
Cosine DecayとWarmupを同時にこなすスケジューラー(timm使用)

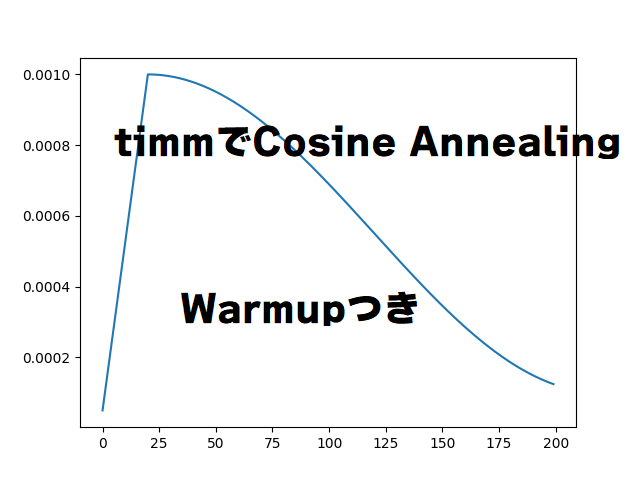
学習初期は徐々に学習率を上げていく「Warmup」と、学習率をなめらかに下げていく「Cosine Annealing」を1つのオプティマイザーとして楽に実装する方法を、timmライブラリを使って見ていきます。
目次
timmについて
timm(PyTorch Image Models)という便利なライブラリがあります。画像のTransformer系の論文実装で特によく使われているライブラリです。
このライブラリでは訓練済みのモデルの係数の提供の他に、Data Augmentationや学習率のスケジューラーも入っています。RandAugmentやCutMix、Mixupといった、ディープラーニングのフレームワークには組み込まれていないが、1から実装するとそこそこ大変なAugmentを使いたいときはかなり便利です。PyTorchのデフォルトのコードとも相互運用できるようになっています。
Cosine DecayとWarmupを同時にしたいよね
学習が進んだらCosine Decay(https://arxiv.org/abs/1608.03983 )で学習率を減衰させたいが、最初はWarmupで徐々に学習率を上げたいというパターンがよくあります。転移学習では最初に大きな学習率を当ててしまうと訓練済みの係数が大きく壊れてしまうおそれがあります。
またプレーンに学習する場合も、初期に大きな勾配がかかることで局所解に収束してしまうという問題への対策になります。Transformer系の論文でWarmupを使っているのはこちらの意味のほうが強いです。
WarmupとCosine Decayを同時にこなすには、timmのCosineLRSchedulerを使います。PyTorchのCosineAnnealingLRでは減衰はできてもWarmupは組み込めません。
公式ドキュメント:https://fastai.github.io/timmdocs/SGDR
timm.scheduler.cosine_lr.CosineLRScheduler
timmのインストール
pip install timm
以下の条件のスケジューラーを考えます。
- 全200エポック訓練
- Warmupの開始学習率は5e-5、20エポックWarmup
- 基本学習率は1e-3(オプティマイザーで設定)
- Restartはせず、Warmupが終わったら学習率は下げるだけ
次のようなコードになります。
scheduler = CosineLRScheduler(optimizer, t_initial=200, lr_min=1e-4,
warmup_t=20, warmup_lr_init=5e-5, warmup_prefix=True)
学習率が期待した通りになったか確認してみましょう。
import torch
from timm.scheduler import CosineLRScheduler
import matplotlib.pyplot as plt
def scheduler():
model = torch.nn.Linear(1, 1) ## 適当なモデル
optimizer = torch.optim.Adam(model.parameters())
scheduler = CosineLRScheduler(optimizer, t_initial=200, lr_min=1e-4,
warmup_t=20, warmup_lr_init=5e-5, warmup_prefix=True)
lrs = []
for i in range(200):
lrs.append(scheduler.get_epoch_values(i))
plt.plot(lrs)
plt.show()
if __name__ == "__main__":
scheduler()
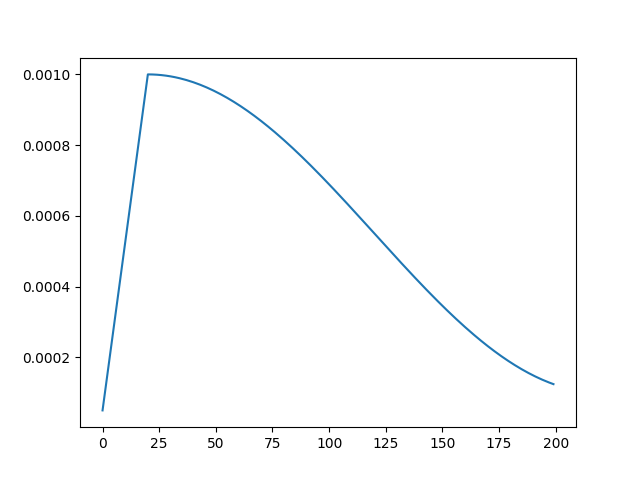
「t_initial」に総エポック数、「warmup_t」にWarmupのエポック数を入れます。「warmup_prefix=True」は、Warmupが完了したタイミングの学習率をオプティマイザーで設定した基本学習率にするかどうかです。
warmup_prefixをFalseにすると、1エポック目を基準にしてコサインカーブで学習率を計算します。この例では、Warmupが完了した時点(20エポック目)で、基本学習率より少し低い値が出てきます。基本はTrueで差し支えないと思われます。
学習率のオプティマイザーへの反映を確認する
本当に学習率が更新されているか確認してみましょう。オプティマイザーの学習率は、
optimizer.param_groups[0]["lr"]
で取得できます。スケジューラーの値と比較してみましょう。
import torch
from timm.scheduler import CosineLRScheduler
import matplotlib.pyplot as plt
def scheduler():
model = torch.nn.Linear(1, 1) ## 適当なモデル
optimizer = torch.optim.Adam(model.parameters())
scheduler = CosineLRScheduler(optimizer, t_initial=200, lr_min=1e-4,
warmup_t=20, warmup_lr_init=5e-5, warmup_prefix=True)
for i in range(200):
# スケジューラーの学習率、反映されたオプティマイザーの学習率
print(scheduler.get_epoch_values(i), optimizer.param_groups[0]["lr"])
scheduler.step(i+1)
if __name__ == "__main__":
scheduler()
このとおりぴったり一致しました。
[5e-05] 5e-05
[9.750000000000001e-05] 9.750000000000001e-05
[0.000145] 0.000145
[0.0001925] 0.0001925
[0.00024] 0.00024
[0.00028750000000000005] 0.00028750000000000005
[0.000335] 0.000335
[0.00038250000000000003] 0.00038250000000000003
[0.00043000000000000004] 0.00043000000000000004
[0.00047750000000000006] 0.00047750000000000006
[0.0005250000000000001] 0.0005250000000000001
[0.0005725000000000001] 0.0005725000000000001
[0.00062] 0.00062
[0.0006675] 0.0006675
[0.000715] 0.000715
[0.0007625] 0.0007625
[0.0008100000000000001] 0.0008100000000000001
[0.0008575000000000001] 0.0008575000000000001
[0.0009050000000000001] 0.0009050000000000001
[0.0009525000000000001] 0.0009525000000000001
[0.001] 0.001
[0.0009999444846167471] 0.0009999444846167471
[0.0009997779521645793] 0.0009997779521645793
[0.0009995004437328865] 0.0009995004437328865
[0.0009991120277927223] 0.0009991120277927223
[0.0009986128001799076] 0.0009986128001799076
schedulerのstepにエポックを指定しないといけないのが、通常のPyTorchと違いますね。インデックスの+1がハマりました。
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー