
VOICEVOXをPythonから利用し、wavファイルで保存する方法[AzureとGoogle Cloudの比較あり]

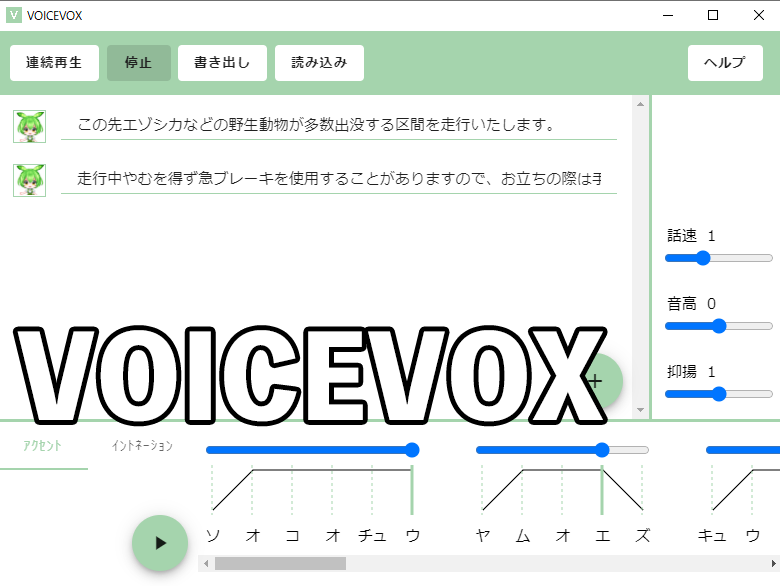
PythonからVOICEVOXの音声を合成する方法を紹介します。VOICEVOXの合成音声を、Azure Text to SpeechやGoogle CloudのText-to-speechとも比較してみました。GoogleやAzureと場合によっては互角になりうる期待のソフトウェアです。
目次
VOICEVOX
VOICEVOX、皆さん使ってますか? 2021年8月ごろに彗星のように登場した、無料なのにかなり優秀な音声合成ソフトウェアです。
今回Pythonから使いたかったのですが、コードベースで使う解説記事がどこにもなかったので書いてみました。
https://voicevox.hiroshiba.jp/
GUIでの使い方は解説されている記事が多いので、この記事ではPythonからコマンドラインベースで音声を出力する方法を書いていきます。インストールのやり方は省略します。
VOICEVOX ENGINE
VOICEVOXのGUIはElectronで作られています。音声合成のコアの部分はPyTorchをベースに、ローカルサーバーで行っています。ソフトを立ち上げると自動的にサーバーも立ち上がります。
コアのサーバーの部分を「VOICEVOX ENGINE」と呼びます。GitHubではCurlを用いて音声合成をするサンプルコードが掲載されています。
https://github.com/Hiroshiba/voicevox_engine
VOICEVOXのGUIを起動中(サーバーを起動中)にhttp://localhost:50021/docsにアクセスすると、APIリファレンスを閲覧できます。

APIのエンドポイントは「http://localhost:50021 」です。いくつかAPIがありますが、音声合成に使うAPIは以下の2つです。
- POST /audio_query
- POST /synthesis
「/audio_query」で、日本語→母音や子音の分解、フレーズやアクセントの検出を行います。「/synthesis」ではそれらの情報を元に音声を合成します。
Pythonコードサンプル
import requests
import json
import time
# VoicevoxでText to Speechするやつ
def synthesis(text, filename, speaker=1, max_retry=20):
# Internal Server Error(500)が出ることがあるのでリトライする
# (HTTPAdapterのretryはうまくいかなかったので独自実装)
# connect timeoutは10秒、read timeoutは300秒に設定(処理が重いので長めにとっておく)
# audio_query
query_payload = {"text": text, "speaker": speaker}
for query_i in range(max_retry):
r = requests.post("http://localhost:50021/audio_query",
params=query_payload, timeout=(10.0, 300.0))
if r.status_code == 200:
query_data = r.json()
break
time.sleep(1)
else:
raise ConnectionError("リトライ回数が上限に到達しました。 audio_query : ", filename, "/", text[:30], r.text)
# synthesis
synth_payload = {"speaker": speaker}
for synth_i in range(max_retry):
r = requests.post("http://localhost:50021/synthesis", params=synth_payload,
data=json.dumps(query_data), timeout=(10.0, 300.0))
if r.status_code == 200:
with open(filename, "wb") as fp:
fp.write(r.content)
print(f"{filename} は query={query_i+1}回, synthesis={synth_i+1}回のリトライで正常に保存されました")
break
time.sleep(1)
else:
raise ConnectionError("リトライ回数が上限に到達しました。 synthesis : ", filename, "/", text[:30], r,text)
def text_to_speech():
# ※テキストはイメージです
texts = [
"この列車は、函館線、宗谷線直通、特急宗谷号・稚内行です。",
"停車駅は岩見沢、美唄、砂川、滝川、深川、旭川、和寒、士別、名寄、美深、音威子府、天塩中川、幌延、豊富、南稚内、終着・稚内です。",
"列車は前から1号車、2号車、3号車、4号車です。車内は全て禁煙で、自由席は4号車です。",
"この列車では車内販売を行いません。また、車内には自動販売機もありません。"
]
for i, t in enumerate(texts):
synthesis(t, f"audio_{i}.wav")
リクエストの際はrequestsライブラリを使っています。
VOICEVOXは開発中ということもあり、長文を入力すると、サーバー側で「500 Internal Server Error」を吐くことが多いです(v0.2.0時点)。これはサーバーの状態によって発生したりしなかったりするので、現状はリトライで根気強く200を返すのを狙うのがいいのではないかなと思います。ローカルサーバーなのでリトライしまくっても迷惑かけないのが安心できますね。
リトライ処理ははじめこちらのようにHTTPAdapterとRetryで実装しましたが、リトライ数が足りないのかすぐ500エラーで例外になってしまったため、forループで自分で実装しました。それでもログを読んだらかなりの回数リトライが必要でした。synthesis関数のmax_retryを大目にとっておくといいかもしれませんね。
audio_0.wav は query=1回, synthesis=18回のリトライで正常に保存されました
audio_1.wav は query=5回, synthesis=14回のリトライで正常に保存されました
audio_2.wav は query=5回, synthesis=19回のリトライで正常に保存されました
audio_3.wav は query=1回, synthesis=2回のリトライで正常に保存されました
追記:このケースはエンジンがGPUの場合です。リトライの必要回数はGPUの状態に強く依存します。例えば、VOICEVOXの起動直後はリトライ1で音声が書き出せても、何度も推論しているうちにリトライ回数が多く必要になることがあります。また、エンジンをCPUにすると単体の推論時間は増えますが、安定して書き出せます。GPUで何度もリトライするのだったら、結果的にはCPUをエンジンにしたほうが速いかもしれません。v0.3以降、GUIからエンジンの切り替えが容易にできるようになりました(要:再起動)
個々のAPI部分ですが、audio_queryはデータを「params」で渡します。synthesisではspeaker(話すキャラ)だけparamsで与え、audio_queryで得られたデータはdataとして渡します。このときjson.dumps等でJSONエンコードが必要です(やらないとエラーになります)。
synthesisのResponseBodyにそのままwavファイルのバイナリが入っているので、r.contentをそのまま保存すれば音声変換されたwavファイルが手に入ります。
音声の結合と音量の正規化
VOICEVOXでは何文にもわたる長文の生成はまだ厳しいようです。1文単位などある程度細切れの文章を食わせていくのが良いでしょう(例えば、ゆっくり実況なら字幕単位で食わせる的なイメージです)。音声を結合した1つのwavファイルでほしいこともあるので、その結合もPythonでやっていきましょう。
音声の結合はPython組み込みのwaveモジュールとNumPyを使います。以下のようにします。
waveファイル → (waveモジュール) → バイナリ → (np.frombuffer) → NumPy配列
waveファイル単位でNumPy配列にすれば「np.concatenate」で結合できるわけです。画像は縦横の2次元でしたが、音声は1次元なので結合は画像より楽です。16ビットのwavファイル(VOICEVOXの場合)の場合、NumPy配列は「np.int16」のデータ型になります。
また、VOICEVOXの出力音声は音量が小さくて聞き取りづらいこともあるので、同時に音量の正規化もしてみましょう。正規化にもいろいろありますが、ここでは単にピーク時の出力をnp.int16の最大値or最小値にあわせるようにスケーリングします。
import wave
import numpy as np
import glob
def combine():
audios = []
for f in sorted(glob.glob("audio_*.wav")):
with wave.open(f, "rb") as fp:
buf = fp.readframes(-1) # 全フレーム読み込み
assert fp.getsampwidth() == 2 # と仮定(np.int16でキャスト)
audios.append(np.frombuffer(buf, np.int16))
params = fp.getparams()
audio_data = np.concatenate(audios)
# 正規化(ピーク時基準)
scaling_factors = [np.iinfo(np.int16).max/(np.max(audio_data)+1e-8),
np.iinfo(np.int16).min/(np.min(audio_data)+1e-8)]
# s>0:位相が反転しないようにする。ここをmaxにするとプチッというノイズが入るので注意
scaling_factors = min([s for s in scaling_factors if s > 0])
audio_data = (audio_data * scaling_factors).astype(np.int16)
with wave.Wave_write("combine.wav") as fp:
fp.setparams(params)
fp.writeframes(audio_data.tobytes())
VOICEVOXの出力(結合前1行目のみ)
結合+正規化
音声ライブラリはずんだもんです。正規化したほうが聞き取りやすくなっています。データ型が符号付き16ビット整数なので、最大値か最小値かのどちらかが合うように調整しました。「最大値-最小値」のようなmin-maxスケーリングをすると、多分声質やピッチが変わってしまうのではないかと思います。スケーリングの定数はマイナスにならないようにします。スケーリングの定数の選択時に「min」ではなく、「max」にしてしまうと、データの一部がオーバーフローしてしまい「プチッ」というノイズが入るため、注意が必要です。
これはPythonとの連携よりVOICEVOXの話になってしまいますが、「音威子府(おといねっぷ)」のような難読漢字は辞書に登録されているようで普通に読めるようです。むしろ、文脈に応じて読み方を変える「滝川(たきかわ)」「豊富(とよとみ)」のようなケースで誤読しまうことが多いです。ただし、このようなミスは例えばAzure Text to Speechのようなクラウドベースの音声合成でも普通にあるので、むしろそれらと互角に戦えるかもしれない性能をしているという点に注目すべきです。
Azure Text to SpeechとGoogle Cloud Text-to-speechとVOICEVOXの比較
同じようなコードベースの合成するなら「AzureやGoogle Cloudを使うべきではないか」という指摘もあると思います。これらと比較してみましょう。
Azure vs VOICEVOX
難読漢字を含まない通常の文章で比較してみましょう。VOICEVOXはGUIで出力した例で正規化は行っていませんが、動画作成時にゆっくりムービーメーカーで音量が2倍(100%設定)になっています。
VOICEVOXは声がかわいいですね。Azureは声が明瞭で聞き取りやすいです。VOICEVOXでも明瞭さのパラメーターを上げるともう少し聞き取りやすくなります。ただ、Azureの七海では「やむを得ず」の部分の発音がおかしい部分がありますが、ここはVOICEVOXがきちんと読めています。
難読地名を含むケース。Azureでは「行(ゆき→ぎょう)」「滝川(たきかわ→たきがわ)」「豊富(とよとみ→ほうふ)」を誤読しています。一方でVOICEVOXでは「滝川」「豊富」の誤読のみです。
Google Cloudの場合
Google Cloudの場合、声の質は機械的で全然かわいくないです。またAzureのような明瞭さも若干落ちます。ただ、読み方の正確性だけはやたら強いのが特徴です。
滝川だけは流石に間違えましたが、豊富を「とよとみ」とちゃんと読めてるのすごい。文脈に応じた読み分けが強いのはさすがGoogleですね。ただ録画の問題かもしれませんが、Google Cloudのデモサイトでは「プチッ」とした音が入ったのが若干気になります。
読み方の正確性を若干捨てても、かわいさを求めるのならVOICEVOXはGAFAのクラウドとかなりいい勝負ができるのではないでしょうか。
固有名詞の正確性でGoogle Cloudと真っ向勝負してみる
宗谷の停車駅は自治体の名前にもなっているぐらい有名な地名なので、ある程度いい辞書使っていれば辞書登録されているでしょう。もっとローカルな固有名詞で勝負してみましょう。人間ですら発狂しそうなレベルのテキストを入れてみます。これ初見で読めた人はすごいと思いますよ。
糠南駅の隣には雄信内駅があります。雄信内駅は幌延町の雄興地区にあります。
雄信内駅を南に下ると雄信内大橋を渡り、天塩町雄信内へとつきます。ここは天塩川と雄信内川の合流地点です。
なぜこれが発狂レベルなのかというと、雄信内の読み方が場所によって変わるからです。また自治体の名前を「ちょう」と読むか「まち」と読むかでも悩ましいです(北海道はほぼ「ちょう」と読めばいいんですけどね)。ふりがなを振ると以下の通りです。
糠南(ぬかなん)駅の隣には雄信内(おのっぷない)駅があります。雄信内(おのっぷない)駅は幌延町(ほろのべちょう)の雄興(ゆうこう)地区にあります。
雄信内(おのっぷない)駅を南に下ると雄信内大橋(おのぶないおおはし)を渡り、天塩町(てしおちょう)雄信内(おのぶない)へとつきます。ここは天塩川(てしおがわ)と雄信内川(おのぶないがわ)の合流地点です。
VOICEVOXの場合
こんだけいじめた文読ませればさすがに誤読が多かったです。VOICEVOX誤読箇所は7箇所でした。では次にGoogle Cloudを見てみましょう。なお同様の文をAzureに読ませたら誤読は3箇所でした(雄信内を全部「おのっぷない」と読んでいた)。特に動画では示しませんが気になる方はデモサイトからやってみてください。
Google Cloudの場合
Google先生の本気を見た。「おのっぷない」と「おのぶない」を文脈に応じて読み分けられています。流石に川の名前はおのっぷないと言ったので、誤読1箇所です。あくまで自分がここを「おのぶない」と読んでいるのは、現地の川にかかっている青看板の読み方を踏襲しただけで、川の名前も「おのっぷない」と書いてあるサイトもあります。ここは解釈の余地はあるところなので、誤読というほどの誤読ではないですね。こんな田舎の地名も読み分けられるのやばいですねGoogle。
ふりがなでVOICEVOXを調教する
通常この手の難読漢字は、SSMLでよみがなやイントネーション情報を与えるのが通例です。VOICEVOXではこの記事を書いた時点(v0.2.0)でSSMLは非対応で、部分的にひらがなにして難読漢字に対応するのが有力な対処方法です。(もっと厳密にAPIからMorasを編集して、母音・子音レベルで辞書登録して合成というやり方もありますが、実装が大変です)。SSML対応するとVOICEVOX神になるんですけどなかなか難しそう。
こちらが意図した読み方に調教したものがこちら。ゆっくりムービーメーカーの読み方からいじりましたが、Pythonの入力テキストを変更するでも同様の効果は得られます。
調教成功時のテキストがこちらです。
糠なん駅の隣にはおのっぷない駅があります。おのっぷない駅は幌延ちょうの雄興地区にあります
おのっぷない駅を南に下ると雄信内大橋を渡り、天塩ちょう雄信内へとつきます。ここは天塩川とおのぶない川の合流地点です
糠南駅を「ぬかなん駅」と入力すると、イントネーションがおかしくなってしまいました。結構このへんがシビアです。実際の運用はカスタム辞書を作るという形になりますが、だいぶ辞書登録する必要がありますね。雄信内だけを登録しても文脈によってかわるので「雄信内駅」や「天塩町雄信内」というようにセットで登録したり、スクリプトを入力する必要がありそうです。アドホックによみがなを入れるという手も考えられます。
これらの比較からVOICEVOX、Azure、Google Cloudを比較すると次のようになります。あくまで現時点での自分の感触です。
| VOICEVOX | Azure Text to Speech | Google Text to speech | |
|---|---|---|---|
| 動作安定性 | △(500エラーをカバーする必要あり) | ◎ | ○(音質疑義あり) |
| 音声の明瞭さ | ○ | ◎ | ○ |
| 読みの正確さ | ○~△(通常の文章は強いが、固有名詞の読み分けが弱い) | ○ | ◎~★ |
| 音声の可愛さ | ◎ | ○ | △(基本的に無機質) |
| 女性ボイス数 | 2 | 1(ニューラルのみ) | 2 |
| 料金 | ◎(無料) | △(月0.5M文字無料) | ○(月1M文字無料) |
安定性の部分はリトライでどうにかなりそうなんで、誤読の部分をうまくカバーできれば相当強いなと思いました。これからに期待したいです。
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー