
LLMで「良い論文」を定義し、サーベイしてみる

引用数依存からの脱却——LLMによる「独創性」評価で、トップカンファレンスから真に読むべき論文を発掘する。 全2119件の論文をTier分類し、「革新性重視」と「トレンド重視」の戦略によるサーベイ品質の違いを検証しました。
目次
膨大な論文を読むための羅針盤を作る
以前の記事で、エージェントを活用したRAGシステムについて実験を行いました。
このときは「ICCV2025全体」という大きな母集団に対するサーベイでしたが、実際のサーベイは読者の「この論文面白そう」という嗜好や、「こういうテーマ深堀りたい」という意思による「フィルター」がかかります。この差によって、同じサーベイ論文でも著者によってかなり差が出ます。
また、以前『AI論文年鑑2025』を書いたときには、暫定のフィルタリングとして、論文の引用数やGitHubリポジトリのスター数で判定しましたが、これも問題があります。
- 新しい論文が不利:公開から日が浅い論文は引用が少ない
- 流行りに偏る:「みんながやっている研究(例:LLM)」が上位にくる
- ダークホースを見逃す:革新的だがまだ注目されていない論文を拾えない
何万件もある論文リストに対して、人間の力で事前フィルタリングは不可能です。そこで、LLMに「良い論文」を定義させて、引用数と組み合わせたらどうなるか?という点について、検証してみました。
そもそも良い論文とはなにか
そもそも良い論文とは何でしょうか? 引用数の多い論文でしょうか?
ここはいろんな方の意見があって然るべきですが、自分はなんとなく以下のようにふわっと考えていました。
- なにか独創的で革新的なアイディアを持ったもの
- 例えば、TransformerやNeRFのように、それ自体がブレイクスルーとなって、後続の研究がどんどん続いていくようなもの
- 論理的に美しいもの
- 例えば、今までは経験ベースで実験されていたものが、理論的に背景をしっかり説明されて、なおかつそれがシンプルな理論で説明されているもの
これらをClaude Codeと壁打ちしながら、「良さの指標」を定義していきます。実務的には、このような主観的な指標2個+引用数のような客観指標1個を組み合わせて使います。
Step 1: LLMで品質評価する
3つの評価軸
論文の「良さ」を3つの軸で測ることにしました:
| 軸 | 意味 | 評価方法 |
|---|---|---|
| Originality | 独創性・新規性 | LLM(1-5) |
| Elegance | 論理の美しさ | LLM(1-5) |
| Citation | コミュニティの評価 | Semantic Scholar API |
- Originality(独創性) は「これまでにない視点か?」を測ります。パラダイムシフトの可能性を評価します。
- Elegance(論理の美しさ) は「シンプルで必然的な解決策か?」を測ります。エンジニアリング的な力技ではなく、「見たら当たり前だけど、誰も気づかなかった」という解を評価します。
- Citation(引用数) は「コミュニティはどう評価しているか?」を測ります。ただし、単純な引用数ではなく、同時期の論文内でのパーセンタイルに変換して使います。
評価プロンプト
LLMに論文のアブストラクトを読ませ、Originality と Elegance を1-5で評価させました。プロンプトの要点は以下です:
IMPORTANT: Evaluate RELATIVE TO OTHER TOP-CONFERENCE PAPERS,
not compared to average research. Be critical and discriminating.
Most accepted papers should score 2-3, with 4-5 reserved for
truly exceptional work.
## Dimension 1: Originality (Paradigm Shift Potential)
- 5: Defines a new research paradigm. Revolutionary idea. Extremely rare
- 4: Opens a significant new direction. Top 5% of accepted papers
- 3: Solid technical novelty within established paradigms. EXPECTED level
- 2: Competent incremental work. Nothing particularly surprising
- 1: Marginal novelty
Key question: "Would researchers say 'I wish I had thought of that'
or 'That's a natural next step'?"
## Dimension 2: Elegance (Logical Beauty)
- 5: Brilliant simplicity. The solution feels inevitable. Extremely rare
- 4: Clean and well-motivated. Top 10% of papers
- 3: Technically sound but workmanlike. Standard for typical papers
- 2: Somewhat ad-hoc. Multiple components stitched together
- 1: Convoluted or poorly motivated
Key question: "Does the solution feel like it was discovered or constructed?"
CALIBRATION: Score 3 should be your default for solid accepted papers.
Reserve 4+ for papers that genuinely stand out.
課題としては、ICCV2025の論文内で実験したところほとんどが「4点/4点」で判定されてしまいました。これはトップカンファレンス内の母集団だから必然的に良い論文が集まっているためです。
そこで、「トップカンファレンスの中での相対評価」を明示しました。3がデフォルトで、4-5は本当に突出した論文にのみ与えるよう指示しています。
評価はGPT-5.2を使い、ReasoningとしてMediumを加えています。
Step 2: 評価結果を見る
予想外の分布
2119件すべてを評価した結果がこちらです:
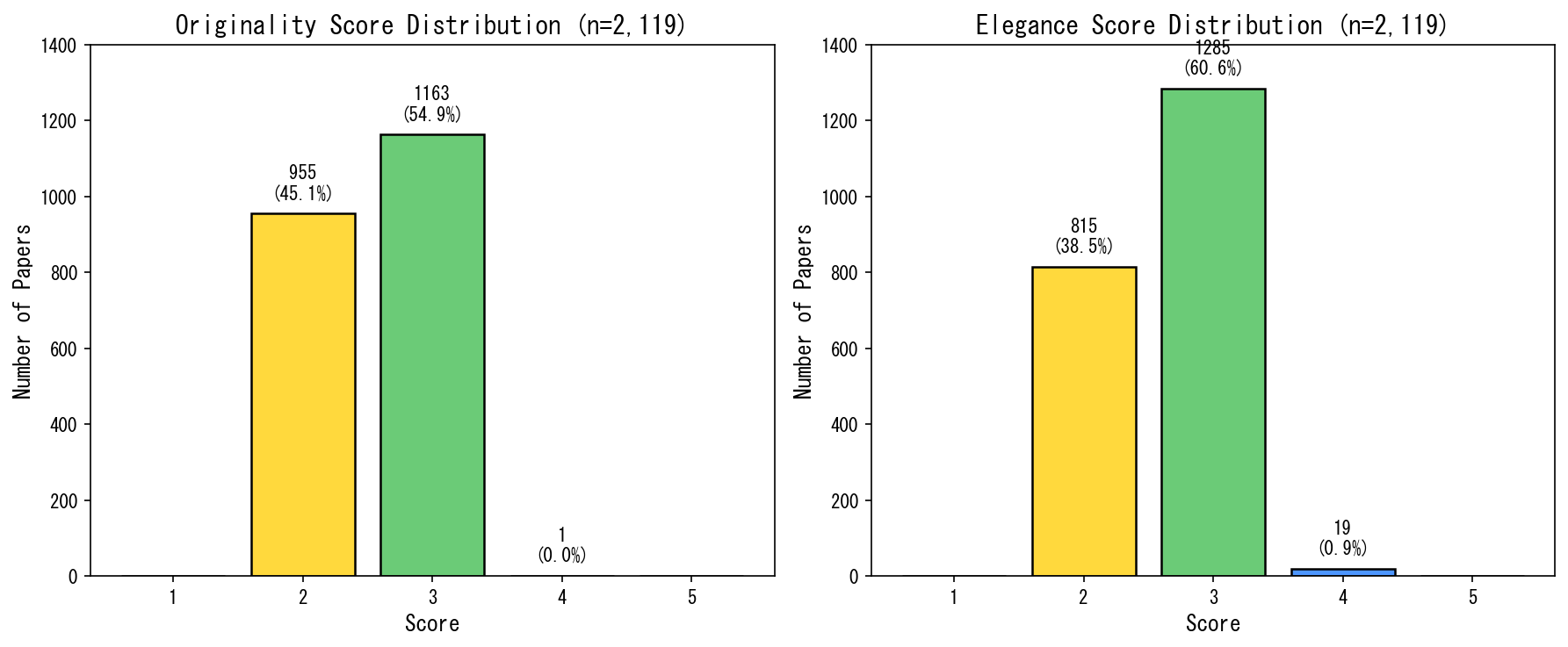
予想: 1-5に均等に分布するだろう
現実: 2-3に集中。4-5はほぼゼロ。
- Originality 5点:0件
- Originality 4点:1件(2119件中)
- Elegance 5点:0件
- Elegance 4点:19件
これをどう解釈するか?
LLMは「普通のトップカンファレンス論文」に3を、「やや弱め」に2を付ける傾向があります。プロンプトで「3がデフォルト」と指示した通りの挙動です。
重要なのは、4以上は本当に希少ということです。
Originality 4以上は1件、Elegance 4以上は19件。両方を合わせてもわずかな数です。
つまり、「4以上」を特別扱いすれば、本当に突出した論文だけを抽出できます。
Step 3: Tier分類の設計
「4以上は希少」を活かす
評価結果の分布を踏まえて、論文を4つのTierに分類することにしました:
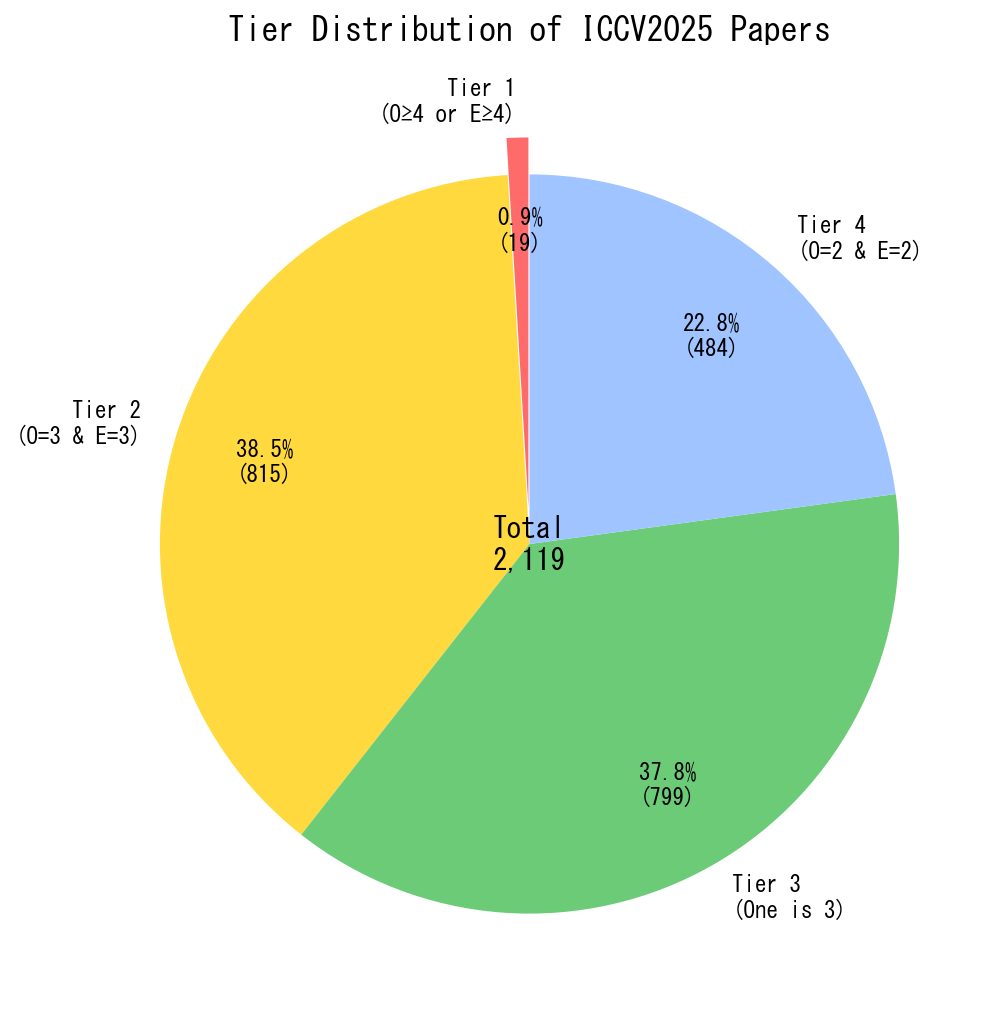
| Tier | 条件 | 件数 |
|---|---|---|
| Tier 1 | O≥4 OR E≥4 | 20件 (0.9%) |
| Tier 2 | O=3 AND E=3 | 815件 (38.5%) |
| Tier 3 | (O=3, E=2) or (O=2, E=3) | 800件 (37.8%) |
| Tier 4 | O=2 AND E=2 | 484件 (22.8%) |
O = Originality, E = Elegance
Tier 1 は「どちらかが突出」した論文です。わずか20件しかありません。
Tier 2 は「両方そこそこ」な高品質論文です。
Tier 3 は「片方は光る」論文です。
Tier 4 は「堅実だが特筆すべき点がない」論文です。
設計のポイント
Tier 1が20件しかないことが重要です。
20件なら全部読んでも大した負担ではありません。つまり、Tier 1は無条件で採用できます。
Tier 2-4については、引用数を加味して優先度を付ければいいのです。
Step 4: 選択戦略の設計
基本式
論文の選択スコアは以下の式で計算します:
selection_score = citation_percentile + tier_bonus
citation_percentile:同時期の論文内での引用数順位(0.0 – 1.0)tier_bonus:Tierに応じた加点
なぜこの式なのか?
citation_percentile だけだと、Tier間の差がつきません。引用数が多ければ、Tier 4でも上位に来てしまいます。
tier_bonus を加えることで、「品質重視」の度合いを調整できます。
3つの戦略
目的に応じて、tier_bonus の設定を変えます:
| 戦略 | Tier1 | Tier2 | Tier3 | Tier4 | 狙い |
|---|---|---|---|---|---|
| quality_first | +1.0 | +0.3 | +0.1 | +0.0 | 革新的な論文を優先 |
| balanced | +0.5 | +0.2 | +0.1 | +0.0 | 品質と注目度のバランス |
| citation_first | +0.2 | +0.1 | +0.05 | +0.0 | 引用数を重視 |
citation_first(Citation Only)については、『AI論文年鑑2025』で実践したので、今回はquality_first, balancedについて検証します。
具体例で理解する
2つの論文を比較してみましょう:
- 論文A:Tier 1(突出した独創性)、引用パーセンタイル 10%
- 論文B:Tier 4(堅実)、引用パーセンタイル 90%
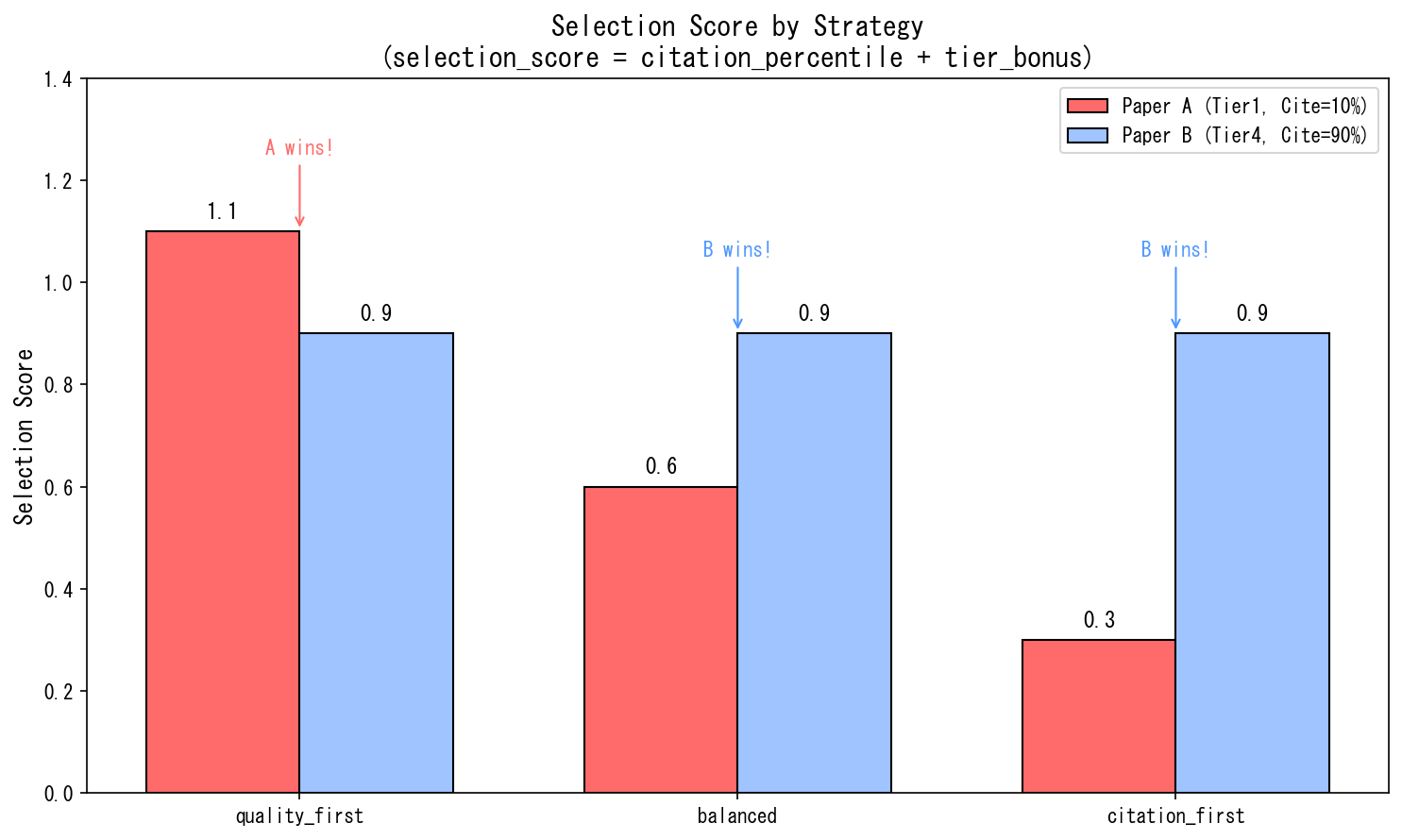
- quality_first では論文Aが上(革新性を重視)
- balanced / citation_first では論文Bが上(注目度を重視)
このように、目的に応じた論文リストを生成できます。
Step 5: 選択結果の違い
200件を選択
quality_first と balanced の2つの戦略で、それぞれ上位200件を選択しました。
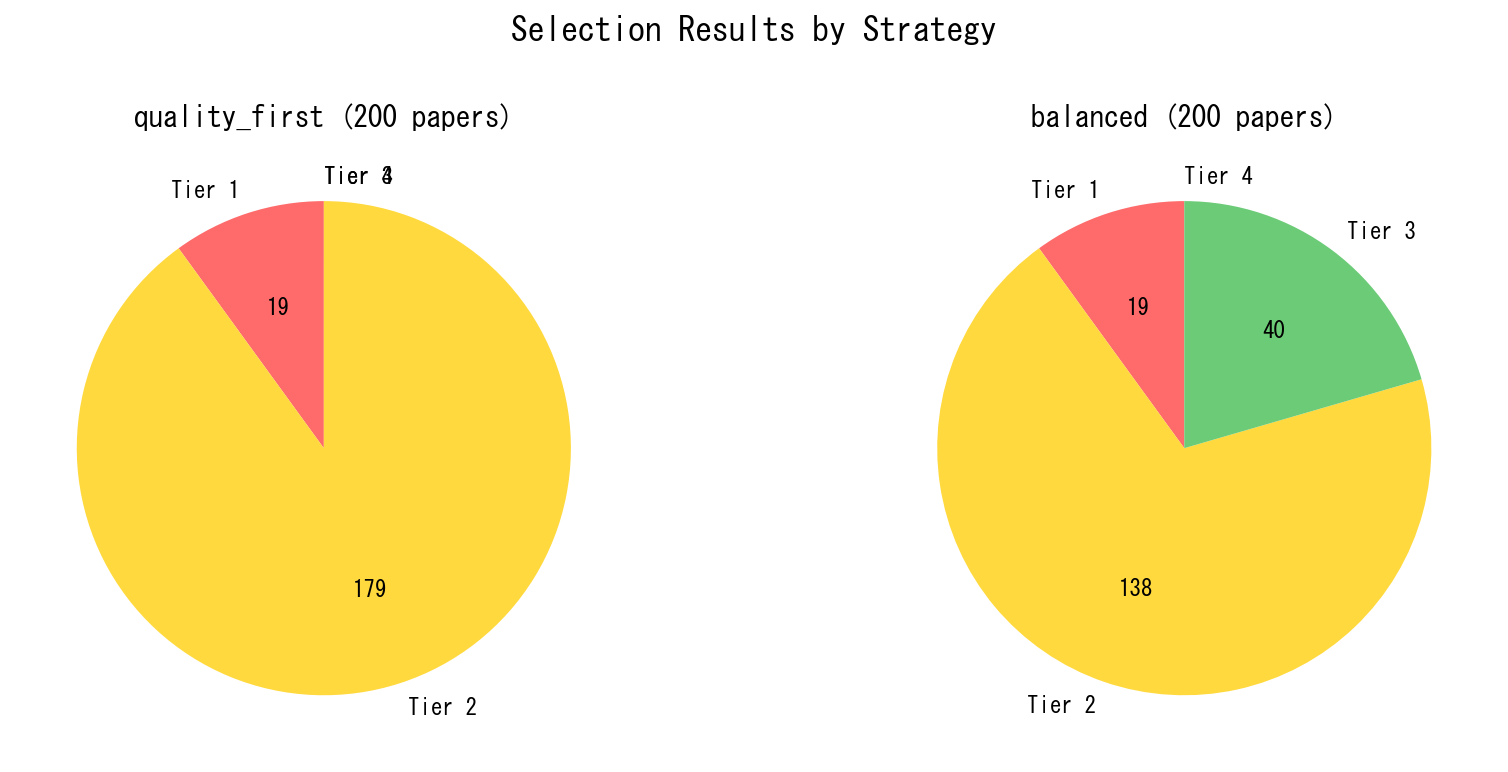
| Tier | quality_first | balanced |
|---|---|---|
| Tier 1 | 20件 | 20件 |
| Tier 2 | 180件 | 139件 |
| Tier 3 | 0件 | 41件 |
| Tier 4 | 0件 | 0件 |
- quality_first ではTier 1-2のみで200件が埋まります。Tier 3は1件も入りません。
- balanced では、引用数の高いTier 3論文が41件入ってきます。代わりにTier 2が減ります。
この違いが、後のトピック分析に影響します。
Step 6: トピック分析(BERTopic)
選択した論文をクラスタリング
選択した200件の論文を、前回同様に、BERTopicでトピッククラスタリングしました。
技術スタック:
- Embedding: OpenAI text-embedding-3-large
- 次元削減: UMAP (15 neighbors, 5 components)
- クラスタリング: HDBSCAN
- ラベル生成: GPT-4o(BERTopicのOpenAIRepresentation)
BERTopicの OpenAIRepresentation を使うと、クラスタの代表文書とキーワードをLLMに渡して、人間が読めるラベルを自動生成できます。
Step 7: トピック結果の違い
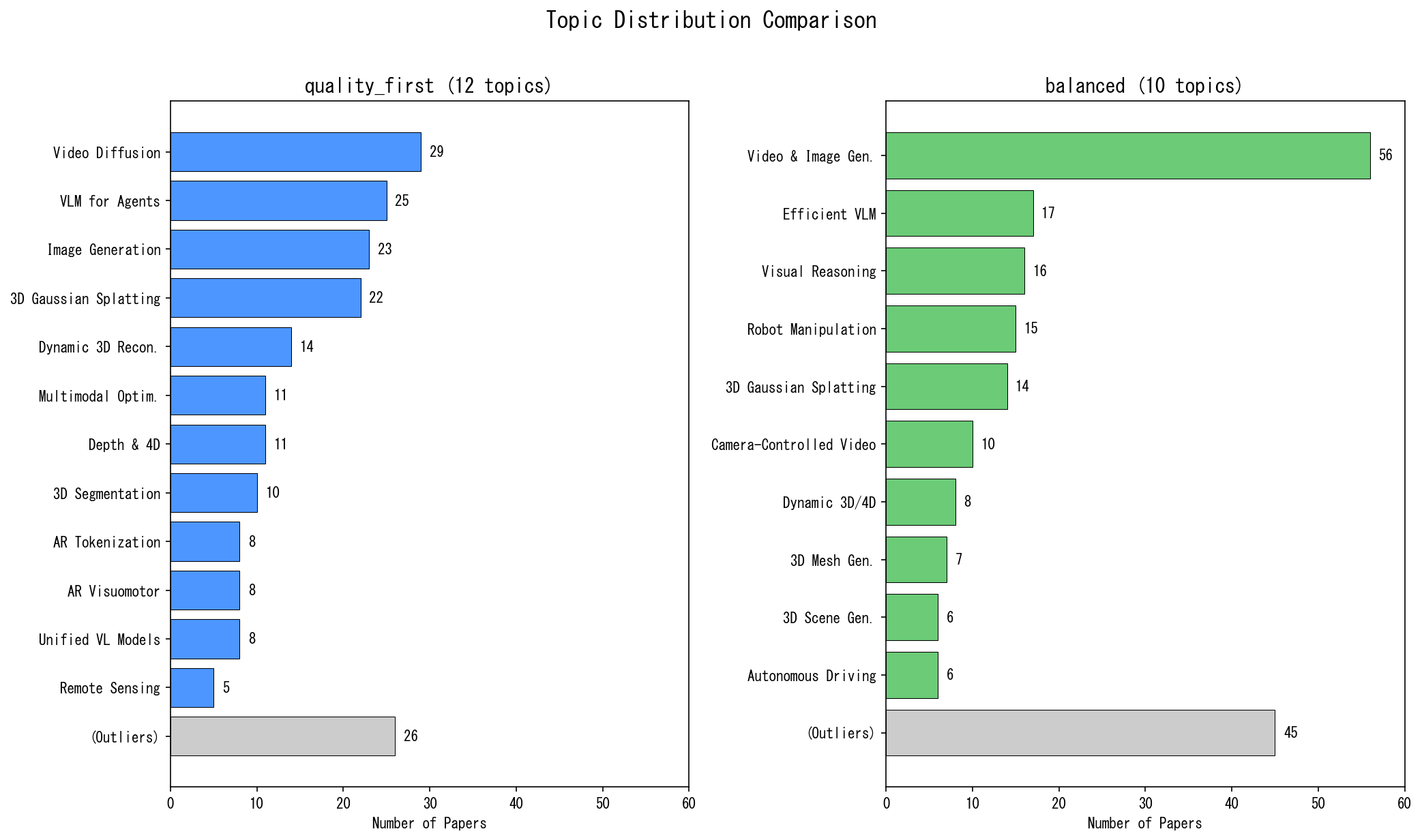
quality_first: 12トピック
| Rank | トピック | 件数 |
|---|---|---|
| 1 | Video Diffusion and Editing Frameworks | 29 |
| 2 | Vision-Language Models for Autonomous Agents | 25 |
| 3 | Advanced Techniques in Image Generation | 23 |
| 4 | 3D Gaussian Splatting Techniques | 22 |
| 5 | Dynamic 3D Scene Reconstruction Methods | 14 |
| – | (その他7トピック + 未分類26件) | 87 |
特徴:
- Video Diffusion、3D Gaussian Splatting、VLMが独立したトピックとして明確に分離しています
- Autoregressive系が2つのトピックに分かれています(Visual Tokenization / Visuomotor Policy)
- 未分類が26件(13%)と比較的少ないです
balanced: 10トピック
| Rank | トピック | 件数 |
|---|---|---|
| 1 | Advanced Video and Image Generation | 56 |
| 2 | Efficient Multimodal Vision-Language Models | 17 |
| 3 | Advancements in Multimodal Visual Reasoning | 16 |
| 4 | Robot Manipulation and Learning Benchmarks | 15 |
| 5 | 3D Gaussian Splatting Techniques | 14 |
| – | (その他5トピック + 未分類45件) | 82 |
特徴:
- 生成系が巨大トピック(56件)に統合されています
- Robot Manipulation、Autonomous Driving が独立トピックとして出現しています
- 未分類が45件(22.5%)と多いです
なぜ違うのか?
balanced では、Tier 3論文(引用数が高いが、独創性/美しさは片方のみ)が41件入ってきます。
これらは「実用化」「効率化」寄りの研究が多いです。結果として:
- 生成系が統合される:革新的な生成手法と効率化手法が同じクラスタに入り、巨大トピック(56件)が形成されます
-
Embodied AI系が独立する:Robot Manipulation、Autonomous Driving といった「実用化」トピックが独立して出現します
-
未分類が増える:Tier 2-3が混在することで、クラスタ境界が曖昧になり、どこにも属さない論文が増えます
quality_first ではTier 1-2のみなので、「革新的手法」同士が細かく分離されます。Video Diffusion と Image Generation が別トピックになり、Autoregressive 系も2つに分かれます。
Step 8: サーベイ生成と比較
同じ質問でサーベイを生成
両方の戦略で、AIエージェントにサーベイを生成させました。
質問:「ICCV2025のトレンドを教えて」
quality_first のサーベイ
quality_firstでは、「支配的なトピック」として以下の3本柱が明確に示されます:
ICCV2025の高品質論文(Originality/Elegance評価上位200件)は12のトピックに分類され、以下の3つの主要な研究領域が顕著です:
- 生成AI・Diffusionモデルの進化(52件, 26%)
- 3D理解・再構成技術(46件, 23%)
- Vision-Languageの統合とエージェント化(44件, 22%)
また、「横断的な技術トレンド」として、複数トピックに共通するパターンを抽出しています:
- Flow Matching / Rectified Flow: Diffusion Transformer (DiT)系の研究で標準化
- 3D Attention & Token Concatenation: source/target video latentsをframe次元で連結し3D attentionで混合
- Self-Supervised Learning & Foundation Model転用: 大規模事前学習モデルを最小変更で新タスクに適用
- Test-Time Compute Scaling: 推論時計算の戦略的配分
balanced のサーベイ
balancedでは、「効率化」と「実用化」という視点が前面に出ます:
今年の高品質論文における最も顕著な特徴は、生成モデルとマルチモーダル理解の融合です。特に以下の3つの軸が明確に浮かび上がっています:
- 効率化の追求:Diffusionモデルの蒸留、トークン削減、量子化など、実用化に向けた計算コスト削減
- 3D理解の深化:Gaussian Splattingを中心とした新しい3D表現
- 具体化AI(Embodied AI):ロボット操作、自動運転など、実世界タスクへの応用
また、個別トピックでも「実用化の視点」が強調されています。例えばVLMのセクションでは:
動画VLMの計算コスト:多数フレームが長大なトークン系列を生成し、アテンション計算とKVキャッシュが爆発的に増加
トレーニングフリー加速:STTM (Spatio-Temporal Token Merging)は空間・時間の両次元で冗長性を削減
ぶっちゃけ、どう違うか
- quality_first:「何が革新的か」がわかります。最先端の技術が見えやすいです。
- balanced:「何が活発か」がわかります。研究コミュニティで注目されているテーマが見えやすいです。
考察:使い分けと限界
使い分け
| 目的 | 推奨戦略 |
|---|---|
| 革新的な研究を知りたい | quality_first |
| コミュニティのトレンドを知りたい | balanced |
| 引用されている研究を知りたい | citation_first |
| まだ注目されていない面白い論文を探したい | Tier 2-3 で Citation 低め |
この手法の限界
- LLMの評価は完璧ではない
- 4-5がほぼ出ないのは、LLMが「保守的」だからです
- アブストラクトだけでは判断できない要素もあります
- トピック数はパラメータ依存
- HDBSCANの
min_cluster_sizeで変わります - 「正しいトピック数」は存在しません
- HDBSCANの
- 引用数の時間依存性がある
- 新しい論文は引用が少ないです
- パーセンタイル化で緩和していますが、完全ではありません
今後の展望
- 時系列分析(年ごとのトレンド変化)
- 他の会議(CVPR、NeurIPS)への適用
- 「ダークホース」発掘の精度評価
まとめ
- LLMで論文を評価し、Tier分類を設計しました
- Originality と Elegance を1-5で評価
- 4以上は希少(20件)→ 無条件採用可能
- 引用数と組み合わせて選択戦略を設計しました
selection_score = citation_percentile + tier_bonus- quality_first / balanced / citation_first の3戦略
- 戦略の違いがトピック分析に影響することを確認しました
- quality_first:革新的手法が細分化
- balanced:実用化研究が独立トピックに
- 目的に応じた使い分けができます
- 革新性を知りたい → quality_first
- トレンドを知りたい → balanced
「良い論文とは何か」を定義することで、大量の論文から目的に合った論文を抽出できるようになりました。
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー