
論文まとめ:GRiT: A Generative Region-to-text Transformer for Object Understanding
Posted On 2023-07-27


- タイトル:GRiT: A Generative Region-to-text Transformer for Object Understanding
- 著者:Jialian Wu, Jianfeng Wang, Zhengyuan Yang, Zhe Gan, Zicheng Liu, Junsong Yuan, Lijuan Wang(所属:ニューヨーク州立大学バッファロー校、Microsoft)
- 論文:https://arxiv.org/abs/2212.00280
- コード:https://github.com/JialianW/GRiT
目次
ざっくりいうと
- 物体検出にImage Captioningを導入した「Dense Captioning」の研究
- 検出とテキスト生成の2段階からなり、画像特徴と、テキストトークンの特徴をText Decoderに入れてキャプション生成
- クローズドセットの物体検出に迫る性能を達成したほうか、LLMとの連携でも注目
問題設定
- 物体検出(Object Dectection)
- Input:画像
- Output:構造化データ(Bounding Boxの座標とクラスのID)
- Bounding Box単位の画像分類
- 画像キャプニング(Image Captioning)
- Input:画像
- Output:テキスト
- 入力画像全体に対するテキスト(説明文の生成)。これに対話が入るとVQA
- Dense Captioning
- Input:画像
- Output:構造化されたテキスト(Bounding Boxの座標と、Bounding Box単位のテキスト)
- Image CaptioningをBounding Box単位で行ったもの。視覚理解をもっとローレベルにすればOCRとも近い
- ChatGPTの登場により、有用性が注目されている
関連
TuringのTech Blog
導入
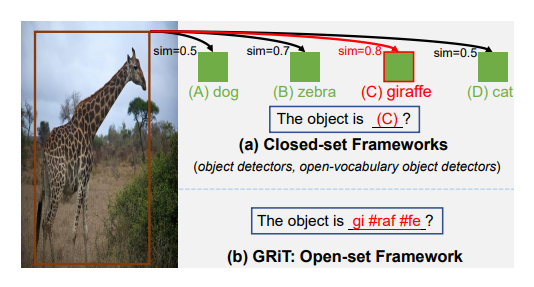
- オープンセット(ゼロショット)物体検出からの派生の文脈で生まれた研究
- 物体検出はただのクラス名を単語で出すのに対し、Dense Captioning(GRiT)は物体検出のBounding Boxに対してキャプション生成を行う
- クローズドセットだと多択問題を実行するように振る舞う。オープンセットだと新しい物体の学習が簡単で、より色や形に関連する補助的な知覚が可能
- GRiTの学習:短文記述(物体検出)と、長文記述(Dense Captioning)を同時学習
- キャプション生成モデルのGITの派生系
GRiT
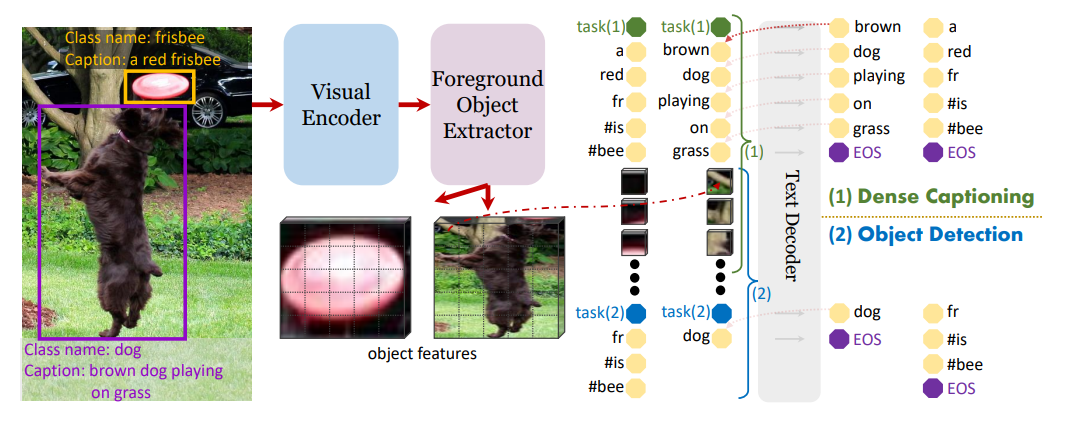
- GRiTのモデル構造
- Visual Encoder、Foreground Object Extractor、Text Encoderからなる自己回帰的なモデル
- Visual Encoder
- 先行研究のGITのバックボーンを使用し、FPN(解像度別に特徴マップを吐き出すこと)を適用
- 解像度に対して:(1/8, 1/16, 1/32, …, 1/128)
- FPN自体は従来のクローズドな物体検出で古くから使われている手法。参考
- Proposal GeneratorにCenterNet、RoIヘッドはCascade R-CNN
- バニラのViTにはHead間の情報交換としてAttentionがあるが、FPNは導入されていない
- ViTの最終層の特徴マップ(図のグリッド部分)から、単純にアップ/ダウンサンプリングして特徴マップを形成
- 先行研究のGITのバックボーンを使用し、FPN(解像度別に特徴マップを吐き出すこと)を適用
- Foreground Object Extractor
- 物体検出で使われるRoIヘッド。単なるDense層
- 通常の物体検出のRoIヘッドと異なる点
- 前景か背景か二値分類かしかしない(オブジェクトの確信度の分類)。通常の物体検出はマルチクラス分類
- Text Encoder
- InputはTextのトークンEmbeddingと、画像特徴
- トークナイザーはBERTのWordPiece
- テキストトークンがオブジェクト特徴のみAttendし、オブジェクトの特徴はそれ自身のみAttendするように、seq2seqのAttention Maskを適用
- 問題点:Text Encoderが短文生成(物体検出)すればいいのか長文生成(Dense Captioning)すればいいのかわからない。タスクの切り替えが必要
- 開始トークンの集合「[Task]i」を定義し、このトークンを切り替えるることで、生成スタイルのコントロールを行う
- 下の図でBOSは開始トークンを指定しない場合。物体検出の「Person」とDense Captioningの文章が混在して生成される
- InputはTextのトークンEmbeddingと、画像特徴
- 推論時には、物体検出からObjectness Score、キャプション側からDescription Scoreを計算。2つのスコアの平方根をかけ合わせる

定量評価
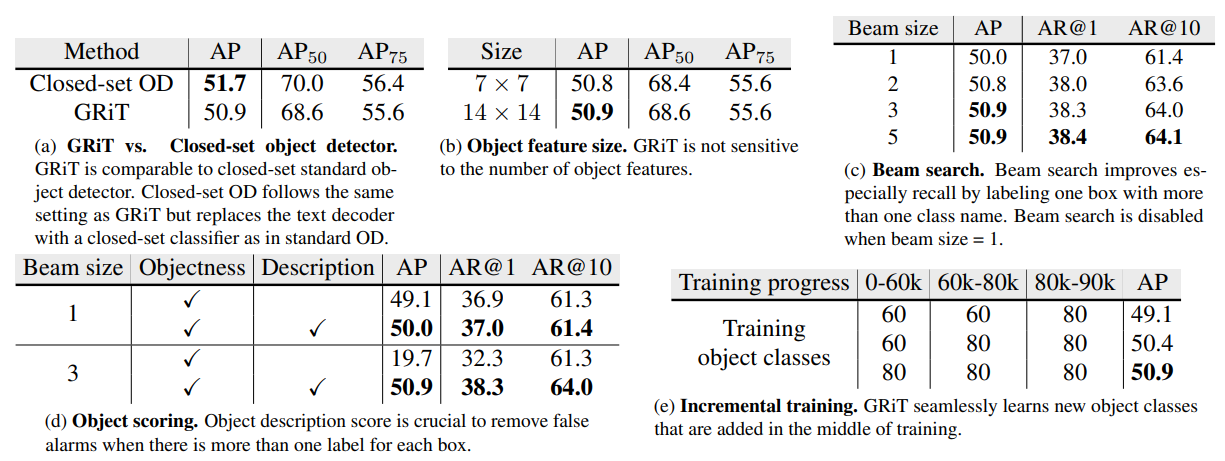
- クロード物体検出にせまる性能(a)
- Feature Mapのサイズには鋭敏ではない(b)
- 物体検出のObjectness Scoreとテキスト生成のDescription Scoreの両方計算するのが重要で、物体検出だけだとAPが大きく下がる(d)
- 訓練の途中でオブジェクトクラス数を追加する「Incremetal Training」でもロバスト(d)
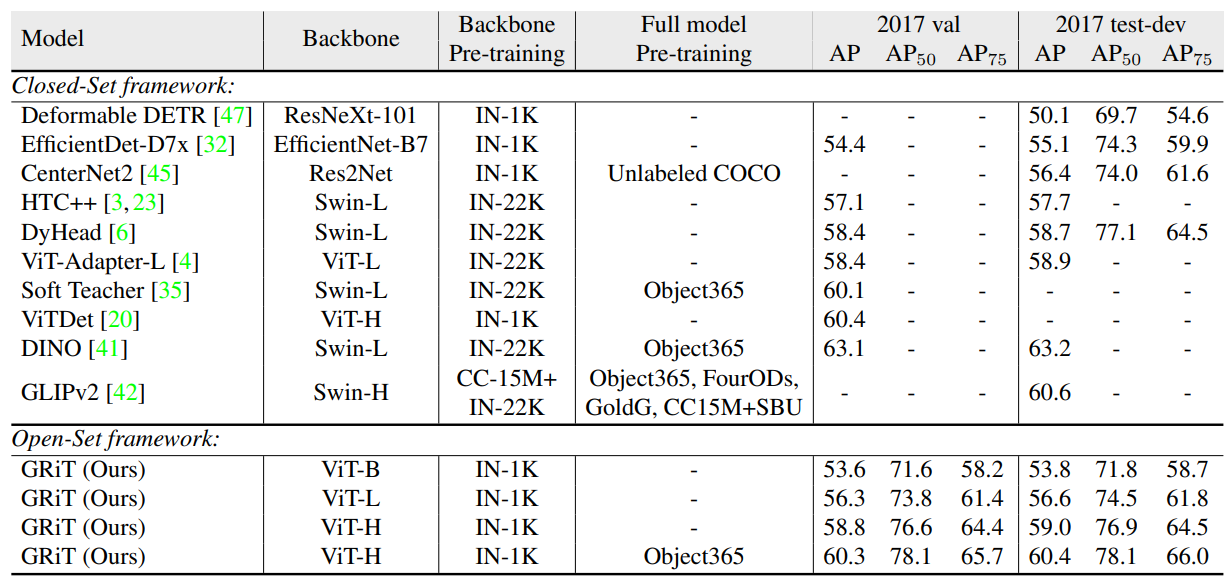
オープンセットの物体検出の性能としては、GLIPv2と同様
所感
- Turingのブログにもある通り、Dense Captioning自体はChatGPTの登場によって大きく注目されそう
- マルチモーダルなAttendの制御のためにAttention Maskを使うのはFlamingoと同じ発想
- GRiTはまだ改善の余地がありそう。2022年12月の論文なのでもっといいのが出てるかも?
- 自己回帰的な(seq2seq)フレームワークってのはややツッコミどころはありそう
- Text DecoerをT5かそれより大きめの言語モデルにして、もっとAttentionでゴリゴリやるほうが今風のやり方かも?
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー