
論文まとめ:Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction


- タイトル:Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction
- 著者:Keyu Tian, Yi Jiang, Zehuan Yuan, Bingyue Peng, Liwei Wang
- 論文URL:https://arxiv.org/abs/2404.02905
- GitHub:https://github.com/FoundationVision/VAR (MIT)
- カンファ:NeurIPS 2024(Best paper)
目次
3行で要約
- 従来のARベースの画像生成が抱える高い計算コストと双方向依存関係の欠如を、「次スケール予測」によって解決。
- 粗い解像度から徐々に高解像度へ生成するマルチスケール構造で、O(n^4)の計算量と拡散モデルに匹敵する画質を両立。
- In/Out-paintingやクラス編集など多彩な応用でも、ゼロショット汎化能力とスケーリング則を実証。
論文要約 By Gemini 1.5 Pro
この論文の内容について、以下のように一問一答で答えます。
1. この論文において解決したい課題は何?
従来の画像生成における自己回帰モデルは、画素またはトークンをラスタースキャン順に予測するため、計算コストが高く、生成品質も拡散モデルに劣っていました。この論文では、高品質な画像を高速に生成できる自己回帰モデルを実現することを目指しています。
2. 先行研究だとどういう点が課題だった?
先行研究の自己回帰モデルは、2次元画像を1次元トークン列に平坦化してラスタースキャン順に予測するため、以下の課題がありました。
* 自己回帰モデルの前提となる単方向の依存関係が、画像の双方向の依存関係と矛盾する。
* 空間的な局所性が失われる。
* 計算コストが非常に高い(O(n^6))。
* 拡散モデルと比べて生成品質が低い。
3. 先行研究と比較したとき、提案手法の独自性や貢献は何?
提案手法であるVisual Autoregressive (VAR) は、「次スケール予測」という新しいパラダイムを導入することで、従来の「次トークン予測」とは異なるアプローチをとっています。画像を粗い解像度から細かい解像度へと段階的に生成することで、空間的な局所性を保持し、計算コストを削減(O(n^4))し、高品質な画像生成を実現しています。また、大規模言語モデルで観察されるスケーリング則とゼロショット汎化能力を、画像生成においても初めて実証しました。
4. 提案手法の手法を初心者でもわかるように詳細に説明して
VARは、二段階の学習プロセスからなります。
- 第一段階:マルチスケールVQVAEの学習
入力画像をエンコーダで特徴マップに変換し、それを複数の解像度のトークンマップに量子化します。その後、デコーダで画像を再構成し、入力画像との差を最小化するように学習します。 - 第二段階:VAR Transformerの学習
第一段階で得られたマルチスケールトークンマップを、粗い解像度から順に自己回帰的に予測するようにTransformerを学習します。各スケールのトークンマップは、それ以前のスケールのトークンマップを条件として並列に生成されます。
5. 提案手法の有効性をどのように定量・定性評価した?
- 定量評価: ImageNet 256×256および512×512データセットを用いて、FID、IS、Precision、Recallなどの指標で評価し、先行研究の自己回帰モデルや拡散モデルと比較しました。また、モデルのパラメータ数や学習計算量に対するスケーリング則を検証しました。
- 定性評価: 生成された画像サンプルを視覚的に比較することで、画質の向上を確認しました。また、in-painting、out-painting、クラス条件付き編集などのタスクでゼロショット汎化能力を評価しました。
6. この論文における限界は?
この論文では、VQVAEのアーキテクチャや学習方法は先行研究から変更していません。そのため、VQVAEの改良は今後の課題として残されています。また、テキストプロンプトによる生成はまだ実装されていません。
7. 次に読むべき論文は?
- VQVAEの改良に関する論文 [99, 59, 95]
- 拡散モデルに関する論文 [63, 3]
- 自己回帰モデルのスケーリング則に関する論文 [43, 35]
コード:
提示されているコードへのリンクは以下です。
https://github.com/FoundationVision/VAR

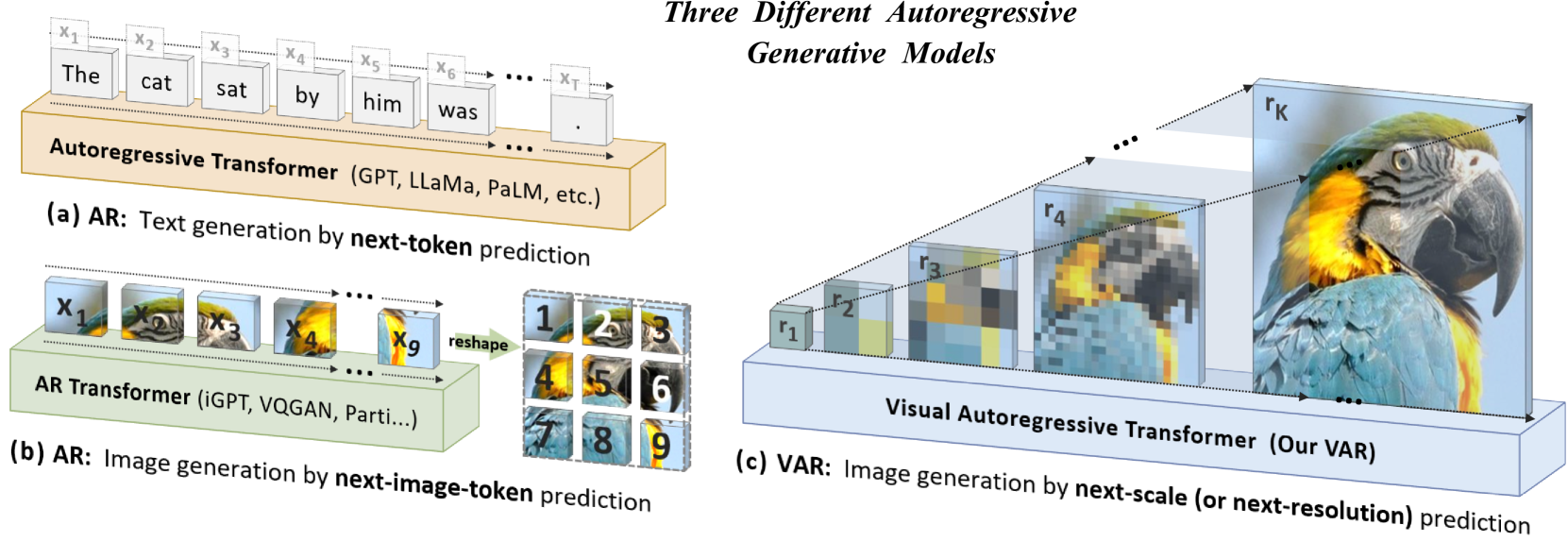
- GPTのようなNext Token Predictionを画像生成に導入したい
- これは従来だと自己回帰(AR)で、パッチ分割により画像をトークン化していた。しかし、画像ってもっと解像度に対して構造的なもの
- そこで「Next Scale(Resolution)Prediction」というパラダイムを導入する
- 拡散モデルベースよりも良いことがわかった。スケーリング則とゼロショット性を検証した
なぜNext Token Predictionではダメなのか?
- そもそも数学的におかしい。VQ-VAEはトークン列に対して双方向の相関を保持している。自己回帰モデルの一方向依存性と矛盾
- ゼロショット汎化できない:双方向推論を必要性により、一般化可能性が制限される。例えば、画像の下の部分が与えられると、上の部分が予測できない
- トークン列はパッチをフラットニングしたもののため、xy方向の近傍の相関関係が破壊される
- O(n^6)の計算量で効率が悪い
Next Scale Prediction

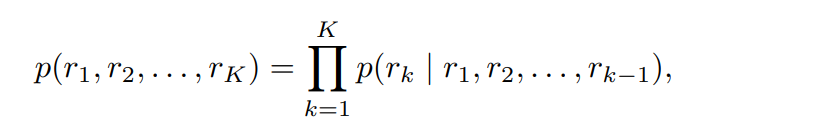
- 解像度で分けちゃえば自己回帰の一方向依存性は満たされる
- ゼロショット汎化もできる
- 近傍相関も破壊されない
- O(n^4)まで減らせる
モデル構造
- VAR Tokenizer
- VA-VQEを使う
- Transformer
- GPT-2やVQGANによく似た標準的になDecoderオンリーのモデルを使用
- AdaLNは使い、クラスつき条件生成ではクラスの埋め込みを開始トークンとして使い、AdaLNでも使用
- LLMでよく使われている、回転位置埋め込み(RoPE)、SwiGLU MLP、RMS Normなどの高度な技術は使用しない
証明


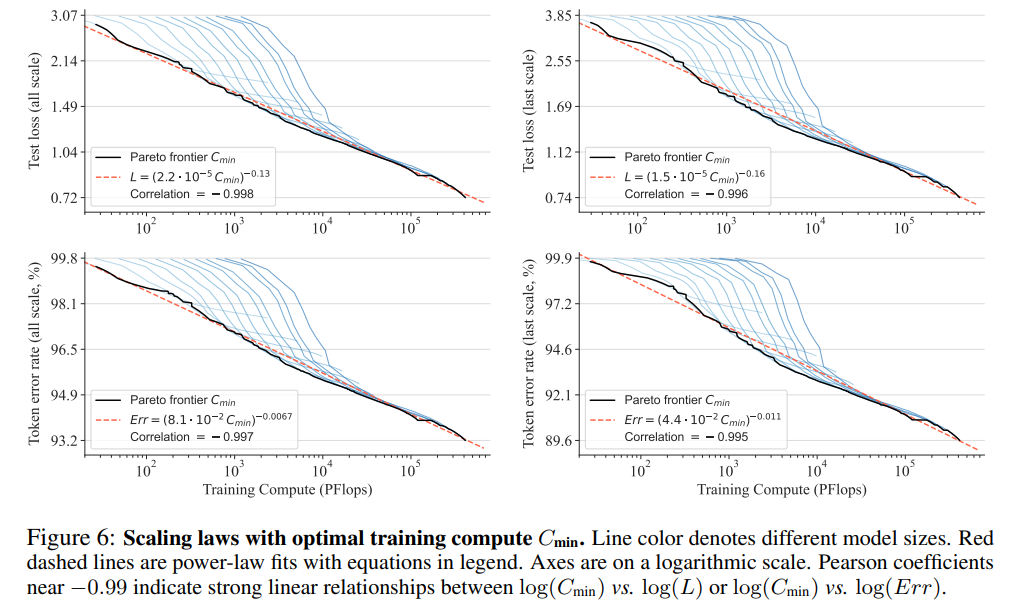
結果
モデルが大きくなったときに計算速度が速い

スケーリング則も確認できる
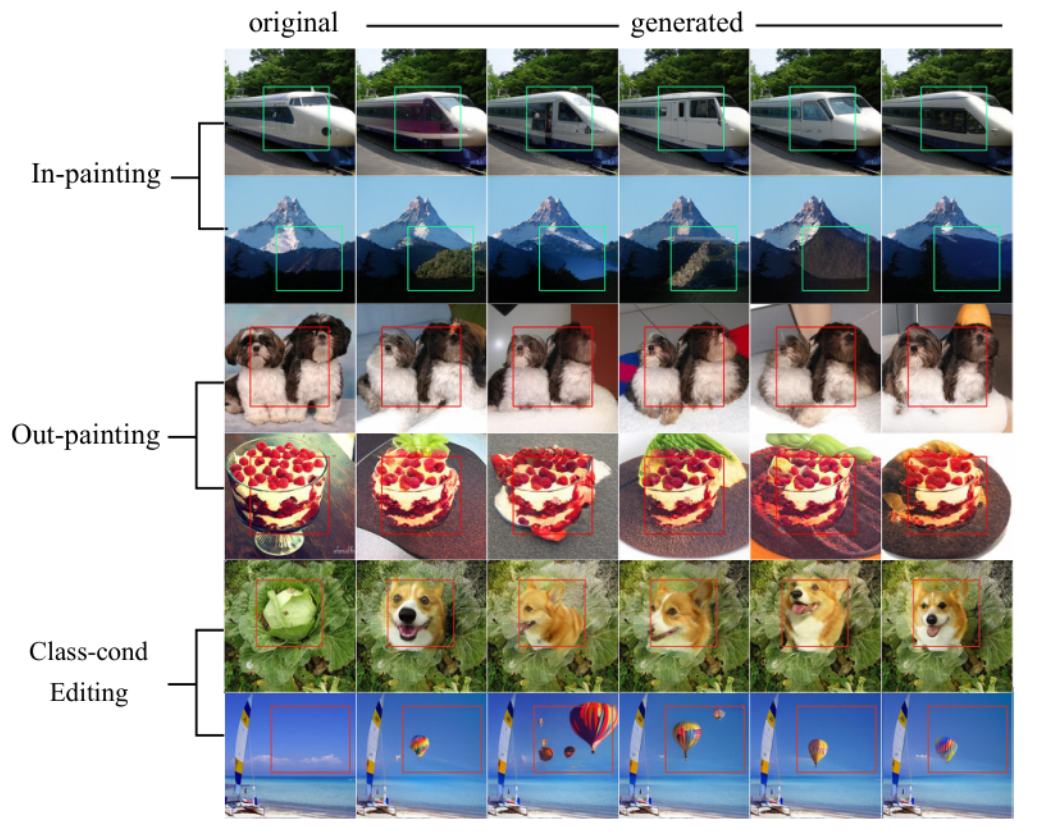
ゼロショット汎化は下流タスクへの汎化で確認。画像生成モデルで訓練してIn-painting / Out-painting / Class-cond Editingが可能。
所感
- すごい!
- 動画に拡張するならxytの相関、3Dに拡張するならxyzの相関がいるのでどうするのだろう?
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー