
いろんなT5からSentence Embeddingをとって遊ぶ


自然言語処理モデルT5を使って文章単位の埋め込み量(Sentence Embedding)を取得することを考えます。T5のEmbeddingはトークン単位ですが、平均を取ることで、簡単に文章単位に変換できます。Sentence T5としてモデルが公開されていない場合でも、既存のT5から自在に特徴量を取得できることを目標とします。Flan-T5からSentence Embeddingをとって見たりします。
目次
はじめに
普段画像処理ばっかりやってる自然言語処理素人だけど、Imagenで使っていたり、Unified IOがベースにしていたり、何かとT5を聞きますよね。
調べていたらtransformersのライブラリから簡単に利用できることがわかったので、今回遊んでいきたいと思います。このブログでは珍しいNLPの内容です。
問題点
(自然言語処理やっている人には当たり前かもしれませんが、)一つ問題がぶち当たります。
T5の計算しているEmbeddingってトークン単位やん。文章のEmbeddingがほしいねん。どうやってトークンから文章のEmbeddingに変換するのよ?
これは検索すると、Hugginfaceなどで同様の質問がちょくちょく出ていました(やっぱりみんな気になるっぽい)。
日本語版のSentence-T5
日本語のT5モデルで、Sentence Embeddingを計算できるものがありました。これは日本語のT5をベースとして、Sentence-T5としたものです。
https://huggingface.co/sonoisa/sentence-t5-base-ja-mean-tokens
ただ、コードを見ていると、トークン→文単位のEmbeddingの変換で追加の係数を使っている気配がなく、ただマスクを加味した平均をとっているだけのようにしか見えません。
!pip install sentencepiece transformers
import numpy as np
import seaborn
import matplotlib.pyplot as plt
from transformers import T5Tokenizer, T5Model
import torch
class SentenceT5:
def __init__(self, model_name_or_path, device=None):
self.tokenizer = T5Tokenizer.from_pretrained(model_name_or_path, is_fast=False)
self.model = T5Model.from_pretrained(model_name_or_path).encoder
self.model.eval()
if device is None:
device = "cuda" if torch.cuda.is_available() else "cpu"
self.device = torch.device(device)
self.model.to(device)
def _mean_pooling(self, model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
def encode(self, sentences, batch_size=8):
all_embeddings = []
iterator = range(0, len(sentences), batch_size)
for batch_idx in iterator:
batch = sentences[batch_idx:batch_idx + batch_size]
encoded_input = self.tokenizer.batch_encode_plus(batch, padding="longest",
truncation=True, return_tensors="pt").to(self.device)
model_output = self.model(**encoded_input)
sentence_embeddings = self._mean_pooling(model_output, encoded_input["attention_mask"]).to('cpu')
all_embeddings.extend(sentence_embeddings)
return torch.stack(all_embeddings)
MODEL_NAME = "sonoisa/sentence-t5-base-ja-mean-tokens"
model = SentenceT5(MODEL_NAME)
「あれ、T5のモデルさえあれば、SentenceのEmbeddingって割りと簡単に計算できるんじゃない?」という疑問が湧きます。そもそもSentenceT5とは何でしょうか? 論文によると、
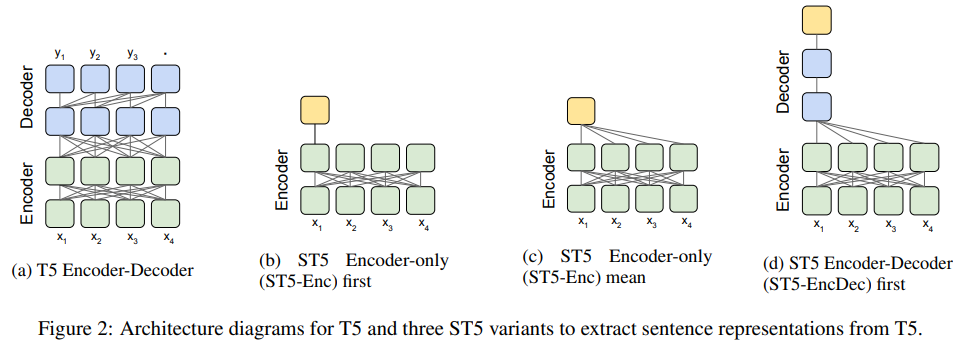
「(c) ST5 Encoder-only (ST5-Enc) mean」がトークンの平均取っています。論文ではいくつかアーキテクチャーを提示していますが、(c)が一番精度が良かったとのことです。
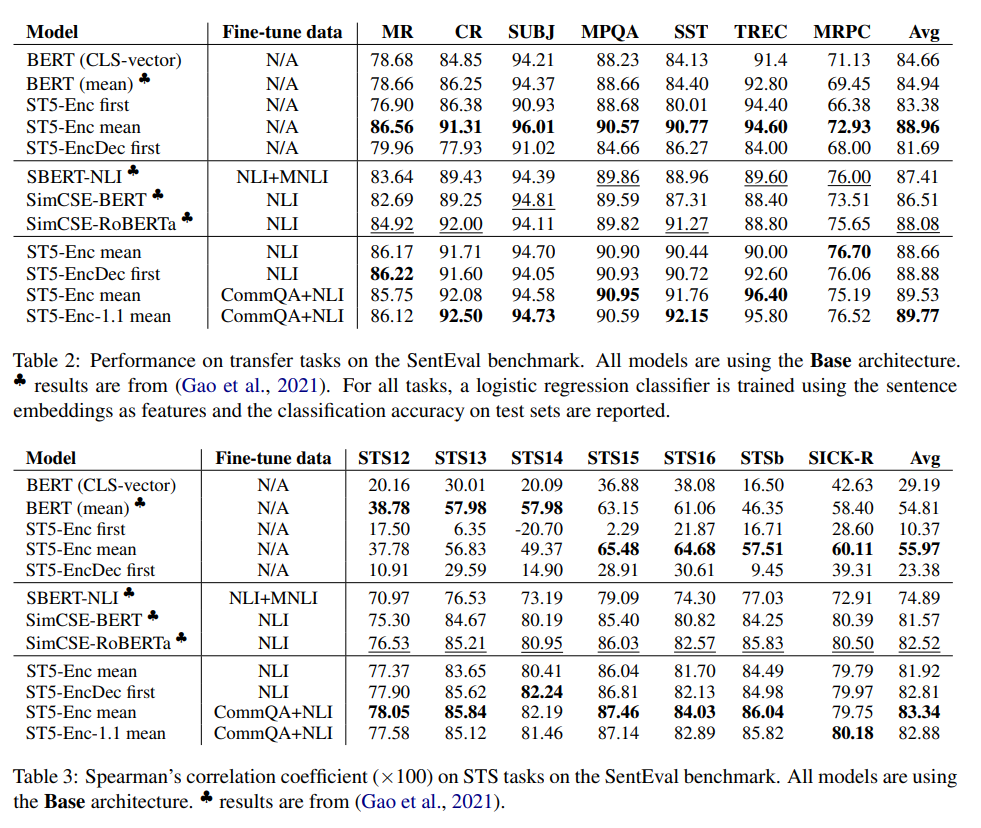
面白いのが、「Fine-tune dataがN/A」でもTable 2のような状況ではFine-tuneありに匹敵するぐらいの精度が出せているということです。ここでのFine-tuneとはなにかというと、「Contrastive Learningをするかどうか」です。
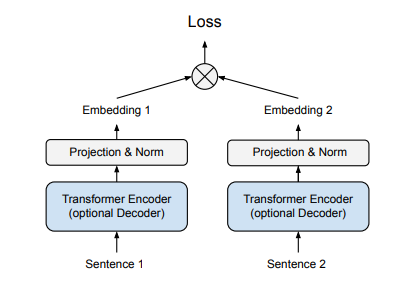
この図を見ると、「画像の自己教師あり学習や距離学習で出てくるあれね」という印象はありますが、Embeddingを学習したいのならこういうFine-tuneをするのは素直なやり方でしょう。
Table 3のように相関係数を見ると、Fine-tuneをするときれいに行くのは「それはそう」なのですが、Table 2の精度を見ると「Fine-tuneが必ずしも必要か」と言われたらそうでもなさそうです。
何がいいたいのかというと、Fine-tuneがいらないとすれば、任意のT5モデルを持ってくれば、即席でSentence Embeddingが求められるということです。これを今回検証していきたいと思います。
データ作成
検証用のデータを作ります。商品のレビュー文を想定して、ポジティブな内容、ネガティブな内容を10文ずつ作ります。これを日本語と英語でそれぞれ作ります。
作り方は手動で入力してもいいのですが、面倒なのでGPT-3で作りました(ChatGPTでもOKです)。
日本語の場合は、GPT-3のプロンプトに
買った商品が良かったです。ほめるレビュー文を10個作ってください
買った商品が良くなかったです。けなすレビュー文を10個作ってください
と入れて検証用のデータを作ります。英語の場合は、このプロンプトをDeepLで翻訳してそのまま突っ込みます。出てきたレビュー文が以下のとおりです。
日本語
positive_sentences_jp = [
"この商品はとても便利で、使いやすいです。",
"品質がとても高く、耐久性も抜群です。",
"デザインがとてもきれいで、見た目も美しいです。",
"安い価格で大変お得な商品だと思います。",
"商品の細部にわたり、仕上がりがとても行き届いています。",
"素早く購入から発送まで行われ、迅速な対応で満足しています。",
"機能性が高く、使い勝手がとても良いです。",
"セット内容が多く、価格に見合った価値のある商品だと思います。",
"箱にはしっかりとしており、安心して受け取ることができました。",
"商品を購入してから毎日使っていますが、問題なく使用できています。"
]
negative_sentences_jp = [
"この商品は期待したほどの質問ではなかったです。",
"購入したはいいものの、素材が薄くて、すぐに壊れてしまいました。",
"この商品はお値段よりも劣悪な品質でした。",
"今回の購入は非常に失敗したと言えます。",
"この商品は非常に不満なものでした。",
"この商品は説明書なしで、どう使えばいいのかよくわからなかったです。",
"素材も品質も期待したものではなかったです。",
"予想していたよりも全然簡単に壊れてしまいました。",
"この商品は思ったよりもずっと劣悪なクオリティでした。",
"持っている時間がもっと長くなければならなかったです。"
]
同様に英語も作成しました。
positive_sentences_en = [
"The product was of great quality.",
"The item was exactly what I was looking for.",
"I was very pleased with my purchase.",
"The product was better than expected.",
"I am extremely satisfied with the product.",
"The product exceeded my expectations.",
"The item was perfect for my needs.",
"The product was a great value.",
"I am delighted with my purchase.",
"The product was exactly as described."
]
negative_sentences_en = [
"The product I bought was terrible.",
"The product was far below my expectations.",
"The quality of the product was very poor.",
"I am extremely dissatisfied with the item I purchased.",
"This product was a complete waste of money.",
"I regret buying this product.",
"I would not recommend this product to anyone.",
"The product was not fit for purpose.",
"The product was far inferior to what was advertised.",
"The product was not worth the cost."
]
ポジティブ10+ネガティブ10、合計20サンプルのEmbeddingをとり、コサイン類似度の行列を見ます。理想的には、ポジティブ同士・ネガティブは1に近く、それ以外は0に近くなるはずです。
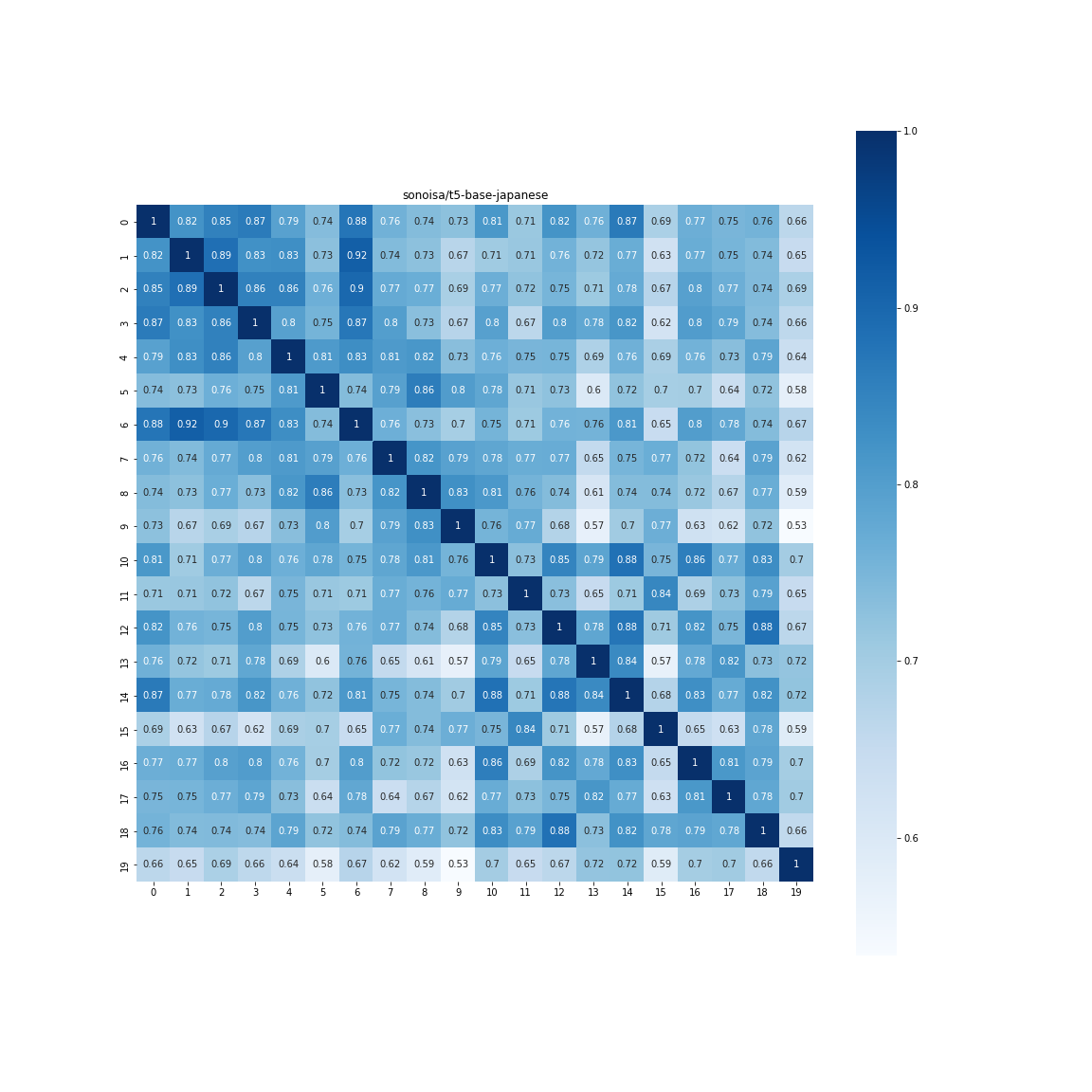
日本語版Sentence-T5-base(Sentence-T5として公開されているモデル)
まずは先程紹介したSentence-T5として公開されているSentence-T5-baseを使って分析します。
MODEL_NAME = "sonoisa/t5-base-japanese"
model = SentenceT5(MODEL_NAME)
## サンプル単位のSentence Embedding
sentence_embeddings = model.encode(positive_sentences_jp+negative_sentences_jp, batch_size=8)
## コサイン類似度(相関)行列の計算
x = sentence_embeddings / sentence_embeddings.norm(dim=-1, keepdim=True)
simiralites = x @ x.T
## ポジ×ポジ、ポジ×ネガ、ネガ×ポジ、ネガ×ネガの相関の平均
print(simiralites.numpy().reshape(2, 10, 2, 10).mean(axis=(1, 3)))
相関行列は、以下のようにきれいにわかれていました。
array([[0.53760684, 0.2090787 ],
[0.2090787 , 0.466138 ]], dtype=float32)
ヒートマップで可視化してみましょう。
plt.figure(figsize=(16, 16))
seaborn.heatmap(simiralites, square=True, cbar=True, annot=True, cmap='Blues')
plt.title(MODEL_NAME)
plt.savefig(MODEL_NAME.split("/")[-1]+".png")
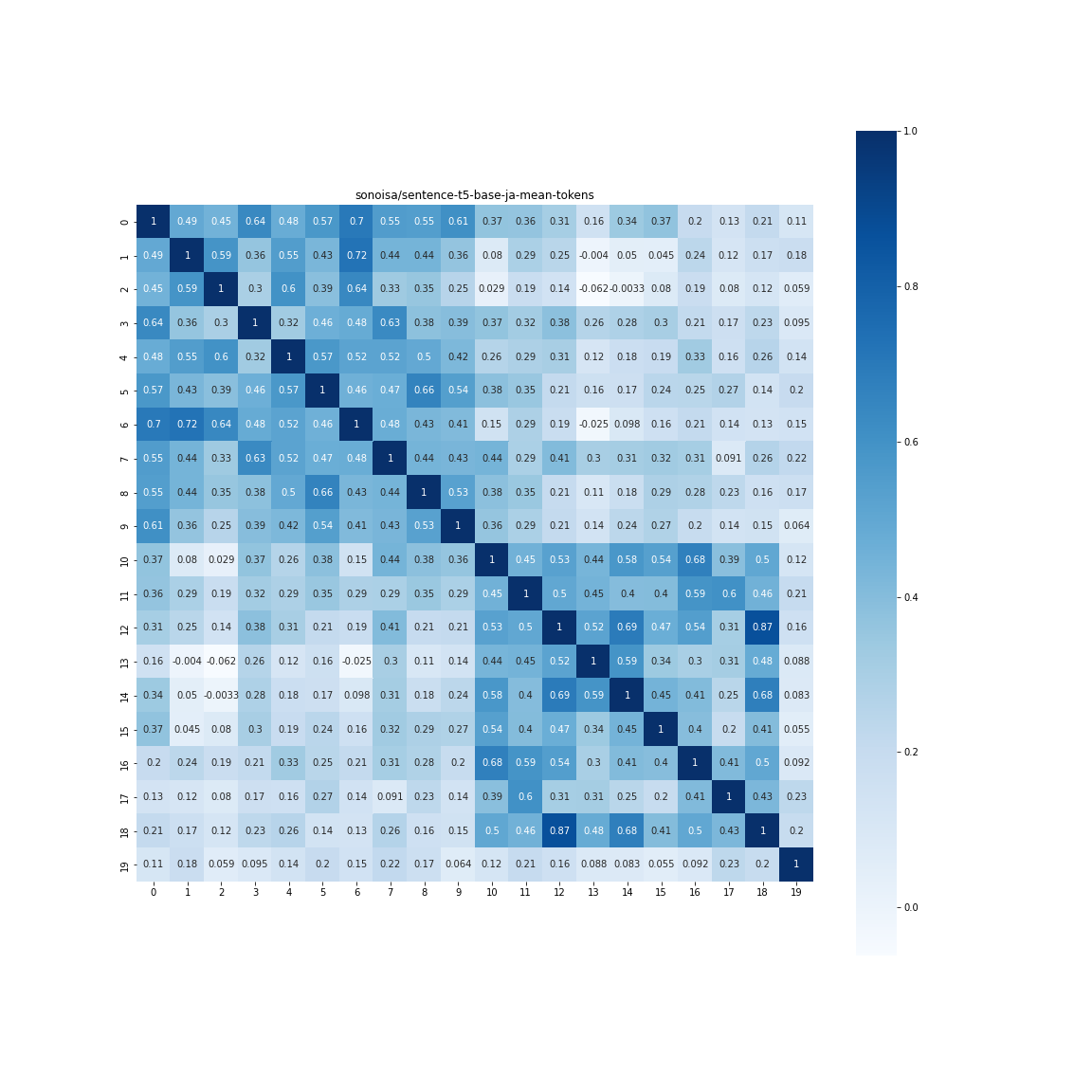
なかなかですね。ポジネガで相関マップが分離できています。Fine-tuneしたかどうかは明言されていませんが、次の結果を見ると多分しているのではないかと思われます。
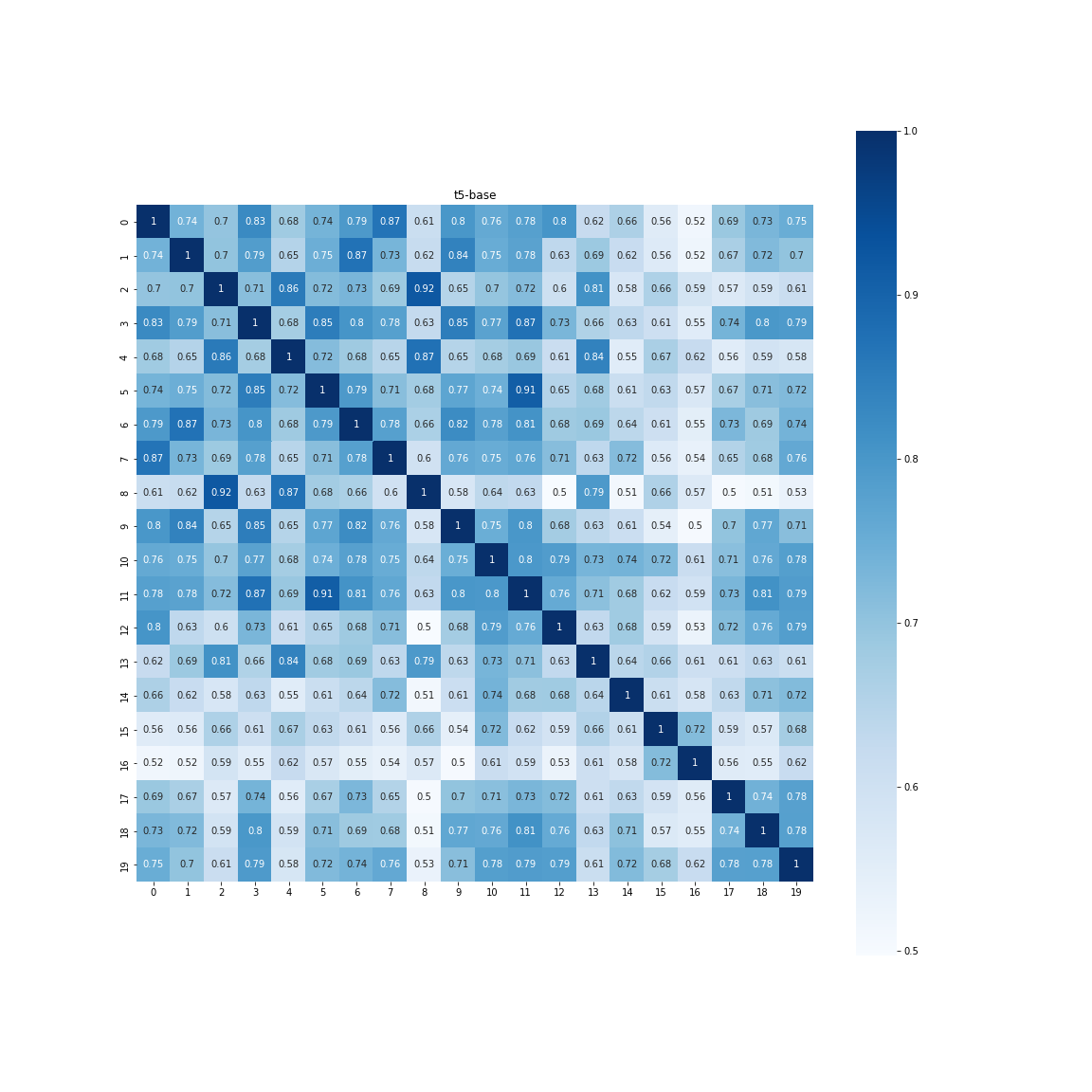
t5-base-japaneseの場合(Fine-tuneしていないモデル)
ここで「Fine-tuneしていない、任意のT5に差し替えてた場合どうなるのか」ということが気になります。日本語版のSentence-T5の元モデルであるt5-base-japaneseを使ってみます。
同じ検証をしてみたところ以下のようになりました。
[[0.8111565 0.72467524]
[0.72467524 0.7763988 ]]
ポジネガ間の差はギリギリ残っていますが、だいぶ境界がぼやけました。ポジネガも「どっちも商品のこと言っているから同じだろう」というお気持ちなのでしょうか。こういった場合は、Fine-tuneである程度ダウンストリームに特化させてあげる必要があるかもしれません。
英語版のt5-baseの場合
ここからは全てSentence T5として公開されていないモデルのテストです。先程は日本語モデルでしたが、英語でも試してみます。
推論コードは次のようになります。
MODEL_NAME = "t5-base"
model = SentenceT5(MODEL_NAME)
sentence_embeddings = model.encode(positive_sentences_en+negative_sentences_en, batch_size=8)
x = sentence_embeddings / sentence_embeddings.norm(dim=-1, keepdim=True)
simiralites = x @ x.T
print(simiralites.numpy().reshape(2, 10, 2, 10).mean(axis=(1, 3)))
結果は以下の通りです。
[[0.76613474 0.6663713 ]
[0.6663713 0.7123178 ]]
ポジ×ポジ、ポジ×ネガの差が0.1程度なので、日本語(t5-base-japanese)と同じような結果です。
Flan-T5を使う(google/flan-t5-base)
最近、無印のT5のより、優秀なT5モデルが公開されています。
FLANとは「Finetuned Language Models」で、訓練手法に工夫を加えることで、ダウンストリームのゼロショット性能が上がるものです。Flan-T5のSentence Embeddingを求めたかったので、この記事を書いたまであります。
「GPT-3並」と紹介されることもありますが、ホントかよ感はありますね。ただ無印のT5よりかは明らかによいはずなので、同様にSentence Embeddingからの相関を計算してみます。
結果はかなり驚愕もので、
[[0.8464212 0.6134691]
[0.6134691 0.8076489]]
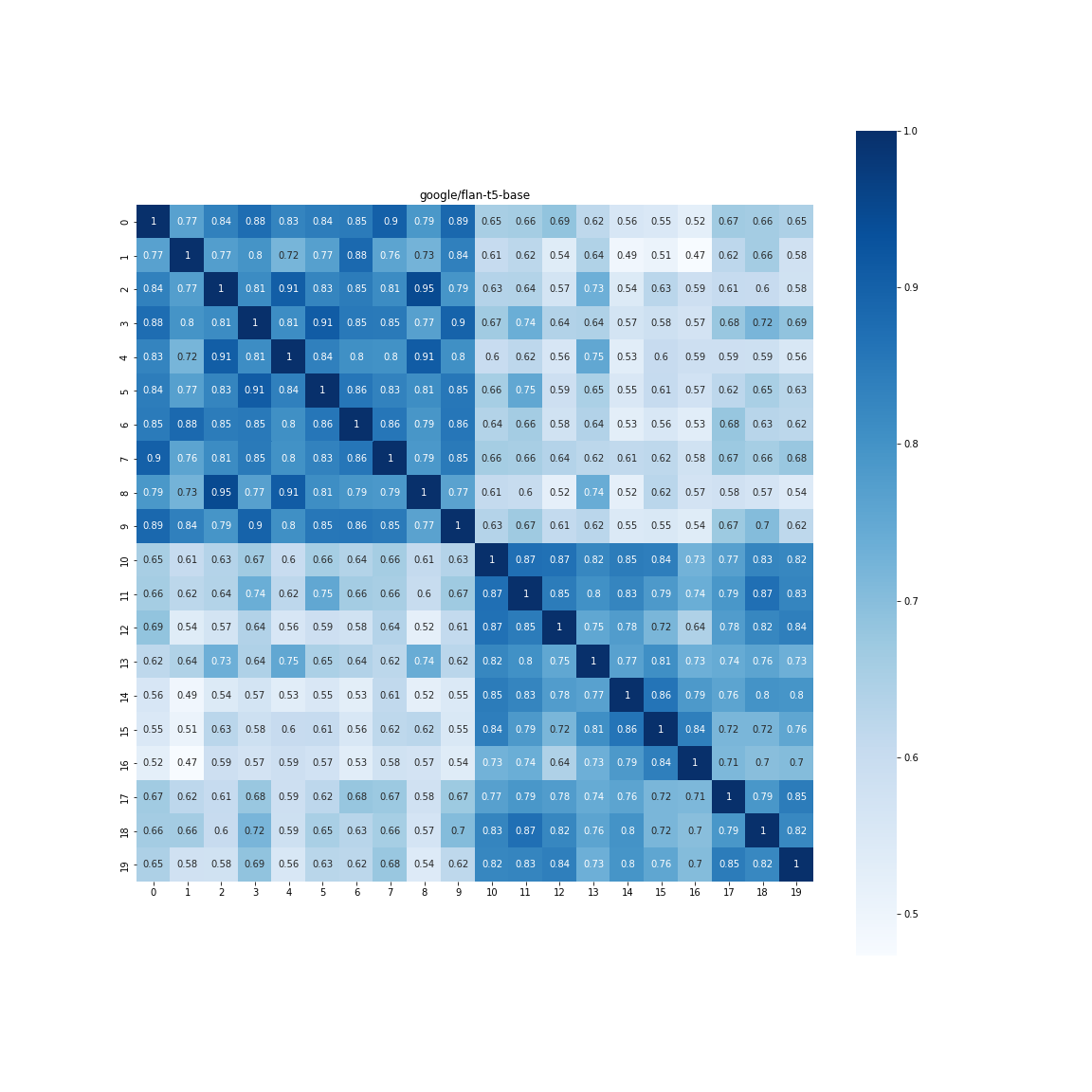
ポジネガ間に0.23も差ができていました。一切Fine-tuneはしていないです。 Flanで「Finetuned Language Models」と言っているだけあって、以前はContrastive LearningのようなFine-tuneで学習するような要素もある程度カバーしているのだと思われます。
参考:OpenAIのEmbedding API
GPT-3のあるOpenAIにはEmbedding APIがあります。よく見ているとこれはSentence Embeddingを取ってくれるので、こちらでも検証してみましょう。
import requests
import json
import numpy as np
OPENAI_API_KEY = "<your-openai-api-key-here>"
def test_embedding(input_string):
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {OPENAI_API_KEY}"
}
data = {
"input": input_string,
"model": "text-embedding-ada-002"
}
res = requests.post(
"https://api.openai.com/v1/embeddings",
data=json.dumps(data),
headers=headers)
print(res.status_code)
result = json.loads(res.text)
embedding = np.array(result["data"][0]["embedding"])
return embedding
同様にプロットしてみると以下のようになりました。
日本語の場合
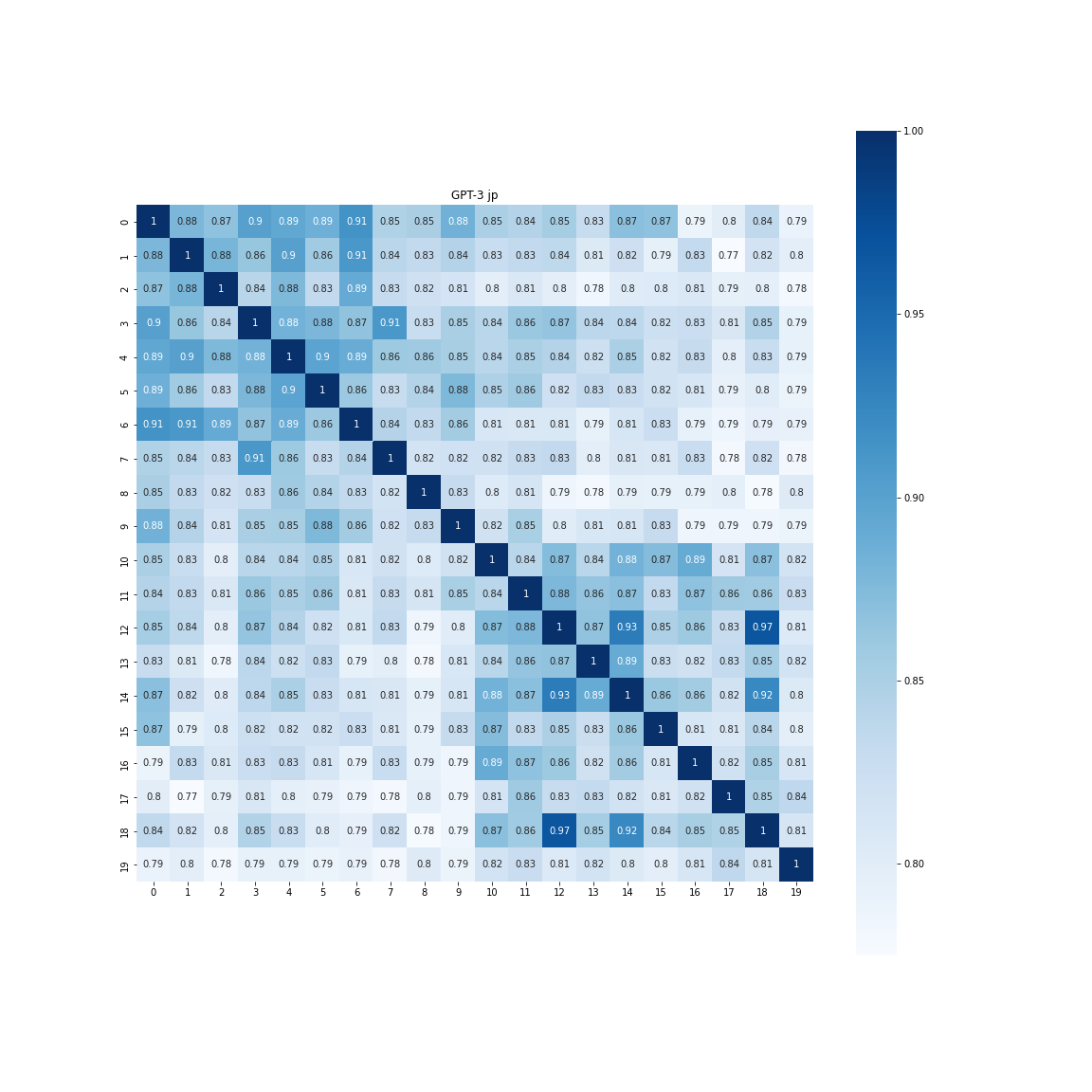
[[0.87516806 0.81397312]
[0.81397312 0.86437926]]
ポジネガ間の差は0.06と思ったより差は出ませんでした。
英語の場合
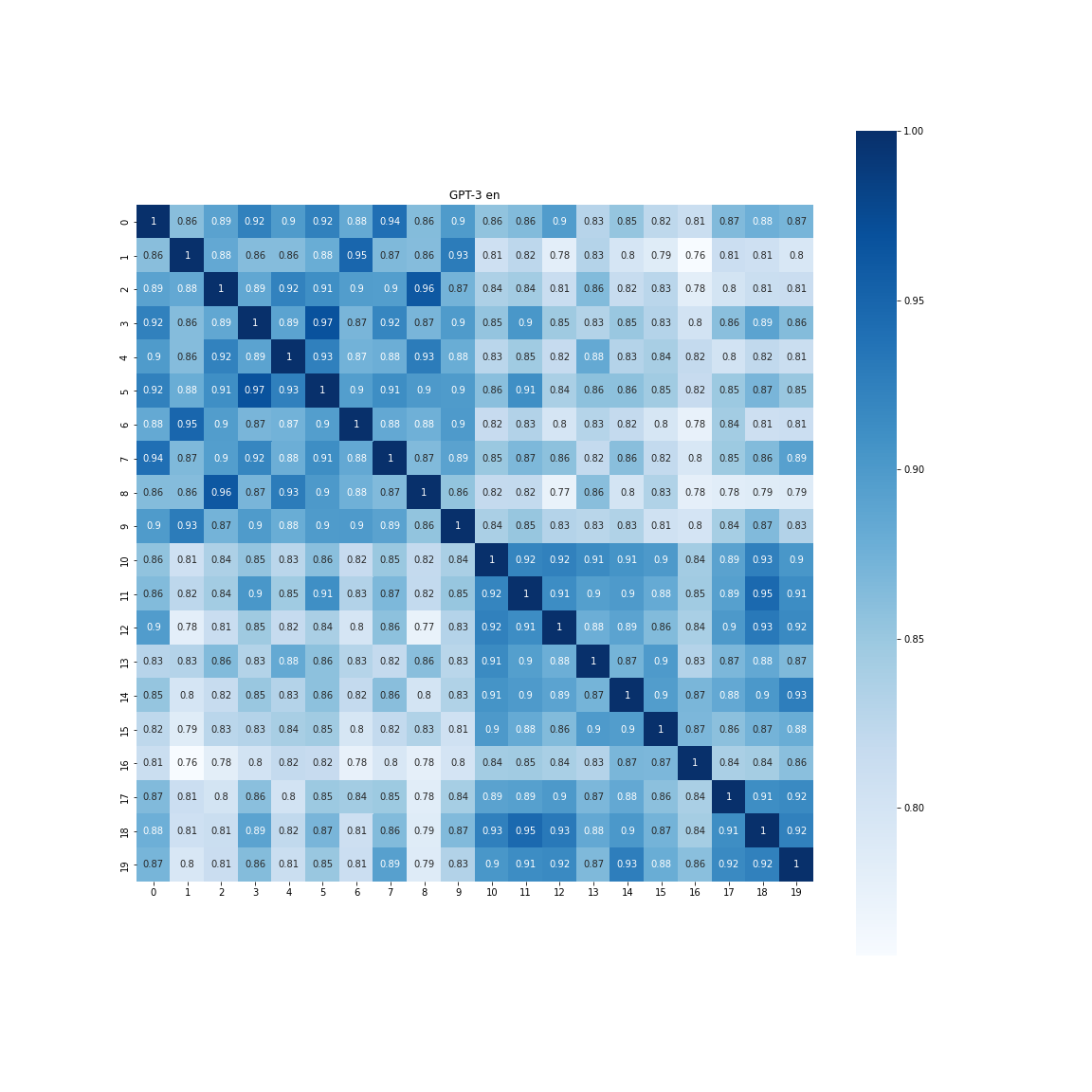
[[0.90626096 0.83129203]
[0.83129203 0.90029497]]
ポジネガ間の差は0.07と、日本語よりかは若干大きくなりました。プロットを見ていても英語のほうがちゃんと分離してくれているように見えます。
ただ、Flan-T5とくらべてどうかというと、明らかにFlan-T5のほうがいいでしょう。この理由は単純で、OpenAIのAPIで公開しているEmbeddingのモデルが、「embedding-ada-002」と古い(第2世代)だからです。
例えばテキスト生成のアプリでは「text-davinci-003」のモデルがデフォルトで使われていますが、こちらは第3世代のモデルです。古いモデルを公開しているから、最新モデルのほうがいいEmbeddingを持っているというのは当たり前ですよね。
text-davinci-003のようなGPT-3のEmbeddingを下手に公開してしまうと、リクエストの物量作戦で、クローズドであるGPT-3を模倣するように学習されてしまう(クローンが作られる)からではないかと思います。
また、OpenAIのEmbeddingが1536次元と高めなので、埋め込み空間で多重共線性的なことがおこってコサイン類似度の値が若干サチったのかもしれません。
GPT-3に対する期待値を高めで持っておくと、ここらへんの意外性にあれ?と思ってしまうかもしれません。ここが新しい発見でした。
所感
自然言語処理の素人でも、T5からSentence Embeddingを割りと簡単にできていろいろ活用できそうで楽しかったです。Flan-T5強いですね。たまにNLPやってみるのもいいですね。
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー