
論文まとめ:Patching open-vocabulary models by interpolating weights
Posted On 2022-08-25


- タイトル:Patching open-vocabulary models by interpolating weights
- 著者:Gabriel Ilharco, Mitchell Wortsman, Samir Yitzhak Gadre, Shuran Song, Hannaneh Hajishirzi, Simon Kornblith, Ali Farhadi, Ludwig Schmidt
- 所属:ワシントン大学、コロンビア大学、Google Research
- 論文リンク:https://arxiv.org/abs/2208.05592
目次
ざっくりいうと
- CLIPのようなオープンボキャブラリーモデルを、オープンセットでの精度を維持しつつファインチューニング(FT)するための研究
- FT前後で係数を線形補間することで、柔軟なAPIを維持し、0からの再訓練なく、サポートタスクでの精度を維持
- タイポグラフィ攻撃対策や、未知のクラスへの適用、クラスの外挿・内挿などの応用ができる
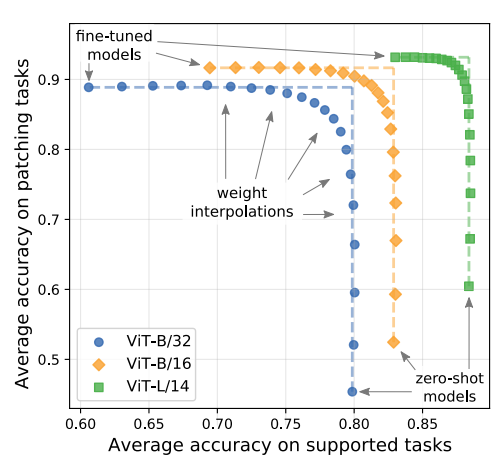
イントロ
- CLIPやBASICのようなオープンボキャブラリーモデルには、まだ課題がある
- ImageNetに特化されたモデルのResNet50において、単純なロジスティック回帰のMNISTより精度が悪い
- ゼロショットの精度は、特定の下流タスクで学習されたモデルよりも普通は悪い
- ラベル付きデータを使って、ゼロショットモデルを目的のタスクに適合させる方法を、複数の著者が提案している
- 一般的な方法はファインチューニング
- ファインチューニングすると、ゼロショットでうまくいったタスクで壊滅的に忘却する
- タスク特有にした分類ヘッドが、オープンボキャブラリーの魅力である柔軟なテキストベースのAPIを犠牲にする
- オープンボキャブラリーの再学習も考えられる
- 1から学習するのは数十万GPU時間が必要で現実的ではない
- 一般的な方法はファインチューニング
- この論文ではPAINT(Patching with interpolation)という手法を提唱。ファインチューニング後のモデルと、元のゼロショットモデルの係数の線形補間
- ニューラルネットワークの係数の線形補間は昔からあり、精度向上や分布シフトへの頑強性に効果があった
- これをオープンボキャブラリーモデルに拡張したもの
- 精度向上と柔軟なAPIの維持が目的
- ImageNetの精度が1%未満の犠牲で、補間後のモデルで下流タスクの精度が15~60%上昇
- PAINTは、合成タイポグラフィ攻撃に対しても効果があり、精度が41%向上
PAINTのいいところ
- 性能が十分でないタスクにおいて、他の精度を損なわずに精度を向上できる
- あくまで係数の補間なので、Fine-tuning時も推論時も計算コストが増えない
- あるタスクにPAINTを適用すると、たとえ同じクラスを共有していなくても、関連するタスクの精度を向上できる
- 複数のタスクに適用でき、状況に応じた特化モデルを提供できる
PAINT
1つのタスクのパッチング
- $\theta_{zs}$:ゼロショットのモデル → $\mathcal{D}_{patch}$のデータでファインチューニング → $\theta_{ft}$:ファインチューニングされたモデル
- $\theta_{patch} = (1-\alpha)\cdot\theta_{zs} + \alpha\cdot\theta_{ft}$で、最適な線形補間の係数$\alpha$を求めたい
- 何を基準にするか? $\mathcal{D}_{supp}$と$\mathcal{D}_{patch}$によるホールドアウト法の精度
- $\mathcal{D}_{supp}$: サポートタスクのデータ
- パッチングタスク、サポートタスクとは? 冒頭の図では、
- パッチングタスク:Stanford Cars, DTD, EuroSAT, GTSRB, KITTI distance, MNIST, RESISC45, SUN397, SVHN
- サポートタスク:ImageNet, CIFAR-10, CIFAR-100, STL-10, Food101
複数のタスクのパッチング
3つの方法を考えた
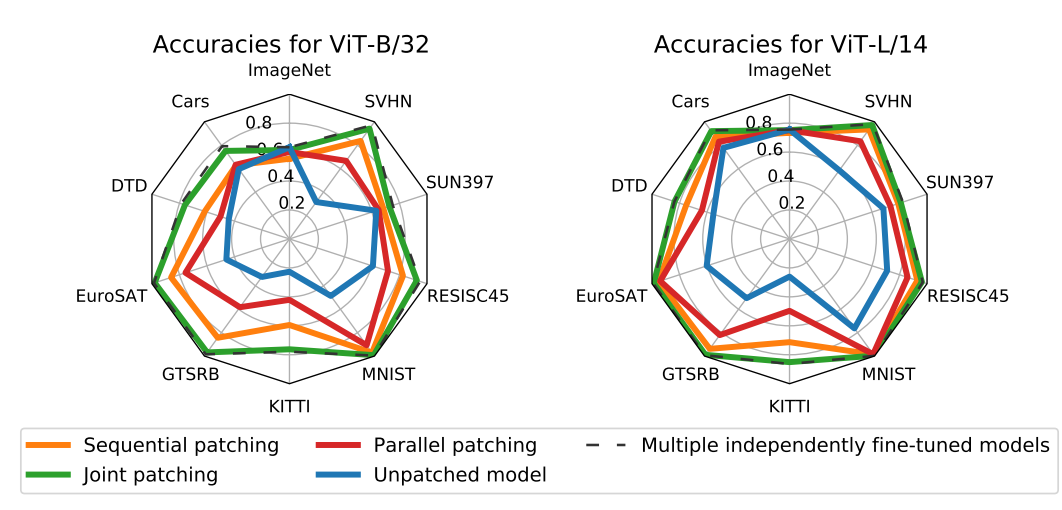
- Joint Patching:ファインチューニングする複数タスクのデータ$\mathcal{D}_{patch}^{(i)}$を、全て1つのデータセット$\mathcal{D}_{patch}$としてまとめた場合
- Sequential patching: 順繰りに補間していく方法
- タスク1 vs ゼロショット で補間 → パッチ1
- タスク2 vs パッチ1 で補間 → パッチ2
- Parallel patching: 別個にファインチューニングのモデル$\theta_{ft}^{(1)}\cdots\theta_{ft}^{(k)}$を作る。それからミックスするための係数$\alpha_i$を探す(以下の式参照)
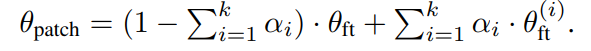
実験の設定
- ゼロショットモデルとタスクに特化したモデルとの間の精度差に基づき、タスクをパッチングタスクとサポートタスクに分類
- 線形プローブ(linear probe)がゼロショットモデルより10%ポイント以上優れているタスクをパッチタスクに分類
- 「末尾のロジスティック回帰だけいじったら精度が伸びるデータセットをパッチにしましたよ」ということ
- 具体的には、Cars、DTD、EuroSAT、GTSRB、KITTI、MNIST、RESISC45、SUN397、SVHN
- 線形プローブ(linear probe)がゼロショットモデルより10%ポイント以上優れているタスクをパッチタスクに分類
- 使ったモデルはCLIPのViT-L-14
結果
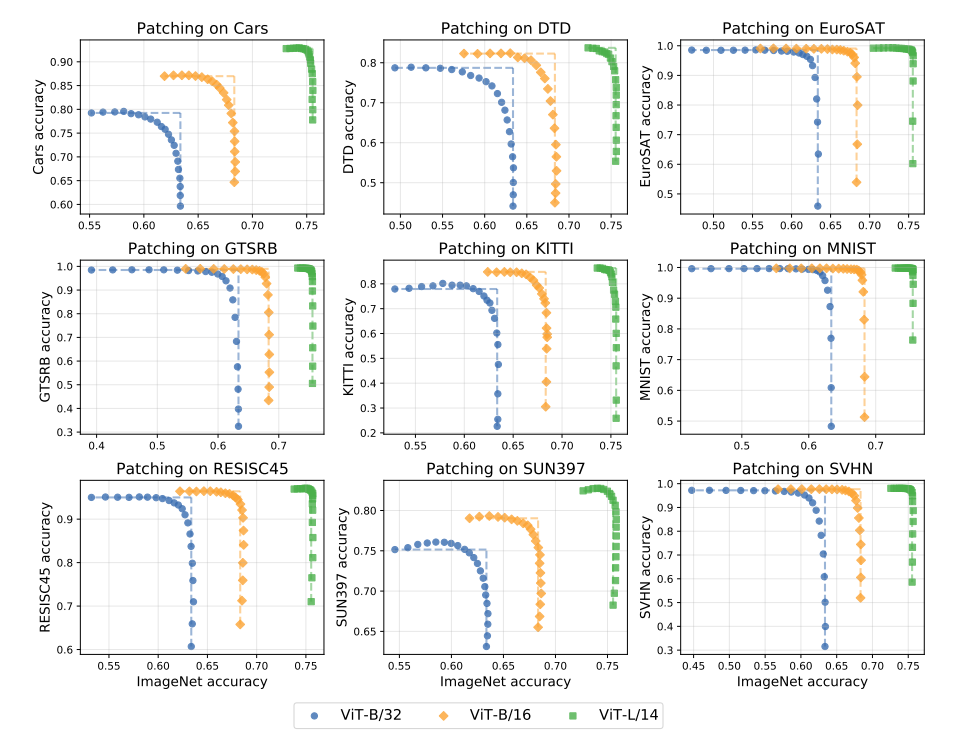
- パッチングタスクの精度(縦軸)とImageNetの精度(横軸)はトレードオフ
- ViT-L/14のような大きいモデルのほうが、完全にファインチューニングしてもImageNetの精度低下は低い(モデルのキャパが大きい)
サポートタスクがImageNet以外、パッチングタスクを9種の精度平均にしても同様のトレードオフ関係があり、PAINTの一貫性を示していると主張
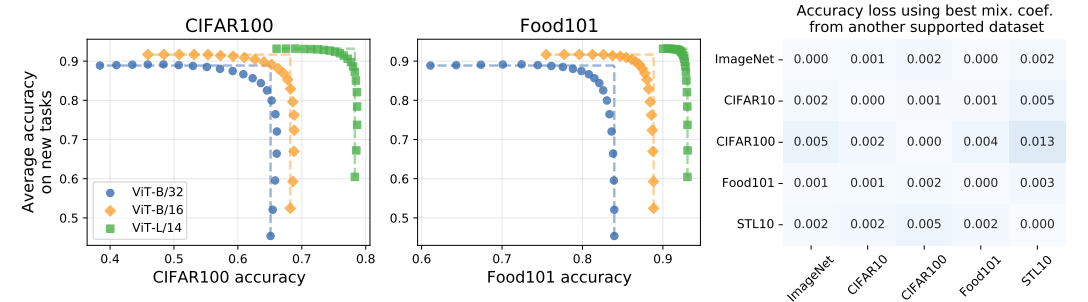
複数タスクのパッチングは、精度がJoint Patching>Sequential patching>Parallel patching。パッチングタスクを全部まとめて1つのデータセットにするのが一番良い
応用
ブロードトランスファー
- タスクAとタスクBが同じクラスを共有していない場合でも、タスクAでモデルをパッチすることにより、タスクBの精度を向上させることができる
- PAINTが未知のクラスに対しても効果がある
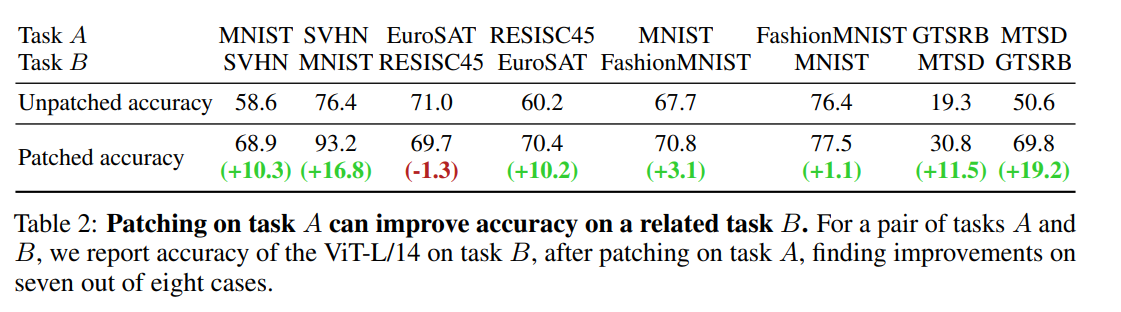
- MNISTとSVHNは、クラスを共有する数字認識タスク
- EuroSATとRESISC45は、クラスを共有していないが一部かぶる衛星画像認識タスク
- GTSRBとMTSDは、クラスを共有していないが一部かぶる交通信号認識データ
- MNISTとFashionMNISTは、クラスを共有していないが見た目は似ている
完全にクラスが一致しなくても、周辺タスクのデータを持ってきてPAINTすれば、精度向上に寄与する
タイポグラフィ攻撃
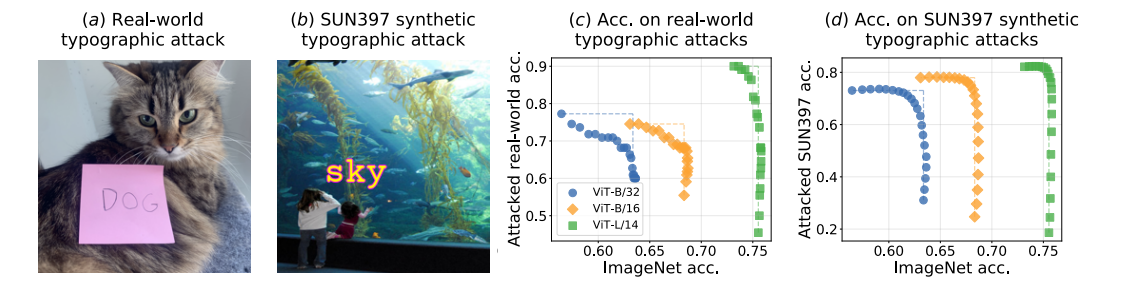
- 実世界のタイポグラフィ攻撃は(a)のような状態
- CLIPはこれを「犬」と誤認する
- SUN397に対して、「水族館の水に対してsky」とテキストを入れるような、機械的に合成したタイポグラフィ対策のデータを作る
- これでファインチューニングしたモデルを作り、PAINTで係数を補間すると、実世界・合成いずれものタイポグラフィ攻撃に対して頑強性のあるモデルができる
モデルの外挿・内挿
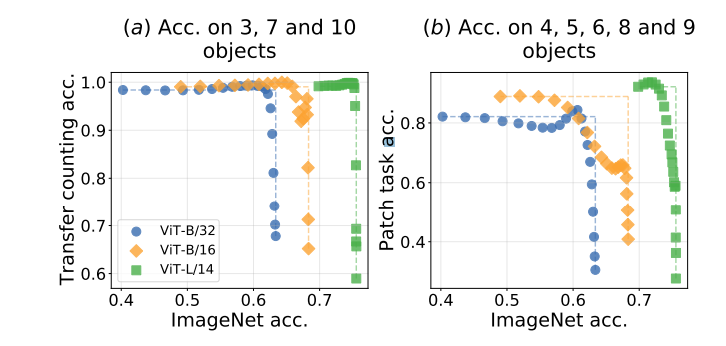
- CLEVRという物体の数を数えるタスク。CLIPは数を数えるのが難しいことが報告されている
- 以下のように、テストと訓練のカテゴリを変えても、外挿・内挿ができている
- PAINTで補間すると、ImageNet性能のようなサポートタスクとの汎化性能を両立できる

限界
- モデルが小さい場合、サポートタスクの精度がまだ低下することがある
- どのデータセットが効率的にパッチングに機能するか、という性能変化を保証できない
まとめと感想
- ニューラルネットワークの係数補間という、古くからあるであろう手法をオープンボキャブラリーモデルに適用した研究
- 一瞬当たり前のように見えたが、タイポグラフィ攻撃への対策、外挿・内挿、未知のクラスへの適用など意外と深い内容だった
- オープンボキャブラリーモデルの特性を維持するための線形補間で、個人的には従来の係数の線形補間よりかは一歩踏み込んだ内容に思えた
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー
One Comment