
論文まとめ:Competitive Programming with Large Reasoning Models


大規模言語モデル(LLM)を強化学習によって訓練し、競争プログラミングにおける高度な推論とコーディング能力を高めたOpenAIによるLRMの研究。特にo3モデルは、人間によるドメイン特化のテスト戦略を使わずとも、IOIやCodeForcesなどで上位レベルの成績を収める性能を示した。
- タイトル:Competitive Programming with Large Reasoning Models
- 著者:OpenAIの方々
- 論文URL:https://arxiv.org/abs/2502.06807
目次
論文まとめ By Gemini
この論文「Competitive Programming with Large Reasoning Models」は、大規模言語モデル(LLM)の競争プログラミングにおける性能向上を、強化学習を用いて達成することを目指しています。
・この論文において解決したい課題は何?
大規模言語モデル(LLM)を用いた競争プログラミングにおける、高度な推論能力とコーディング能力の向上です。特に、人間が設計したテスト時戦略への依存を減らし、LLM自身の推論能力を高めることが課題です。
・先行研究だとどういう点が課題だった?
先行研究であるAlphaCodeなどは、大量の候補解を生成し、人間が設計したテスト時戦略で上位解を選択する手法を用いていました。これは、モデル自身の推論能力ではなく、人間による介入に大きく依存している点が課題でした。
・先行研究と比較したとき、提案手法の独自性や貢献は何?
強化学習を用いて、大規模推論モデル(LRM)を開発し、人間が設計したテスト時戦略への依存を軽減しました。特に、o3モデルは、高度なテスト時推論戦略を自律的に学習し、人間による介入なしに高い性能を達成した点が独自性であり、大きな貢献です。
・提案手法の手法を初心者でもわかるように詳細に説明して
OpenAIは、強化学習を用いて「思考連鎖」を学習するLRMを開発しました。o1モデルは、問題解決の過程を段階的に記述する思考連鎖を用い、強化学習によってその精度を向上させました。o1-ioiモデルは、o1モデルをIOI向けに微調整し、AlphaCodeと同様のテスト時戦略を導入しました。o3モデルは、o1-ioiモデルよりもさらに大規模な強化学習を行い、人間による介入なしに高度なテスト時戦略を自律的に学習しました。o3は、自力で解を検証するなど、高度な推論能力を示しました。
・提案手法の有効性をどのように定量・定性評価した?
CodeForcesとIOI 2024での成績、HackerRank AstraとSWE-bench Verifiedを用いた定量評価を行いました。CodeForcesでは、o3モデルがトップレベルの人間プログラマーに匹敵する成績を達成しました。IOI 2024では、o3モデルは人間が設計したテスト時戦略なしでも金メダルを獲得しました。定性評価としては、o3モデルの思考過程の分析を行い、高度な推論戦略が自律的に学習されていることを確認しました。
・この論文における限界は?
o3モデルは、非常に計算コストの高い強化学習を必要とします。また、特定のドメイン(競争プログラミング)に特化したモデルであるため、他のドメインへの適用可能性は限定的です。さらに、最上位の人間プログラマーにはまだ及ばない点も限界として挙げられます。
・次に読むべき論文は?
論文中に引用されている、o3モデルに関するシステムカード([13] OpenAI o3 system card. Technical Report , 2025.)や、他のLRMに関する論文([3], [15])などが、より詳細な情報を得るために適切でしょう。
論文中にコードは提示されていますが、全てをここに掲載することはできません。論文のAppendix B, Cに掲載されているコードは、論文のPDF版を入手して確認してください。リンクは本文中に記載されているものをご参照ください。
はじめに
- 先行研究:これのタイトルのオマージュ元の『Program Synthesis with Large Language Models』では、244M~137Bの一般的なモデルであっても、自然言語で短いPythonスクリプトを生成できることがわかっている。性能はモデルサイズの対数に線形比例。
- AlphaCode以降、LLMの推論能力を向上するために強化学習を使うことが大きく進展
- 大規模推論モデル:large reasoning models (LRMs)。思考の連鎖を推論し、思考するモデル。OpenAI o1/o3や、DeepSeek-R1やKimi k1.5など。
- 未解決の問題「ドメインに特化した手作業で設計された推論戦略が、モデルが独自に生成・実行する学習済みのアプローチとして良いのか悪いのか」。これをo1、o1-ioi、o3を使って見ていく。
OpenAI o1
- o1=複雑な推論タスクに取り組むために、強化学習で訓練された大規模な言語モデル
- 解凍前に拡張された内部思考の連鎖を生成することで、ステップバイステップで困難な問題を解決する人間の思考を模倣
- o1のようなインコンテクスト推論は、幅広いタスクで全体的なパフォーマンスを大幅に向上
強化学習の有効性
- 複雑な推論に対しては強化学習が有効である
- CodeForceのベンチマークをo1は大幅に持ち上げた
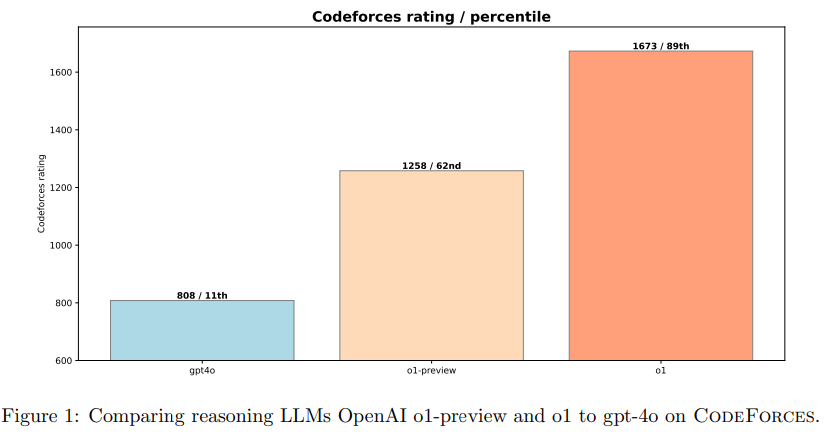
OpenAI o1-ioi
- o1-ioi system for competing at the 2024 International
Olympiad in Informatics (IOI)- 2024年の国際情報オリンピック向けのo1システム
- 強化学習の訓練時の計算量と、テスト時間の推論計算量の両方を増やすことで一貫してモデル性能が向上することがわかった
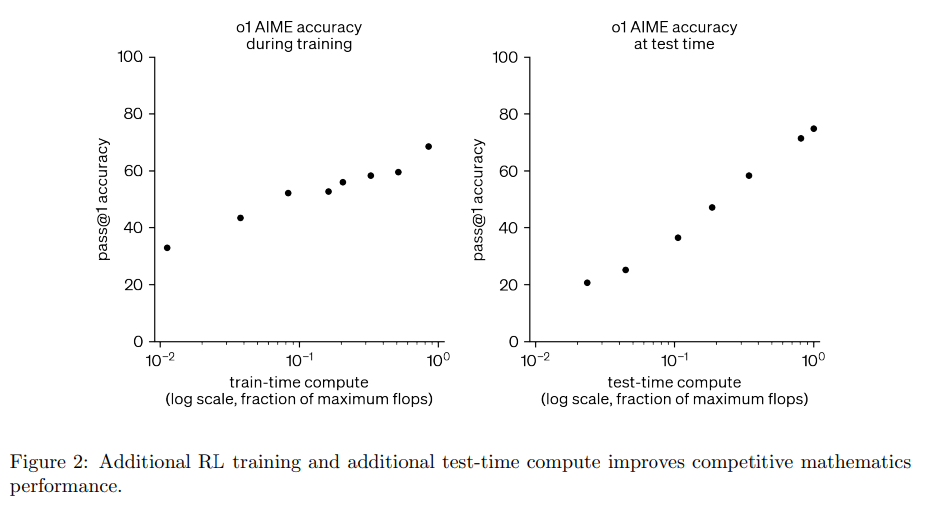
- 強化学習のスケーリングと、テスト時間の推論の拡張は顕著なメリットが有り、この2つを最適化することが重要
o1-ioiでの強化学習のファインチューニング
- o1の強化学習フェーズを拡張し、コーディングタスクに焦点。プログラミングの問題に学習計算を追加し、複雑な解決策、実装、デバッグする能力を強化
- OpenAIのo1チェックポイントから強化学習を再開
- プログラミングの難問に重点をおき、C++の生成と実行時のチェックを改善
- IOIの提出フォーマットで出力するようにモデルを誘導
o1-ioiでのテスト時間戦略
- 各IOI問題をサブタスクに分解。
- 各サブタスクに対して、o1-ioiから10000個の解をサンプリングし、クラスタリングとリランキングにより、このセットからどの解を導出するかを決定
定式化
- IOIでは、スコアリングはサブタスクごとに行われ、各サブタスクの全てのSubmitにわたって、最大スコアを用いる
- サブタスクを別々に解決する。各IOIの問題を、人工的ななサブタスクに分割(採点ガイドに記載された分割を使用)
クラスタリング
- モデルが生成したテスト入力に対する出力に基づいて、生成された解をクラスタリング
- 問題とサブタスクが与えられたときに、256個のテスト入力をC++で生成
- テスト入力の妥当性を確保するために、サブタスクの制約を満たすかどうかのバリデータを記述するようにモデルに促す
- バリデータを75%が通過するテスト入力を受け入れた
- 出力が一致したテストは同じクラスタに配置
リランキング
- テスト時間戦略のためのリランキング
- 学習されたスコアリング関数による解の品質
- モデルが生成したテスト入力の誤差
- 公開されているテスケースに不合格
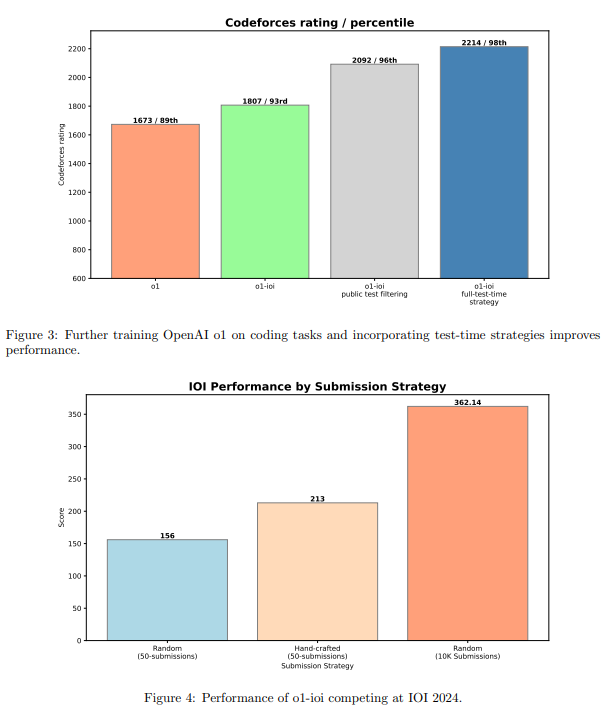
→ o1よりもo1-ioi(IOI独自のチューニング)が有効
- 公開テストに失敗したのをフィルタリングする単純なアプローチが一番効いている
ライブコンペ
- o1-ioiが人間の参加者と同様の条件でIOIに参加した
- 6個の困難なアルゴリズム問題に対して、10時間。1個の問題に対して最大50回の提出が許可された
- 10000個の解候補の中からどれを選択するかが問題
- 下図の左がランダムに50個選択、真ん中が人間が手作業で50個選んで提出、右が10000個の条件を緩和した場合
- 10000個に緩和した場合に大きく伸びるのはモデルの性質というよりIOIのルールによる。サブタスクの最大点の合計を取っているため
OpenAI o3
- o1-ioiはIOIのルールに従って(ドメインに合わせて)、テスト時間戦略を人間がかなりルールベースに作っていた。これを人間の依存性をやめて強化学習でどこまで行けるか
- そもそも論として、強化学習の訓練を進めていくとベンチマークは大きく向上する
- o3は洞察的で意図的な思考の連鎖を示している。自己実装型検証メカニズムが動くようになった
- 公開テストケースに対して解を検証するためのコードを書き、そのフィードバックを元にアップデートするようなループができるようになった
- 検証が自明でない問題は、単純なブルートフォース解を書き、最適化されたアルゴリズムの出力をクロスチェックするようになった
IOI2024ベンチマーク
- IOI2024はo3の知識カットオフ以降にあったもので、IOIのテスト問題が学習データで汚染されていないことを検索で確認
- 本番と同じように1問題あたり最大50件の提出を許可
- 解の選択は、複雑なルールベースのアルゴリズムではなく、1024個のサンプルからテスト計算時間が最も長い50個の解を採用
- テスト時間が最も長いという単純なヒューリスティックアルゴリズムを使うことで、ドメイン固有の人間のチューニングをやめることに成功。o1のときの人間の50個選択したケースはおろか、10Kサブミットしたケースよりも良いパフォーマンスになった
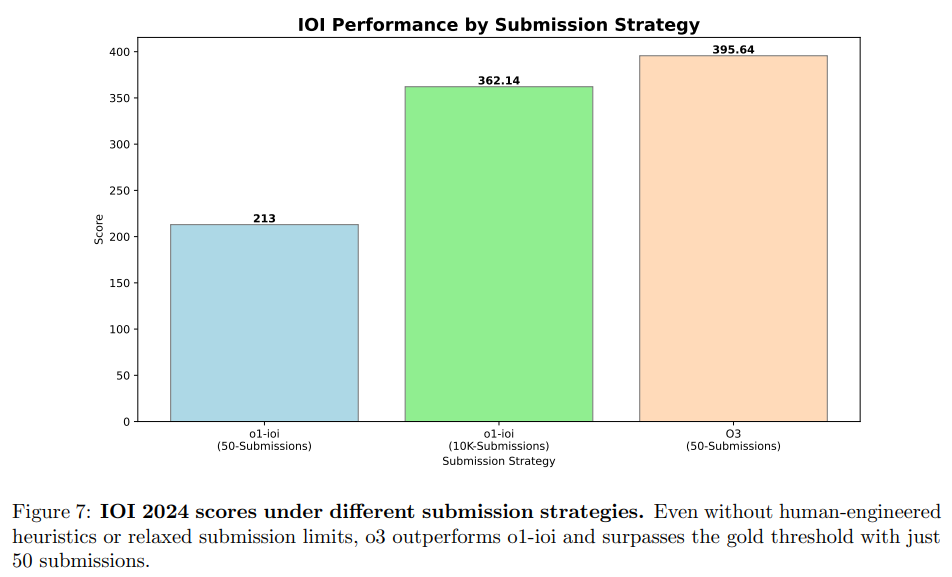
その他のベンチマーク
- CodeForceやIOI2024だけでなく、HackerRank AstraやSWE-bench Verifiedでも検証。一貫して良いことを確認した
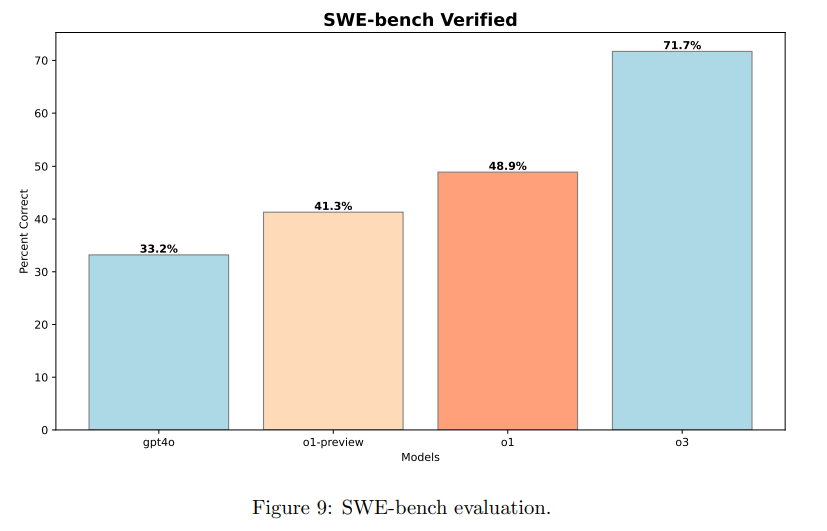
OpenAIの結論
- LRMのような思考連鎖推論が、競技プログラミングから複雑なソフトウェア工学の課題までパフォーマンスを向上させる強力な戦略だった
- 強化学習の訓練時間を増やすこと、テスト時間戦略の強化が一貫したモデル性能を向上させる
- o系の大規模推論モデルは、科学、コーディング、数学、その他多くの分野におけるAIの可能性とユースケースを解き放つだろう
所感・考察
- 大規模推論モデル(LRM)というのが結構注目されるワードになるかと思われる。最近ブラックボックス化しがちだったOpenAIの中でやってることがよくわかった論文
- AGIの構築というすごく大きな問題を、競技プログラミングというミニマムなところからやっていくのが面白い
- o3やo1は自分もよく使っていたが、IOI2024のコンペから結構着想を得ているであろうというのが新発見。論文としてはコンペレポートの側面が強いが、oシリーズの背景を知れてよかった。おそらくDeepSeek-R1の論文が公開されたから出したという感じだと思う
- 強化学習の時間を増やすというのはわかるのだが、テスト時間が一番長いのを最良解としますはさすがにスケール性が乏しい。o3の発表のときに天文学的な時間がいるって言われたのはこれが理由だったっぽい
ここからポエム
- この世の中に存在している問題っておそらく3種類あって、
- 答えが存在している問題:例:1+1=?、関ヶ原の戦いがあった西暦は?
- 答えが存在しない、もしくは存在しているが恐ろしくその発見が難しいものの、答え同士の良し悪しは比べられる問題:例:競技プログラミング、複雑なコーディングタスク、研究
- 答えが存在しなく、その良し悪しも比べられない問題:例:哲学、美、正義のように価値観や主観が入る問題
- 1番目は普通のLLMや検索併用でほぼ全て解ける。2番目がoシリーズで解けるようになりつつ領域。良し悪しが比べられれば強化学習に落とせるというのは理解が容易い(将棋やチェスのレーティングのように)。
- oシリーズもまだコーディングという狭い領域であって、より大きなジャンルにスケールしていくのは結構時間かかりそう。またドメインごとに強化学習する必要があるので、あんまりスケーラブルではない。おそらく今後のGPTでここは強化されていきそう。
- 現実世界の問題はそもそも良し悪しを定義するのが大変で、多面的なことが多くここに人間の労力が割かれていくことが多い(普通の考え方をすると、oシリーズが強化されれば人間の労力はよりここに集中されることになる)ので、そこをデータドリブンで設計できるようになると強そう。しかし、データ自体にもバイアスがあるので、一周回って古典的なデータ分析に戻る可能性すらある。
- AWSのWell-Arcitected Frameworkのようなドクトリンを、事前知識なしでいろんな事例を見てどの程度生成できるのかみたいなのは気になる
- コーディングの場合は、良し悪しの依存関係はないが、現実問題の場合は複雑な依存関係がある(例:高齢者への社会保障を拡充すれば、若年層の課税が強化されてしまう)ので、そこをGPTがどうバランスを取るのかが見もの。
- これからは問題を解くべきことではなく、問題を定義することがより大事そうに見えるが、DeepResearchで結構そのへんのコンサル的なことはできてしまうので、どーなんだろう。
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー