
Spectral Normalization(SNGAN)を実装していろいろ遊んでみた


GANの安定化の大きなブレイクスルーである「Spectral Normalization」をPyTorchで実装していろいろ遊んでみました。従来のGANよりも多クラスの出力がかなりやりやすくなりました。確かにGANの安定化についてはものすごい効いているので、ぜひ皆さんも遊んでみてください。
※アホみたいに長い内容なので、暇なときに読んでください
目次
はじめに
SNGANとは
Spectral Normalizationを使ったGANの実装。従来のDiscriminator(D)のBatch NormalizationをSpectral Normalizationに置き換えることで、WGANやWGAN-GPで前提としているようなリプシッツ制約を満たし、GANの安定性が向上する――というもの。ちなみに論文書いたのは日本人(半分ぐらいPFNの人)。
論文
Spectral Normalization for Generative Adversarial Networks
https://arxiv.org/abs/1802.05957
なんか難しいこと言っているような気がするけど、要はDのBatch Normの置き換えをするだけで、WGAN相応のものができますよということ。しかも論文によると、WGAN-GPより性能が良い(Inception Scoreが高い、様々なハイパーパラメーターに対するロバスト性が高い)とのこと。これを実装してみました。
実装
https://github.com/koshian2/SNGAN
Spectral Normalizationの実装はBig GANの実装からもってきました。PyTorchの組み込みでもできるっぽい。
いくつか自分が試した実験結果を示します。
再実装(CIFAR-10, STL-10)
再実装(1) : CIFAR-10 (Standard CNN)
固定条件
- Generator: Standard CNN
- Discriminator : Standard CNN
- n_epochs : 321 (約5万回のGのアップデート)
- n_dis = 5
- Adam parameters : lr=0.0002, beta1=0.0, beta2 = 0.9
- 訓練データを使用 (10クラス、5万枚)
Standard CNNの詳細はこれ。

SNGANでは、主にWGANからの名残ですが、GとDのアップデート回数を非対称にするという方式が取られています。これがn_disです。例えばn_dis=5なら、Gが1回アップデートする間に、Dが5回アップデートされることを意味します。
なぜこのようなことが必要かというと、Spectral NormでDの学習が遅くなっているからです。ここらへんはWGANと関連するのですが、直感的には、安定性を取るためにDを構造上弱くしているので、その分アップデート回数や学習時間を増やす必要があります。
ちなみに、Dの学習率を5倍にするというようなこともできますが、n_disを変えるのと比べては効果は薄かったです。これは後で確かめます。
変更条件
| Case | 0 | 1 | 2 | 3 |
|---|---|---|---|---|
| Loss | Cross Entropy | Hinge | Cross Entropy | Hinge |
| Conditional | FALSE | FALSE | TRUE | TRUE |
| Inception Score | 5.844 | 6.077 | 6.094 | 5.821 |
Incpetion score ログ
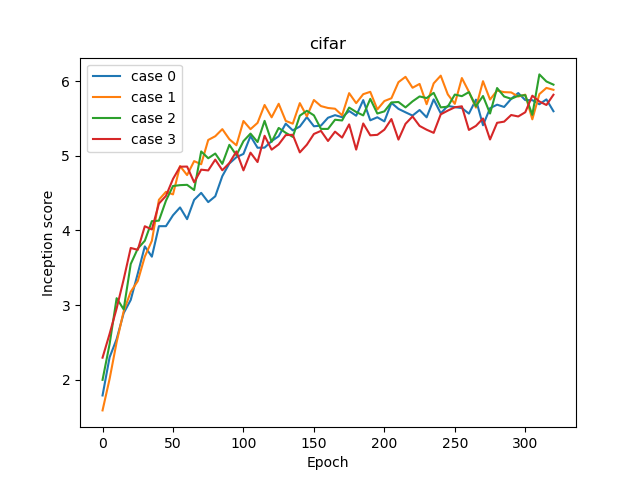
このケースではほとんど差がありませんでした
サンプリングと補間
Case 0
IS = 5.844

Case 1
IS = 6.077

潜在空間の補間が滑らかでGANがうまく行っているのが確認できます。
Case 2
IS = 6.094 (Best)

Conditionalなケースです。ラベルを指定したほうが映る対象を固定しやすいです。
ただしSNGANのGには、Conditionalなケースに限り、Conditional BatchNormという特別なBatch Normalizationが指定されていることに注意してください(あと他にはDの最後にも工夫がある)。やっていることはBatch Normなのですが、計算されたBatch Normに対してクラス別の線形操作($y=ax+b$のような操作)をやっています。
このConditional Batch Normがクラス間の差を明確にすることに大きく寄与しています。Un-conditionalな場合だと、潜在空間の部分にクラスが紛れてしまうので。
似たようなことは、AC-GANでもできますが、ラベル変数をネットワークに与える回数が増えているので、クラス間でより明瞭な差が生まれるようになっています。
Case 3
IS = 5.821

Conditional+ Hinge Lossのケースです。ResNetの場合だとHinge Lossはとても有効に機能しますが、Standard CNNの場合ではあまり差が生まれませんでした。
再実装(2) :CIFAR-10 (ResNet)
固定条件
- Generator: ResNet (32×32)
- Discriminator : ResNet (32×32)
- n_epochs : 321 (約5万回のGのアップデート)
- n_dis = 5
- Adam parameters : lr=0.0002, beta1=0.5, beta2 = 0.9
- 訓練データを使用 (10クラス、5万枚)
Standard CNNではAdamのbeta1=0としていましたが、ResNetのケースでは学習の早い段階で鞍点に引っかかりそのまま損失が変動しなくなってしまうため、beta1=0.5としました。beta1=0.5とするとうまくいきます。
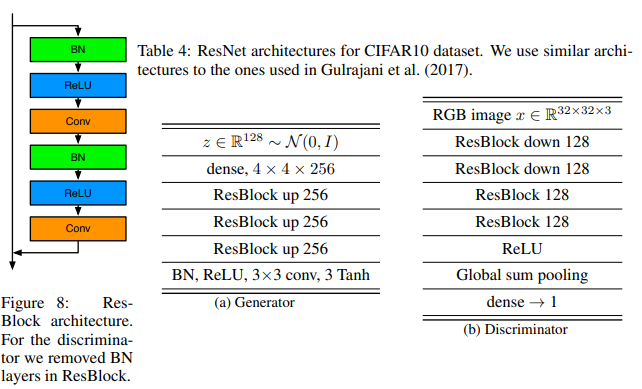
論文でのResNetの構成は、「pre-act ResNet」であることに注意してください。画像分類の場合はあまり気にしなくてもよくても、少なくともSNGANの場合はこれが大きな差になるようです。
変更条件
| Case | 0 | 1 | 2 | 3 |
|---|---|---|---|---|
| Loss | Cross Entropy | Hinge | Cross Entropy | Hinge |
| Conditional | FALSE | FALSE | TRUE | TRUE |
| Inception Score | 3.916 | 5.962 | 3.908 | 5.900 |
Hinge Lossが非常に有効に機能することが確認できました。
Incpetion score ログ
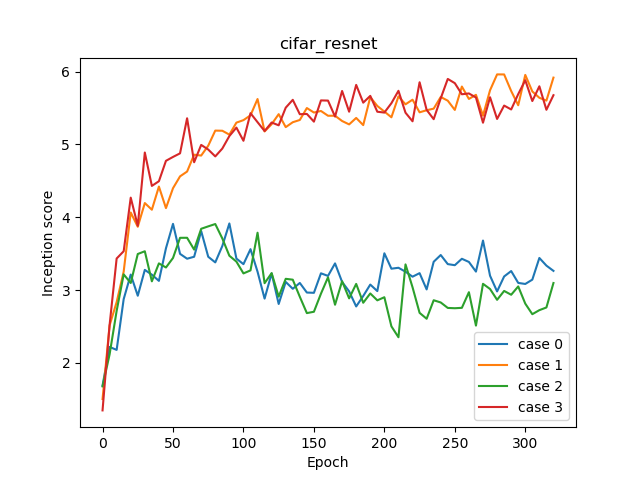
Hinge Lossのケース(case1, 3)が明らかに良いのが確認できます。
サンプリングと補間
Case 0
IS = 3.916

Case 1
IS = 5.962 (Best)

Hinge Lossのケースです。交差エントロピーよりもくすみが少なくなっているのがわかります。
Case 2
IS = 3.908

Case 3
IS = 5.900

Hinge Loss + Conditionalなケースです。テクスチャが安定しているのがわかります。
再実装(3) : STL-10 (Standard)
固定条件
- Generator: Standard CNN (48×48)
- Discriminator : Standard CNN (48×48)
- n_epochs : 1301 (約5.3万回のGのアップデート)
- n_dis = 5
- Hinge loss
- Adam parameters : lr=0.0002, beta2 = 0.9
- 訓練+テストデータ (10クラス, 13k (5k + 8k) サンプル)
次にネットワークをStandard CNNに戻して、STL-10の実験を行います。
STL-10は、5000枚訓練画像、8000枚のテスト画像、10万枚の未ラベルの画像からなります。うち訓練とテスト画像についてはクラス別にアノテーションされており、訓練+テストの1.3万枚の画像をGANに使いました。本来のSTL-10の解像度は96×96ですが、論文では48×48に縮小して使っています。
変更条件
| Case | 0 | 1 | 2 | 3 |
|---|---|---|---|---|
| Conditional | FALSE | FALSE | TRUE | TRUE |
| Beta1 | 0.5 | 0 | 0.5 | 0 |
| IS | 5.932 | 6.058 | 6.157 | 5.813 |
ロスはHinge Lossで固定し、Beta1を変動させてみました。
SNGANに限ったことではないですが、STL-10でのGANはCIFAR-10よりも難しく、成功するかどうかはかなりハイパーパラメーター選択に敏感になります。いくつか理由があります。
- CIFAR-10が1クラス5000枚あるのに対して、STL-10は1クラス1300枚しかない
- そもそもの解像度が高く、背景に複雑な模様を含んでいることがある
- 全般的に画像がくすんでいる(?) クラスが特有のテクスチャで決まりづらく、ニューラルネットワークがそれっぽい特徴を探すのが難しい。これは画像の前処理で改善する可能性はある
STLの画像一覧(公式サイトより)

Incpetion score ログ
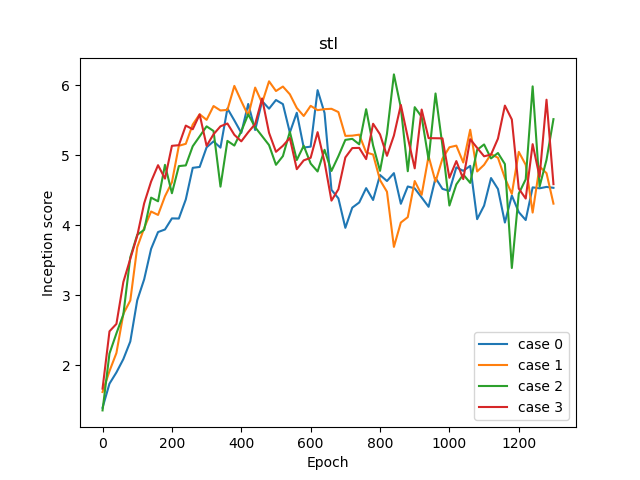
CIFAR-10のときのようにきれいな学習曲線にはなりませんでした。
サンプリングと補間
Case 0
IS = 5.932

部分的に暗い画像がありますね。そもそもの画像のヒストグラム分布に問題があるのかもしれません。
Case 1
IS = 6.058

Case 2
IS = 6.157 (Best)

beta1=0.5のケースです。一番ISは良かったですが、画像のくすみが気になります。これでもマシな方です。
Case 3
IS = 5.813
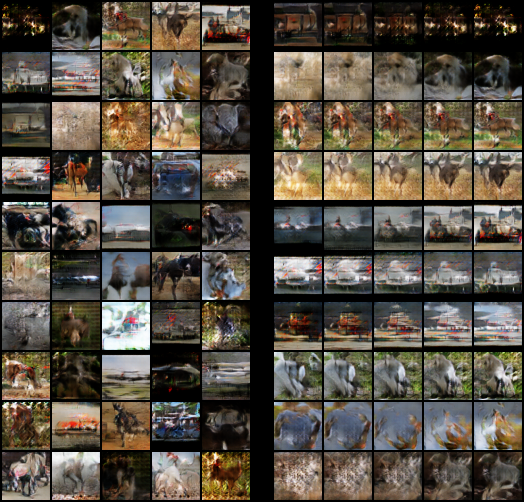
再実装(4) : STL-10 (Res Net)
固定条件
- Generator: Res Net (48×48)
- Discriminator : Res Net (48×48)
- n_epochs : n_dis=5→1301, n_dis=1→261 (どちらも約5.3万回のGのアップデート)
- Hinge loss
- Adam parameters : lr=0.0002, beta1=0.5, beta2 = 0.9
- 訓練+テストデータ (10クラス, 13k (5k + 8k) サンプル)
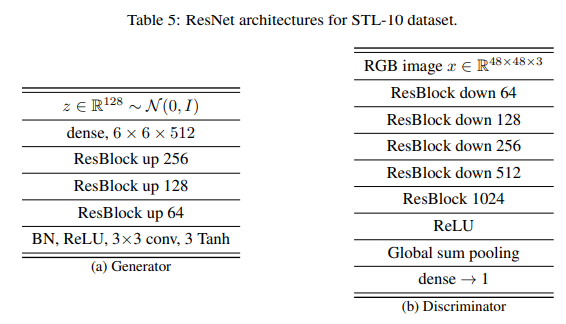
ネットワーク構造は論文に示されたSTL-10版のResNetを使っています。こちらもpre-act構造です。
また、「これDの計算量が支配的なのに、Dが重すぎるよな(特に最後の1024のResBlock)」と思ったので、Dの最後のチャンネル数を512に変更したバージョンも試してみます。
変更条件
| Case | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| Conditional | FALSE | TRUE | FALSE | TRUE | FALSE | TRUE | FALSE | TRUE |
| N dis update | 5 | 5 | 1 | 1 | 5 | 5 | 1 | 1 |
| D last ch | 512 | 512 | 512 | 512 | 1024 | 1024 | 1024 | 1024 |
| IS | 5.795 | 7.136 | 3.421 | 3.883 | 6.538 | 7.314 | 3.444 | 3.653 |
n_dis=5ではどうしても訓練時間が長くなってしまうため、できればn_dis=1で訓練したかったのです。そこでこのケースでは、n_dis=1でうまくいくようチャレンジをしてみました。
また、Dの最後のチャンネル数のカスタマイズも行っています。
結論としては、n_dis=1での訓練は非常に難しいです。これについては後ろの方にさらなる実験を載せています。
Incpetion score ログ
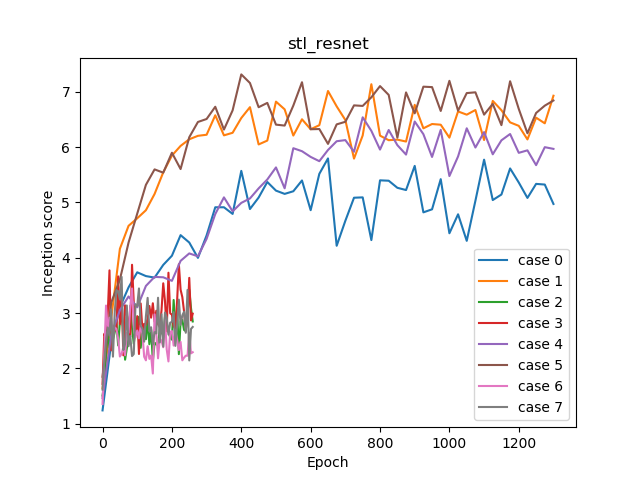
グラフが短いのがn_dis=1のケースです。n_dis=5のケースと比べて全然良くなってないのがわかります。
また、Dの最後のチャンネル数が512よりも1024のほうが、若干良くなっていることがわかります。つまり、SNGANにおいてはDのモデルを大きくしたほうが若干画質がよくなるということが確認できます。
サンプリングと補間
Case 0
IS = 5.795

Standard CNNよりも全然綺麗です。
Case 1
IS = 7.136 (2nd)

これが2番目によかったケース(Conditional-512ch)。テクスチャからぎりぎり輪郭まで捉えていますね。
Case 2
IS = 3.421

n_dis=1は意味のない出力になっています
Case 3
IS = 3.883

Case 4
IS = 6.538

Un-Conditional にしてはかなり良いです。
Case 5
IS = 7.314 (Best)

色調が死に気味なのが気になりますが、これが最もInception Scoreが高かったです。
Case 6
IS = 3.444

Dのモデルを大きくしても、このようにDのアップデート回数が足りないと全然意味ある画像になりません。
Case 7
IS = 3.653

追加実装
SNGANが案外綺麗に出たので、論文では書かれていないデータセットに対して実装してみました。
追加実装(1) AnimeFace Character Dataset
http://www.nurs.or.jp/~nagadomi/animeface-character-dataset/
アニメ顔のデータセットです。14490枚の画像からなり、176枚のクラスからなります。1クラスあたりの枚数あhSTL-10やCIFAR-10より極めて少ないので、難しめのデータセットです。
なぜクラスあたりの枚数がポイントかというと、これはAC-GANと関連しています。AC-GANではクラス単位の出力を行っています。しかし、あまりにクラスあたりの枚数が少なかったり、枚数が多くても場合によっては、クラス単位のモード崩壊というのが発生します。クラス単位のモード崩壊は、「1つのクラスに対して同一の画像しか返さない」という現象で可視化されます。
この点はAC-GANの論文にも書かれていますし、実際にアニメ顔のデータセットで実験したらほぼ同じことが起こったので、GANの安定性を考える上ではポイントとなる事柄でしょう。
固定条件
- Generator: Res Net (96×96)
- Discriminator : Res Net (96×96)
- n_epochs : 1301 (approx. 53k G updates)
- Hinge loss, n_dis = 5
- Adam parameters : lr=0.0002, beta1=0.5, beta2 = 0.9
D,Gともに論文にあるImageNetの128×128のResNetを使っていますが、Gの最初のdenseを4x4x1024から3x3x1024に変更し、出力解像度が96×96になるように変更しています。これは時間短縮のためです。

変更条件
- Case 0 = unconditional
- Case 1 = conditional
Inception Scoreは測定しませんでした。なぜなら、Inception Scoreは(主に)ImageNetで訓練済みのInceptionモデルで測定しますが、アニメ顔とImageNetではドメインが異なります。したがって、これまでのようにInception Scoreを計算しても、指標として意味がないものとなってしまいます。
実際計算してみるとISは2~3程度をうろうろして、出力画像のクォリティと連動しません。
Case 0 (Un-conditional)
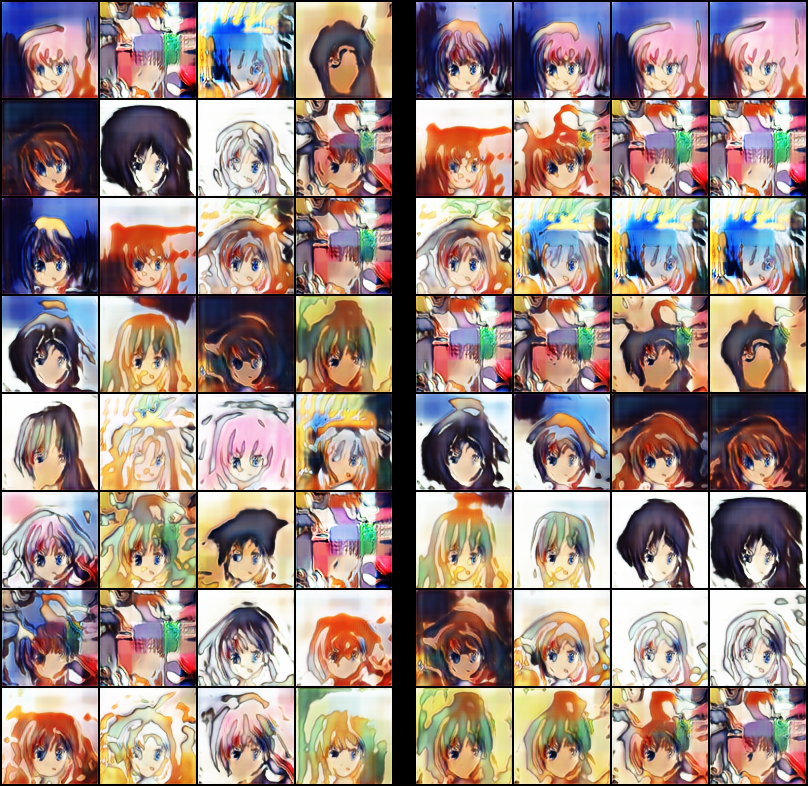
Unconditionalなケースです。若干潜在空間が飛び飛びになっていますが、ある程度滑らかな変動はできているのが確認できます。
Case 1 (Conditional)

Conditionalなケースです。SNGANの強さが明らかに出たケースとなりました。ACGANのときにほぼすべてのクラスであった、クラス単位でのモード崩壊というのが、全くといっていいほど観測できませんでした。これはSpectral Normでリプシッツ連続の制約をおいているためだと思われます。
補間のケースを見てみましょう。ACGANではクラス単位でモード崩壊しているため、いくら補間で潜在空間の乱数を動かしても同一画像しか返ってきませんでした。ところが、SNGANなら乱数の変動が、表情や顔の向きといったパラメーターに対応しています(一部似たようなキャラの混同はあります)。
GANの成功しているための指標の一つに、「潜在空間の補間をして出力画像が滑らかに変動すること」があげられるので、これは素直にうまく行っているといえるでしょう。
Oxford Flower Dataset
http://www.robots.ox.ac.uk/~vgg/data/flowers/
オックスフォード大学が出している、花の画像のデータセットです。8189枚の画像からなり、102のクラスからなります。最近はあまり使われることがないデータセットですが、キレイな花が多いのでぜひ覗いてみてください。
変更条件
- Case 0 = unconditional
- Case 1 = conditional
基本的にAnimeFaceと同じ設定でやっていますが、1つ違うのはDのネットワークの最初にstride=2のConvをおいて、ResBlockを1つ減らしているという点です。
最後のResBlockにおける解像度が半分になるので、理論的には計算量が1/4ぐらいになります。実際に計測してみたところ、1エポックあたりの所要時間がCPUでは1/3、GPUでは半分強ぐらいになりました。
Case 0 (Un-conditional)

一部うまくいっていないケース(閉じている花)がありますね。花は輪郭が複雑なものがあるので、もしかしたらアニメ顔よりも難しいのかもしれませんね。
Case 1 (Conditional)

クラス単位での出力はそこそこ上手く行っていますが、花弁の「まとまり感」を作るのが難しいようです(花びら単位でバラバラになっている画像ができる)。もっとデータ数があればうまくいくと思われます。
付録・失敗例 (STL-10に対するさらなる実験)
ここでの目標はn_dis=1で訓練することですが、結果的にはかなり多くの「うまく行かなかった例」が生み出されました。
失敗例(1) : STL-10 (Post-act Res Net / Standard CNN)
固定条件
- Generator: Post-act Res Net (48×48)
- Discriminator : Standard CNN (48×48)
- Generator leraning rate : 0.0002
ここでは、SNGANのモデル構造に対するロバスト性を見るために、論文ではPre-act ResNet(BN / SN-> ReLU-> Conv)になっているのを、Post-act ResNet(Conv-> BN / SN-> ReLU)にしてみました。
実際、画像分類などGAN以外の1つのネットワークで行うタスクでは、pre-actかpost-actかというのは、正直好みの問題でしょ感は否めません(pre-actのほうが精度を出しているという研究もありますが、post-actの実装もあるので、一般的にはそういえるのか疑問がある)。同じことがGANで言えるかどうかを確認してみます。
このケースでは、Gにpost-actのResNetを使い、DにはStandard CNNを使いました。これだと計算コストを減らせるので。
変更条件
| Case | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|---|
| N dis | 5 | 5 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| Beta2 in Adam | 0.9 | 0.9 | 0.9 | 0.9 | 0.999 | 0.999 | 0.999 | 0.999 | 0.999 | 0.999 |
| Leaky relu slope in D | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.2 | 0.2 | 0.2 | 0.2 |
| D learning rate | 0.0002 | 0.0002 | 0.0002 | 0.0002 | 0.0002 | 0.0002 | 0.0002 | 0.0002 | 0.001 | 0.001 |
| Conditional | FALSE | TRUE | FALSE | TRUE | FALSE | TRUE | FALSE | TRUE | FALSE | TRUE |
| Inception Score | 6.419 | 5.663 | 1.285 | 2.634 | 2.342 | 2.447 | 2.499 | 2.722 | 2.355 | 2.544 |
とにかくn_dis=1でうまくいくようにしたかったので、ありそうなパラメーターをいろいろ変えてみました。まずはn_dis=5で訓練します。そこから、
- Adamのbeta2 (係数が大きい方が長い期間の移動平均を見るから良くなりやすいかも)
- Leaky ReLUのslope(ある程度大きい係数のほうが勾配消えにくいかも)
- Dの学習率(そもそもDの学習が追いつかないのが問題だから、DとGの学習率を非対称にして、Dの学習率を高くしちゃえばいいかも)
などの条件を変更しました。Unconditional, conditional別にまとめると次のようになります。
| Case | Condition | IS |
|---|---|---|
| 0 | uncoditional n_dis = 5 | 6.419 |
| 2 | uncoditional n_dis = 1 | 1.285 |
| 4 | + beta2 = 0.999 | 2.342 |
| 6 | + lrelu slope = 0.2 | 2.499 |
| 8 | + lr_d = 0.001 | 2.355 |
| Case | Condition | IS |
|---|---|---|
| 1 | coditional n_dis = 5 | 5.663 |
| 3 | coditional n_dis = 1 | 2.634 |
| 5 | + beta2 = 0.999 | 2.447 |
| 7 | + lrelu slope = 0.2 | 2.722 |
| 9 | + lr_d = 0.001 | 2.544 |
n_dis=1のケースはいずれも成功しませんでした。他のハイパーパラメーターチューニングは若干効いてはいるものの、n_dis=5のケースと比較すると誤差みたいなものでした。
Incpetion score ログ
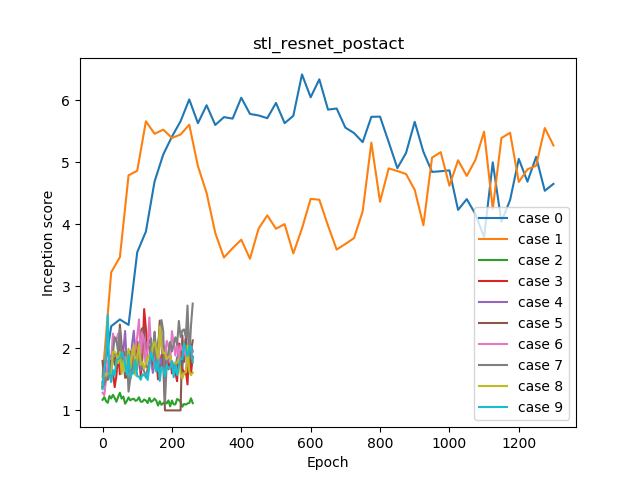
サンプリングと補間
部分的に書きます。残りはリポジトリのフォルダを参照してください。
https://github.com/koshian2/SNGAN/tree/master/sampling_interpolation
Case 0
IS = 6.419

この中で最も良いケースでした。Unconditionalなケースです。pre-actのResNetのD/Gのケース若干マイナスぐらい出ています。
Case 1
IS = 5.663

なぜかConditionalにすると劣化するという事件がおこります。
Case 6
IS = 2.499

Case 7
IS = 2.722

n_dis=1にすると意味のある画像を出力できません。
なぜn_dis=1がうまくいかないのか
これはcase 0(n_dis=5)、case 6(n_dis=1)のD,Gのロスのプロットです。両方uncoditionalなケースです。
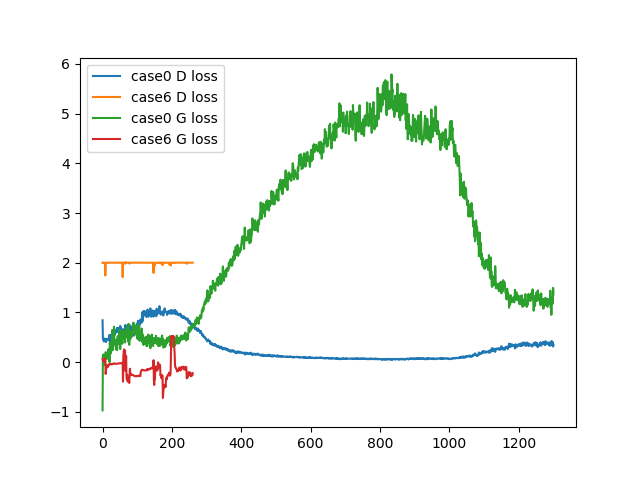
見てわかるように、case 6のDがロスがほとんど減っていません。別の言い方をすれば、Gの学習が強すぎてDの学習が追いつかず、全然学習できていないということになります。これはDにSpectral Normをおいているため、Dのアップデート幅が小さくなってしまうためだと思われます。安定性と学習の速度はある意味トレードオフになっているのです。
この現象は、Dのアップデート回数を増やすことが最も有効な解決法になります。Dだけ学習率を大きくしてもほとんど効果はありませんでした。
失敗例(2) : STL-10 (Post-act Res Net / Post-act Res Net)
固定条件
- Generator: Post-act Res Net (48×48)
- Discriminator : Post-act Res Net (48×48, 最初のチャンネルは変更可能)
- Generatorの学習率 : 0.0002
- n_epochs : n_dis=5→1301, n_dis=1→261 (約5.3万回のGのアップデート)
- Adamのパラメーター : beta1=0.5, beta2 = 0.999
このケースでは、DもGもpost-actのResNetにしてみます。
変更条件
| Case | 0 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|---|
| D initial ch | 16 | 16 | 32 | 32 | 64 | 64 |
| N dis | 5 | 1 | 5 | 1 | 5 | 1 |
| Inception Score | 4.621 | 3.004 | 4.789 | 4.365 | 4.990 | 4.341 |
変更条件として、n_disと同時に、Dの大きさも変えてみます(最初のResBlockのチャンネル数を16, 32, 64で変える)。
Incpetion scoreログ
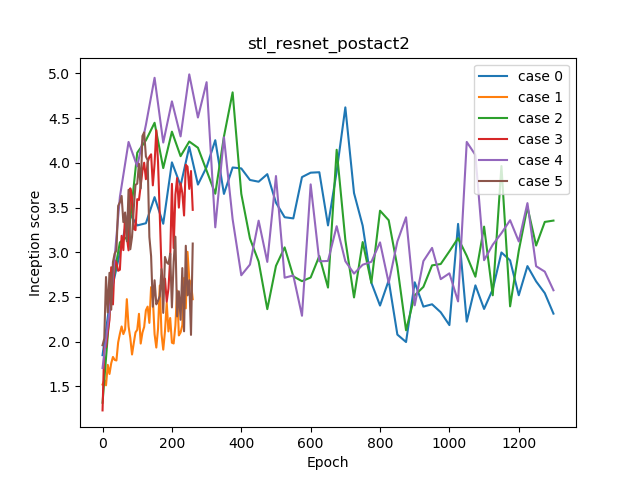
DをResNetにしたらある程度マシになりましたが、全体的にむしろ下がっているので、post-actなResNetは少なくともSNGANにおいて明らかによくないのでは?というのが示唆されます。
サンプリングと補間
caseが偶数番台はn_dis=5で、奇数番台はn_dis=1です。
Case 0
IS = 4.621

Case 2
IS = 4.789
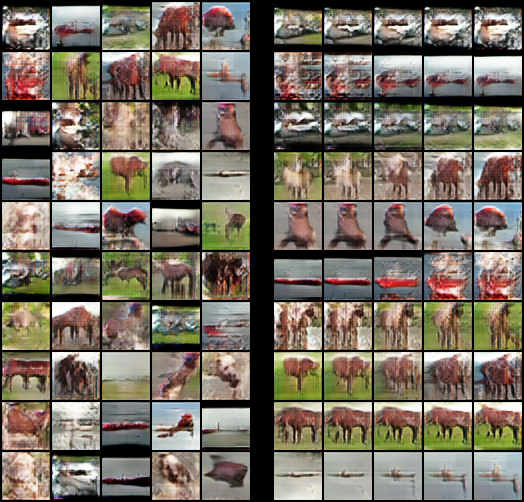
Case 4
IS = 4.990

最も良かったケースです(n_dis=5, initial_ch=64)。ぱっと見はきれいなんですが、Inception Scoreがあまりよくありませんね。
Case 5
IS = 4.341

こちらはn_dis=1のケースです。n_dis=5よりに暗い画像が多いですね。n_dis=1ではこれが限界でした。
失敗例(3) : STL-10 (論文でのpre-ResNet / 若干いじったResNetのD)
固定条件
- Generator: 論文のResNet (48×48)
- Generator leraning rate : 0.0002
- n_dis : 5
- n_epochs : 1301
- All conditional
- Adam parameters : lr=0.0002, beta1=0.5
次はGのネットワークは論文のもので固定します。そして、Dのネットワークのみ変えます。Unconditionalなケースは省きました。n_dis=5で固定します。
変更条件
| Case | 0 | 1 | 2 | 3 |
|---|---|---|---|---|
| Beta2 in Adam | 0.9 | 0.999 | 0.9 | 0.999 |
| D architecture | postact | postact | strided resnet | strided resnet |
| Inception Score | 5.955 | 5.708 | 6.906 | 7.222 |
Dの構造は、ケース0,1がpost-actのResNet、ケース2,3は論文のSTLのResNetの最初にStrided Convを入れたものです(やり方は発想はOxford Flowerのケースと同じ)。これはn_dis=5で多くなりがちな計算量を削るためです。
Incpetion score log
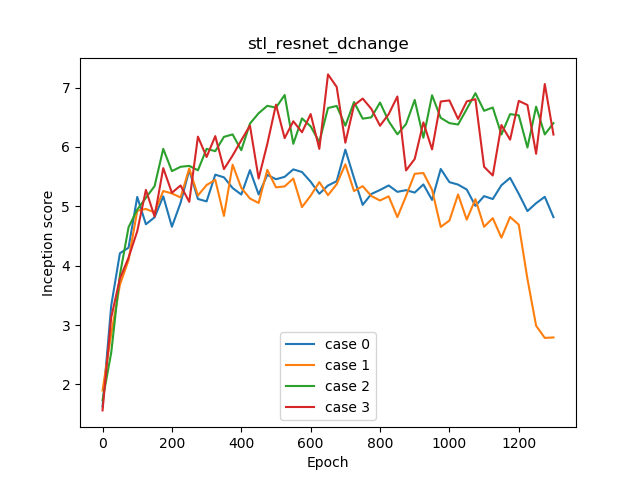
Gをpost-actからpre-actにしたら良くなった(ケース0,1)、そしてDもpre-actにしたらさらに良くなった(ケース2,3)なので、SNGANにおいてResNetを使う場合は、pre-actのほうが明らかに良いという結果になりました。
ただし、Dの冒頭にStride Convを入れて計算量を削っても、そこまで画質は落ちませんでした。計算量をへらすテクとしては使えるかもしれません。
Case 0
IS = 5.955

Case 1
IS = 5.708

これはbeta2を0.999にしたケースですが、色調が同じような感じになっていますね。もしかすると移動平均を取りすぎていてよくないのかもしれません。
Case 2
IS = 6.906

pre-actの例です。明瞭さが全然違います。
Case 3
IS = 7.222 (Best)

pre-actの例でも、beta2のパラメーターを大きくすると、色調がより統一的になるのかもしれません。
失敗例のまとめ
Dのモデルを大きくすると、Inception Scoreは若干よくなります。しかし、n_dis=1で綺麗に出力する方法を見つけることができませんでした。
画像分類では、ResNetとpre-actとpost-actは僅かな違いかもしれません。しかし、GANではこの違いは大きな差を生んでいるのかもしれません。少なくともSNGANではそれを確認できました。
まとめ
非常に長い内容になってしまいましたが、SNGANでいろいろ遊んでみました。SNGANは「Dの損失値が下がるかどうか」で画質が決まるという、かなり単純な仕掛けになっているので、従来のGANよりもロスの解釈が簡単そうです。安定性を取るならSpectral Normというのはほぼ間違いなさそうです。
ただ、安定性の反面計算コストが若干膨らみがちなので、DとGのアップデート回数が非対称になったりと、若干扱いにくい部分があるかもしれません。しかし、後続研究のSelf attention GAN(SAGAN)やBig GANでは、DとGの両方にSpectral Normを入れるということをやっているので、n_disのようなアップデートの非対称性はおそらく解決されるでしょう。速度の面なら、PG-GANという奥の手があるので、まだ手詰まりではなさそうです。
また、SNGANではpre-act, post-actのように、ハイパーパラメータにまだ若干鋭敏に反応し、出力画像の質が振り回される感は否めませんが、これでも従来のGANよりも相当良くなっています(従来のGANは適当なモデル組んで、論文以外のデータセット使うと学習すら進まないのが往々にしてある)。ただこれも後続の研究ではもっと良くなるでしょう。
SNGANはSpectral NormというGANの安定性に関して大きなブレイクスルーを出しており、ACGANのような従来のクラス単位でのGANよりも一線を画する画質になっています(アニメ顔なんかわかりやすいです)。みなさんもぜひSpectral Normalizationを使ってみてください。
余談
手元の2枚のGPUじゃ回すのが追いつかなく、とにかく計算資源が足りなかったので、ColabのGPUを6アカウントぐらいで回してたら、GPUを使いすぎたのかTesla T4のGPUが全然割り当てられなくなってしまいました(T4割り当てがBANされたっぽい?)。月が変わっても全然直らないんで、中の人見てたらはやく直してほしいなー。ペナにしてはちょっとエグい。
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー