
論文まとめ:Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
Posted On 2023-04-20


- タイトル:Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
- 著者:Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, Lei Zhang
- 論文URL:https://arxiv.org/abs/2303.05499
- コード:https://github.com/IDEA-Research/GroundingDINO
- デモ:https://huggingface.co/spaces/ShilongLiu/Grounding_DINO_demo
目次
ざっくりいうと
- 物体検出モデルDINOを、Vision & Langに拡張したオープンセット物体検出モデル
- Transformerベースの構造上の緻密なモダリティ融合と、クローズドな物体検出モデルの活用が大きな特徴
- 2023年4月時点でSoTAで、Segment Anythingとの融合も行われている
前提知識
この論文、DETRのようなTransformerベースの物体検出のお気持ちがわからないとちょっとむずかしいです
物体検出
- Input:画像
- Output:クラスとBounding Boxの座標を予測するタスク
よくある物体検出

CNNは特徴マップの位置不変性があるので、特徴マップからBounding Boxを推定できる
Transformerベースの物体検出(DETR)
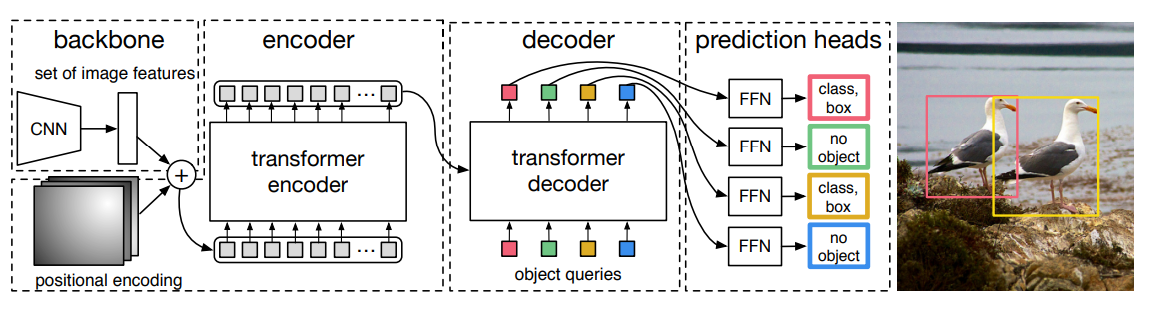
オブジェクトクエリによってBounding Boxの計算に必要な属性を抽出する←(なんのこっちゃ??)
- Bounding Boxの出力をテキストのように考える
- Outputは何らかのシーケンスを吐いてほしい(x=400, y=300, w=200, h=100)
- このシーケンスを適切に吐いてくれるためのクエリ(Attentionの入力)を学習しようね!というものがObject Query
- 言語モデルだと考えればお気持ちは伝わると思う!
イントロ
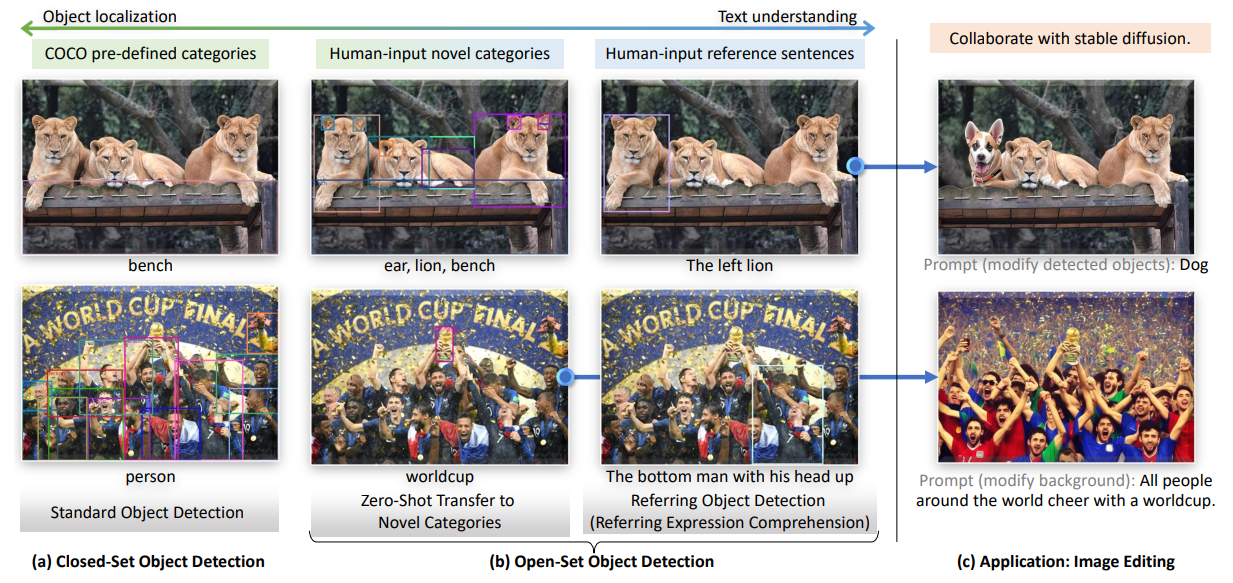
- 人間の言語入力によって指定された任の物体を検出するタスク=オープンセット物体検出
- 未知の物体を検出できるのが強い!
- 先行研究のGLIP:1段検出器のDynamic Headにもとづいているためそれに制約される
- Grounding DINOのおおきな発想=オープンセットだろうがクローズドセット(例:COCO)の物体検出の結果を利用すればいいじゃん!
- 従来のオープンセットの物体検出では、クローズドの結果を使うことがかなり見過ごされてきた
- ツヨツヨ物体検出のDINOがベースで、これは画像だけのユニモーダルなクローズドな設定。これをVision & Languageにしてオープンセット化したい
- 領域を抽出してきて、CLIPのようなContrastive Learningをすればオープンセットに拡張できそう(従来の研究と同じ)
- 全部Transformerベースにして、NMSのような難しいモジュールを廃止してEnd-to-Endで流したい(DETR系の発想)
- 画像とテキストが最初から利用可能なので、早い段階から融合すると性能が上がることがわかっている
- Faster R-CNNのような古典的なやり方だと早い段階から画像と言語を融合できない
- 古いオープンセット物体検出の研究だと、RoI Alignを抽出してきてCLIPで分類なようなもの多い
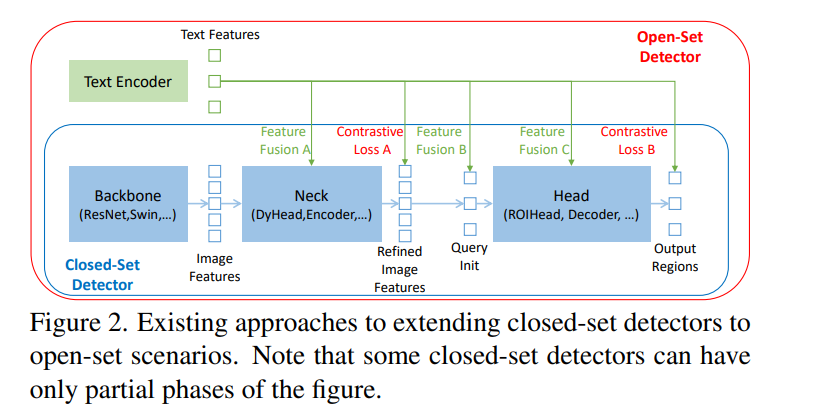
- Transformerベースにして、ネック、クエリ初期化、ヘッドの各フェーズで、3つの画像言語の特徴融合をする
- オープンセット物体検出で見過ごされてきた、REC(Referring Expression Comprehension)というタスクを導入する
- RECの例:Referring Object Detection
手法
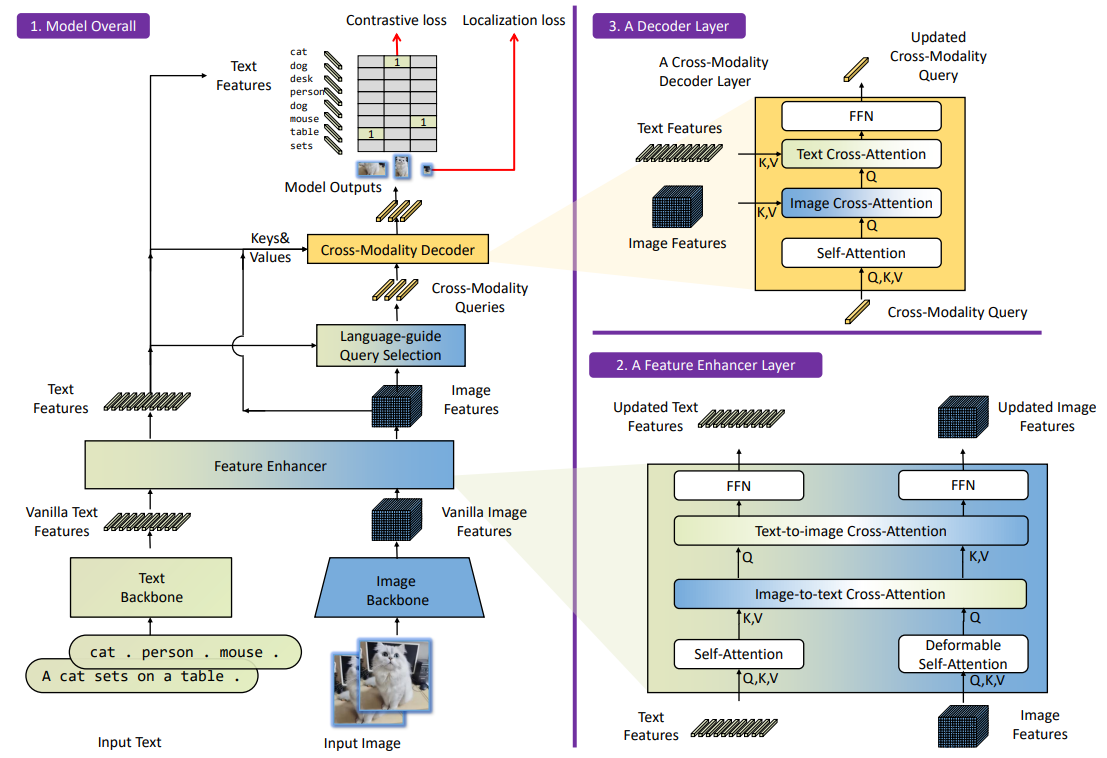
以下の3モジュールからなる
- Feature Extraction and Enhancer
- Language-Guided Query Selection
- Cross-Modality Decoder
Feature Extraction and Enhancer
- 画像はSwin Transformer、テキストはTransformer
- Feature Enhancerでは、画像にDeformable self-attention、テキストにvanilla self-attentionを使用
Language-Guided Query Selection

Cross-Modality Decoder
言語と画像のアラインメントをとるためAttention
→結論:Attention is All You Need.
結果
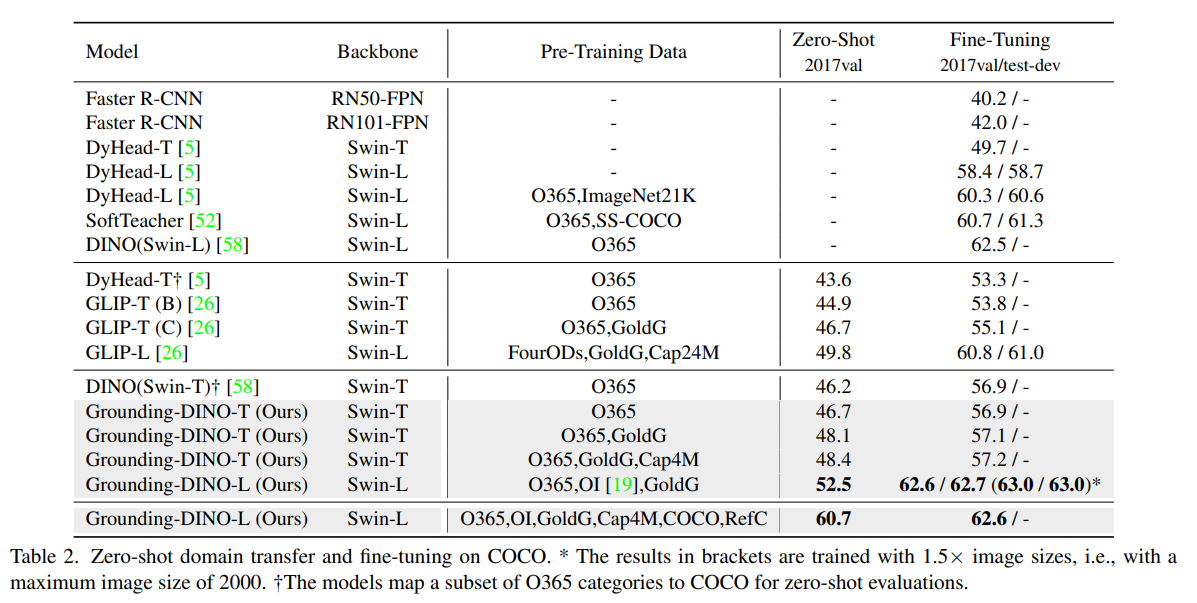
Ablation
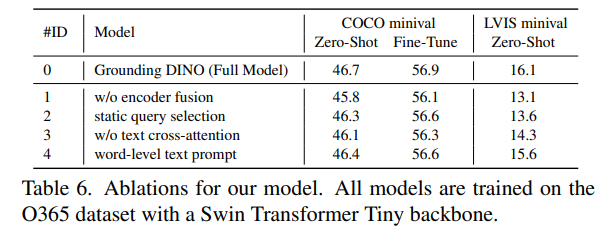
Encoder Fusionが割りと大事
所感
- 普通にツヨツヨ。最近話題のSegment Anythingと統合されてキメラになってる(これとか、これとか)
- HuggingFaceで試してみたが、かなり細かいものまで気持ち悪いぐらいにとってくれる
- Transformerベースの物体検出は、Attentionで思考停止できるので逆にわかりやすいかもしれない
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー