
論文まとめ:Unveiling Encoder-Free Vision-Language Models
Posted On 2024-07-11

- タイトル:Unveiling Encoder-Free Vision-Language Models
- 著者:Haiwen Diao, Yufeng Cui, Xiaotong Li, Yueze Wang, Huchuan Lu, Xinlong Wang(BAAI)
- 論文URL:https://arxiv.org/abs/2406.11832
- コード:https://github.com/baaivision/EVE
- モデル:https://huggingface.co/BAAI/EVE-7B-Pretrain-v1.0 (Apache2.0)
目次
ざっくりいうと
- 解像度や縦横比の制限があるビジョンエンコーダを用いずに、視覚と言語を統合的に処理できるVLMを開発する研究。パッチ埋め込み層(PEL)とパッチアラインメントレイヤー(PAL)を導入し、LLM主導の事前アラインメントを含む三段階の学習プロセスを提案。
- 公開データセットのみを用いて開発されたEYE-7Bモデルが、既存のエンコーダ型VLMと同等以上の性能を達成し、エンコーダフリーVLMであるFuyu-8Bを大きく上回った。
- 言語能力の低下が見られるため、言語データの混合学習などを検討する必要があり、エンコーダ型VLMとの性能差をさらに縮小する余地がある。
要約By Claude3
この論文では以下の点について取り組んでいます。
- 課題:
- 既存のビジョン・ランゲージモデル(VLM)は、ビジョンエンコーダを使用して視覚特徴を抽出し、大規模言語モデル(LLM)でそれを処理するという構造になっている。しかし、ビジョンエンコーダには入力解像度や縦横比の制限があり、効率的な適用が難しい。エンコーダを使わずに視覚と言語を統合的に処理できるVLMを開発することが課題。
- 先行研究の課題: エンコーダなしでVLMを直接学習しようとすると、収束が遅く、性能が大幅に劣る。
- 提案手法の独自性と貢献:
- LLMを中心にビジョンと言語の事前アラインメントを行うことで、効率的な学習を実現。
- ビジョン特徴の視覚認識能力を高めるための監督学習を行うことで、性能を大幅に向上。
- 提案手法の詳細:
- パッチ埋め込み層でイメージを効率的にエンコーディング
- パッチアラインメント層で事前学習したビジョンエンコーダの特徴と整合させる
- 3段階の学習手順で、LLM主導の事前アラインメント、生成事前学習、教師あり微調整を行う
- 提案手法の評価:
- 公開データセットのみを使って、エンコーダ型VLMと同等以上の性能を達成
- 既存のエンコーダフリーVLMであるFuyu-8Bを大きく上回る
- 限界:
- 言語能力の低下が課題。言語データとの混合学習などが必要。
- エンコーダ型VLMとの性能差をさらに縮小する余地がある。
- 次に読むべき論文:
- 言語能力の維持と向上に関する研究
- エンコーダフリーVLMの性能をさらに高める手法の研究
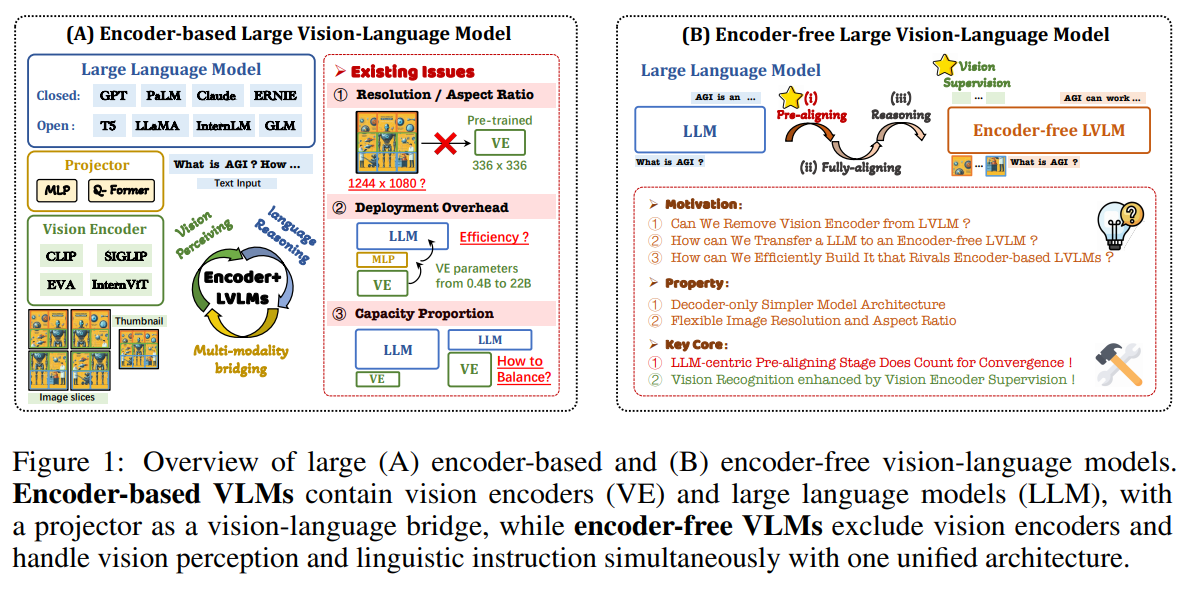
- 既存手法の課題
- 解像度:Vision Encoderは正方形の画像。高解像度の画像だと、パッチ分割により断片化やレイアウトの歪みが大きくなる
- オーバーヘッド:Vision EncoderとLLMが逐次実行になり、特に高解像度だと計算効率が損なう
- モデルサイズ:Vision EncoderとLLMのサイズについて不確実性が上がる
- Vision Encoderそのものを消してしまって、LLMDecoderだけにしてして、Vision & Languageモデルを作ろう
- Encoderを使わない場合の本質的な課題
- VLMをゼロから学習するのは高価。既存のLLMを活用するのが現実的
- LLMの言語能力を維持しながら、視覚認識を発達させるように強制して訓練する
- Vision Encoderが対比学習により獲得した視覚認識能力をどう伝える?
- Vision Backboneのパッチ特徴や、エンコーダーベースのVLMによって予測されたテキストラベルをアラインメントさせ、VLMに埋め込む
- 高価な再学習プロセスを回避
- VLMをゼロから学習するのは高価。既存のLLMを活用するのが現実的
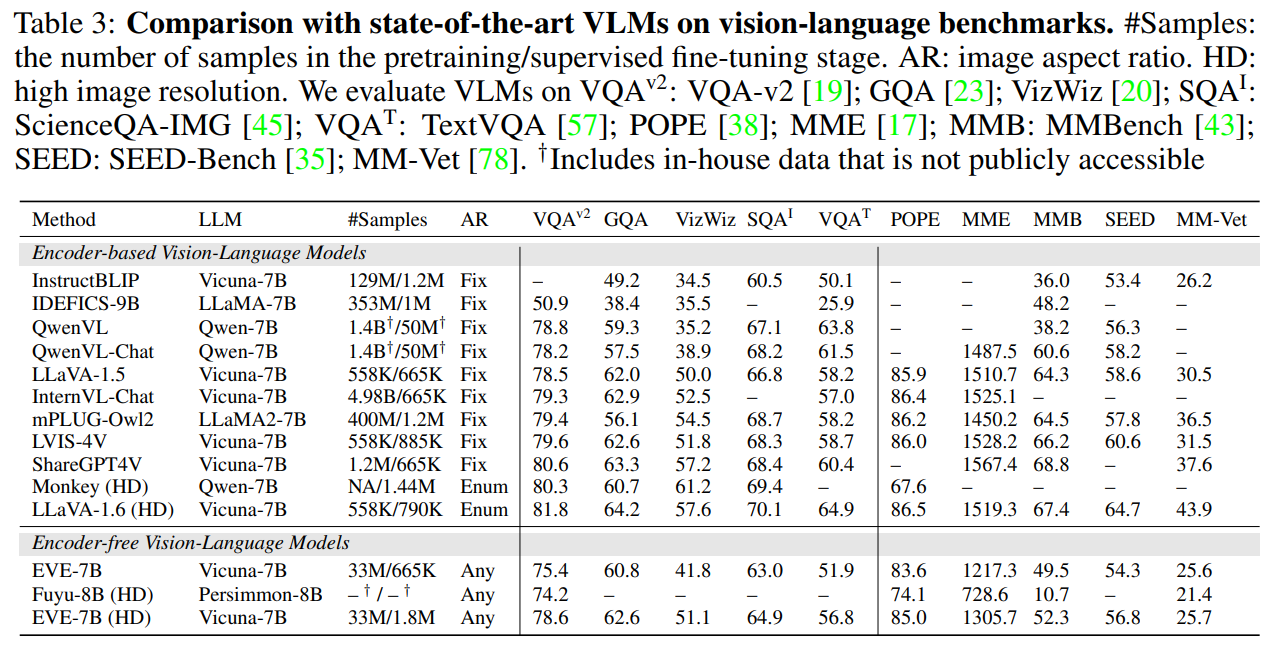
- EVE-7B
- Vicuna-7Bを進化させ、2×8-A100(40GB)で9日間させたEVE-7B
- 35Mの公開データだけで、複数の視覚言語タスクにおいて、エンコーダーベースのVLMに匹敵する性能
- Fuyu-8Bに対して大幅に上回ったという主張で、このモデルは学習手順や未公開の学習てデータに依存
- Fuyu-8Bが画像エンコーダーなしのデコーダーのみのVLMの先行研究
- 画像パッチを単純なLinear Projectionを通してモデルに入れているだけ
- 平均な性能で、学習戦略やデータの透明性に欠ける
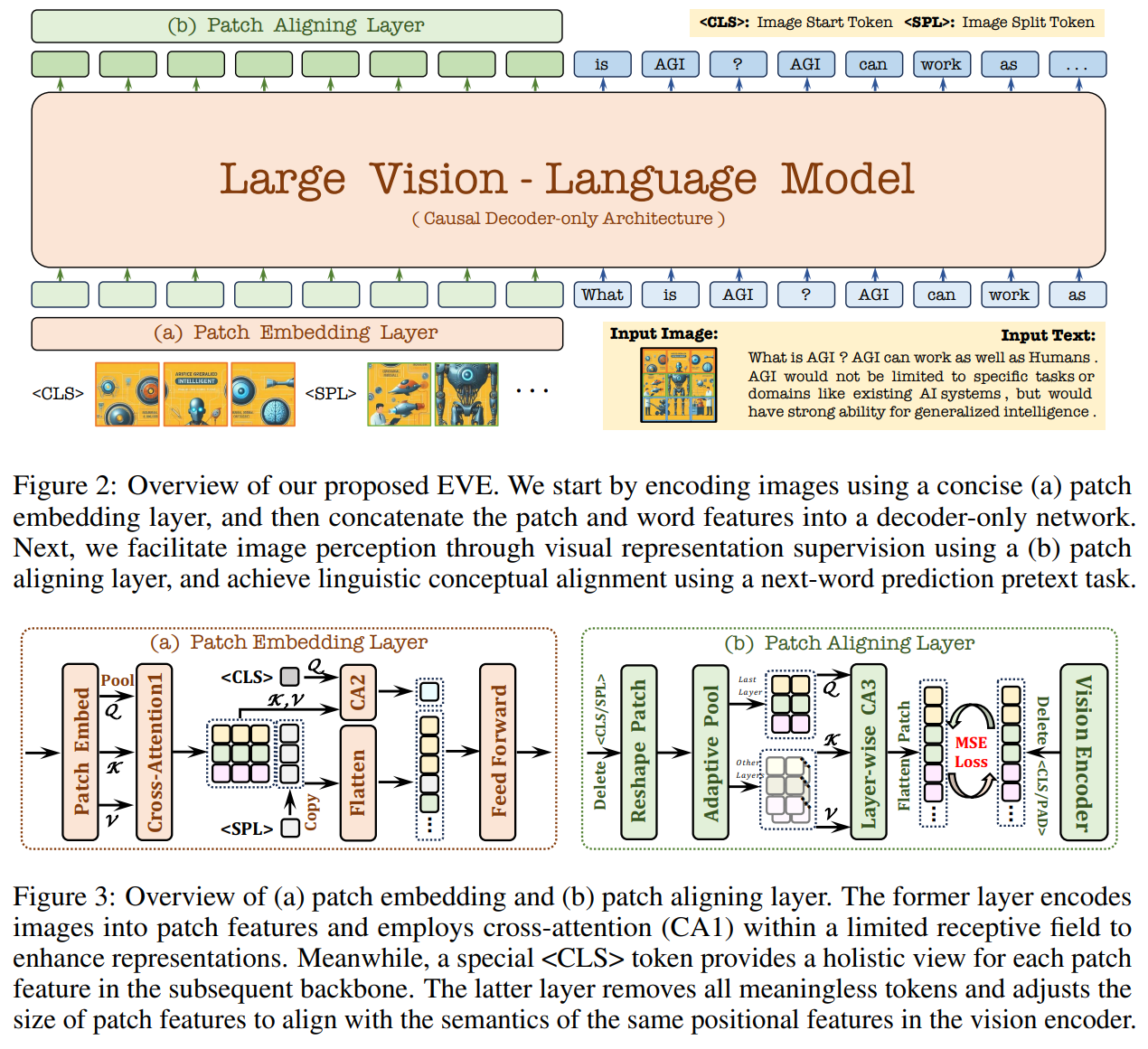
手法
パッチ埋込み層(PEL)
- 画像情報を意味表現に圧縮するためのエンコーダーやトークナイザーを利用しない。ロスレスで送信する
- 画像→畳み込み→2次元の特徴マップ。オーバーヘッド対策で平均プーリングを入れる。
- 特別な
トークンと、全パッチ間のCross-Attention層を採用 - 画像のアスペクト比が変わることを考慮し、各行のパッチ特徴の末尾に新しい行のトークン
を追加 - アスペクト比を任意にできる
- 事前定義されたセット、絶対的なPositional Encoding、パーティショニング操作は必要としない
パッチアラインメントレイヤー(PAL)
- LLM単体で画像特徴を学習するのは困難
- 学習時のみVision Encoderを導入し、パッチ特徴をアラインメント(補助的なガイドを)させる。推論時はこれを外してしまう
- 中間特徴から
, トークンを除外し、2次で特徴を復元 - Vision Encoderの特徴とL2ロスで訓練
- 推論時にVision Encoderを廃止しつつ、LLM内で暗黙的な圧縮ができる
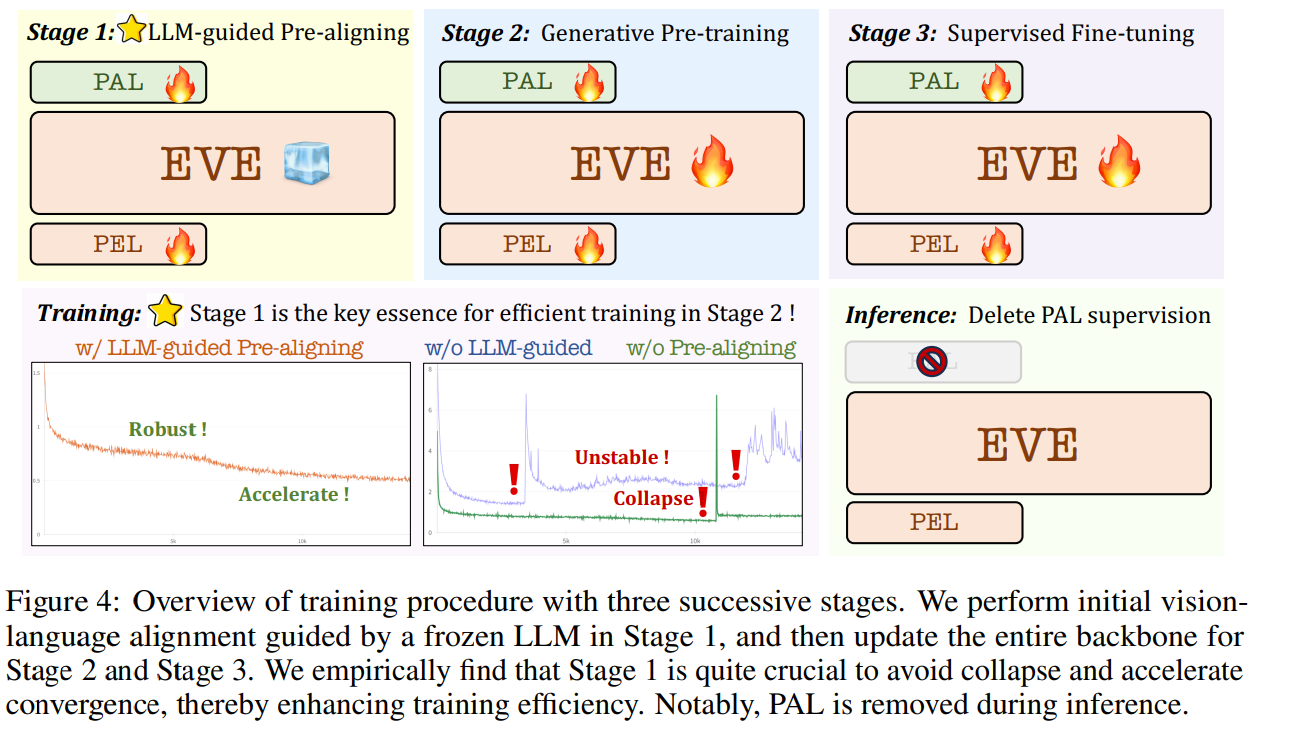
学習プロセス
LLM-guided Pretraining
- 画像と言語のモダリティ間の初期接続を確立
- 高品質なキャプションデータを作る
- SA-1B, OpenImages、Image-text: LAIONよりノイズの多いテキストキャプションを削除
- Emu2-17BとLLaVA-1.5-13Bを用いて33Mの高品質なキャプションを再現(EVE-cap33M)
- このプロセスがないと、Stage2で学習が不安定になる(w/o LLM-guided)
生成的事前学習(Generative Pre-training)
- テキストのCross Entropy Lossと画像のMSE Lossの最小化
- マルチモダリティの性能は徐々に向上するものの、言語能力が著しい低下傾向にある課題
- 妥協点としては、Stage2では低い学習率を使用
SFT(Supervised Fine Tuning)
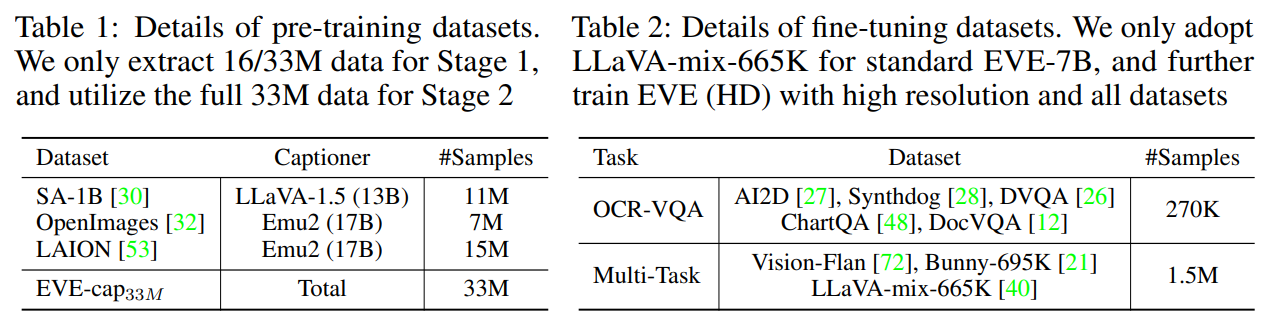
- 標準的なEVE-7B:LLaVA-mix-665Kのみ
- EVE(HD):より高解像度なOCR-VQA(270k)とMulti-Taskの1.5M
実装と結果
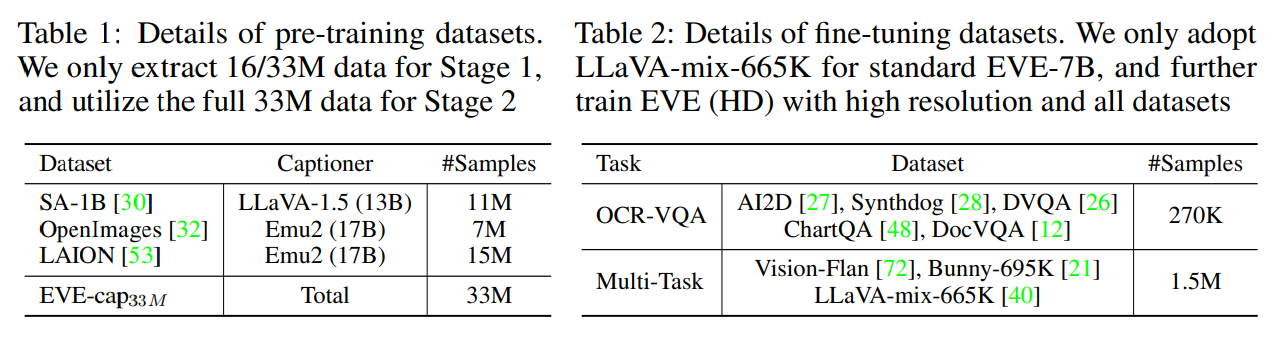
データの前処理
- SA-1B、OpenImages、LAIONの33Mサンプルを用いてEVEを訓練
- LAIONのテキストデータはノイズが多く、重複の問題がある。多様性と品質を下げる
- EVA-CLIPからK-Meansクラスタリングを行い、5万子のクラスタを抽出
- 各クラスタ中心に近い300枚の画像を選択(15万枚)
- LAIONから15Mの画像サンプルのキュレーションされたサブセットを得た
- Emu2-17BとLLaVA-1.5-13Bを利用し、高品質な画像記述を再生し、繰り返しや不完全な文を含むテキストサンプルを除外
実装の詳細
- 解像度はEVE-7Bでは672、EVE-7B(HD)では1344
- PALでVision Supervisedするときは、336にリサイズしたときの特徴量を使用
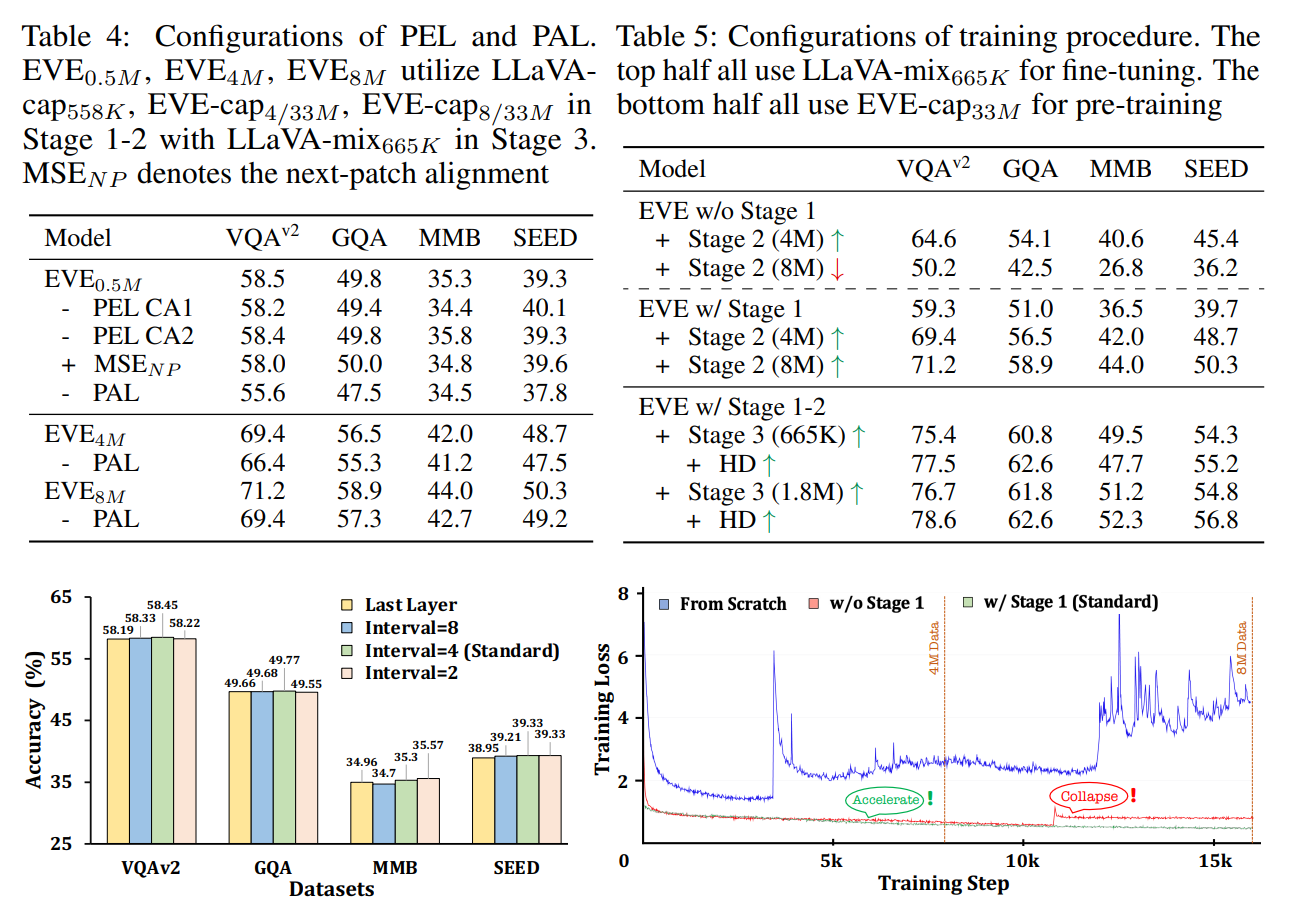
アブレーション
- PAL(アラインメント)が結構効いている(左図)
- Stage1は学習の安定化にもつながっているし、性能も上がる
- HDにすると性能は向上
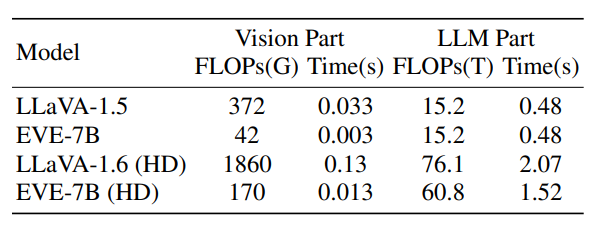
スループット
Vision Encoderなしのほうが速い
議論
- 論文上での議論
- 言語能力の低下→MoEでどうにかならないのか?という提案
- マルチモダリティ構想→画像以外でもいけますよね?
- 私の所感
- まだまだネットワークアーキテクチャで工夫できる部分が多そうなので、この考え方メジャーになるのかな?
- EncoderもLLMもTransformerなら、結局LLMに吸収させちゃえばいいじゃん!ってのはわかる
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー