
KerasのLearningRateSchedulerを使って学習率を途中で変化させる


ディープラーニングで学習が進んだあとに学習率を下げたいときがときどきあります。Kerasでは学習率を減衰(Learning rate decay)させるだけではなく、epoch数に応じて任意の学習率を適用するLearningRateSchedulerという便利なクラスがあります。これを見ていきましょう。
目次
学習率変化なし
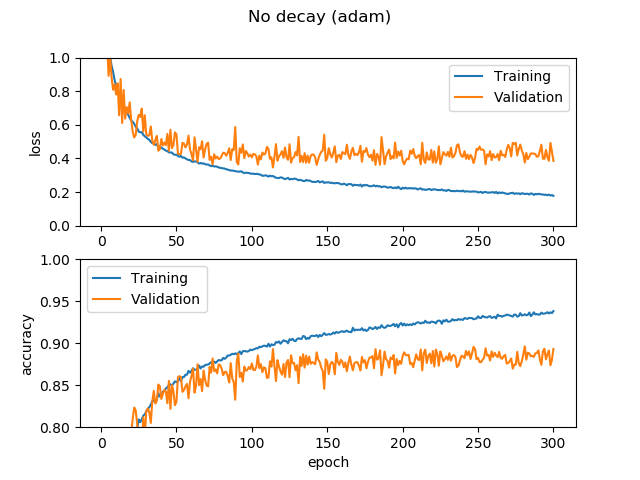
10層のCNNでCIFAR-10で検証精度90%を達成したコードを使い回しします。これは学習率の変化がありません。Adamでずっとデフォルトの0.01の学習率を維持します。
学習の過程は次のように進みます。
任意の学習率減衰(SGD)
次に、DenseNetの論文で出てきたオプティマイザーはSGD(モメンタム)で、初期の学習率は0.1で、全体の50%のepochで学習率を1/10(0.01)に、全体の75%でさらに1/10(0.001)にするという減衰操作を行います。DenseNetの論文では、学習率が変わったタイミングで急に精度が上昇(損失が減少)するのが確認されていましたが、DenseNetは使わずとも同様の効果は確認できるのでしょうか。
コードは以下のようにします。先程のコードに追加します。
from keras.optimizers import Adam, SGD
from keras.callbacks import LearningRateScheduler
# 学習率
def step_decay(epoch):
x = 0.1
if epoch >= 150: x = 0.01
if epoch >= 225: x = 0.001
return x
lr_decay = LearningRateScheduler(step_decay)
# コンパイル
model.compile(optimizer=SGD(lr=0.1, momentum=0.9), loss="categorical_crossentropy", metrics=["accuracy"])
# フィット
datagen.fit(X_train)
validationgen.fit(X_val)
history = model.fit_generator(datagen.flow(X_train, y_train, batch_size=128),
steps_per_epoch=len(X_train) / 128, validation_data=validationgen.flow(X_val, y_val), epochs=300,
callbacks=[lr_decay]).history
訂正:225epoch目で学習率が変化しなかったので訂正しました。正しくはelifではなくifです。
150epochで学習率を0.01に、225epochで学習率を0.001にしました。step_decayの中身次第でいくらでも調整できます。Kerasとっても簡単。結果は次の通りです。
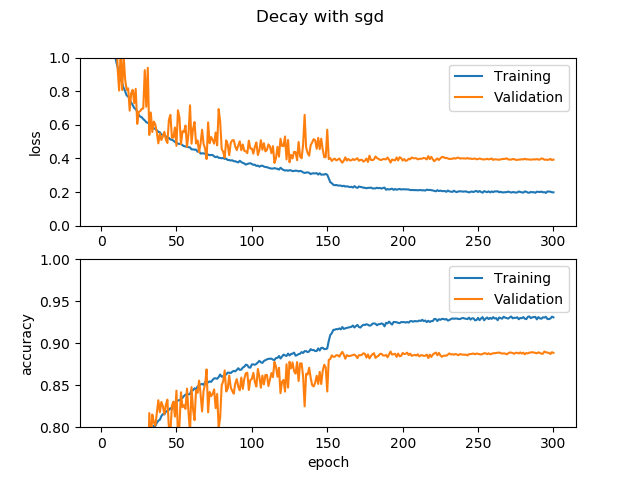
確かに学習率が0.01になった瞬間に論文ほどではないですが、かなり大きく精度が上がってますね。225epoch目はあまり効果がなさそうです。検証データに対して、瞬間的に高い精度を出したいか安定して高めの値を出したいかで好みがわかれそう。
Adamでも学習率減衰
Adamで同様のことをやった例です。SGDでは初期学習率が0.1で問題なかったのですが、Adamでこれだと大きすぎて発散してしまうので初期学習率は0.01としました。減衰させるタイミングは同様で、150epochで1/10に、225epochで1/100にします。
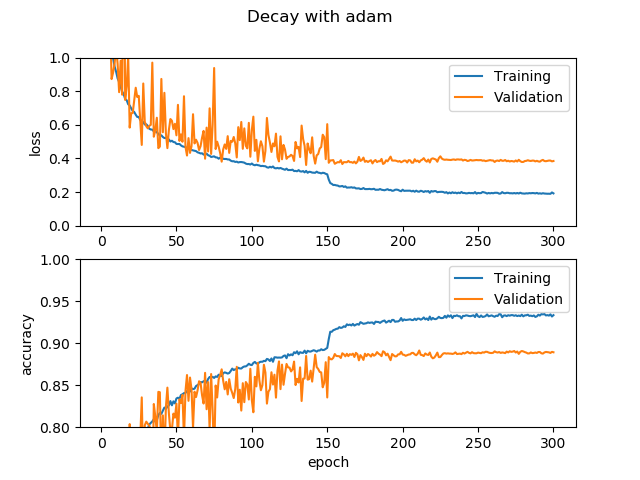
Adamでも似たような感じに。この場合、SGD(モメンタム)だからといって特に良いわけではないようです。Adamはモメンタム+RMSPropという高性能オプティマイザーなので、これだったら自分は特に理由がない限りAdamを使います。以上です!
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー