
論文まとめ:Collaborative Neural Rendering using Anime Character Sheets


- タイトル:Collaborative Neural Rendering using Anime Character Sheets
- 論文URL:https://arxiv.org/abs/2207.05378
- コード:https://github.com/megvii-research/CONR
- 所属:Megvii、武漢大学
目次
ざっくりいうと
- 数枚のアニメキャラクター画像と、ポーズのマップから、任意のポーズのキャラクター画像をレンダリングするのを目的とした研究
- UVマップを使わず、3次元ワールド座標系でのランドマーク点の対応を計算する「Ultra-Dense Pose (UDP)」というポーズマップを新たに導入し、あたかも画像間転移として扱える
- 参照画像の順序を保証しないのがキモで、これにはデコーダーに「CINN」という協調推論を伴ったネットワーク構造を導入
- UVマップのような2次元→3次元の対応を使うことなく、NeRFで難しかった髪型やアクセサリといった細かいパーツに対してもロバストになった
入力と出力
- CoNRのインプット
- RGBのキャラクターシート(イラスト)
- 「UDP」というポーズマップ(画像として扱える)
- CoNRのアウトプット
- 任意のポーズでレンダリングされたキャラクター画像

モチベーション
- アニメ制作で、キャラクターを任意のポーズで描画することは不可欠だが、手間のかかる作業
- アニメ産業の慣習的には、複数の参照画像からアニメーターが描いているが、同じプロセスをニューラルネットワークベースで定義したい
この研究の貢献
- アニメキャラクターのために設計されたUDP表現を導入し、多様なポーズを含む大規模なキャラクターシートのデータセットを構築
- データセットを公開する予定(Coming soonなので本当?)
- キャラクターシートを動的なサイズの画像集合としてモデル化するために、フィードフォワードニューラルネットワークの協調推論手法を検討
関連研究
生成モデルベース
- StyleGAN2 を改良したモデルは、身体の一部が奇妙につながるなどのアーティファクトに悩まされながらも、アニメの全身画像を生成可能なことが実証済み
人間のポーズと外見の転移
- 人間のポーズと外観の転移はかなりメジャー
- 多くは、1枚の画像から体の動きやトーキングヘッド(VTuberのような喋っている頭部動画)を生成するもの
- CLIPなどの巨大なデータセットで学習したモデルは、人気のあるアニメのキャラクターデザインをを暗黙的に符号化できるかもしれないが、アニメキャラクターの領域では外観やスタイルを確立することが困難
- NeRF は、光線追跡法(Ray-marching) を用いて3D 描画を行うため、対象物以外の事前知識に依存せず、実世界の3Dデータのモデリングに有望な手法。しかし、アニメのキャラクター画像のように、幾何学的・物理的な制約にあまり従わない手描きデータのモデリングには、まだあまり進展がない。
人間の姿勢の表現
- 代表例:
- 骨格の棒グラフ
- SMPL ベクトル
- 関節のヒートマップ
- これらの疎な表現を人間→アニメに移行する際には、ノイズの多い手動アノテーション、多様なスタイルの衣服、他の身体装飾によるオクルージョンなどに悩まされる
- アニメのキャラクターは、人間の関節が直接駆動しない髪やスカートなどの可動部を誇張し、細かいディテールやポーズを柔軟に制御する必要がある
- DensePoseとUVテクスチャマッピングは,3D人体表面を2D座標系に展開する定義を課すことによって,人体や顔の姿勢表現の詳細を大幅に向上させる
- アニメのキャラクターが、UVテクスチャマッピングに応じてアノテーションを行うようになると、3つの問題が生じる
- 女の子のキャラ:スカートのような円錐状の物体で、平面の正確な位置を見つけるのに苦労する
- 男の子のキャラ:ジーンズやキルトなど、非ホメオタイプの体型をどう一貫して扱えばいいのかわからない
- 装飾品:ウサギ耳やネコ耳はポイント数がわからない。アニメキャラクターの体型は多様であり、体の部位によって必要なキーポイントの数が異なる
手法
タスクの定式化
- Itとは同一のキャラクターで、異なるポーズのRGB画像。
- アニメーターが描くとき、キャラクターシートの複数の画像を参照する。キャラクターシートから一連の参照画像I1…Inが与えられると、アニメ画像を描く人間のアーティストは、各Itを見た後にキャンバス上で一連の操作を行う
- ユーザが推論時にシーケンスに入れることから解放されるためには、キャラクタシートで任意の順序を許容することが望ましい
$I_n$の順序を無視した$S_{ref}$を考える。目的のポーズを$P_{target}$¥としたときに、ターゲットの画像$y$は以下のように定式化できる。
$$y = f(P_{tar}, S_{ref})$$
複雑なポーズ,モーション,キャラクタは,Srefの参照数を他より多く必要。$S_{ref}$のサイズを動的に変更できるべき
キャラクターシートのモデリング
- PointNet[38]とEquivariant-SFM[34]に触発されたCollaborative Inference for convolutional Neural Networks (CINN) を利用
- 古典的な畳み込みニューラルネットワーク(CNN)に、複数の画像を任意の順番で入力し、対応する推論結果を得ることができる。
CINNでは、集合内の複数の画像は、全体として一つの入力サンプルとして定義される。複数のCNNの対応するブロックの出力に特徴平均をかけると、動的な数のサブネットワークからなるネットワークが得られる。サブネットワークは同じ重みを共有し、メッセージパッシング機構によって相互に接続される。加算の可換性により、サブネットワークの順序を変えても推論結果には影響しない。このようなネットワーク上で協調推論を行う場合、セット内のn個の参照画像(またはビュー)が、それぞれn個の重み共有サブネットワークに供給される。
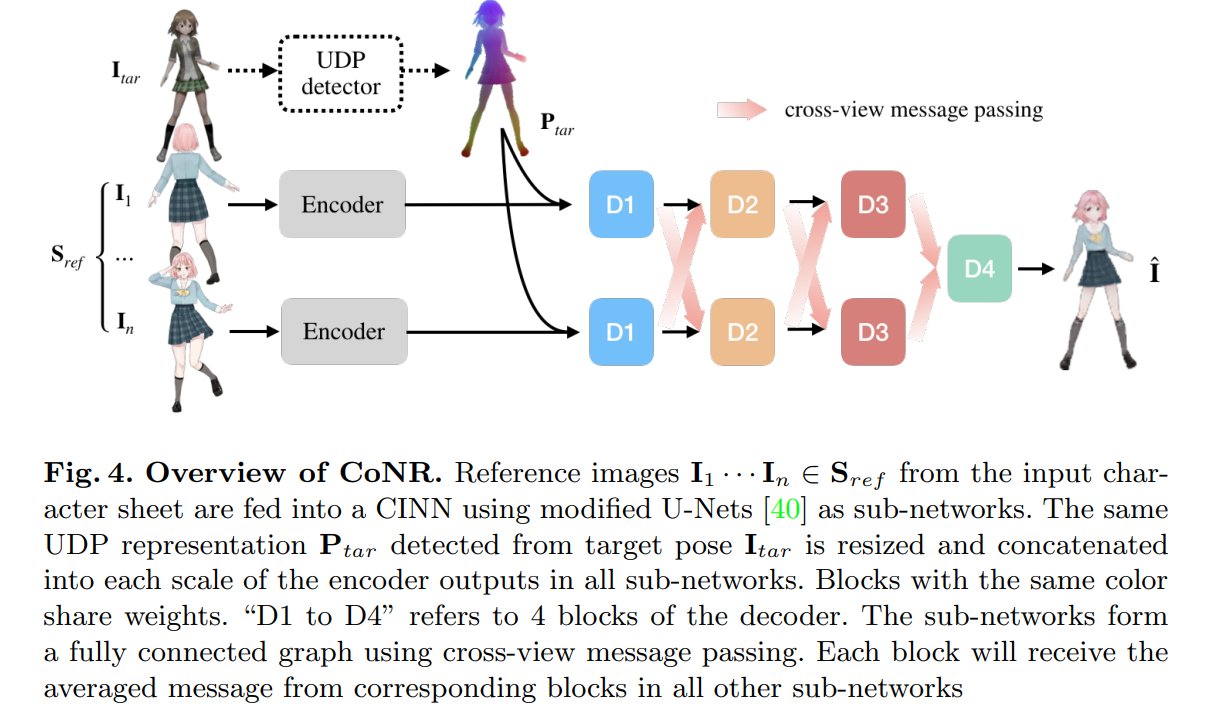
→重み付き平均によって順序の無視を保証(加算の可換性)
Ultra-Dense Pose

UDP:アニメキャラクターのために設計されたコンパクトなランドマーク表現
UDPは、2次元ビューポート座標と特徴ベクトル(3タプルの浮動小数点数)の対応付けにより、キャラクターの姿勢を指定
- ランドマークの座標$L_{(x, y)}$ごとの姿勢の$(X, Y, Z)$のパラメータ
- 姿勢のパラメーターはピクセルとみなせるので、UDPはカラー画像として扱える
- 出てくる$P_{tar}$は$\mathbb{R}^{H\times W\times 3}$になる
既存の方法:3Dメッシュ
- 対応するテクスチャ座標$(u, v)$または頂点色$(r, g, b)$で構成
- バリセントリック座標を補間することで、テクスチャ座標から求めた色値やピクセルで塗りつぶされた三角形の面が形成
- UDPのいいところ:よく使われている2DのUVテクスチャマッピングで行われている、3D→2Dの投射のステップを省略できる
UDPを構築するために、元のテクスチャを取り除き、各頂点の色(r、g、b)をランドマークで上書きし、現在のワールド座標(x、y、z)とする。アニメのボディが姿勢を変えたとき、メッシュ上の頂点はワールド座標系で新しい位置に移動しても、対応するボディ部分のランドマークは変わらず、同じ色で示される
UDP表現は0から1までの浮動小数点数で記録されたH×W×4型の画像となる。4つのチャンネルには3つのボディランドマークエンコーディングと、そのピクセルが身体上にあるかどうかを示すための1つの占有率が含まれる。
データの準備
- 公開データセットから人間に似たキャラクターを選択し、2万以上の手描きのアニメキャラクターを含むデータセットを作成
- 機械的なアルゴリズム+手動で背景除去(Matting)をして、人間のみ切り出す
-
手描きのアニメ画像にUDPで手動でアノテーションを行うことは、耐え難いレベルの苦痛
- アニメ調の3次元メッシュを合成したデータセットを作成し、ラベル不足の問題を解決した
- 最後に、高品質なUDPラベルを持つ合成データセットと、スタイルやキャラクターの多様性が高い手描きデータセットを16:1の割合
- ここで使っているのは、ポーズを変えたときのワールド座標系でのランドマークの移動マップとして、UDPを機械的に作成する方法
Collaborative Neural Rendering
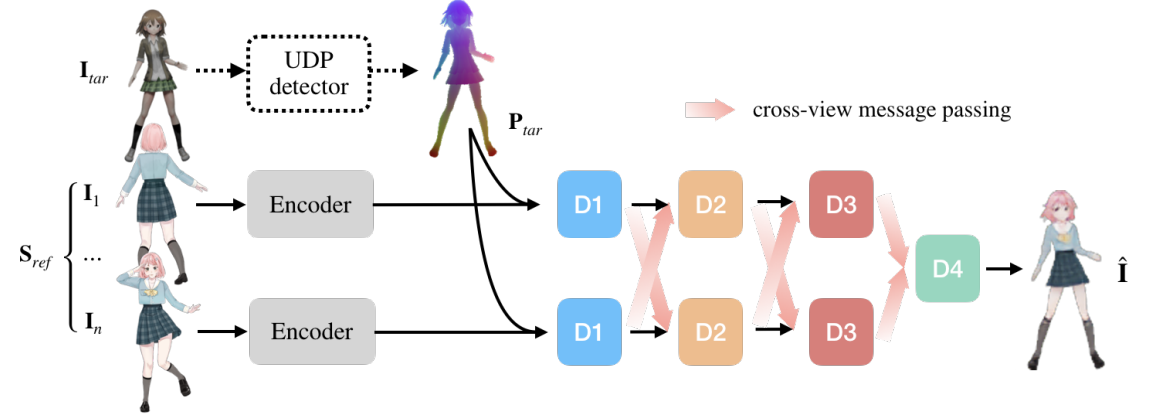
UDP Detector:ResNet50+U-Net
- アニメーションのような検出では、$P_{tar}$を推定するようなニューラルベース
- ゲームやインタラクティブなアプリケーションでは、3Dの物理エンジンから直接計算可能
レンダラー:U-Netベース
- UDP入力を削除し、代わりにニアレストサンプリング法で再スケーリングしたUDP入力をエンコーダからデコーダまでの各スキップチャネルに連結
- CNNの長距離探索能力を高めるため、各デコーダブロックにおいて、フローフィールドを生成
- CINN法をネットワークのデコーダに適用(以下の図参照)
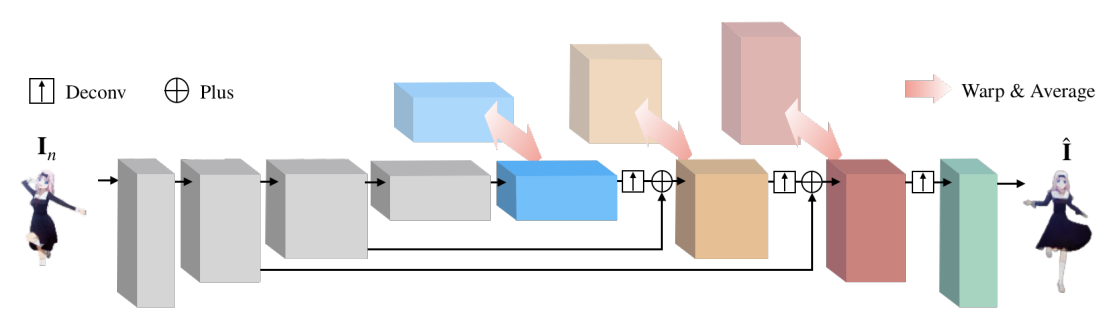
実験
損失関数
以下の5つの項目を組み合わせたもの
- UDPのロス:UDP Detectorの推定ポーズ$\hat{P}{tar}$と、GTの$P^{GT}{tar}$のL1ロス
- maskのロス:UDPの背景/人間のBCE
- UDPのConsistency loss:ランダムな背景にキャラをコピペしたときの、$\hat{P}$間の標準偏差(正則化項)
- photoのロス:レンダリング後($\Phi(\hat{P}{tar}, S{ref})$)のRGB画像と、GTのRGB画像($I_{tar}^{GT}$)のL1ロス
- Perceptualロス:photoのロスのLPIPS版
計算量
128×128の解像度で、4GPUで1週間
結果
参照画像が増えると生成結果が良くなる
青が与えた画像、赤が生成結果。参照画像で見えていない部分は当然ながら描画に失敗する

実写のポーズを参照とすることも可能
2段目が従来の手法(SMPL-based)、3段目が提案手法。スカートの描画がより正確になっている

参照画像はキャラクターあたりFew-shotでできるため、実際のアニメーション制作において有効に機能すると主張している。
アブレーション
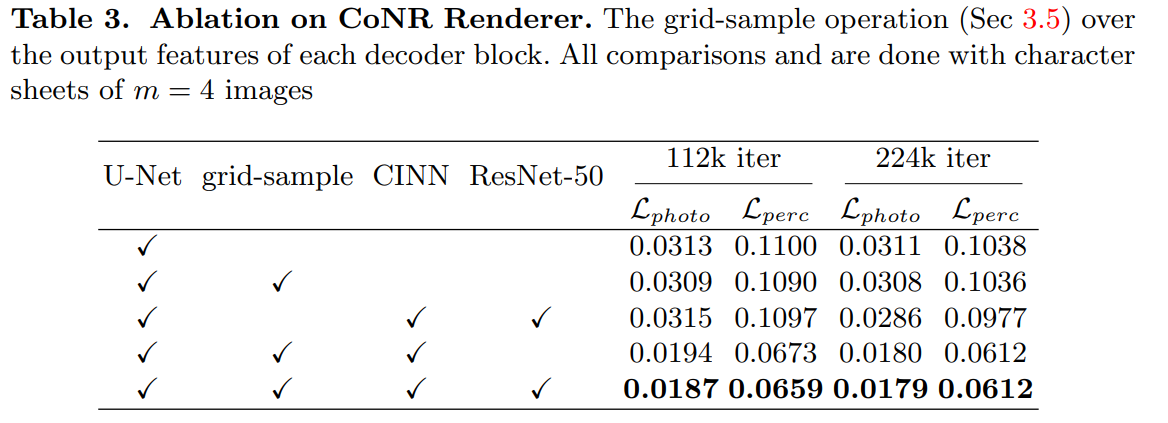
CINNが特に効いており、参照画像の順序を保証しないことが重要。
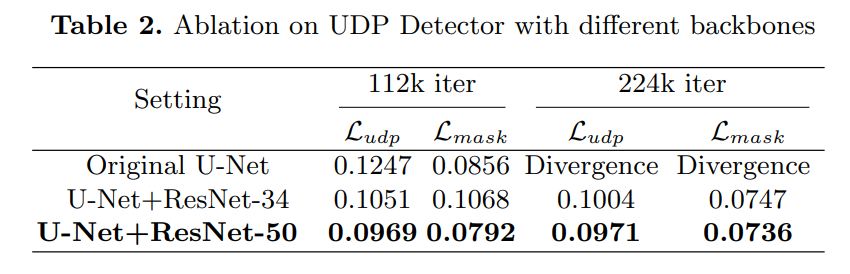
ResNetがないとUDP Detectorのロスが発散する。
手法の限界
環境照明効果を反映できない。今後の研究に期待
まとめと感想
- UDPという画像として扱えるようなポーズマップを提案。3DのレンダリングをあたかもImage-to-Image Translationのように扱えている
- 参照画像の順序を保証しないことが重要で、実装的にはCINNという構造をデコーダーに追加し、加算の可換性により保証する
- データを公開するらしいが、いつ公開するのだろうか?
- NeRFベースや、3Dメッシュよりもかなり発想的にはわかりやすく、一見難しそうな3Dの問題を簡単に解けそうでなかなか面白い内容だった
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー