
論文まとめ:MixEval: Deriving Wisdom of the Crowd from LLM Benchmark Mixtures


- タイトル:MixEval: Deriving Wisdom of the Crowd from LLM Benchmark Mixtures
- URL:https://mixeval.github.io/
- 論文:https://arxiv.org/abs/2406.06565
目次
要約By Claude-3 Haiku
この論文において解決したい課題は何?
LLMの評価における課題として、以下の3つのバイアスが指摘されています。
1) クエリバイアス – 評価クエリの網羅性や適切な分布が不足している
2) 採点バイアス – 採点プロセスに大きなバイアスや誤りが含まれている
3) 一般化バイアス – モデルがベンチマークデータに過剰に適応してしまう
先行研究だとどういう点が課題だった?
従来の自動ベンチマークは、クエリの網羅性や現実世界の多様性を捉えられていない一方で、LLMを採点者として使うアプローチは採点バイアスの問題がある。また、これらのベンチマークは静的なため、時間とともに劣化・汚染されてしまう。一方、大規模なユーザ評価ベンチマークは信頼性が高いが、コストと時間がかかり再現性がない。
先行研究と比較したとき、提案手法の独自性や貢献は何?
提案するMixEvalは、効率的で公平な基準ベンチマークを実現するために、1) 効率的で採点の公平性が高い基準ベンチマーク、2) 現実世界のクエリ網羅性と分布を反映したユーザクエリを組み合わせる新しいアプローチです。これにより、従来の課題を解決しつつ、高い相関と効率性を両立しています。
提案手法の手法を初心者でもわかるように詳細に説明して
MixEvalは2段階のパイプラインで構成されています。
- ウェブからユーザクエリを検出する
- オープンソースのLLMを使ってCommon Crawlからクエリを検出し、GPT-4でフィルタリングして分類する
- 既存ベンチマークとウェブクエリをマッチングする
- 既存の基準ベンチマークプールから、ウェブクエリと最も類似したクエリとその正解を抽出する
これにより、現実世界のクエリ分布と効率的な基準ベンチマークを組み合わせたMixEvalを構築します。さらに、MixEval-Hardではより難易度の高いサブセットを抽出しています。また、動的更新メカニズムにより、ベンチマークの汚染を抑制しています。
提案手法の有効性をどのように定量・定性評価した?
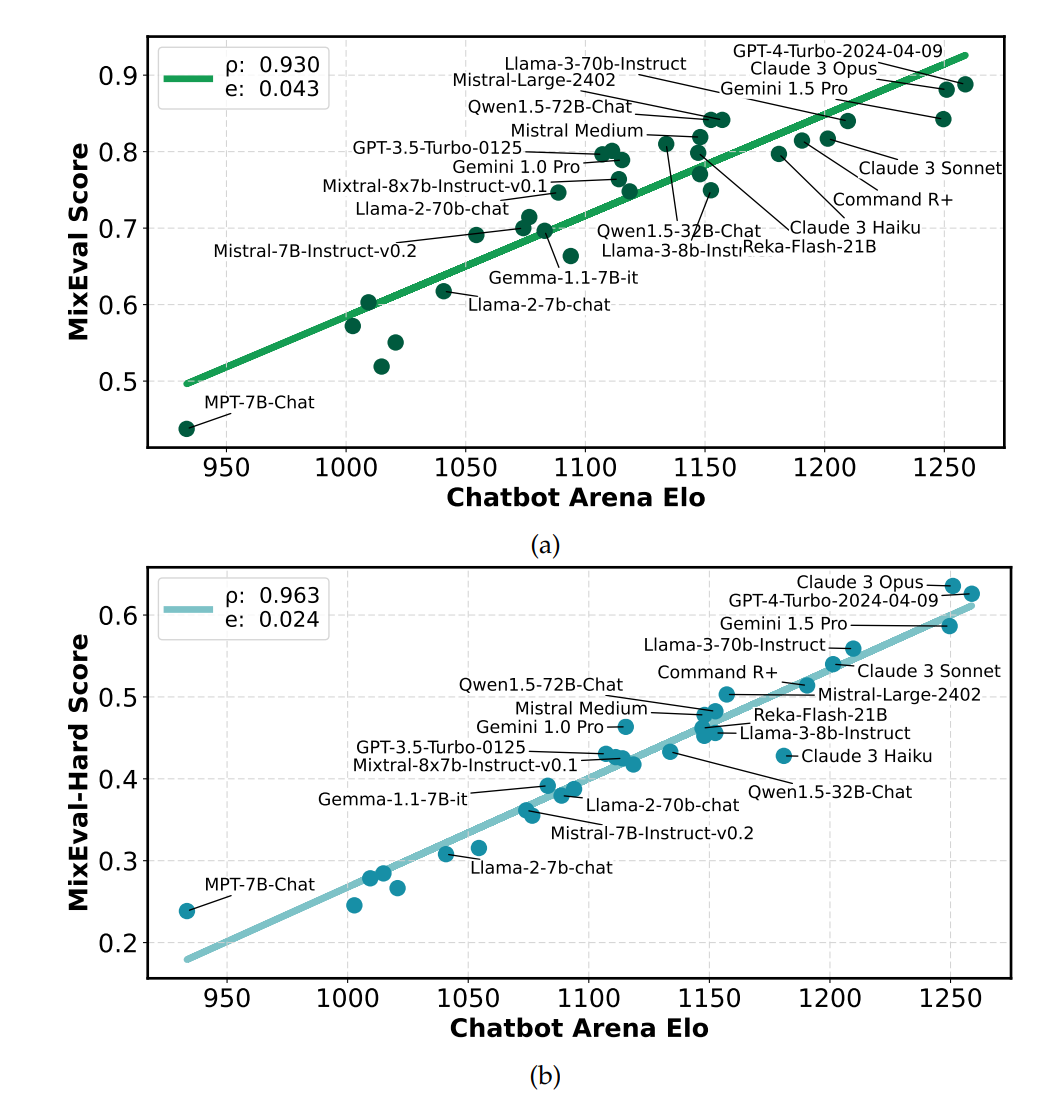
MixEvalとMixEval-Hardは、ユーザ評価ベンチマークであるChatbot Arenaとの相関が最も高く(それぞれ0.93, 0.96)、従来の自動ベンチマークを大きく上回っています。また、コストと時間が従来の10%以下と大幅に削減されています。さらに、動的更新メカニズムにより、モデルスコアの標準偏差が0.36と安定しています。
この論文における限界は?
提案手法では、ウェブクエリ検出パイプラインの精度や、Common Crawlデータ収集の偏りなど、いくつかの潜在的なバイアスが残っています。また、MixEval-Hardの更新にはある程度の時間がかかるという限界もあります。
次に読むべき論文は?
* MAmmoTH2: Scaling Instructions from the Web
* ウェブからドメイン特化型クエリを大規模に抽出する手法
* From Live Data to High-Quality Benchmarks: The Arena-Hard Pipeline
* ユーザ評価ベンチマークの構築と更新に関する手法
* Rethinking Benchmark and Contamination for Language Models with Rephrased Samples
* ベンチマークの汚染問題に関する分析と対策
また、提案手法のコードはhttps://mixeval.github.io/ で公開されています。
導入
先行研究の課題
- LLMベースの評価
- 有効だが3つのバイアスがある
- クエリバイアス
- 採点バイアス
- 一般化バイアス
- 有効だが3つのバイアスがある
- MMLUのようなGround Truthベースのベンチマーク
- 公平な等級付けプロセスが可能
- 実世界のクエリの包括性とニュアンスを捉えられない
- MT-Benchのような等級付け+LLMによるベンチマーク
- 優先順位についての高いアノテーションコスト
- 問い合わせの包括的ではなく、Staticなデータなので時間経過で劣化する
- Chatbot Arenaのような大規模な人間ベースの評価
- 3つのバイアスの緩和
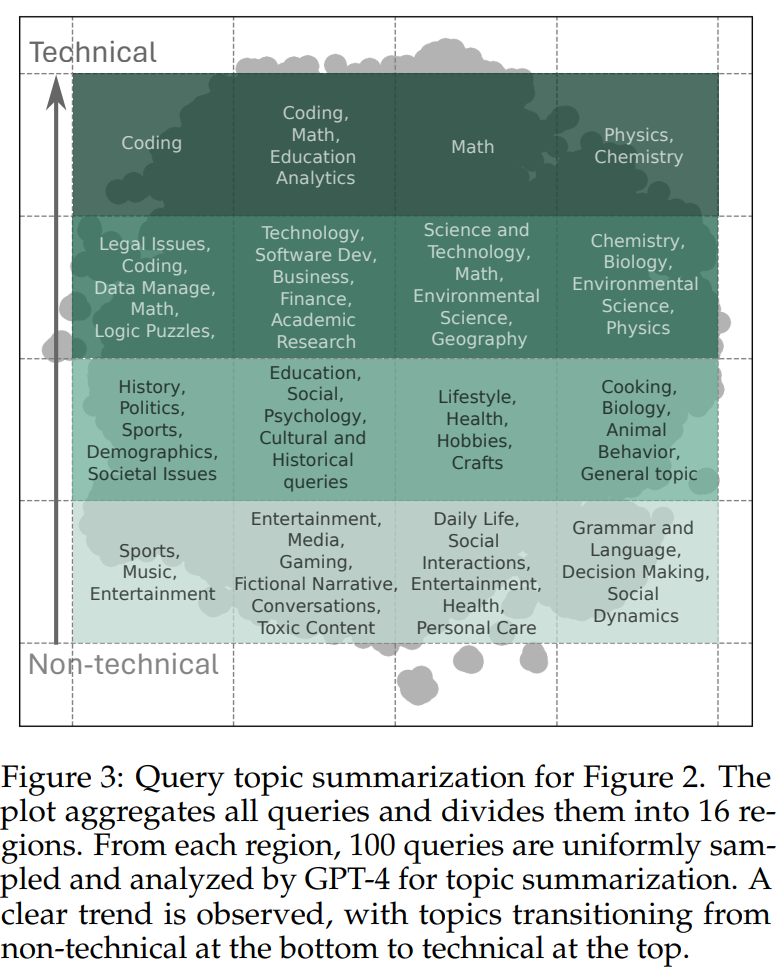
- クエリバイアス→実世界のユーザークエリを大量に収集するため、包括性はある
- Chatbot ArenaやLMSYS-Chat-1Mはクエリトピックについてはやや技術よりのバイアスはある
- 下の図は、16分割した領域をGPT-4でトピック要約
- 採点バイアス→個人の判断ノイズの回避(「群衆の知恵」効果)
- 一般化バイアス→継続的にクエリを受信するため、時間経過の劣化にロバスト
- クエリバイアス→実世界のユーザークエリを大量に収集するため、包括性はある
- その一方で法外な採点コストがかかる
- 3つのバイアスの緩和
本研究の目的:Chatbot Arenaのような手法だが、低コストでできる手法を考えた
How?
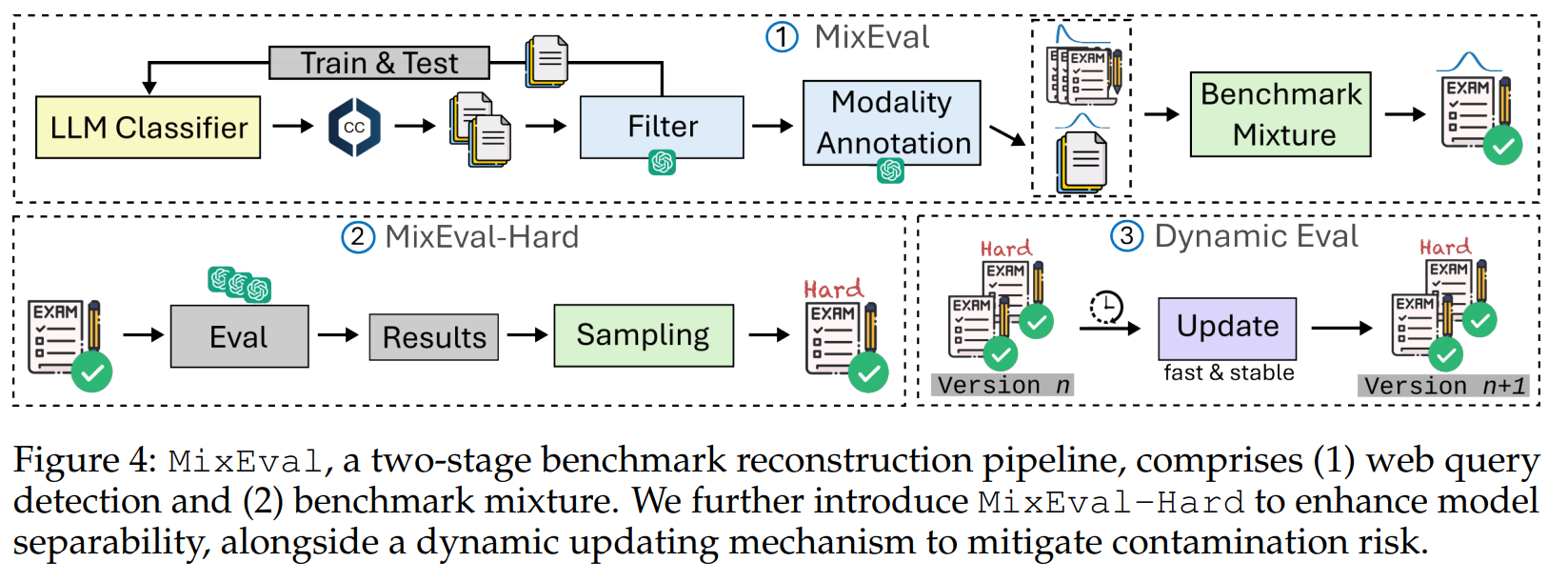
- 2つの要素からなる、ベンチマーク再構成パイプライン「MixEval」
- クエリマイニング
- マイニングされたクエリにおける既存のベンチマークのGrounding
- 3つの流れ:
- クエリ検出
- Common Crawl分割のクエリを検出するため、自己収集したデータでオープンソースのLLMを学習
- フィルタリング
- GPT-4-Turboを利用し、クエリ以外の文章を除外
- 分類
- フィルタリングされたクエリを入出力モダリティによって分類
- ベンチマーククエリの中から最も類似したクエリに対応するGround Truthの答えとマッチングさせる
- クエリ検出
MixEval
Webユーザークエリ検出
- Common Crawlから実環境のシナリオに必要な、ユーザークエリを検出したい(分類モデルによるフィルタリング+生成)
- 実世界のシナリオを反映するようなPrecision Recallの両方が重要
- 予備実験
- 1つ目:Wekipediaのデータセットをネガティブ、自己収集した実環境のユーザークエリをポジティブ
- 2つ目:手作業で選んだポジティブとネガティブのサンプル(高品質)
- フィルタリングはGPT-4、クエリ生成はVicuna 33Bを学習
ベンチマークの混合
- 行うこと:クエリ文→どのデータセットが適しているか?のマッピング
- データセットにわたりSentence Embeddingを計算し、データセット内で最大のクエリ(Top1)をデータセットの類似度とする。それを最大とするようなデータセットにマッピング
Ops的な部分
- 静的なベンチマークだと時間経過で劣化してしまう
MixEval-Hard
- LLMの急速な進化でサチってるから難しい問題だけ抽出したい
- 回答の結果から、クエリあたりの難易度スコアを推定し、より高い難易度のクエリを1000個抽出

結果
Arena Eloと高い相関
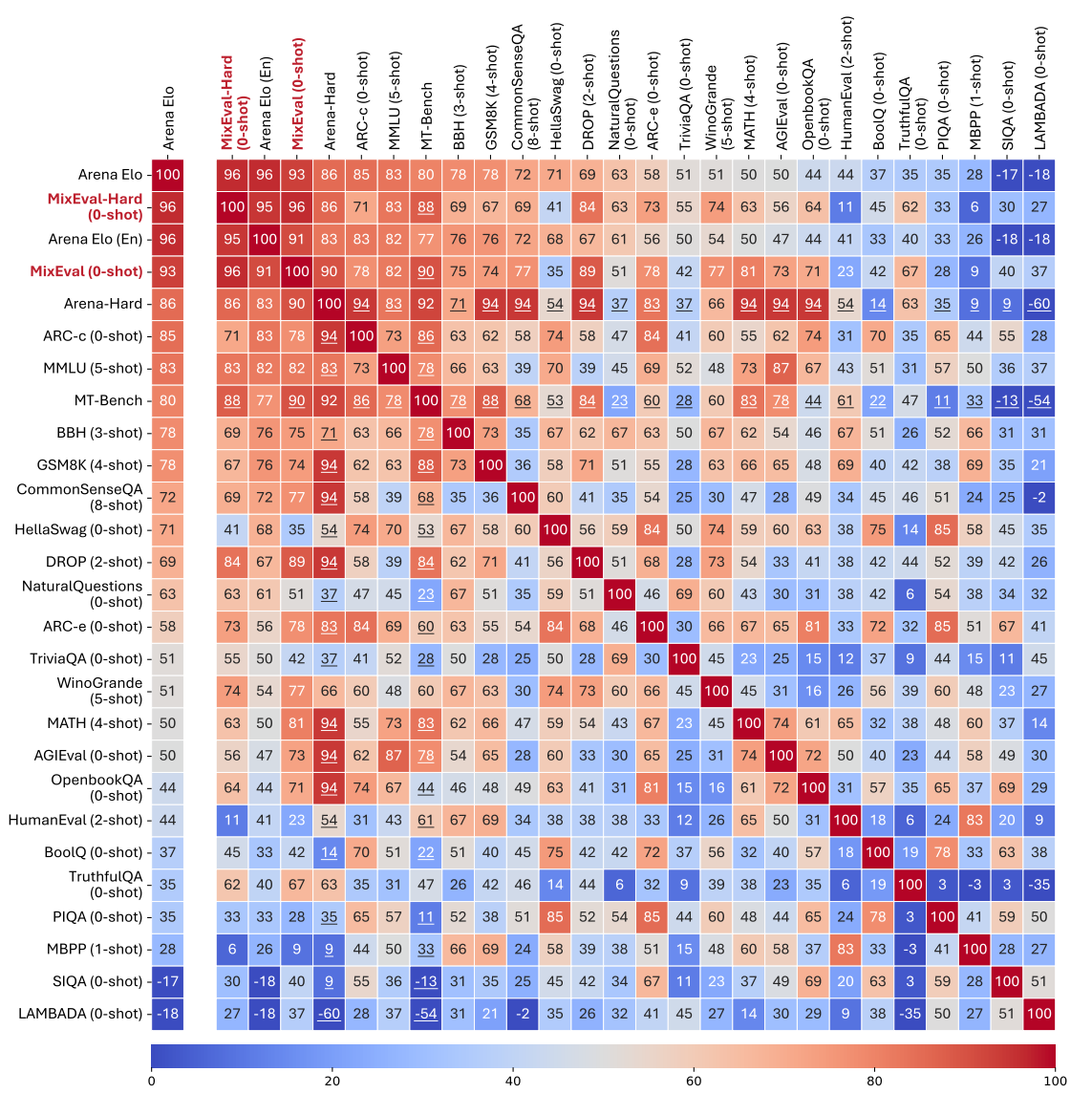
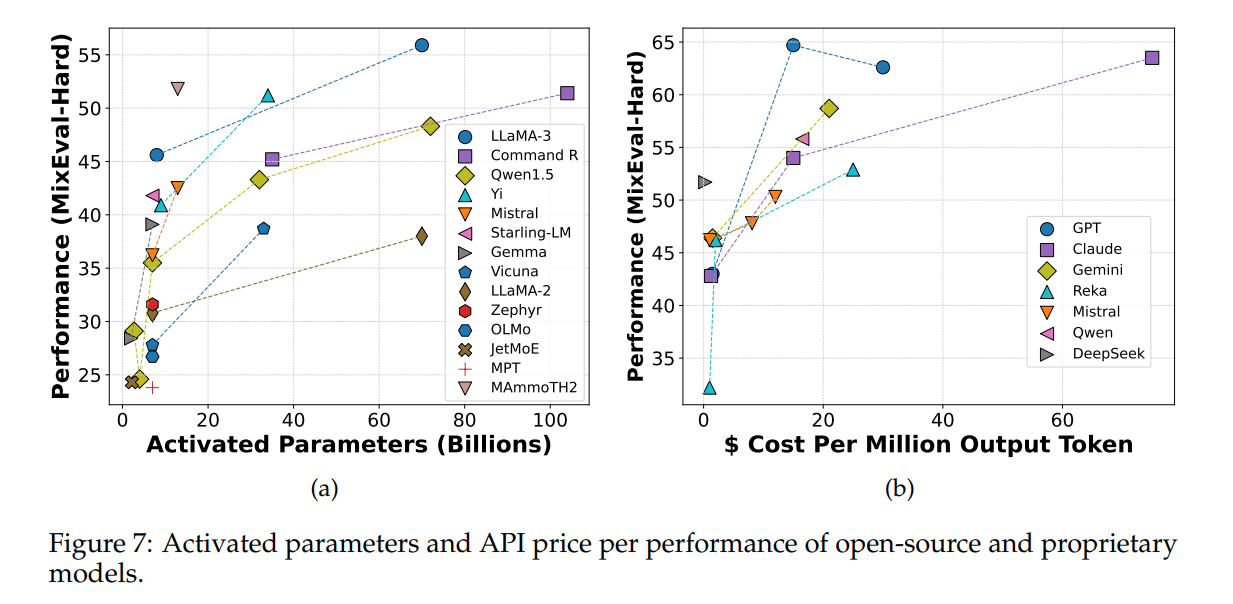
パラメーター数と性能、コストと性能のトレードオフを考慮可能(物体検出の図っぽい)
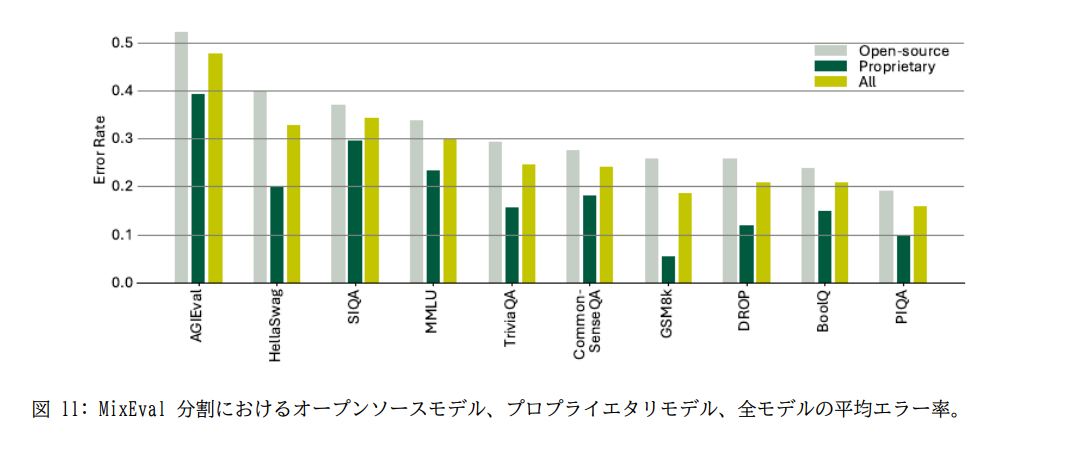
エラー分析
AGI Evalにおける誤差が大きい
→(私の注釈):AGI Evalのデータの多くは高考から取れており、中国のドメインスペシフィックな問題が多いのではないか?
{kind=link}
所感
- フィルタリング部分をGPT-4にやらせているのが原因ではないだろうか? ローカルで動く分類モデルでもよかったのでは?
- 発想はいいが、アブレーションがないのが論文として弱い。合成するよりも、検索してGround Truthの答えをそのままとってきたほうが良いというところのアブレーションがほしい
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー