
論文まとめ:Human Preference Score v2: A Solid Benchmark for Evaluating Human Preferences of Text-to-Image Synthesis
Posted On 2024-05-22


* タイトル:Human Preference Score v2: A Solid Benchmark for Evaluating Human Preferences of Text-to-Image Synthesis
* 著者:Xiaoshi Wu, Yiming Hao, Keqiang Sun, Yixiong Chen, Feng Zhu, Rui Zhao, Hongsheng Li(香港中文大学、SenseTime Researchなど)
* 論文URL:https://arxiv.org/abs/2306.09341
* GitHUb : https://github.com/tgxs002/HPSv2 ※Apache 2.0
目次
ざっくりいうと
- テキストから生成された画像の質を正確に評価する新しい指標HPS v2を開発
- 専用のアノテーションチームで大規模なデータセットHPD v2を構築
- HPS v2は、HPD v2を用いて幅広いモデルの生成画像を正確に評価できるよう訓練され、既存指標よりも一般化性が高い。
1分で読む用
要約By Claude3
- この論文において解決したい課題は何?
- この論文において解決したい課題は、テキストから画像を生成するモデルの生成画像の質を正確に評価することです。既存の評価指標はテキスト-画像の整合性を適切に捉えられていないため、人間の好みを反映した新しい評価指標の開発が必要とされていました。
- 先行研究だとどういう点が課題だった?
- 先行研究では、Inception Score (IS)やFréchet Inception Distance (FID)などの一般的な評価指標が、テキスト-画像生成モデルの生成画像の質を適切に評価できないことが示されていました。また、人間の好みを反映した評価指標として提案されたHPS v1やImageReward、PickScoreなどのモデルも、特定のモデル(主にStable Diffusion)に偏った評価しかできないという課題がありました。
- 先行研究と比較したとき、提案手法の独自性や貢献は何?
- 本論文では、より幅広いモデルの生成画像を含む大規模なデータセットHPD v2を構築し、それに基づいて訓練された新しい評価指標HPS v2を提案しています。HPS v2は既存の指標よりも一般化性が高く、テキスト-画像生成モデルの改善を適切に捉えられることが示されています。
- 提案手法の手法を初心者でもわかるように詳細に説明して
- HPS v2は、CLIP modelをHPD v2のデータで微調整することで構築されています。具体的には、同じプロンプトから生成された2つの画像に対して、人間がどちらを好むかを予測するように学習しています。
- 提案手法の有効性をどのように定量・定性評価した?
- HPD v2とHPS v2の有効性は、ImageRewardやPickScoreなどの既存指標との比較実験で示されています。また、HPS v2を用いてテキスト-画像生成モデルのベンチマークを行い、モデルの改善を定量的に評価しています。
- この論文における限界は?
- 本論文の限界としては、プロンプトの収集範囲が一部に偏りがちであること、アノテーターの人数が限られていることなどが挙げられます。
- 次に読むべき論文は?
- 今後は、より多様なプロンプトの収集や、より多数のアノテーターを活用することで、HPS v2のさらなる一般化性の向上が期待されます。また、生成画像の解像度がヒトの好みに与える影響なども検討する必要があります。
概要
- やりたいこと:人間の好みを反映した画像生成の評価手法の作成
- 既存手法の課題:
- Stable Diffusionに特化しすぎて他のモデルを反映できない
- ImageRewardやHPD v1はDiscordからとってきたが、スタイルの偏りが強烈すぎる
- やったこと:いろんなスタイル・モデルに対応した専用のデータセットを作ってモデルを訓練した
データセットどう作った?
- Human Preference Dataset v2 (HPD v2) :434k枚からなる798k組の二値嗜好の選択
- 各ペアは1個のプロンプトから異なるモデルによって生成された画像。1人のアノテーターによって選ばれた2値のアノテーション
- 3ステップからなる
- プロンプト収集
- 画像収集
- 嗜好アノテーション
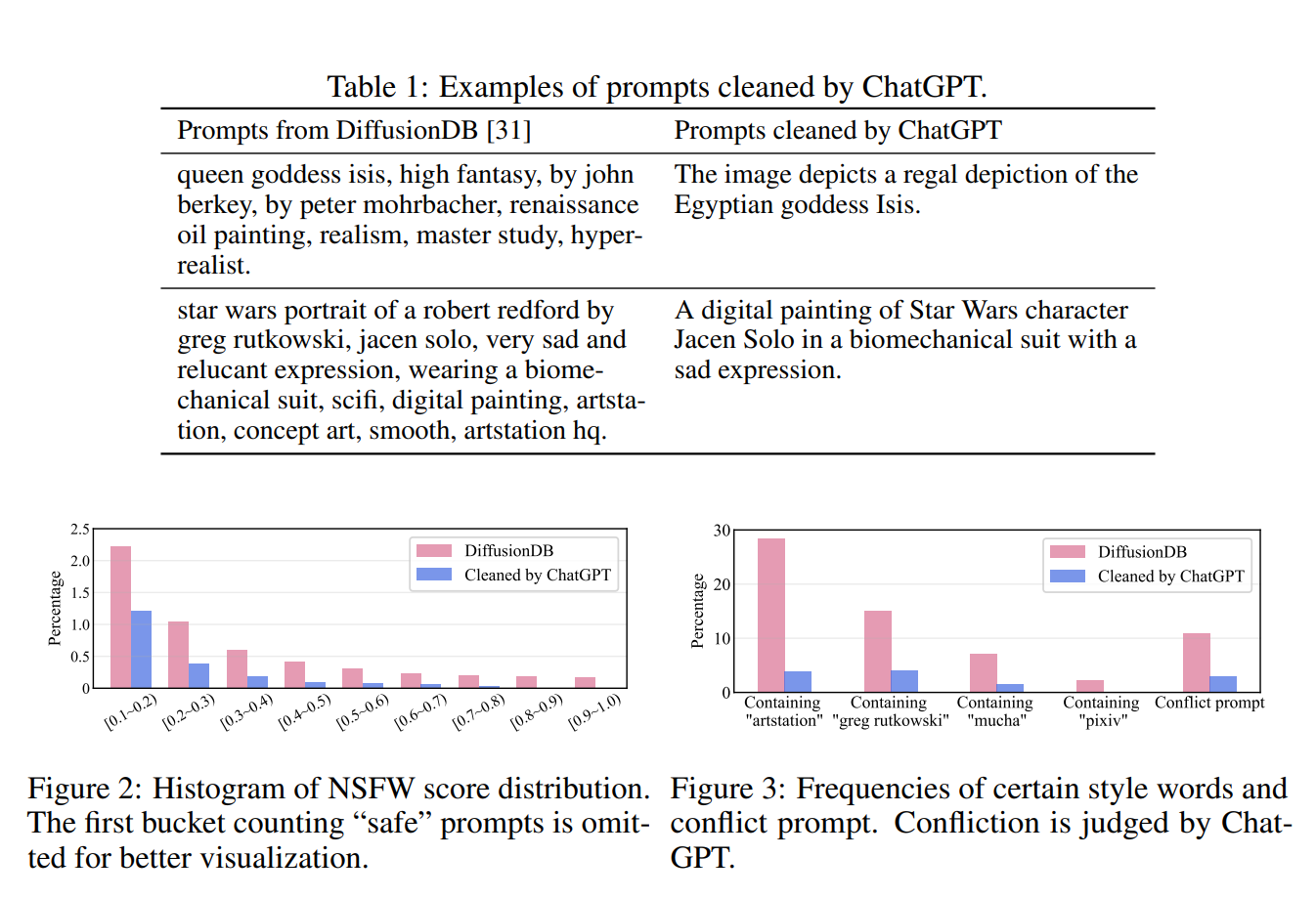
プロンプト収集
- 素朴なやり方:COCO CaptionsやLAIONから収集
- キャプションは実画像を記述もので、画像生成ユーザーの一般的な関心を反映していない可能性
- 「フィクション」のコンテンツは生成するユーザーの想像力に任される
- ユーザーが書いたプロンプトのソース:DrawBench、DiffusionDB
- 特定ワード(Greg Rutkowski、artstation、pixivなど)に偏っており、学習時に敵対的に機能する
- 矛盾した内容がある(“renaissance oil painting” vs “realism”, “hyper realistic”)
- これらをChatGPTを使ってクリーニングする
画像収集
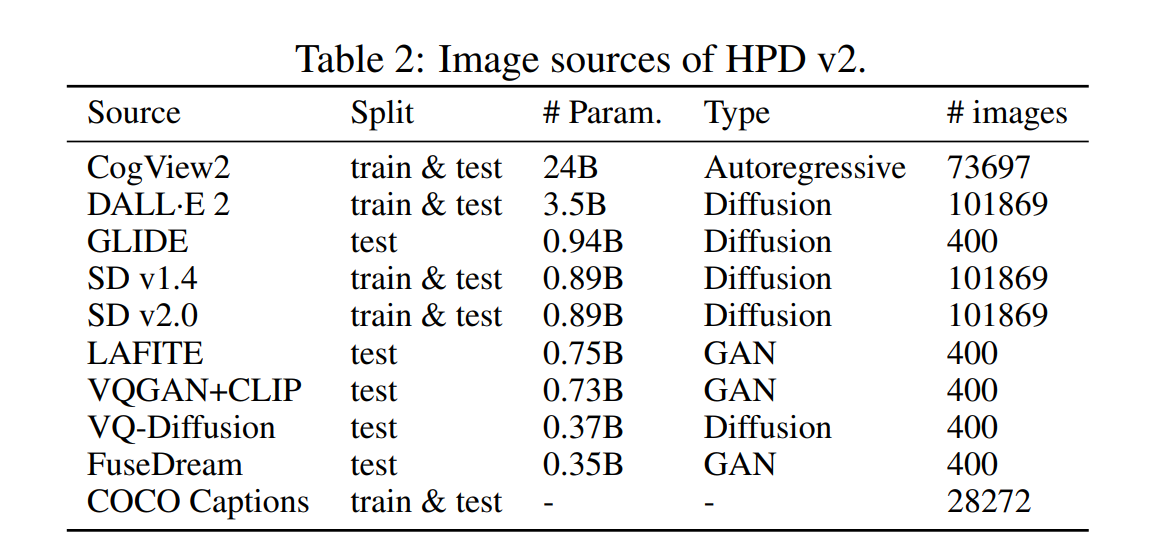
ポイントは、SDXLやDALL-E3が学習データに入っていないのに、その良さが評価できること
アノテーション
- 50人のアノテーターと7人の品質管理チェッカーからなる請負業者を雇った
- 10%のタスクを品質管理チェッカーによりクロスチェック
- 特に画像の好みはアノテーションしている人の属性にもよるので、アノテーターの統計を出している(これが珍しい)
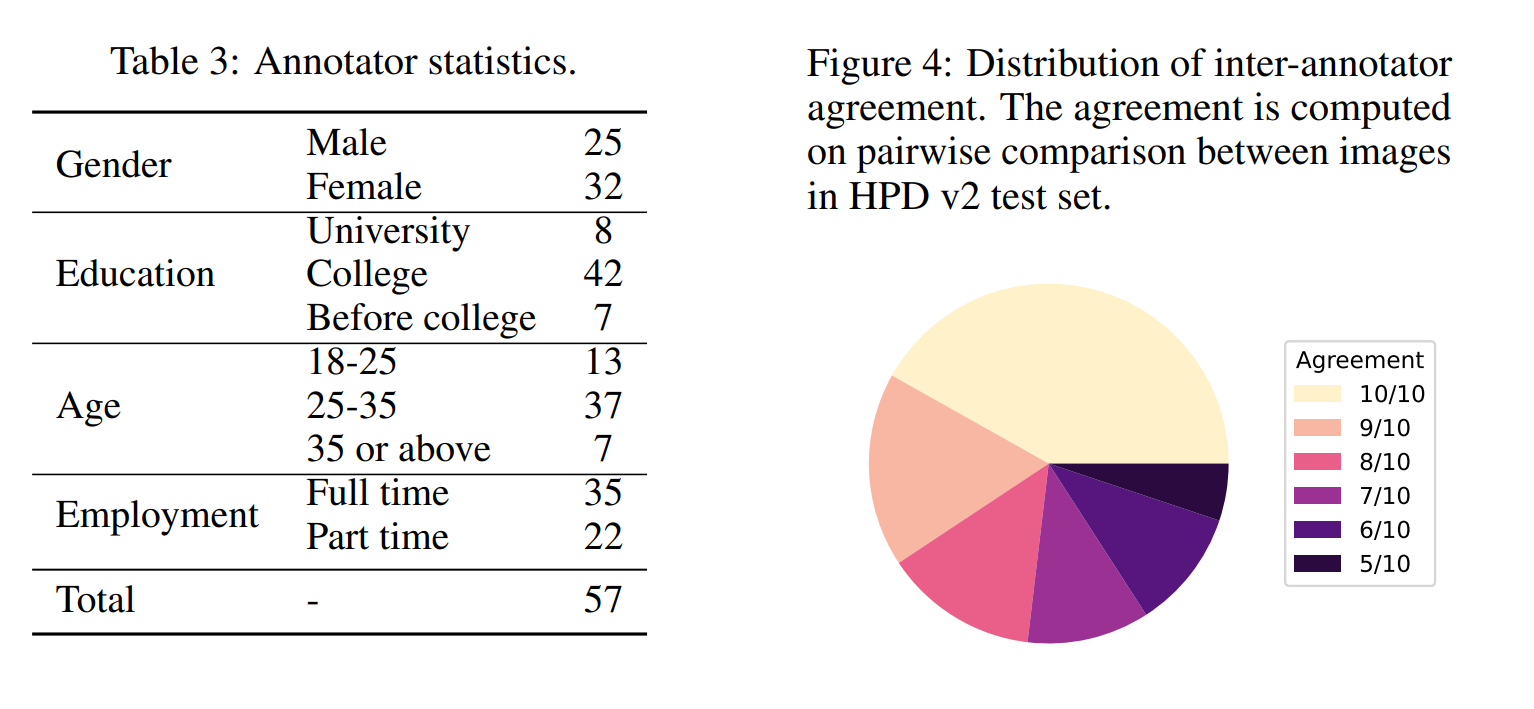
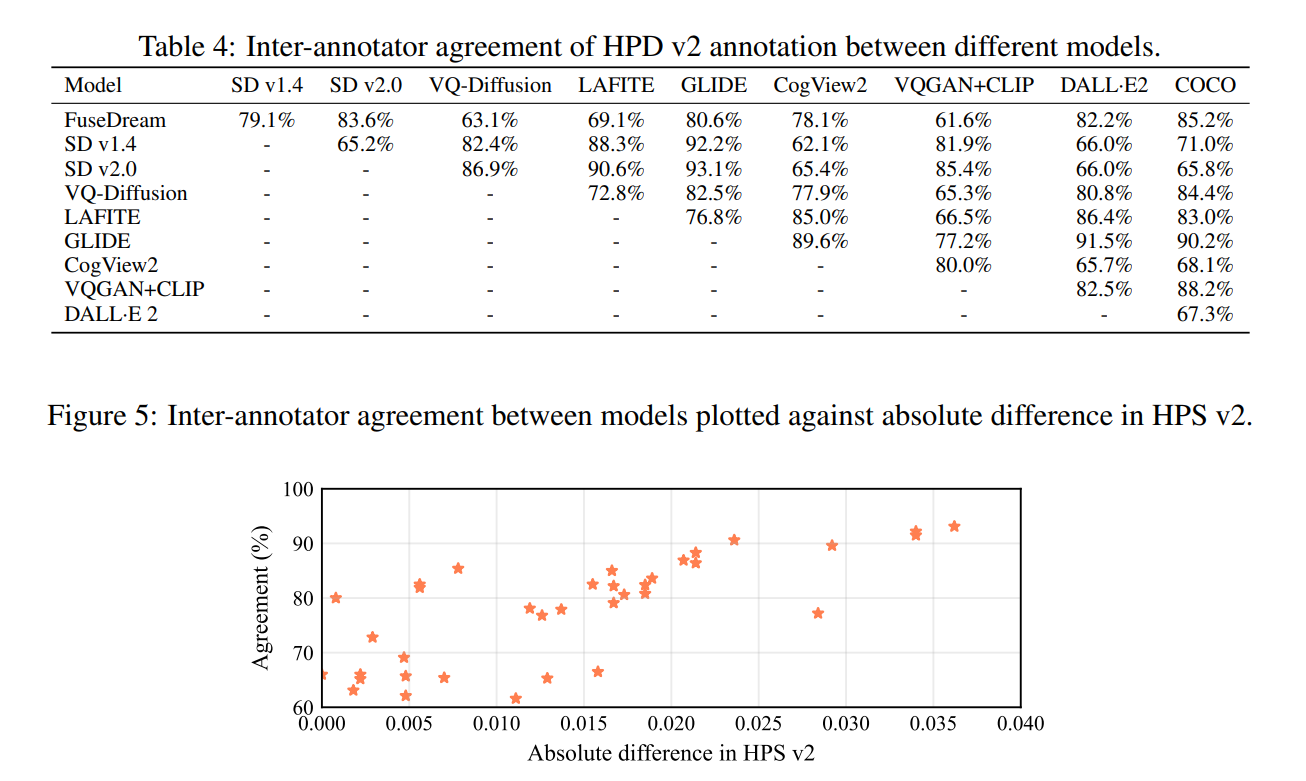
モデルの訓練
- CLIPをファインチューニングし、嗜好の順位を予測するようにする
- 人間の嗜好について、画像$x_1$>画像$x_2$の場合、$y=[1, 0]$でラベル付けする
- KL-Divergenceを最小化
結果
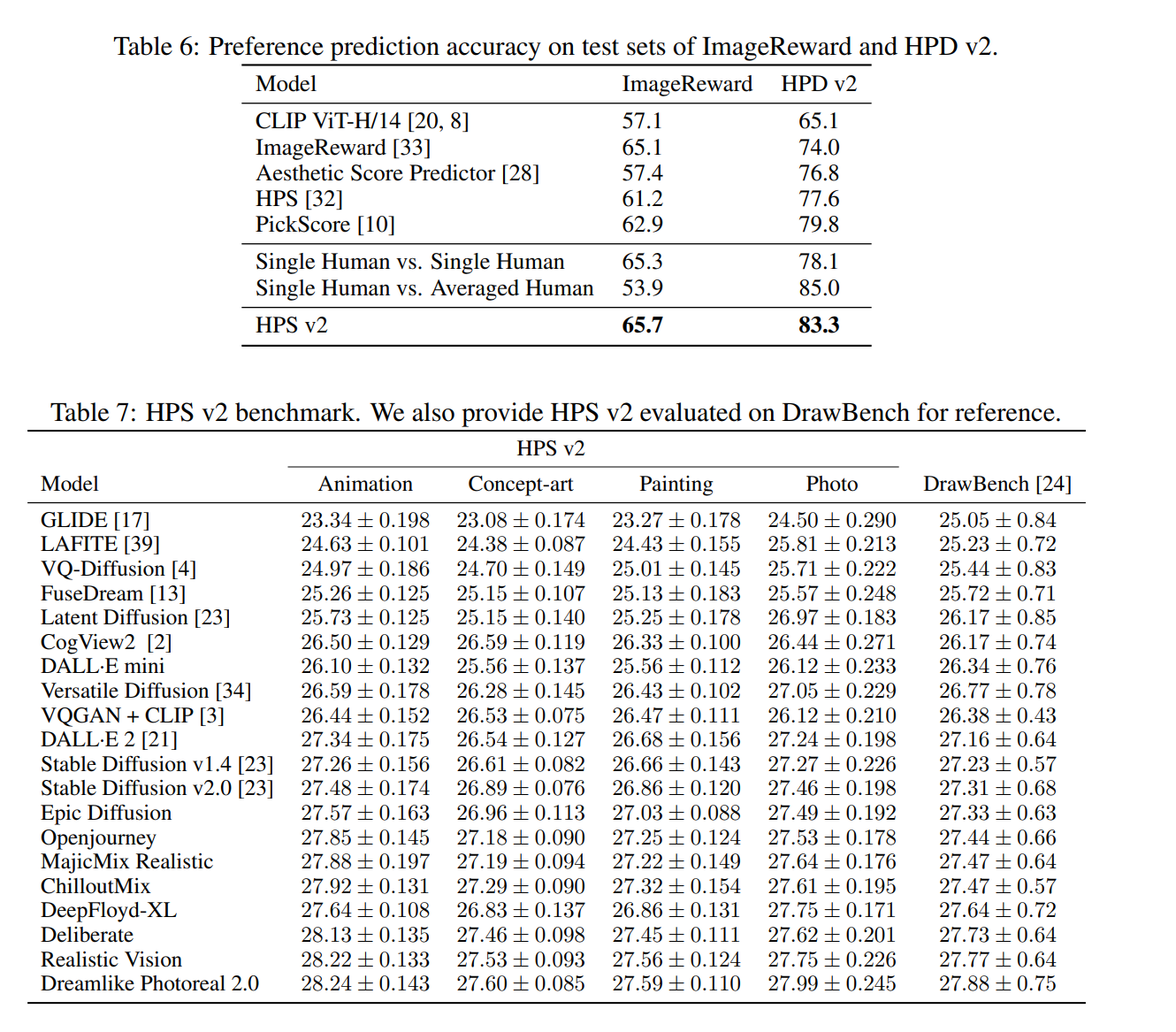
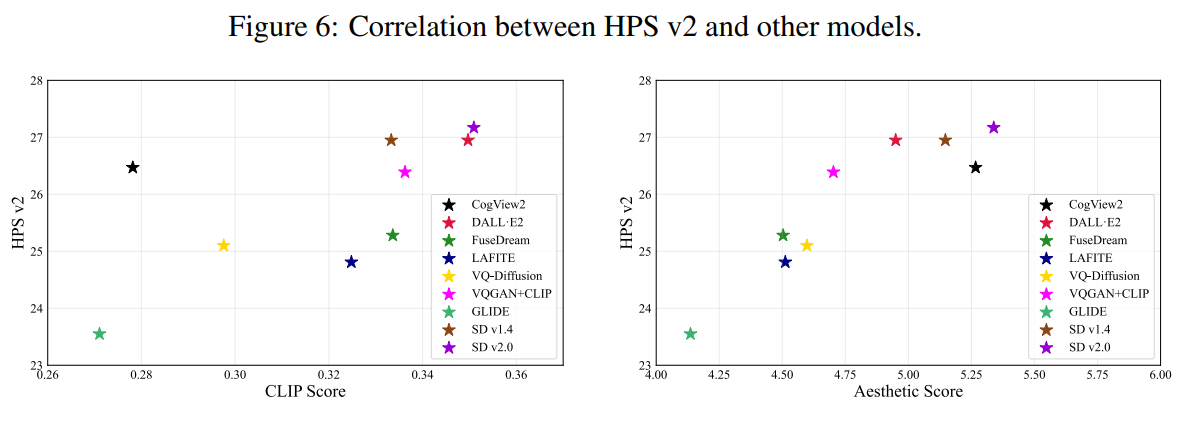
限界
- ChatGPTを使ったクリーニングは潜在的なバイアスになる(ただし、問題は特に見つかっていない)
- 解像度が人間の嗜好に影響を与えることは調査できていない
- 学習データに内在するバイアスやステレオタイプを増幅する可能性
試してみた


DALLE-3やSDXLまで汎化できている
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー