
Kerasで複数のラベル(出力)があるモデルを訓練する


Kerasで複数のラベル(出力)のあるモデルを訓練することを考えます。ここでの複数のラベルとは、あるラベルとそれに付随する情報が送られてきて、それを同時に損失関数で計算する例です。これを見ていきましょう。
目次
問題設定
MNISTの分類で、ラベルが奇数のときだけ損失を評価し(categorical_crossentropy)、偶数のときは損失0として考える問題を想定します。
この実装方法以外にもやり方はあると思いますが、今回はいつもの(バッチサイズ, 10)の「どの数字を表すか」というラベルの横に、もう1列「奇数かどうかの」ラベルを作ります。次のようなイメージです。
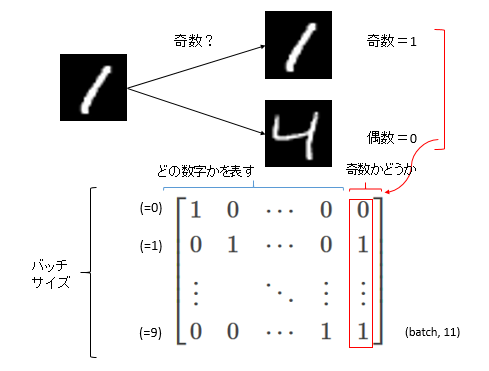
今回作るラベルは(バッチサイズ, 11)のshapeになります。1~10列目はどの数字を表すかというOne-hotベクトル、11列目は奇数かどうかのベクトルになります。例えば、1という数字だった場合、2列目は1で1列目と3~10列目は0、11列目は奇数なので1となります。4という数字だった場合、5列目は1で1~4列目と6~10列目は0、11列目は偶数なので0となります。このようなラベルデータです。
もう少し一般的に考えると、この「奇数かどうか」というラベルは、ラベルを評価する際に付随する情報(条件)とも考えることができます。複数出力というと馴染みが薄いかもしれませんが、このように考えると意外と使うケースがあるのではないかと思います。
さて、このラベルの列数は11ですが、分類問題の出力ニューロン数は10なので、ラベルデータと予測値にデータ数のミスマッチを起こします。そこはカスタム損失関数を定義して処理します。具体的な実装をこれから見ていきます。
実装
モデルを作る
まずはモデルを作ります。今回は簡単な多層パーセプトロンとしました。これはラベルの種類が増えようが普通のMNISTの例と同じで、出力のニューロンは10となります。
from keras.layers import Dense, Input, Flatten
from keras.models import Model
from keras.datasets import mnist
from keras.utils import to_categorical
from keras.objectives import categorical_crossentropy
import numpy as np
def make_model():
input = Input(shape=(28, 28))
x = Flatten()(input)
x = Dense(64, activation="relu")(x)
x = Dense(10, activation="softmax")(x)
return Model(input, x)
これはいつものモデルなので特にいいですね。
データのジェネレーター
データをモデルに流し込むジェネレーターも自作してみました。わかりづらかったら、yの行列を事前にフルバッチでnumpyベースで合体させても良いと思います。
def generator(X, y, batch_size, train):
X_batch, y_batch = [], []
indices = np.arange(X.shape[0])
while True:
if train:
np.random.shuffle(indices)
for i in range(len(indices) // batch_size):
current_indices = indices[i*batch_size:(i+1)*batch_size]
X_batch = X[current_indices] / 255.0
y_batch_label = to_categorical(y[current_indices], num_classes=10)
y_batch_is_odd = np.expand_dims(y[current_indices] % 2 == 1, axis=-1).astype(np.float32)
y_batch = np.c_[y_batch_label, y_batch_is_odd]
yield X_batch, y_batch
インデックスのベクトルを定義し、そのインデックスからスライスさせることでバッチを生成しています。訓練データを食わせる場合はシャッフルさせています。
複数ラベルの生成部分は「y_batch_labelとy_batch_is_odd」の部分です。keras.utilsの「to_categorical関数」を使って数字をone-hotな表現にしています。これは1~10列目に相当します。「y_batch_is_odd」は奇数かどうかを表すもので、True, Falseで帰ってきた値をfloatでキャストすることで1.0と0.0に変換しています。また、スライスだとランク1のテンソルになってしまうため、後の結合を考えて「np.expand_dims関数」でランク2に戻しています。そのあと、y_batchを列方向につなげることで(np.c_)データのジェネレーターが完成します。
ジェネレーターを作ることは必須ではないので、わかりづらかったら、y全体を結合するとかでもいいと思います。
損失関数の自作
ここは必須です。デフォルトの損失関数だと、出力ユニットの数とラベルデータの数が等しい場合しか想定していないのでエラーが出ます。つまり、損失関数の中で列方向のスライスをする必要があります。
def loss_function(y_true_combined, y_pred):
y_true, is_odd = y_true_combined[:, :10], y_true_combined[:, 10]
return categorical_crossentropy(y_true, y_pred) * is_odd
y_true_combinedという(バッチサイズ, 11)の形式で与えられるテンソルをスライスします。ちなみにy_predは(バッチサイズ, 10)の形式で返ってきます。スライスは基本的にはNumpyベースと変わりません。y_trueは(バッチサイズ, 10)という形式、is_oddは(バッチサイズ, )という形式にそれぞれなります。y_true_combinedはランク2であったのに、is_oddがランク1に落ちることがポイントですね。
次に、keras.objectivesのcategorical_crossentropyを使い、通常のMNISTの分類と同じ交差エントロピーを計算します。keras.backendにもcategorical_crossentropyの関数はありますが、objectivesのほうは計算結果のランクが入力のランク-1される(つまりこの場合はランク1で返ってくる)、backendのほうはランクが落ちない(今回は使いませんでしたがランク2で返ってくる)という違いがあります。今回はobjectivesの交差エントロピーを使っているので、is_oddとランク1のテンソル同士の積を計算しています。
Kerasの損失関数は基本的にはサンプル単位で返してあげればあとは勝手にやってくれる(サンプル単位で荷重をかけたりすることが想定されているそうです)ので、サンプル単位で集計したランク1のテンソルを返す実装でOKです。
訓練と評価
少し長めのコードになってしまいましたが、訓練とモデルの評価をします。今回のケースでは、偶数の場合は全く訓練されないので(偶数ではis_odd=0となり、どのような場合でも損失=0となり学習が進まないから)、偶数の場合は分類精度が極端に低くなることが想定されます。それを確認しています。
from sklearn.metrics import confusion_matrix, accuracy_score
def train_eval():
(X, y), (_, _) = mnist.load_data()
model = make_model()
model.compile("adam", loss=loss_function)
model.fit_generator(generator(X, y, 128, True), 60000//128, epochs=3)
X_even, X_odd = X[y % 2 == 0], X[y % 2 == 1]
y_true_even, y_true_odd = y[y % 2 == 0], y[y % 2 == 1]
y_pred_even = np.argmax(model.predict(X_even), axis=1)
y_pred_odd = np.argmax(model.predict(X_odd), axis=1)
print("Even result")
print("acc =", accuracy_score(y_true_even, y_pred_even))
print(confusion_matrix(y_true_even, y_pred_even))
print(np.bincount(y_true_even))
print(np.bincount(y_pred_even))
print()
print("Odd result")
print("acc =", accuracy_score(y_true_odd, y_pred_odd))
print(confusion_matrix(y_true_odd, y_pred_odd))
print(np.bincount(y_true_odd))
print(np.bincount(y_pred_odd))
if __name__ == "__main__":
train_eval()
偶数、奇数に対して、精度と混同行列、真の値と推定値の分布を調べています。それぞれSklearnの関数を使っています。
では結果を見てみましょう。
468/468 [==============================] - 1s 2ms/step - loss: 0.1372
Epoch 2/3
468/468 [==============================] - 1s 2ms/step - loss: 0.0562
Epoch 3/3
468/468 [==============================] - 1s 2ms/step - loss: 0.0416
Even result
acc = 0.0
[[ 0 2 0 690 0 4431 0 69 0 731]
[ 0 0 0 0 0 0 0 0 0 0]
[ 0 910 0 4314 0 149 0 453 0 132]
[ 0 0 0 0 0 0 0 0 0 0]
[ 0 78 0 77 0 103 0 129 0 5455]
[ 0 0 0 0 0 0 0 0 0 0]
[ 0 309 0 725 0 3426 0 49 0 1409]
[ 0 0 0 0 0 0 0 0 0 0]
[ 0 416 0 3336 0 1112 0 43 0 944]
[ 0 0 0 0 0 0 0 0 0 0]]
[5923 0 5958 0 5842 0 5918 0 5851]
[ 0 1715 0 9142 0 9221 0 743 0 8671]
Odd result
acc = 0.9790546741838206
[[6699 24 4 7 8]
[ 14 6049 21 24 23]
[ 12 149 5217 9 34]
[ 28 49 11 6082 95]
[ 20 59 19 29 5822]]
[ 0 6742 0 6131 0 5421 0 6265 0 5949]
[ 0 6773 0 6330 0 5272 0 6151 0 5982]
順調にLossが減って訓練が進んでいるものの、偶数の精度は0%となって、奇数の精度は約98%となりました。想定どおりの結果になったことを確認できました。
全体のコード
全体のコードをgistに上げました。
まとめ
複数のラベル(またはラベルに付随する条件)を訓練したいときは、あたかも1つのラベルのように大きなラベルデータに放り込み、損失関数を独自に定義し、損失関数内でスライスして計算するのと楽というのがわかりました。
全てがこのように簡単にできるとは限りませんが、自分は複数のラベルをサンプル単位で直交化させたほうが楽ではないかなと思います。
以上です。これができるとモデル構築の柔軟性が上がって様々な例に応用できるので、ぜひ活用してくださいね。
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー