
論文まとめ:RTMPose: Real-Time Multi-Person Pose Estimation based on MMPose
Posted On 2023-10-05


- タイトル:RTMPose: Real-Time Multi-Person Pose Estimation based on MMPose
- 著者:Tao Jiang, Peng Lu, Li Zhang, Ningsheng Ma, Rui Han, Chengqi Lyu, Yining Li, Kai Chen
- URL:https://arxiv.org/abs/2303.07399
- コード:https://github.com/open-mmlab/mmpose/tree/1.x/projects/rtmpose
目次
ざっくりいうと
- MMPoseベースのポーズ推定の研究。様々なモデルが公開されている
- トップダウンのアプローチで、改良したSimCCを使い、xy座標単位での分類問題を解きローカリゼーションとする
- 学習戦略の改良で大きく精度を改善し、モバイル環境でもリアルタイム可能
イントロ
- ポーズ推定におけるアプローチはトップダウン / ボトムアップがある
- トップダウン
- 画像 → 人物検出 → キーポイント推定
- ボトムアップ
- 画像 → キーポイント推定 → 人物単位でグルーピング
- https://book.st-hakky.com/docs/difference-of-top-down-and-bottom-up-method/
- トップダウン
- トップダウンのデメリットは推論速度の遅さだが、検出器の優れたリアルタイム性でボトルネックにはならなくなった
- RTMPoseはすべてのインスタンスに対し、複数のフォワードパスをリアルタイムで実行可能
- 小さな入力解像度でもできる。提案手法は6人以下の場合はボトムアップより高速かつ正確だった
- ボトムアップ
- メリット:人数が増加しても計算コストが一定なので、群衆では有利
- デメリット:大きな入力解像度が必要で、精度と推論速度の両立が困難
- RTMPoseのバックボーンはCSPNeXt。物体検出用の設計。画像分類用のバックボーンは視線推定やセグメンテーションのようなDenseタスクには向いていない
- 速度と精度のバランスがよく展開が速い
- RTMPoseのキーポイントローカライゼーションの分類タスクとしてSimCCを使用
- 2つのFC層なシンプルな構造。様々なバックエンドに適用可能
- この活用がポイント
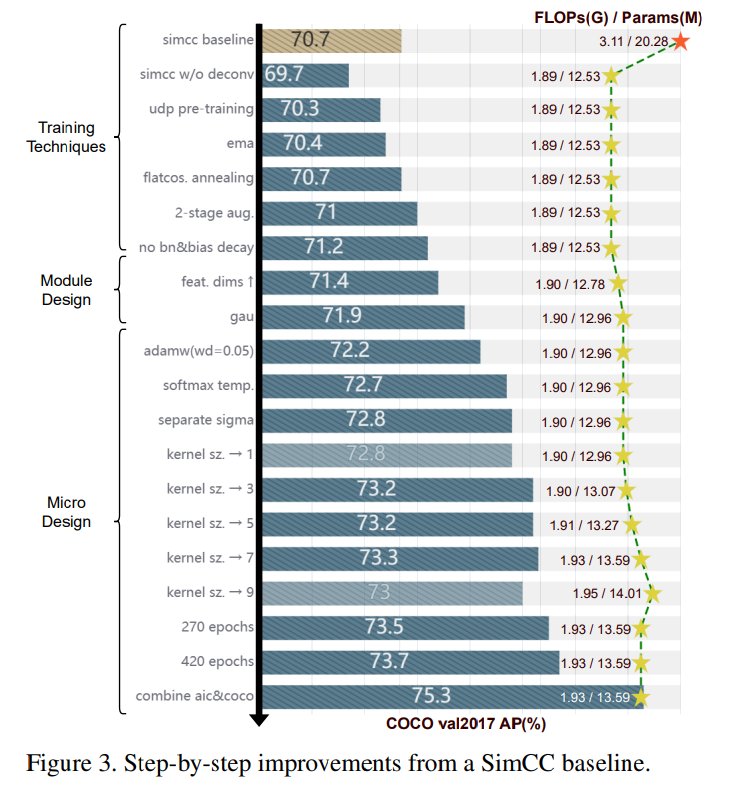
- 学習戦略の改善をしたら精度が大きく向上した
- 推論パイプラインの最適化
- スキップフレーム検出戦略による遅延の低減
- ポーズNMSとスムージングフィルタによるポーズ処理の改善
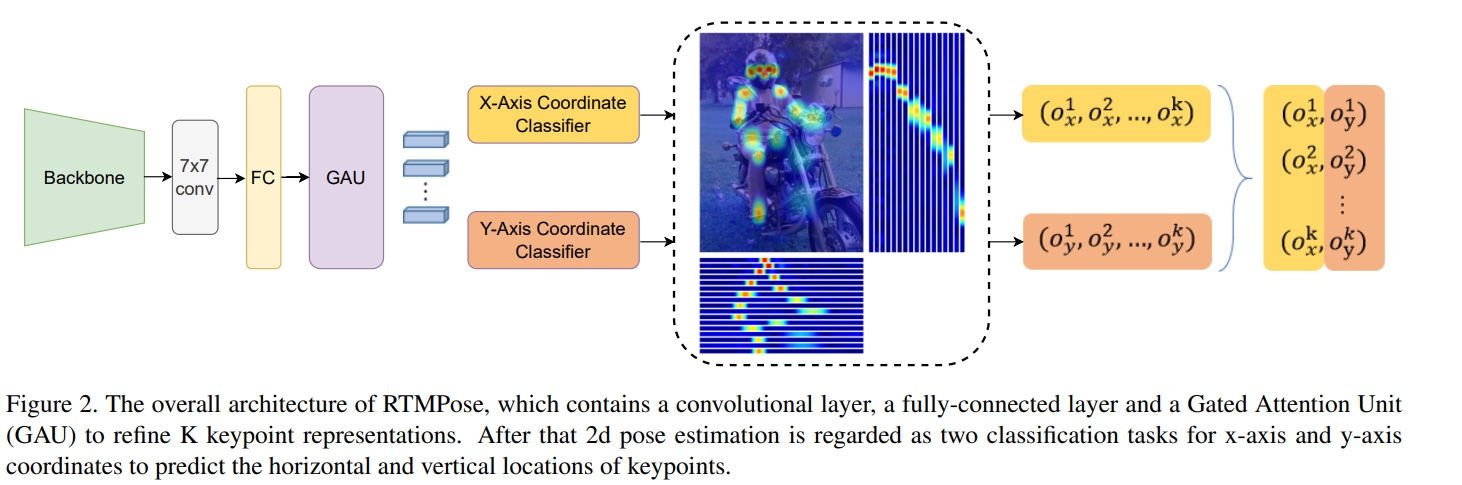
手法
SimCC
既存手法
- これまでのポーズ推定は、キーポイントの座標回帰やヒートマップ回帰だった
- SimCCは垂直座標と水平座標のサビピクセルのbin(例:ヒストグラムのような量子化)からの分類問題
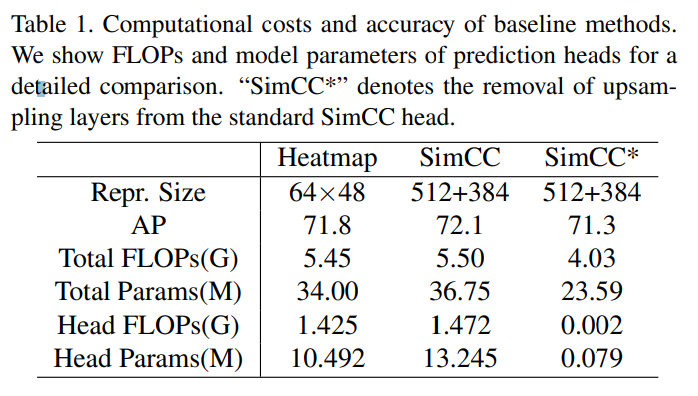
- 高解像度なヒートマップに依存しないため、高解像度な中間表現や高価なアップスケーリングが不要
- Global poolingを使わず、最終層をFlattenするため空間情報を損なわない
- 量子化誤差を使うことで、余分な後処理を減らせる
提案手法の工夫:SimCCからアップサンプリング層を消して軽量化・高速化した(SimCC*)
学習戦略の改良
ベースラインからいろいろ変えたらめちゃくちゃ性能上がった
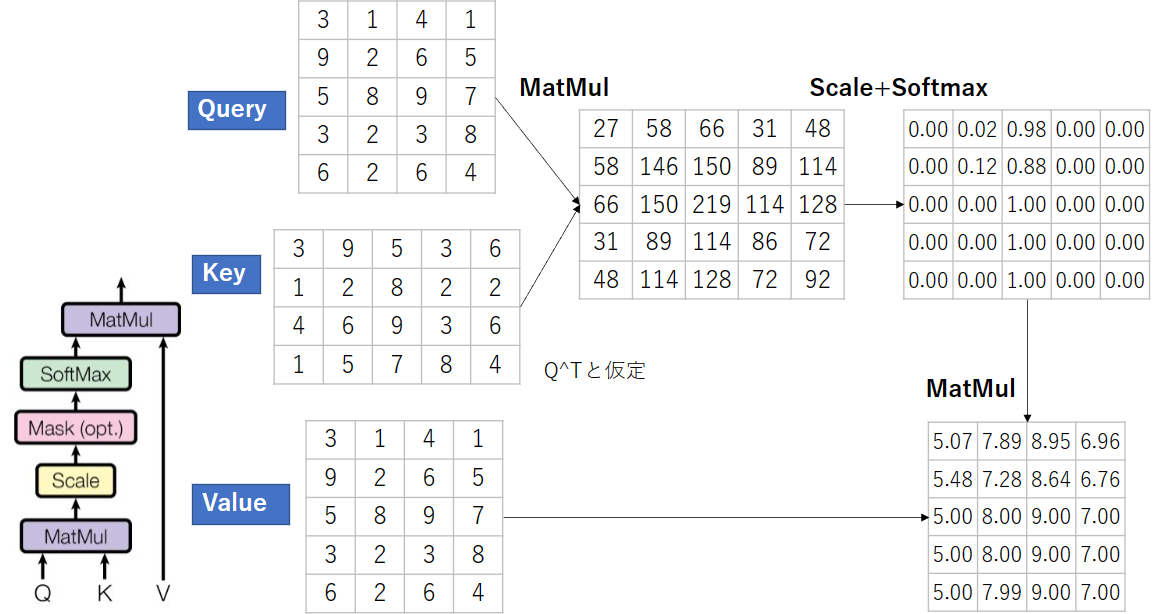
Gated Attention Unit
バックボーンからx, y座標単位の分類で使用(めっちゃ凝ったAttentionと考えればよさそう)

Attentionとは
損失関数の工夫
SORDに提案されているソフトラベルエンコーディングの損失関数を使用。


$\phi(r_t, r_i)$は真の距離値からどれだけ離れているかのペナルティ。空間的な距離(量子化されたヒートマップ)の回帰だけでなく、クラス間の距離も考える(5)
結果
性能
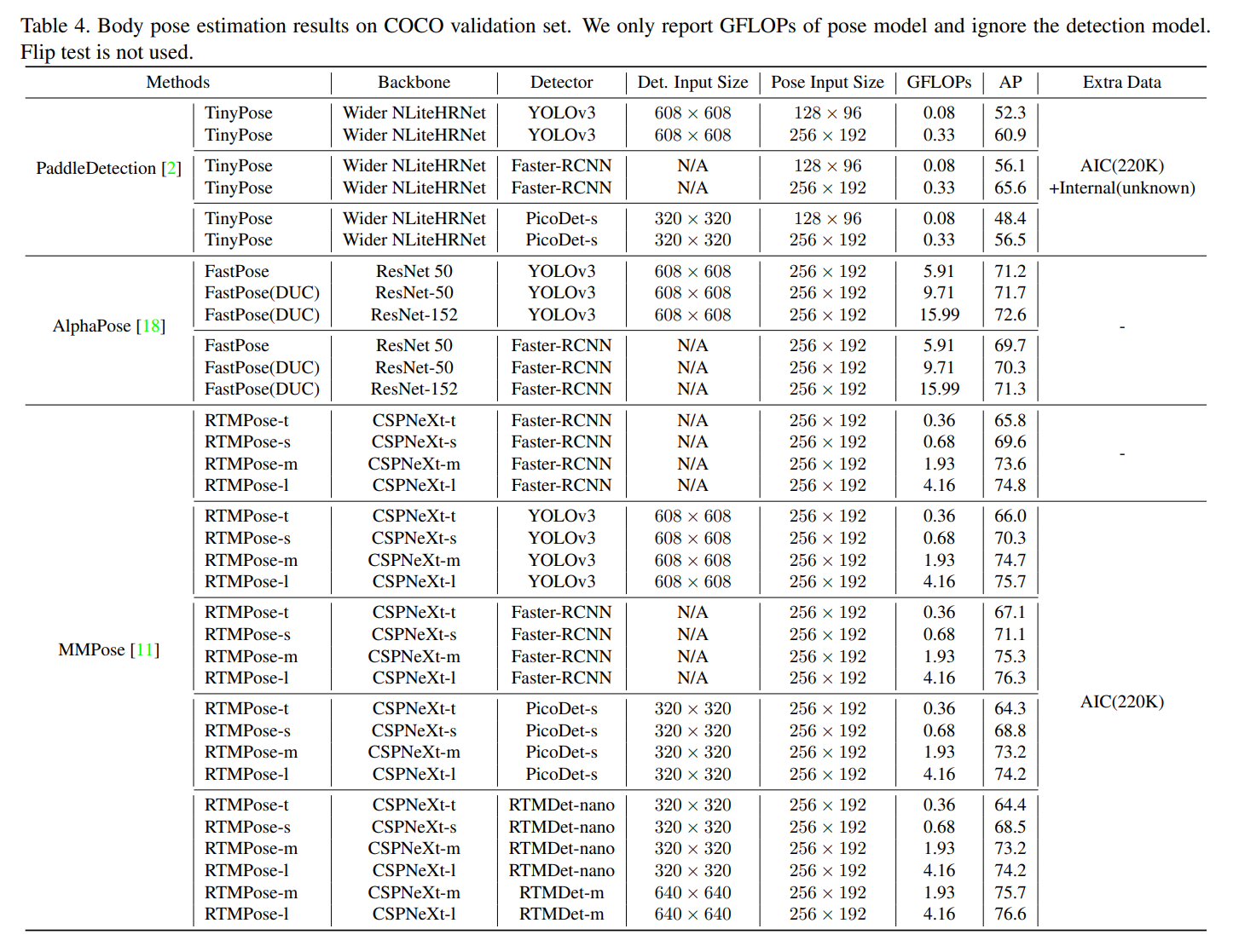
速度
Snapdragon 865というモバイルのCPU(Antutu60-70万でかなりハイエンドなCPU)
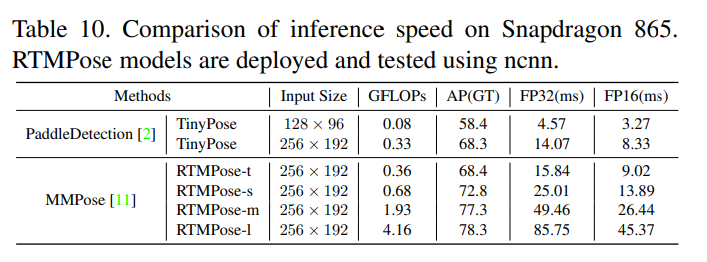
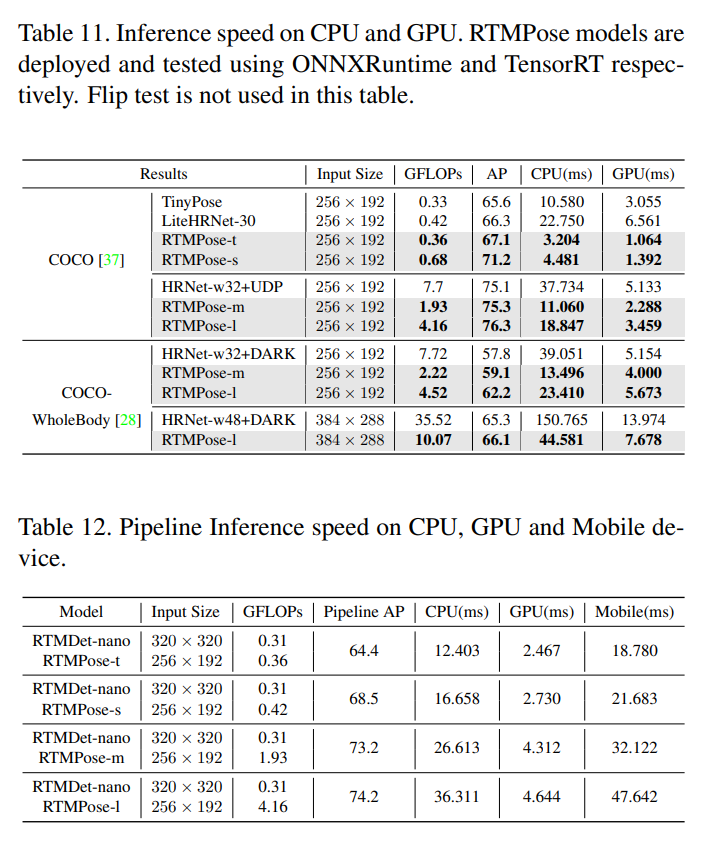
CPUはONNXRuntime(i7-11700)、GPUはTensorRT(1660TiのFP16)で測定。
その他
- MMPoseの中の一つでモデルが多く公開されている
- 一般的なモデル(全身、顔)のほか、手のトラッキングモデルや動物のキーポイント検出モデルもある
- ONNXに変換されたモデルも公開されている
- Mediapipeで公開されているポーズ推定のモデルは、MobileNetV2ベースとBlazePoseなので、こっちのほうが新しそう
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー