
LLMの推論システムの定式化(1):GPU以外のボトルネック


LLM推論時にGPU以外が占める遅延要因(SQSのバッチ処理やログ書き込み等)を実験的に検証し、オーバーヘッドは入力トークン数に対してほぼ線形に近似できることを示した。トークナイザーの負荷は軽微だが、SQSとDynamoDBへの書き込みが大きなボトルネックとなり、並列化や非同期化で大きく改善できる。
目次
はじめに
- LLMの推論システムの定式化というのはあまり見たことがない。究極的にやりたいことはLLMの推論システムにおける原価計算で、GPUインスタンスの料金や、推論速度を変数として損益分岐点を探るというもの
- LLMの推論におけるボトルネックをGPUに起因するものと、起因しないものに分解し、この記事ではGPUに起因しないものを理論と実験の両方から検証する。
- GPUに起因しないものは、トークナイザーによるエンコードや、キューからの読み出しや、ログへの記録である。このオーバーヘッドは入力トークン数に対する線形関数で大まかに表されることがわかった。
- トークナイザーのボトルネックは小さく、キューからの読み出しのボトルネックが大きめで、最低限ログへの書き込みの非同期化などは必要
LLMの推論システムにありがちな構成
LLMのバックエンドAPIってミニマムだとこんな構成になると思われる。昔からMLってこんな構成が多かったが、今も昔もそこは変わっていないはず。
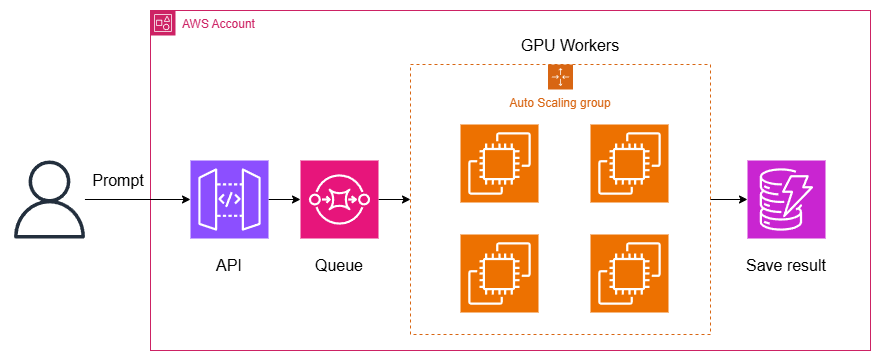
ユーザーがプロンプトが入力すると、API GatewayのようなAPIの前段がいて、SQSのようなキューに入れられて、GPUのワーカーがそれを処理するというシステム。結果が出てきたらログや結果の表示用に何らかのデータベースに格納する(この例では、わかりやくDynamoDBにしている)。非同期APIならこれで終わりだし、同期APIならユーザーに結果を返す。
処理時間の大半はGPUのLLMの推論部分だが、それ以外のオーバーヘッド(特にキューやプロンプトのエンコーダーの部分)ってあんまり考慮されていないよね? っていうのが疑問。ここを実験的にどの程度のオーバーヘッドがあるかを確認する。
LLMの推論時間のモデリングと実験の目的
究極的にやりたいことは、LLMの推論時間のモデリング。LLMのやっていることは(MLモデル一般だけど)、以下のマッピング
$$x_i\to \hat{y}_i$$
- プロンプトが$x_i$であったときに、返答が$\hat{y}_i$
- データセット全体は$(x_i, y_i)_{i=1}^N$
- $y_i$は正解データ。通常$y_i$はLLMの訓練するときに利用するもので、推論時は観測できない
$i$番目の推論時間を$T_i$としたとき以下の式で表される。
$$T_i = \mathcal{E}(x_i) + \mathcal{D}(\hat{y}_i|x_i)$$
狭義には、$\mathcal{E}(\cdot)$はトークナイザーなどのエンコード関数、$\mathcal{D}(\cdot)$はLLMなどのデコード関数を示す。
推論システム全体を考えると、SQSからのポーリングやログの書き込みなどの、GPU以外のオーバーヘッドは$\mathcal{E}$側で含める。トークナイザーなどの前処理もこちら。$\mathcal{D}(\cdot)$は純粋なLLMを推論するときの、GPU時間で、Token Per Second(TPS)などの一般的な速度の指標の関数となる。
トークナイザーの計算量など、一定入力トークン数に比例する部分もあるので、プリミティブには$\mathcal{E}(x_i)$は、入力トークン数$|x_i|$の一次関数で近似されれるはずである。
$$\mathcal{E}(x_i)\sim \alpha +\beta|x_i|$$
$\beta$はトークナイザーの計算量など、入力トークン数に対する比例係数で、$\alpha$は固定のオーバーヘッド、すなわちSQSからのポーリングやDynamoDBに対するログの書き込みを表す。非同期処理や出力SQS+LambdaでDynamoDBの処理をEC2からオフロードさせる場合でも、出力SQSへの書き込み部分は$\alpha$でキャッチアップされるはずである。
今回の記事の目的は、$\mathcal{E}(x_i)$は実際にどの程度のオーバーヘッドなのか、どういった関数で表されるのか、本当に一次近似できるのかを実験的に求めることである。
検証のVPCのアーキテクチャー
検証のために以下のVPCを定義する。
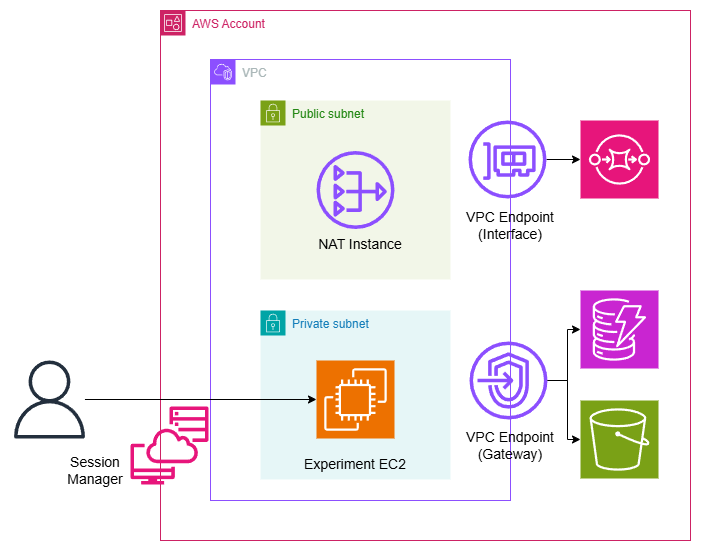
NATゲートウェイが高いのでNATインスタンスを使っている。本来LLMの推論処理はNATのようにインターネットに出ていく部分は必要はないのだが、実験のPythonコードだとトークナイザーの初期化の部分でHuggingFaceにリクエストを送ったり、SSH(Session Manager)でつなぐ必要があったりなど、実験の都合でEC2がインターネットに通信できたほうが便利なので、NATをつけている。
ただ、NATインスタンスは結構通信にオーバーヘッドがあるので、SQSやDynamoDBへの書き込みをガチるためにVPCエンドポイントをつけている。これらのAWSサービスへのやり取りをエンドポイント経由でできるように通信をNATからオフロードさせている。ゲートウェイ型とインターフェイス型の両方を設置し、ゲートウェイ型はS3とDynamoDB、インターフェイス型はSQS用につけている。
通信をオフロードできているのか?
これが実験EC2にでのトラフィック。SQSからPub/Subしている部分で結構通信が発生している。
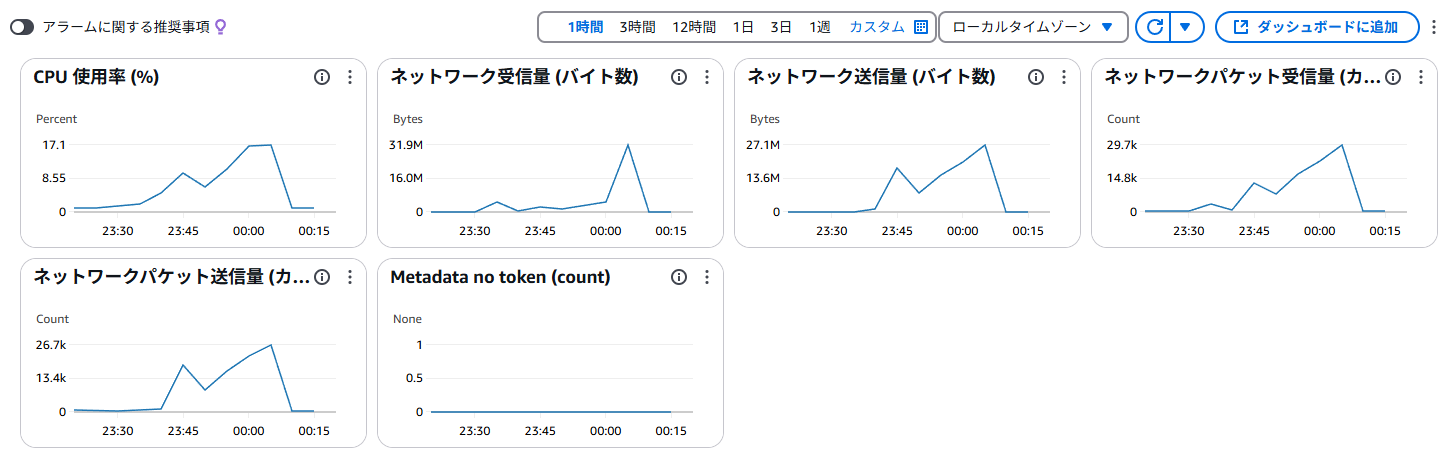
同時期のNATインスタンスのトラフィック。最初にちょっと発生しているが、SQSの部分は明らかに出ていない。ほぼほぼVPCエンドポイントにオフロードできているものと考えて良い。
実験設定
計測用データ
Japanese MT Benchのプロンプトをベースに、いろんな既存のLLMプラットフォーム(OpenAI、Bedrock、Vertex AI)のいろんなモデルで推論させて、$(x_i, \hat{y}_i)$を大量に得る。このJSONLは以下の通り。
これをGPUを抜いた推論エンドポイントのアーキテクチャーに入れて、GPU以外のオーバーヘッドを計測するというもの。$\mathcal{E}(\cdot)$の部分。
各APIが入力と出力のトークン数を持っているので、これを組み合わせることで$\mathcal{E}(x_i)$の関数の形がわかるという仕組み。
使用したトークナイザー
上のデータを以下の3つのトークナイザーで評価。トークナイザー間でほぼ差がないことを示すため。トークナイザーの切り替えは計測時間から無視する。
TOKENIZER_NAMES = [
"meta-llama/Llama-3.3-70B-Instruct",
"google/gemma-2-27b-it",
"microsoft/phi-4"
]
使用したEC2
AWSのm7i.largeをUbuntuで使用した。このインスタンスを選択した理由は、バースト要因がないこと(M系)、GPUのインスタンスはCPUが結構リッチなことが多いので、一定リッチなインスタンスを用意したほうがいいこと。ちなみに計測中はほとんどCPU使用率は上がらなく、10~20%程度だった(トークナイザーのエンコード処理は結構軽い)。
オーバーヘッドのアブレーション
検討したケース
いろんなタイプのアーキテクチャー、処理を変えてみて全体のオーバーヘッドがどの程度変わるのかを確かめてみた
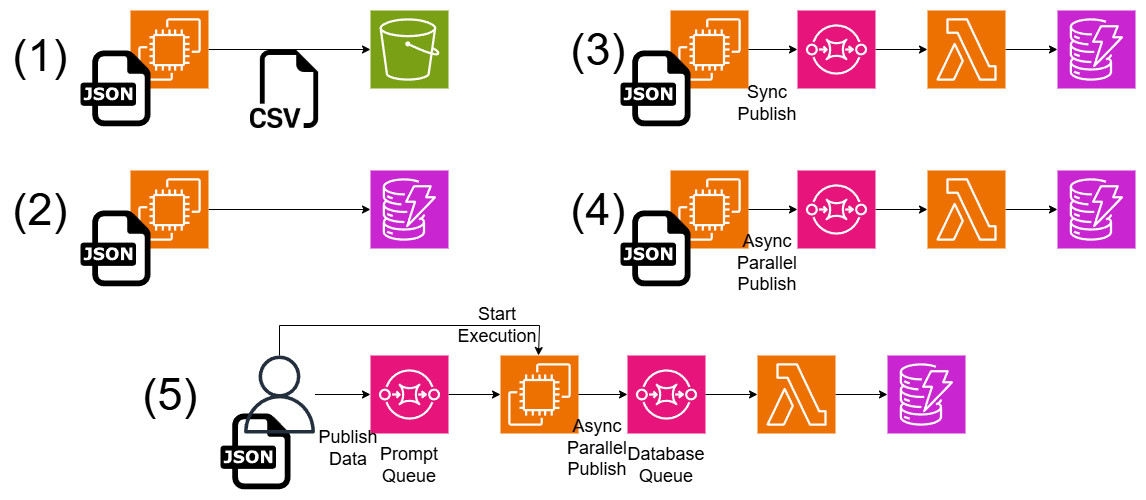
各アーキテクチャーの違いは以下の通り。(5)が最もリアルのシステムに近い。
- (1):EC2に埋め込んだJSONLファイルを、EC2から読み込み、トークナイザーの処理だけを行い、結果をキャッシュ。全体の処理が終わったら結果をCSVに変換してS3にアップロード。ログやポーリングの関係ない、純粋なトークナイザーだけの時間がわかる
- (2):EC2に埋め込んだJSONLファイルを、EC2から読み込み、トークナイザーの処理を入れてその場でDynamoDBに記録。(1)にログの機能が入る。ここでのDynamoDBはログというよりパフォーマンス測定のためのタイムスタンプ記録目的で使っている。
- (3):DynamoDBの記録部分がややオーバーヘッドになるので、記録部分をSQS+Lambdaにオフロードする。ここでのSQSは後段のSQSで、ユーザーからプロンプトを受け付けるイメージではない。SQSへのPushは同期的に行う。データは相変わらずEC2に埋め込んだ固定のデータを使う。
- (4):(3)のデータベースSQSへのPushを非同期処理化して並列化するもの。SQSへのPushがメインの処理をブロッキングしているので、これを行うことで大幅にスループットが良くなる。
- (5):(4)にインプットのSQSをつけたもの。インプットのSQSはユーザーから受け付けたプロンプトをおいておくイメージ。プロンプトSQS→EC2は同期的に処理する(ここを非同期で処理すると、実際はCUDAのOOMのクラッシュが起こるため)。EC2→データベースへのSQSへのPublishは引き続き非同期並列で行う(ここは割とどうでもいいため)。この状態が一番リアルのシステムに近い。
入力トークン数の統計量
推論データ全体について、入力トークン数は以下の統計量。
| 統計量 | token_count | api_input |
|---|---|---|
| Q1 | 72 | 64 |
| Median | 231 | 224 |
| Q3 | 556 | 526 |
| 合計 | 13,822,778 | 12,469,326 |
| 平均 | 402.20 | 362.82 |
データは全体で11456件ある。3種類のトークナイザーで計測しているため、平均×データ件数×3が合計トークン数となる。
token_count:EC2内でエンコードしたとき使ったトークナイザー(例:AutoTokenizer.from_pretrained(...))でエンコードしたときのトークン数api_input:元データ(Japanese MT Bench)をLLMのAPI(OpenAI、Bedrock、Vertex AIなど)でサンプリングしたときに得られたトークン数。APIの返り値を使用。
ケース別の所要時間
表にまとめると以下の通り
| ケース | SQSからの読み込み | トークナイザー | SQSへのPush | DynamoDBへの書き込み | 総所要時間(m:s.ms) |
|---|---|---|---|---|---|
| (1) | ✓ | 00:15.621 | |||
| (2) | ✓ | ✓ | 04:17.364 | ||
| (3) | ✓ | 同期 | 別のLambda | 03:55.018 | |
| (4) | ✓ | 非同期 | 別のLambda | 00:51.039 | |
| (5) | ✓ | ✓ | 非同期 | 別のLambda | 01:38.887 |
総所要時間は3つのトークナイザーの所要時間の合計である。ここからわかることは
- トークナイザー自体の処理は15秒とほとんどボトルネックではない(1)
- しかし、DynamoDBのログの記録を加えると、4分17秒と非常に大きなボトルネックになる(2)
- DynamoDBをSQS+Lambdaの別立てにしてもそれほど改善しない(3)。SQSへの書き込みを非同期+並列化にすると、51秒と若干良くなる(4)。
- プロンプトのSQSから取ってくる部分はどうしようもない固定のオーバーヘッド。結局1分38秒が避けられないシステム全体のオーバーヘッドとなり、$\sum\mathcal{E}(x_i)$に相当する(5)
SQSのバッチサイズはいずれも10とし、ログのSQSに書き込むときの並列プロセス数も10としている。ここは調整すれば幾分かは改善するが、ひとまずは(5)の値(全体で1分38秒)がGPU以外のオーバーヘッドとする
オーバーヘッドの関数の形
トークン数と所要時間の関係を見ることで、$\mathcal{E}(x_i)$の関数の形を推定する。
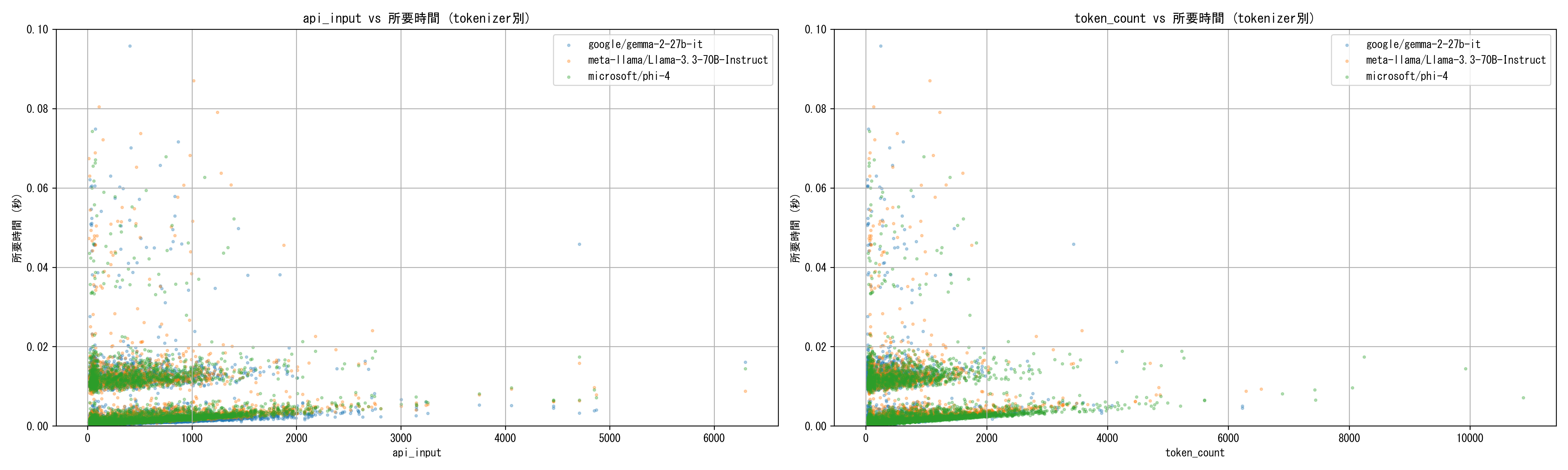
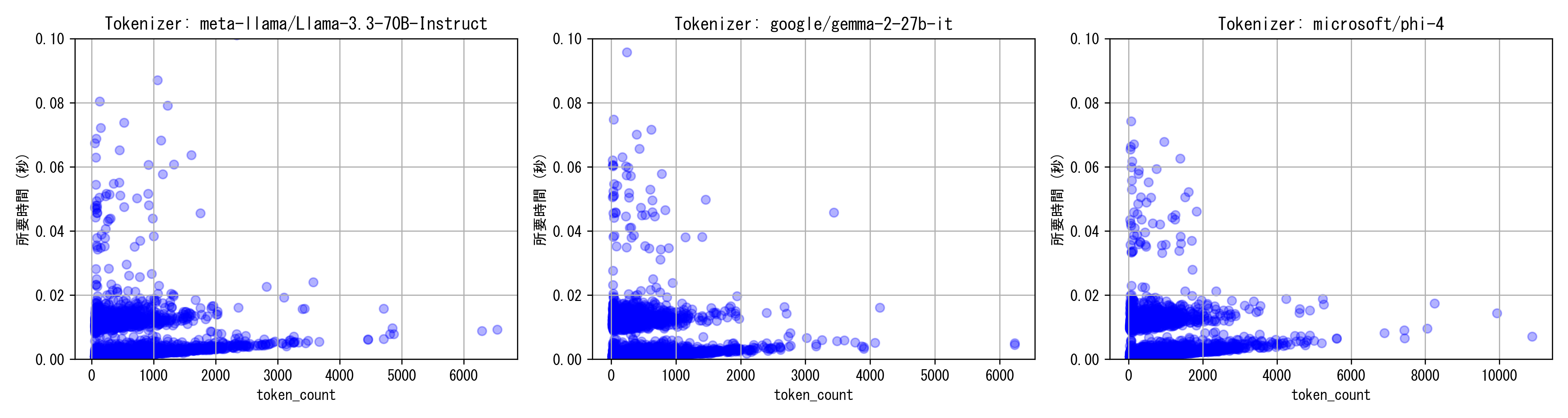
api_input、token_countで見ても、入力トークン数に対して線形の分布が得られている。トークナイザー間はほとんど差がない。その一方で、分布が2コブになっており固定のオーバーヘッドが発生している。これはSQSのバッチ削除のオーバーヘッドで、バッチの切り替わりに発生する
これの裏付けは所要時間のヒストグラムを見るとわかる。
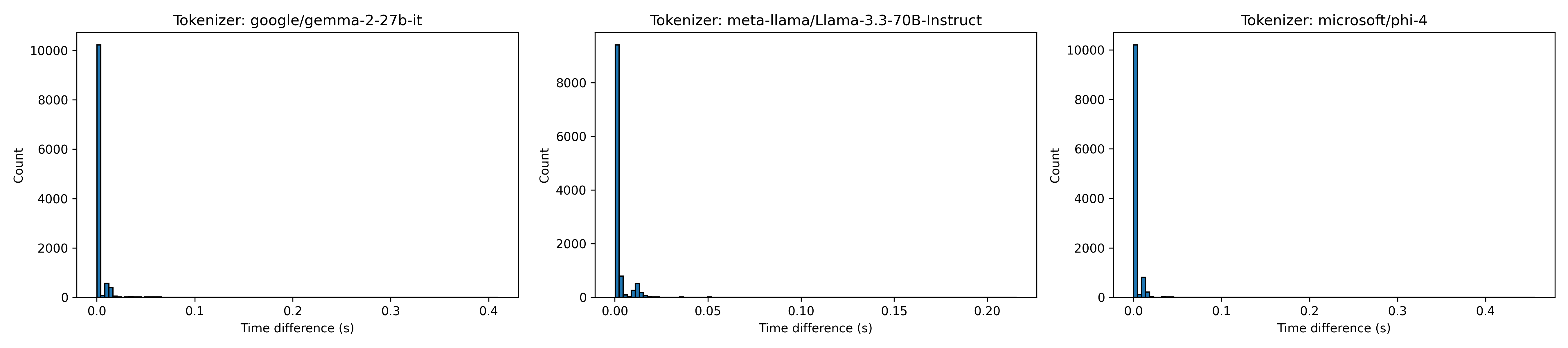
ほとんどのサンプルが低レイテンシーなのに対して、2コブ目はおおよそ全体の10%程度で固定のオーバーヘッドが出ている。SQSのバッチサイズが10なので、SQSのバッチ削除のオーバーヘッドである。
定式化
$i$番目のサンプルがバッチの切り替わりのときを$B_i=1$、バッチの切り替わりでないときを$B_i=0$として、それに対応する指示関数を$\mathbf{1}_{B_i=1}$とすると、より正確には$\mathcal{E}(x_i)$は、
$$\mathcal{E}(x_i)\sim\alpha_1 + \alpha_2\mathbf{1}_{B_i=1} + \beta|x_i|$$
で表現できる。$\alpha_1$はバッチの切り替わりの定数にもキャッチできないノイズ項である(通信ノイズなど)。$\alpha_2$のある第2項はバッチの切り替わりかどうかなので、バッチサイズが10なら「10回中1回発生する」ような周期的な値となる。平均的に考えれば、第1項に含められ、
$$\mathcal{E}(x_i)\sim \alpha +\beta|x_i|$$
で表現できて最初の仮説通りである。$|x_i|$は入力トークン数である。
考察
- そもそものSQSのオーバーヘッドが大きいが、これはこの設定だとGPU部分を考慮していなく、実際はGPUのオーバーヘッドが相当大きい。SQSを変えますみたいなことは一旦考えなくても良さそう
- どうしても変えたいならここはElastiCache(Redis)になると思う
- ロギング系はSQSで別立てにしたほうが良さそう
- 一旦はGPU以外のボトルネックがわかったので、全体の料金構成やGPUを含めた定式化をやっていきたい
コード
(5)のケース
EC2側で動かしたコード
# SQSキューのURL設定
SQS_INPUT_QUEUE_URL = "https://sqs.ap-northeast-1.amazonaws.com/your-account-id/experiment-prompt-queue" # 入力SQSキューのURL
SQS_OUTPUT_QUEUE_URL = "https://sqs.ap-northeast-1.amazonaws.com/your-account-id/experiment-db-queue" # 出力SQSキューのURL
import os
import json
import datetime
import boto3
from transformers import AutoTokenizer
from concurrent.futures import ThreadPoolExecutor, as_completed
# 使用するトークナイザーのリスト
TOKENIZER_NAMES = [
"meta-llama/Llama-3.3-70B-Instruct",
"google/gemma-2-27b-it",
"microsoft/phi-4"
]
EXPERIMENT_ID = "sqs_10" # 適宜変更してください
sqs = boto3.client("sqs", region_name="ap-northeast-1")
def push_payload_to_sqs(payload):
response = sqs.send_message(
QueueUrl=SQS_OUTPUT_QUEUE_URL,
MessageBody=json.dumps(payload)
)
return response
def push_payload_to_sqs_async(executor, payload):
"""
ThreadPoolExecutor を利用して、SQS送信を非同期に実行する
"""
return executor.submit(push_payload_to_sqs, payload)
def encode_item(data, tokenizer, tokenizer_name):
# 処理開始時間
start_time = datetime.datetime.now(datetime.timezone.utc).isoformat()
# 各メッセージを「role: content」の形式で結合(トークナイザー依存)
chat_text = tokenizer.apply_chat_template(data["prompt"], tokenize=False)
# トークナイズ処理
encoded = tokenizer(chat_text, add_special_tokens=True)
token_count = len(encoded.get("input_ids", []))
# 処理終了時間
end_time = datetime.datetime.now(datetime.timezone.utc).isoformat()
# ペイロード作成
payload = {
"experiment_tokenizer": f"{EXPERIMENT_ID}#{tokenizer_name}",
"id": data["id"],
"model": data["model"],
"start_time": start_time,
"end_time": end_time,
"token_count": token_count,
"api_input": data["usage"]["input"],
"api_output": data["usage"]["output"],
"experiment": EXPERIMENT_ID,
"tokenizer": tokenizer_name,
}
return payload
def delete_messages_in_batch(receipt_handles):
# receipt_handles: 削除対象の receipt handle のリスト
entries = [{"Id": str(idx), "ReceiptHandle": rh} for idx, rh in enumerate(receipt_handles)]
response = sqs.delete_message_batch(
QueueUrl=SQS_INPUT_QUEUE_URL,
Entries=entries
)
return response
def process_messages(executor):
# 各トークナイザーを事前にロード
tokenizers = {}
for tokenizer_name in TOKENIZER_NAMES:
print(f"トークナイザー {tokenizer_name} をロード中...")
tokenizers[tokenizer_name] = AutoTokenizer.from_pretrained(tokenizer_name)
print("入力SQSからメッセージをポーリングします...")
futures = [] # 非同期送信タスクのリスト
cnt = 0
while True:
response = sqs.receive_message(
QueueUrl=SQS_INPUT_QUEUE_URL,
MaxNumberOfMessages=10, # 一度に最大10件取得
)
messages = response.get("Messages", [])
if not messages:
print("入力SQSにメッセージが存在しません。")
break
# バッチ削除用のエントリを蓄積
delete_entries = []
for message in messages:
receipt_handle = message["ReceiptHandle"]
data = json.loads(message["Body"])
# data["tokenizer"] に合わせたトークナイザーを取得
tokenizer = tokenizers[data["tokenizer"]]
payload = encode_item(data, tokenizer, data["tokenizer"])
# 非同期でSQS送信を実行
future = push_payload_to_sqs_async(executor, payload)
futures.append(future)
# delete_message_batch用のエントリを作成(最大10件まで可能)
delete_entries.append({
"Id": message["MessageId"],
"ReceiptHandle": receipt_handle
})
if cnt % 5000 == 0:
print(f"送信件数: {cnt}")
print(f"送信ペイロード: {payload}")
cnt += 1
# 一括でメッセージを削除
if delete_entries:
sqs.delete_message_batch(
QueueUrl=SQS_INPUT_QUEUE_URL,
Entries=delete_entries
)
# 全ての非同期送信タスクの完了を待つ
for future in as_completed(futures):
try:
response = future.result()
except Exception as e:
print("SQSへのPush中にエラーが発生:", e)
def main():
# SQS送信用のスレッドプールを作成(max_workersは環境に応じて調整)
with ThreadPoolExecutor(max_workers=10) as executor:
process_messages(executor)
if __name__ == "__main__":
main()
ローカルからのキューの送信
import os
import json
import boto3
import uuid
import re
# SQSキューのURL設定
SQS_INPUT_QUEUE_URL = "https://sqs.ap-northeast-1.amazonaws.com/your-account-id/experiment-prompt-queue" # 入力SQSキューのURL
# 使用するトークナイザーの名前(全パターン)
TOKENIZER_NAMES = [
"meta-llama/Llama-3.3-70B-Instruct",
"google/gemma-2-27b-it",
"microsoft/phi-4"
]
# JSONLファイルのパス
jsonl_path = "docker/vanila/all_data.jsonl"
sqs = boto3.client("sqs", region_name="ap-northeast-1")
BATCH_SIZE = 10
with open(jsonl_path, "r", encoding="utf-8") as f:
# 改行コードの統一
lines = f.read().strip().replace("\r\n", "\n").split("\n")
for tokenizer_name in TOKENIZER_NAMES:
batch_entries = []
for i, line in enumerate(lines):
if not line.strip():
continue
data = json.loads(line)
# 送信ペイロードにトークナイザー名(名前のみ)を付与
payload = data.copy()
payload["tokenizer"] = tokenizer_name
del payload["answer"]
# バッチエントリ作成: "Id"は各メッセージ毎にユニークな文字列にしてください
# トークナイザー名からバッチエントリ用のID作成
# 許可される文字は英数字、ハイフン、アンダースコアのみ
safe_tokenizer = re.sub(r"[^a-zA-Z0-9\-_]", "_", tokenizer_name)
entry_id = f"{i}_{safe_tokenizer}"
# 最大80文字に調整(必要なら)
entry_id = entry_id[:80]
entry = {
"Id": entry_id,
"MessageBody": json.dumps(payload)
}
batch_entries.append(entry)
# バッチサイズに達したら送信
if len(batch_entries) == BATCH_SIZE:
response = sqs.send_message_batch(
QueueUrl=SQS_INPUT_QUEUE_URL,
Entries=batch_entries
)
print(f"バッチ送信完了: トークナイザー {tokenizer_name} のメッセージ {len(batch_entries)} 件")
batch_entries = []
# 残りのメッセージがあれば送信
if batch_entries:
response = sqs.send_message_batch(
QueueUrl=SQS_INPUT_QUEUE_URL,
Entries=batch_entries
)
print(f"バッチ送信完了: トークナイザー {tokenizer_name} の残りメッセージ {len(batch_entries)} 件")
SQSとDynamoDBの定義
resource "aws_dynamodb_table" "experiment_records" {
name = "experiment_records"
billing_mode = "PAY_PER_REQUEST"
hash_key = "experiment_tokenizer"
range_key = "id"
attribute {
name = "experiment_tokenizer"
type = "S"
}
attribute {
name = "id"
type = "S"
}
}
resource "aws_sqs_queue" "experiment_db_queue" {
name = "experiment-db-queue"
}
resource "aws_sqs_queue" "experiment_prompt_queue" {
name = "experiment-prompt-queue"
}
続き
LLMの推論システムの定式化(2):価格理論の推論速度の統合
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー