
asyncioを使ったLangChain+Streamlitでの非同期処理:複数のストリーミングチャットを同時に動かす


asyncioを使い、StreamlitのUIを非同期化することを目指します。非同期化することで、複数のストリーミングチャットを同時に動かすことが可能になります。LangChainとの統合ではUIの反映をどのコンテクストで行うかが課題になりますが、Chain間の結合など面白い活用法も期待できる実践的な内容です。
目次
はじめに
Streamlit+LangChainで複数のストリーミングチャットを同時に動かすことを考えます。最終的に作りたいものはこういったものです。
このようにボタンを押すと、複数のストリーミングチャットが同時に表示されることを考えます。これはちょっと難しくて、
- ChatGPTのストリーミングを複数動かす
- 非同期処理でStreamlitとのUIをつなぎこむ
これ1週間ぐらいずっと悩んでいた内容で、ネットを探しても解決方法が全然なかったものです。ようやく解決方法見つけたのでメモしておきます。結論はasyncioで非同期処理を任せて、LangChainのChainを使わない(LangChainではコールバックを使わない)です。
うまくいかなかったこと・試さなかったこと
- Threadingを使う
- これはうまくいかなく、UIスレッドとのコンテクストが問題になりました
- バックエンドを作る
- UIスレッドがどこかがかなり問題になってくるので、バックエンドのAPIを立ててしまえばその問題が無視できるので楽かもしれません。ただChatGPT程度で中継バックエンドは立てたくなかったのであえてやりませんでした
- Queueを作ってProducer-Consumerパターンを試す
- https://discuss.streamlit.io/t/best-fastest-practice-to-display-live-2d-data/19895/4
- この例のように、Queueを作り、LangChain側でそこにストリーミングのトークンを入れ続け、UI側でトークンを取り出すという昔からあるやり方をやるパターンです
- Streamlitが全画面再描画するという昔ながらのデザインなので、これは相性いいと思いますが、Queueの管理が面倒くさいのとやり方が古臭い(20年前ぐらいのゲームであったような作り方)なので、できればいちいち実装したくないというのがありました
今回はPythonに用意されているasyncioを使い、コルーチンを活用する方法を採用しました。
Streamlitと非同期処理
これだけ見ると「並列処理してそれをUIに戻せばいいのではないか」と思うかもしれませんが、UIに戻す際はコンテクストが問題となり、UIスレッドやコンテクストと異なるスレッドで並列処理が実行されるとそれがUI側に反映されないというクライアントサイド特有の問題があります。
まずはLangChainを無視して、StreamlitとのUIをつなぎこむ部分だけ試してみます。チャットウィンドウを4つ開いて以下のようなタイマーを表示してみます。
これをasyncioで実装する場合は割りとシンプルです。
import streamlit as st
import asyncio
async def corrutine(base_number):
with st.chat_message("assistant"):
container = st.empty()
for i in range(11):
container.markdown(base_number+i)
await asyncio.sleep(1)
async def runner():
tasks = []
for i in range(4):
t = asyncio.create_task(corrutine(i*10))
tasks.append(t)
await asyncio.sleep(1)
await asyncio.gather(*tasks)
def main():
st.title("Async UI")
button = st.button("Click me")
if button:
asyncio.run(runner())
if __name__ == "__main__":
main()
各タイマーの部分はasync(非同期)のコルーチンとして定義します。同期版だったらtime.sleepしているところを、asyncio.sleepにしているだけです。非同期だとスレッドをロックはしないのですが、awaitしてあげないと待たないで次の処理が走ってしまうので、asyncio.sleepにはawaitを入れます。
次のrunnerの部分ですが、ここがタスクのfactoryです。4個のタスクを1秒のラグを持たせて実行し、すべてのタスクが完了するまで待ちます。ここが非同期版の大きな特徴で、以下のような複数ストリーミングを同時に動かすことが可能になります。
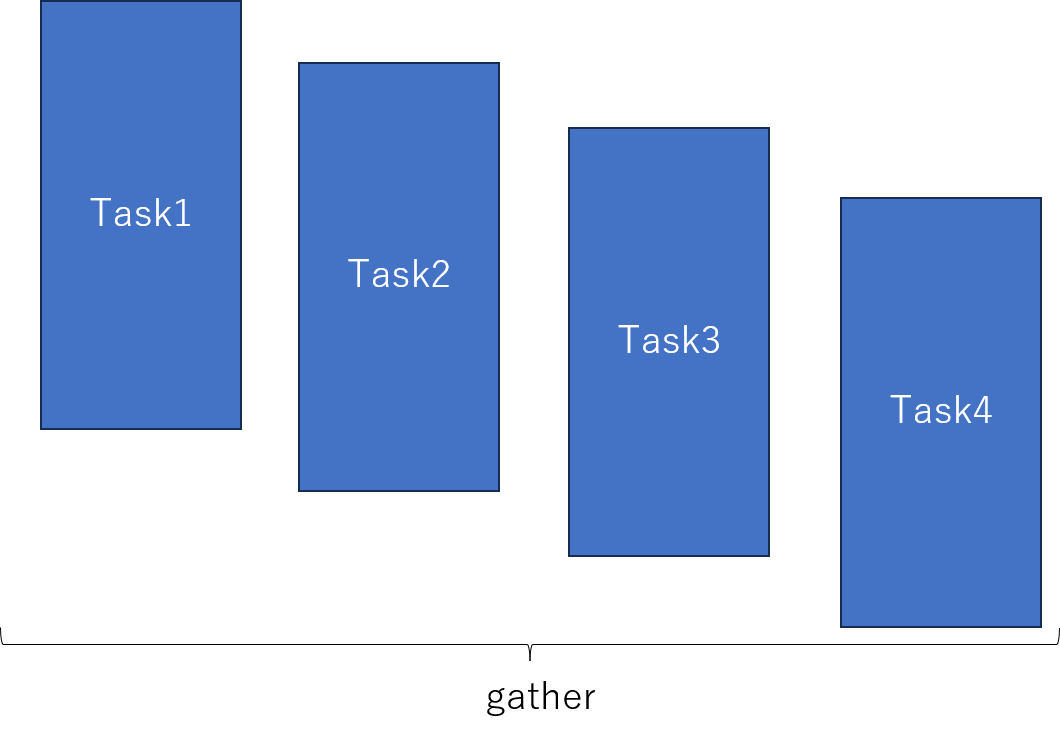
もしここが同期版だとTask1→Task2→…→Task4のようにシーケンシャルに実行されます。最後のasyncio.gatherの部分は、このケースの場合タスクの実行時間がほぼ固定長なので最後のタスクを待つでも良かったのですが、各タスクの実行時間が不定の場合は、gatherにして最後のタイミングだけ揃えてあげるほうが有効です。
asyncioの場合は、複数タスクを投げっぱなしにする→最後だけ揃えるというデザインパターンをすると、簡単に並列化っぽいことができるのが面白い点です。
main関数のif button以下は、非同期関数を同期関数の中で呼び出すためのラップです。asyncio.runだと、同期関数の中から非同期関数を呼び出して終わるまで待機するという処理になります。なので、タスクファクトリーの非同期関数を作って、それをメインの同期関数から呼び出すというパターンが良さそうです。
ただ、厳密には並列化ではないので、重い処理を複数走らせて高速化するというわけではないです。あくまでやっているのは、1つのスレッドに複数のタスクを非同期で並行して走らせて、ブロッキングしていない空き時間を見つけて処理を走らせているというだけです。ChatGPTのストリーミングのようにLLM自体の計算量を考えなくて良い場合に使える手法です。逆にいうと、今回は1つのスレッドで複数タスクが走っていたほうがUIへの反映のコンテクストの問題が起こらないから都合がいい(UIと同じコンテクストのスレッドで走らせられる)という点に注目して、この方法を採っています。
LangChainのストリーミングをコールバックなしで使う
同期版
LangChainのストリーミングの例は、トークンが入ったときのコールバックを定義してそれを読ませるというパターンがほとんどですが、実はOpenAIの公式ライブラリのようにストリーミングの内容をforループで取り出せます。まずは同期版から見てみます。
from langchain.chat_models import ChatOpenAI
def simple_streaming():
llm = ChatOpenAI(model="gpt-3.5-turbo-0613", temperature=0.2, max_tokens=512, streaming=True)
text = ""
for chunk in llm.stream("こんにちは"):
print(chunk)
text += chunk.content
print(text)
if __name__ == "__main__":
simple_streaming()
llmだけをLangChainで定義して、stream関数を使います。この結果は以下のようになります。
content='' additional_kwargs={} example=False
content='こんにちは' additional_kwargs={} example=False
content='!' additional_kwargs={} example=False
content='い' additional_kwargs={} example=False
content='つ' additional_kwargs={} example=False
content='も' additional_kwargs={} example=False
content='お' additional_kwargs={} example=False
content='世' additional_kwargs={} example=False
content='話' additional_kwargs={} example=False
content='に' additional_kwargs={} example=False
content='な' additional_kwargs={} example=False
content='って' additional_kwargs={} example=False
content='います' additional_kwargs={} example=False
content='。' additional_kwargs={} example=False
content='な' additional_kwargs={} example=False
content='に' additional_kwargs={} example=False
content='か' additional_kwargs={} example=False
content='ご' additional_kwargs={} example=False
content='用' additional_kwargs={} example=False
content='件' additional_kwargs={} example=False
content='は' additional_kwargs={} example=False
content='あり' additional_kwargs={} example=False
content='ます' additional_kwargs={} example=False
content='か' additional_kwargs={} example=False
content='?' additional_kwargs={} example=False
content='' additional_kwargs={} example=False
こんにちは!いつもお世話になっています。なにかご用件はありますか?
OpenAIのライブラリのように、ストリーミングのチャンク単位で取得できているのがわかります。コンソールだったらもうこれでOKですね。
非同期版
このstream関数実は非同期版も定義されています。公式ドキュメントには数行しか書かれていなくて、ネットを探してもユースケースが全然見つからなかったのですが、astreamという関数です。今回これを活用します。
from langchain.chat_models import ChatOpenAI
import asyncio
async def simple_async_streaming():
llm = ChatOpenAI(model="gpt-3.5-turbo-0613", temperature=0.2, max_tokens=512, streaming=True)
text = ""
async for chunk in llm.astream("こんにちは"):
print(chunk)
text += chunk.content
print(text)
if __name__ == "__main__":
asyncio.run(simple_async_streaming())
content='' additional_kwargs={} example=False
content='こんにちは' additional_kwargs={} example=False
content='!' additional_kwargs={} example=False
content='お' additional_kwargs={} example=False
content='元' additional_kwargs={} example=False
content='気' additional_kwargs={} example=False
content='です' additional_kwargs={} example=False
content='か' additional_kwargs={} example=False
content='?' additional_kwargs={} example=False
content='何' additional_kwargs={} example=False
content='か' additional_kwargs={} example=False
content='お' additional_kwargs={} example=False
content='手' additional_kwargs={} example=False
content='伝' additional_kwargs={} example=False
content='い' additional_kwargs={} example=False
content='で' additional_kwargs={} example=False
content='き' additional_kwargs={} example=False
content='る' additional_kwargs={} example=False
content='こ' additional_kwargs={} example=False
content='と' additional_kwargs={} example=False
content='は' additional_kwargs={} example=False
content='あり' additional_kwargs={} example=False
content='ます' additional_kwargs={} example=False
content='か' additional_kwargs={} example=False
content='?' additional_kwargs={} example=False
content='' additional_kwargs={} example=False
こんにちは!お元気ですか?何かお手伝いできることはありますか?
先程の関数を非同期版に書き換えたものです。こうすることでストリーミング中に、メインスレッドをブロッキングすることがなく処理を続けることができます。
先程との違いはforループの部分ですが、もともとのstream関数の実装がジェネレーターなので、ここは非同期ジェネレーターになります。非同期ジェネレーターについては以下のページが詳しいです。forの前にasyncを入れる非同期ジェネレーターは私は初めて使ったのですが、こういうところに使い所がありました。
pythonのGeneratorとAsyncGeneratorの使い方
Streamlit単発の質問を複数同時に流す
先程のはコンソールの例でしたが、これを次はStreamlitへの統合する場合を見てみます。単発で質問する場合は複数同時は簡単です。以下のようなものを作ります。
from langchain.chat_models import ChatOpenAI
import streamlit as st
import asyncio
async def corrutine(theme):
with st.chat_message("assistant"):
container = st.empty()
llm = ChatOpenAI(model="gpt-3.5-turbo-0613", temperature=0.2, max_tokens=512, streaming=True)
text = ""
async for token in llm.astream(f"{theme}の観光地を教えて"):
text += token.content
container.markdown(text)
async def runner():
tasks = []
themes = ["東京", "大阪", "札幌", "福岡"]
for i in range(4):
tasks.append(asyncio.create_task(corrutine(themes[i])))
await asyncio.sleep(1)
await asyncio.gather(*tasks)
def main():
st.title("Async UI")
button = st.button("Click me")
if button:
asyncio.run(runner())
if __name__ == "__main__":
main()
先程のカウントダウンの例にLangChainが入っただけです。コルーチンの内側とメイン関数のコンテクストは一緒なので、コルーチン側からUIをアップデートしても大丈夫なのが強い点です。
サンプル動画を見ると「おおっ」となりますよね。
LangChainって普通LLM(ChatOpenAI)単体では使わなくて、Prompt TemplateやConversation Bufferを入れながらChainとして使いますよね。ただ問題なのは、Chainにastream/stream関数が実装されていなく、この例のようにforループでストリーミングを取得できないという点です。もうここはCallbackでやってくださいというLangChain側の設計思想なのかもしれません。したがって、2023年9月現在は、チャット履歴やプロンプトの整形部分は自力で実装する必要があります。ただ、Prompt TemplateやConversation Bufferを使って整形部分の関数を流用することである程度は楽できるのでそれを見ていきます。
Chainを使わないで推論させる
from langchain.prompts import ChatPromptTemplate, HumanMessagePromptTemplate, MessagesPlaceholder
from langchain.chat_models import ChatOpenAI
from langchain.memory import ConversationBufferMemory
def main():
llm = ChatOpenAI(model="gpt-3.5-turbo-0613", temperature=0.2, max_tokens=512, streaming=True)
prompt = ChatPromptTemplate.from_messages([
MessagesPlaceholder(variable_name="chat_history"),
HumanMessagePromptTemplate.from_template("{human_input}")
])
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
question = "東京の観光地を教えて"
x = prompt.format_prompt(human_input=question, chat_history=memory.load_memory_variables({})["chat_history"])
print(x)
print(type(x))
text = ""
for y in llm.stream(x):
text += y.content
print(y.content, end="")
memory.save_context({"input": question}, {"output": text})
print()
print("---------------------")
print()
question = "各観光地に対応したおすすめの宿泊地は?"
print(memory.load_memory_variables({}))
x = prompt.format_prompt(human_input=question, chat_history=memory.load_memory_variables({})["chat_history"])
print(x)
text = ""
for y in llm.stream(x):
text += y.content
print(y.content, end="")
print()
if __name__ == "__main__":
main()
このコードは再びコンソールですが、ConversationBufferMemoryやPrompt Templateは使いつつも、Chainを使って推論していません。この結果は以下のようになります。
messages=[HumanMessage(content='東京の観光地を教えて', additional_kwargs={}, example=False)]
<class 'langchain.prompts.chat.ChatPromptValue'>
東京には多くの観光地がありますが、以下は特に人気のある観光地です。
1. 東京ディズニーランド/東京ディズニーシー:世界的に有名なディズニーパークで、アトラクションやショーを楽しむことができます。
2. 東京タワー:東京のシンボルとして知られる展望台で、都心の美しい景色を楽しむことができます。
3. 浅草寺:日本最古の仏教寺院で、仲見世通りや雷門などの歴史的な建造物があります。
4. 上野公園:広大な公園で、東京国立博物館や上野動物園などがあります。
5. 秋葉原:電気街として有名で、最新のテクノロジー商品やアニメグッズを購入することができます。
6. 明治神宮:東京の中心部にある神社で、静かな森の中で散策することができます。
7. 六本木ヒルズ:高層ビルやショッピングモールが集まるエリアで、展望台からの眺めが素晴らしいです。
8. 築地市場:新鮮な魚介類や海産物が豊富な市場で、寿司を食べることができます。
9. 東京スカイツリー:世界最高の自立式塔で、展望台からのパノラマビューが楽しめます。
10. お台場:東京湾に浮かぶ人
---------------------
{'chat_history': [HumanMessage(content='東京の観光地を教えて', additional_kwargs={}, example=False), AIMessage(content='東京には多くの観光地がありますが、以下は特に人気のある観光地です。\n\n1. 東京ディズニーランド/東京ディズニーシー:世界的に有名なディズニーパークで、アトラクションやショーを楽しむことができます。\n2. 東京タワー:東京のシンボルとして知られる展望台で、都心の美しい景色を楽しむことができます。\n3. 浅草寺:日本最古の仏教寺院で、仲見世通りや雷門などの歴史的な建造物があります。\n4. 上野公園:広大な公園で、東京国立博物館や上野動物園などがあります。\n5. 秋葉原:電気街として有名で、最新のテクノロジー商品やアニメグッズを購入することができます。\n6. 明治神宮:東京の中心部にある神社で、静かな森の中で散策することができます。\n7. 六本木ヒルズ:高層ビルやショッピングモールが集まるエリアで、展望台からの眺めが素晴らしいです。\n8. 築地市場:新鮮な魚介類や海産物が豊富な市場で、寿司を食べることができま す。\n9. 東京スカイツリー:世界最高の自立式塔で、展望台からのパノラマビューが楽しめます。\n10. お台場:東京湾に浮かぶ人', additional_kwargs={}, example=False)]}
messages=[HumanMessage(content='東京の観光地を教えて', additional_kwargs={}, example=False), AIMessage(content='東京には多くの観光地がありますが、以下は特に人気のある観光地です。\n\n1. 東京ディズニーランド/東京ディズニーシー:世界的に有名なディズニーパークで、アトラクションやショーを楽しむことができます。\n2. 東京タワー:東京のシンボルとして知られる展望台で、都心の美しい景色を楽しむことができます。\n3. 浅草寺:日本最古の仏教寺院で、仲見世通りや雷門などの歴史的な建造物があります。\n4. 上野公園:広大な公園で、東京国立博物館や上野動物園などがあります。\n5. 秋葉原:電気街として有名で、最新のテクノロジー商品やアニメグッズを購入することができます。\n6. 明治神宮:東京の中心部にある神社で、静かな森の中で散策することができます。\n7. 六本木ヒルズ:高層ビルやショッピングモールが集まるエリアで、展望台からの眺めが素晴らしいです。\n8. 築地市場:新鮮な魚介類や海産物が豊富な市場で、寿司を食べることができます。\n9. 東京スカイツリー:世界最高の自立式塔で、展望台からのパノラマビューが楽しめます。\n10. お台場:東京湾に浮かぶ人', additional_kwargs={}, example=False), HumanMessage(content='各観光地に対応したおすすめの宿泊地は?', additional_kwargs={}, example=False)]
以下は各観光地に対応したおすすめの宿泊地です。
1. 東京ディズニーランド/東京ディズニーシー:舞浜エリアにあるディズニーリゾート内のホテルが便利です。また、舞浜周辺には多くの宿泊施設もあります。
2. 東京タワー:東京タワー周辺のホテルやゲストハウスがおすすめです。ミッドタウンや赤坂エリアも近く、便利な立地です。
3. 浅草寺:浅草エリアには多くの宿泊施設があります。浅草寺周辺のホテルや旅館で、伝統的な日本の雰囲気を楽しむことができます。
4. 上野公園:上野エリアには多くのホテルやゲストハウスがあります。公園内にも宿泊施設があり、観光に便利です。
5. 秋葉原:秋葉原周辺には多くのビジネスホテルやカプセルホテルがあります。また、銀座や東京駅周辺もアクセスが良く、宿泊地として便利です。
6. 明治神宮:原宿や表参道エリアには多くの宿泊施設があります。青山や渋谷も近く、ショッピングや観光に便利な立地です。
7. 六本木ヒルズ:六本木や麻布エリアには高級ホテルやビジネス
各Chainの実装を見ればトレースできますが、LLMChain程度ならprompt.format_promptでプロンプトを作り、memoryのload_memory_variables→save_contextで記録する程度でも通用します。複雑なChainを使いたい場合はもっと実装が面倒になるかもしれません。
対話履歴を保持しつつ、複数の質問からなるストリーミングチャットを同時に動かす
最後に冒頭示した例のコードを示します。今までの内容をすべて組み合わせます。
from langchain.prompts import ChatPromptTemplate, HumanMessagePromptTemplate, MessagesPlaceholder
from langchain.chat_models import ChatOpenAI
from langchain.memory import ConversationBufferMemory
import streamlit as st
import asyncio
st.set_page_config(layout="wide")
async def manual_run(panel, llm, prompt_template, memory, question):
message = prompt_template.format_prompt(
human_input=question,
chat_history=memory.load_memory_variables({})["chat_history"]
)
# add to ui
with panel:
with st.chat_message("user"):
st.markdown(question)
with st.chat_message("assistant"):
container = st.empty()
response = ""
async for chunk in llm.astream(message):
response += chunk.content
container.markdown(response)
memory.save_context({"input": question}, {"output": response})
return response
async def logic(location, key, panel):
llm = ChatOpenAI(model="gpt-3.5-turbo-0613", temperature=0.2, max_tokens=512, streaming=True)
prompt = ChatPromptTemplate.from_messages([
MessagesPlaceholder(variable_name="chat_history"),
HumanMessagePromptTemplate.from_template("{human_input}")
])
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
questions = [
"こんにちは",
f"{location}の観光名所を教えて",
f"この観光名所の{location}駅からの行き方は?"
]
answers = []
for question in questions:
# Add to state
st.session_state[f"messages{key}"].append({
"role": "user",
"content": question
})
# run chatgpt
ans = await manual_run(panel, llm, prompt, memory, question)
# add to state
st.session_state[f"messages{key}"].append({
"role": "assistant",
"content": ans
})
answers.append(ans)
return answers
async def task_factory(parameters):
tasks = []
for param in parameters:
t = asyncio.create_task(logic(*param))
tasks.append(t)
return await asyncio.gather(*tasks)
def main():
if "messages1" not in st.session_state:
st.session_state.messages1 = []
st.session_state.messages2 = []
st.title("Multiple Streaming Chat")
column_left, column_right = st.columns(2)
button = st.button("Click to start chats")
with column_left:
for message in st.session_state.messages1:
with st.chat_message(message["role"]):
st.markdown(message["content"])
with column_right:
for message in st.session_state.messages2:
with st.chat_message(message["role"]):
st.markdown(message["content"])
if button:
parameters = [
("東京", 1, column_left),
("京都", 2, column_right)
]
asyncio.run(task_factory(parameters))
if __name__ == "__main__":
main()
これの実行結果が以下の動画です。
今までの内容とほぼ変わらないのでさほど解説いらないと思いますが、対話履歴を保持しつつ、複数質問に対応したチャットを複数同時に動かす例です。ConversationBufferMemoryとStreamlitの2つのステートを管理する必要があるため、ちょっとコードがごちゃっとしていますが(あんまりクリーンアーキテクチャじゃない)とりあえず動くことは動きました。
main関数にメッセージ履歴を表示しているのは、ページ遷移や他のUIがトリガーされて再描画が走ったときに過去の会話履歴を復活させるためです。単発のボタンだったらそこまで気にしなくていいと思います。
基本はasyncioベースで、factory関数を作って、そこでチャットを並行的に実行し、最後だけ揃える、メイン関数からはfactoryを呼び出すみたいなデザインパターンにすればいいというのがわかったのが収穫で、これはいろいろ応用が効きそうな感じがしました。
応用可能な例
例えば、チャットの講談に翻訳用のChainが入るといったパターンです。こういうのを最初は実装したかったのです。
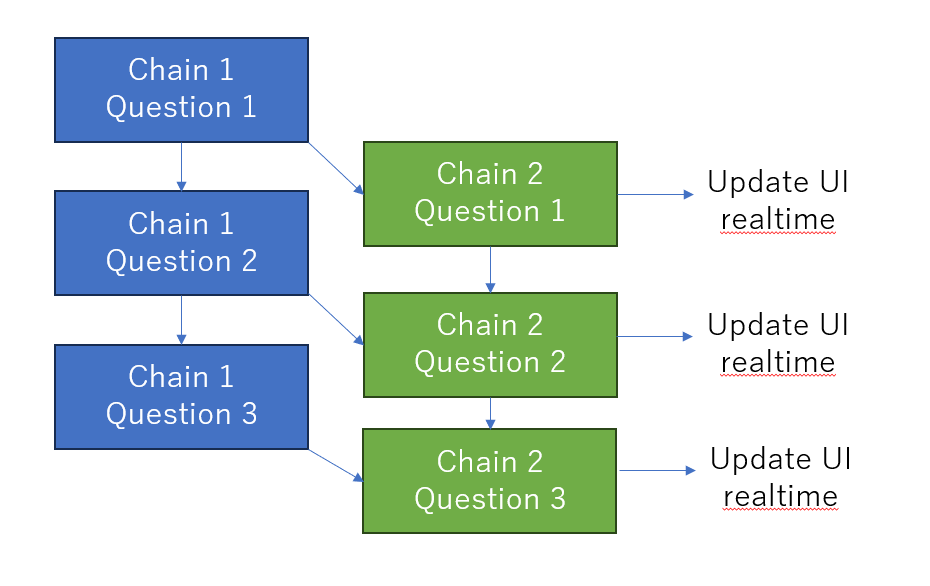
実装的に簡単なのはシーケンシャルにこういった実装をするのですが、これだとGPT-4のような重いモデルを使ったときにレスポンスが悪いです。
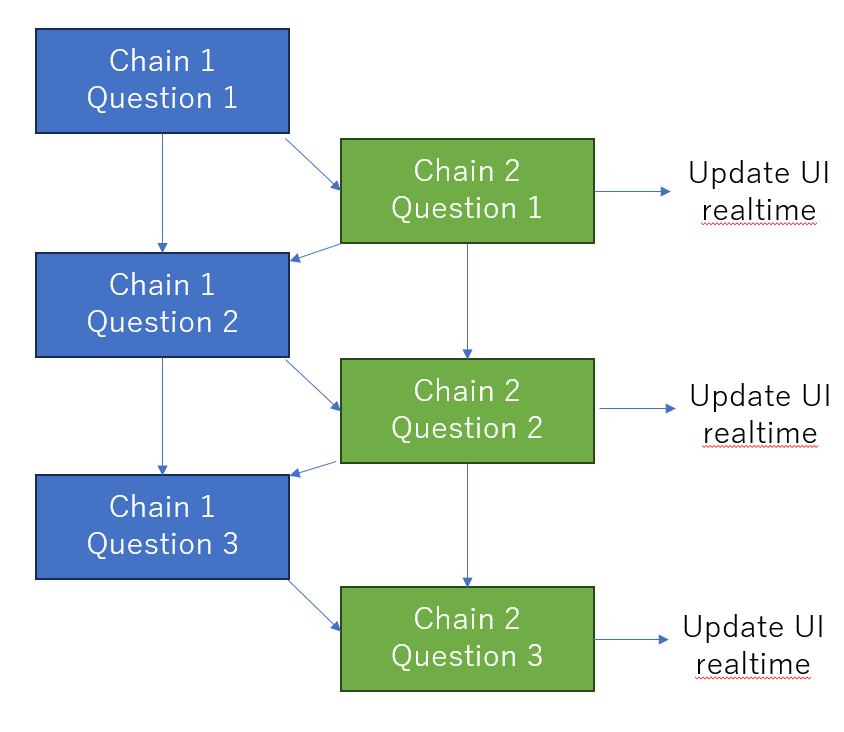
この場合は、例えば、Chain1 Question2とChain2 Question1を同じfactoryに入れて並行処理させて、Chain2のほうだけストリーミングとしてUIに反映させれば良いということになります。ともかくこういった連鎖的なんだけど、非同期要素のあるChainというのは実践的にまあまああるので、皆さんどうしているんだろうと思いました。ChatGPTやLangChainを騒いでいる割には、このへんの情報が全然出てこなかったので、今のメインユーザーはこんなこと気にしないのでしょうかね。
ちなみにUIのスレッドがどうというのは、C#でデスクトップアプリ作ってたときに結構よく見たので(Forms時代はUIの反映をメインスレッドからしないといけなかった)、懐かしいなと思いながらやっていました。asyncioを使いたかったのは発想が似ているというのもあります。
失敗例:LangChainのコールバックを使った例
最後に失敗例を示します。LangChainのChainで推論し、コールバックでUIに引き渡す例です。UIのコンテクストとの違いが問題になり正常に反映されません。
from langchain.prompts import ChatPromptTemplate, HumanMessagePromptTemplate, MessagesPlaceholder
from langchain.chat_models import ChatOpenAI
from langchain.memory import ConversationBufferMemory
from langchain.chains import LLMChain
from langchain.callbacks.base import BaseCallbackHandler
import streamlit as st
import asyncio
class StreamHandler(BaseCallbackHandler):
def __init__(self, panel):
self.text = ""
self.panel = panel
def on_llm_start(self, *args, **kwargs):
self.text = ""
with self.panel:
with st.chat_message("assistant"):
self.container = st.empty()
def on_llm_new_token(self, token, **kwargs):
self.text += token
self.container.markdown(self.text)
async def logic(location, key, panel):
handler = StreamHandler(panel)
llm = ChatOpenAI(model="gpt-3.5-turbo-0613", temperature=0.2, max_tokens=512, streaming=True, callbacks=[handler])
prompt = ChatPromptTemplate.from_messages([
MessagesPlaceholder(variable_name="chat_history"),
HumanMessagePromptTemplate.from_template("{human_input}")
])
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
chain = LLMChain(
llm=llm, memory=memory, prompt=prompt)
questions = [
"こんにちは",
f"{location}の観光名所を教えて",
f"この観光名所の{location}駅からの行き方は?"
]
answers = []
for question in questions:
# Add to state
st.session_state[f"messages{key}"].append({
"role": "user",
"content": question
})
# add to ui
with panel:
with st.chat_message("user"):
st.markdown(question)
# run chain
ans = await chain.arun(human_input=question)
# add to state
st.session_state[f"messages{key}"].append({
"role": "assistant",
"content": ans
})
# add to ui
answers.append(ans)
return answers
async def task_factory(parameters):
tasks = []
for param in parameters:
t = asyncio.create_task(logic(*param))
tasks.append(t)
return await asyncio.gather(*tasks)
def main():
if "messages1" not in st.session_state:
st.session_state.messages1 = []
st.session_state.messages2 = []
st.title("Multiple Streaming Chat")
column_left, column_right = st.columns(2)
button = st.button("Click to start chats")
with column_left:
for message in st.session_state.messages1:
with st.chat_message(message["role"]):
st.markdown(message["content"])
with column_right:
for message in st.session_state.messages2:
with st.chat_message(message["role"]):
st.markdown(message["content"])
if button:
parameters = [
("東京", 1, column_left),
("京都", 2, column_right)
]
asyncio.run(task_factory(parameters))
if __name__ == "__main__":
main()
LangChainのChainまたは、Callbackのスレッドないしコンテクストが問題なようです。これがUIのコンテクストと異なる結果、返答が正常に表示されないようです。コンソールを見ると以下のようなエラーがズラッと出ていました。
2023-09-30 16:33:34.675 Thread 'asyncio_2': missing ScriptRunContext
2023-09-30 16:33:34.675 Thread 'asyncio_2': missing ScriptRunContext
2023-09-30 16:33:34.701 Thread 'asyncio_0': missing ScriptRunContext
2023-09-30 16:33:34.702 Thread 'asyncio_0': missing ScriptRunContext
2023-09-30 16:33:34.714 Thread 'asyncio_2': missing ScriptRunContext
2023-09-30 16:33:34.715 Thread 'asyncio_2': missing ScriptRunContext
2023-09-30 16:33:34.725 Thread 'asyncio_0': missing ScriptRunContext
2023-09-30 16:33:34.725 Thread 'asyncio_0': missing ScriptRunContext
2023-09-30 16:33:34.745 Thread 'asyncio_2': missing ScriptRunContext
2023-09-30 16:33:34.745 Thread 'asyncio_2': missing ScriptRunContext
2023-09-30 16:33:34.754 Thread 'asyncio_0': missing ScriptRunContext
2023-09-30 16:33:34.754 Thread 'asyncio_0': missing ScriptRunContext
2023-09-30 16:33:34.764 Thread 'asyncio_2': missing ScriptRunContext
2023-09-30 16:33:34.764 Thread 'asyncio_2': missing ScriptRunContext
2023-09-30 16:33:34.825 Thread 'asyncio_0': missing ScriptRunContext
何も考えずに実装するとおそらくこうなるはずです。このエラーについては以下のような解決策が用意されていますが、asyncioとの結合方法については情報がありませんでした。
- https://github.com/streamlit/streamlit/issues/1326
- https://discuss.streamlit.io/t/concurrency-with-streamlit/29500
正直ちゃんとしたフロントエンドフレームワークを使わないとここは解決しないのかなと思っていたのですが(Streamlitはデモ向けなのでおもちゃ的な使い方しかできない)、バックエンドを立てなくても解決法があったためおお…となりました。
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー