: 約 8GB〜12GB
- 対象: 一般的な消費者向けGPU(例: RTX 4060 / 3080など)。NVIDIAはこのモデル専用のFP4ウェイトを公開しており、最も軽量に動作します。
- FP8 量子化モデル:
- 必要VRAM: 約 16GB〜24GB
- 対象: ハイエンド消費者向けGPU(例: RTX 4080 / 4090)。
- BF16 (フル精度) モデル:
- 必要VRAM: 40GB以上 推奨
- 対象: 業務用GPU(例: A100, H100, RTX 6000 Ada)。ウェイトだけで約24GBを消費するため、消費者向けGPU(24GB)ではコンテキスト(動画や長文)を読み込む余裕がほとんどありません。
注意点:
動画や長文(Long Context)を扱う場合は、これに加えてKVキャッシュ用メモリが大量に必要になります。長い動画を扱う際は、より多くのVRAM(またはEVSのような軽量化技術の利用)が必要です。
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー