
GANでGeneratorの損失関数をmin(log(1-D))からmaxlog Dにした場合の実験


GANの訓練をうまくいくためのTipとしてよく引用される、How to train GANの中から、Generatorの損失関数をmin(log(1-D))からmaxlog Dにした場合を実験してみました。その結果、損失結果を変更しても出力画像のクォリティーには大して差が出ないことがわかりました。
目次
はじめに
GANの訓練をうまくいくためのTipとしてよく引用される、How to train GANの2番目のTipsの、
Generatorの学習の際には、min(log(1-D))ではなく、maxlogDを使ったほうが良い。前者は勾配消失しやすい
という点についてDCGANで実験してみます。G損失関数を変更して、Inception Scoreがどれぐらい変わるかを実験しました。
はじめに結論
Inception Scoreは大してかわらない
きっかけ・設定
以前GANの訓練がうまくいかないときにHingeロスを使うといいよという話を書いたときに、「Generatorの損失関数を変更すると勾配消失しない」という指摘をいただきました。これが気になって実験したくなりました。
まず勾配消失が起こっているときは、Dの損失が0に限りなく近くなります(逆は必ずしも成立しないそうです)。つまり、Dの損失が0に近いほど、この変更は生きてくるのではないかと思われます。以前書いた記事では、それを再現しやすいように、通常の交差エントロピーで「min(log(1-D))」として訓練したときにDが0に近づくように設定しています。
今回2つのデータに対して実験をしました。
- CIFAR-10 :今回新規にコードを書いてモデルも新規に組んだ。min(log(1-D))で訓練してもそこそこ安定している。
- STL-10 : 前回の記事のコードを流用してGの損失関数だけ変更
つまり、Gの損失関数が2種類、データの2種類の、計4個の実験をしました。
maxlog Dでの最適化をどう書くか
まず、min(log(1-D))→maxlogDへの変更はどうやるのかというと、おそらくこうではないかと思います。若干擬似コードですが、PyTorchの場合、
bce_loss = nn.BCELoss()
# min(log(1-D))で最適化する場合
loss = bce_loss(fake_d_output_prob, torch.ones(batch_size, 1))
# max(log D)で最適化する場合
loss = -bce_loss(fake_d_output_prob, torch.zeros(batch_size, 1))
とすればよいのではないでしょうか。ここで、「fake_d_output_prob」はGの生成した偽の画像をDに通した際の出力(本物か偽物かの確率)とします。普通にBCELossで計算した損失をbackwardすると最小化計算になるので、マイナスをつけて最小化すれば実質最大化になりますよねというのが理屈。
いずれのケースでも、Dの訓練では本物はones, 偽物はzerosで損失計算します。min(log(1-D))の場合はDのones, zerosが逆転しますが、maxlogDの場合は同じになるはずです。
CIFAR-10の場合
CIFAR-10の場合は以下のようになりました。損失推移と、300エポック訓練した最終エポックの出力を貼ります。
min(log(1-D))で最適化
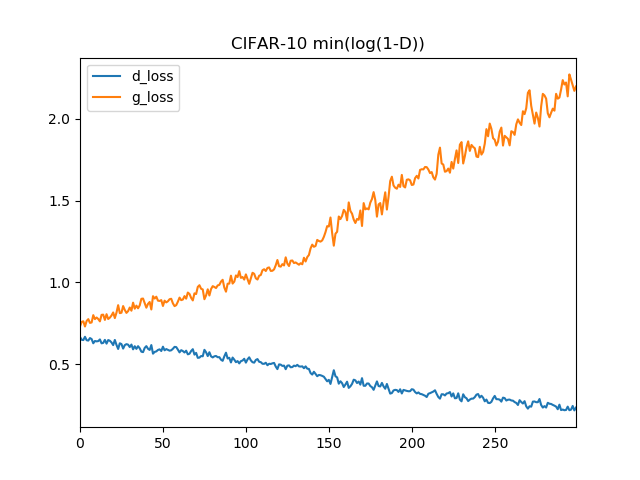

max(log D)で最適化
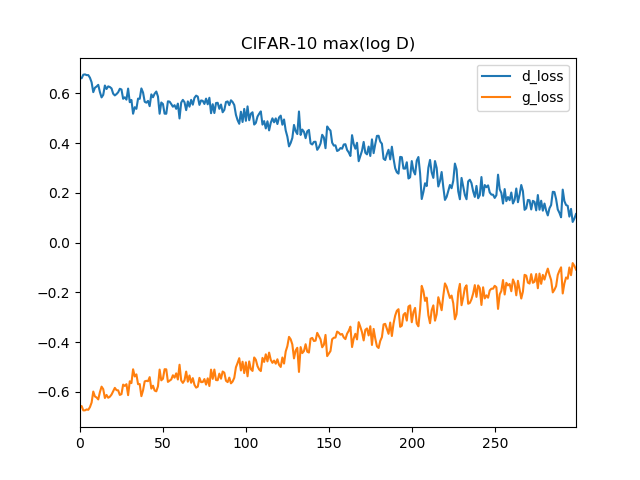

確かにエラー推移を見てると、こっちのほうが安定してそうな気はします
Inception Scoreの推移
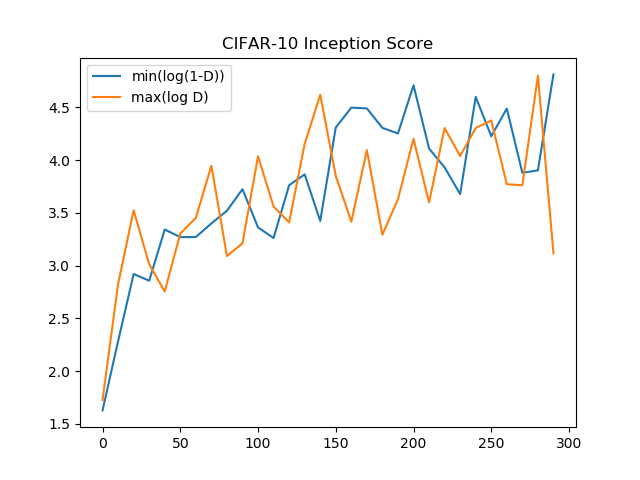
しかし、Inception Scoreで比較するとほとんど差はありませんでした。
STL-10の場合
STL-10の場合、以前の記事で書いたBinary crossentorpy(= min(log(1-D)))、Hinge lossでの損失推移は次のとおりでした。
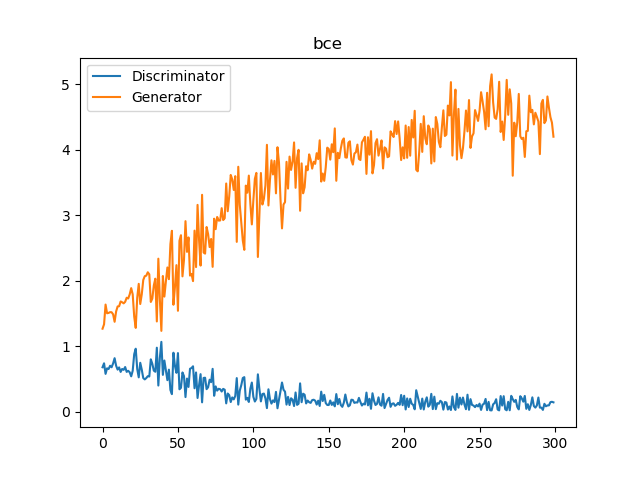
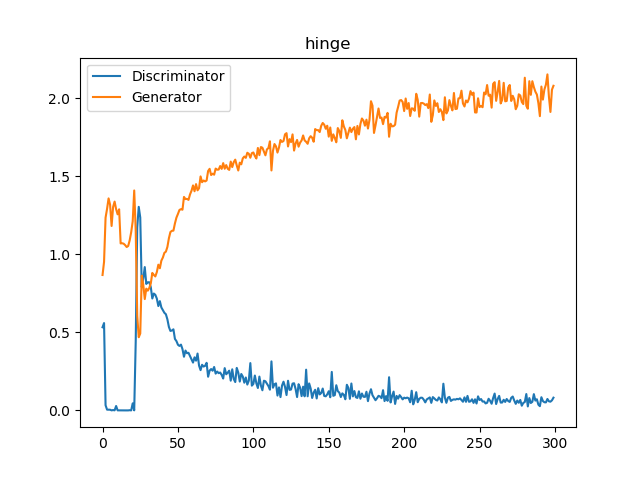
あまりうまく行かないケースを想定して、Dが0に近づきやすいようにしています。
max(log D)で最適化
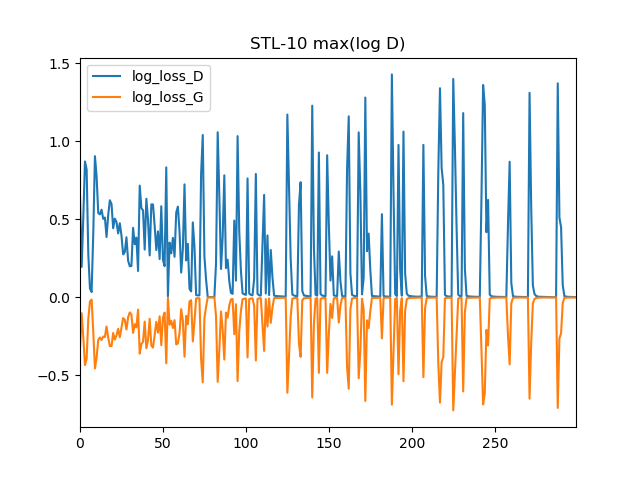
ものすごいスパイクでこれ本当に上手くいってるの?と心配になります。300エポック訓練したときの最後の出力は次のとおりでした。

Inception Scoreの推移
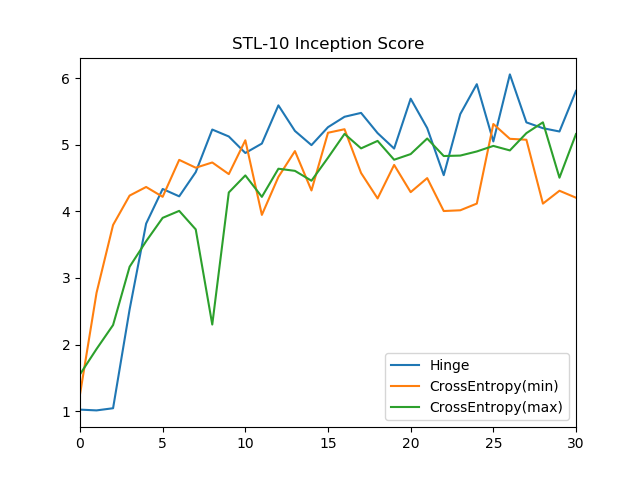
Inception Scoreを測ってみると一目瞭然で、minで最適化しようが、maxで最適化しようが、Inception Scoreには差はなかった。出力画像のクォリティーを上げるなら、Hinge lossを使ったほうが効果がありそう。
まとめ
CIFAR-10, STL-10の実験を通じて以下のことがわかりました。
- 理論的にはmaxで最適化したほうが勾配消失はおきにくくなるだろうが、実際のところInception Scoreを見るとminとmaxにはほとんど差がない
- むしろ、Hinge lossで訓練したほうがInception Scoreは高そう
- 勾配消失と、クォリティーを上げることはおそらく別問題なのではないか
ということでした。何らかの参考になれば幸いです。
コード
STL-10のコードは前回の記事を参照。CIFAR-10のコードは以下の通りです。Inception Scoreの計算はこちらのコードを使用。
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー