
Windows11でWSL2+nvidia-dockerでPyTorchを動かすのがすごすぎた


Windows11にはWSL2があり、Linux環境からGPUありのPyTorchを動かすことが可能です。WSL2経由のほうがWindowsネイティブよりも訓練速度が倍になります。nvidia-dockerを使うと、CUDAのバージョンを気にすることなく、環境構築できます。
目次
やりたいこと
- Windows11に標準装備されたWSL2を使って、Linux環境からGPU利用ありのPyTorchを動かしたい。
- よくあるやり方(例えばこの記事)では、WSL側にCUDAとCuDNNをインストールしているが、これをやったところCUDAのセットアップ時に、前提ライブラリのインストールでドハマリし、うまくいかなかった
- GPUのランタイムはWindowsにインストールしたCUDAのみを使い、できるだけあとはnvidia-dockerに任せたい
よくあるやり方ではうまく行かず「もうWSL2でPyTorch動かすの無理かな」と諦めていたところ、nvidia-dockerを使う方法を試したら楽勝でできてしまったので、手順をメモしていきたいと思います。
自分はDocker素人でしたが、特にDockerの知識なくても行けると思います(ファイルコピーだけ最初は迷いました)。
参考情報
すべてNVIDIAのサイトにあります(英語)。「CUDA on WSL User Guide」では、TensorFlowのセットアップですが、PyTorchのDockerイメージも用意されており、それが2番目のリンクです。
最初は「CUDA on WSL User Guide」を追う形で進めます。
Dockerイメージについて
Pytorchのイメージは6.51GBとディープラーニングのDockerにしては比較的軽量で(展開しても10GB程度)、Kaggleのイメージを入れるよりはかなり容量が小さいかと思われます。
また、PyTorchのイメージはかなり頻繁に更新されており、本記事執筆時(2022/3/7)の最終更新は2/26でした。
PyTorchに限らずGPU利用できるディープラーニングのフレームワークは、フレームワークのバージョンに合わせてCUDA/CuDNNのバージョンも対応させる必要があります(ソフトウェアのビルドの関係)。GPUドライバののバージョンアップが、フレームワークの更新の大きな手間になることがしばしばあります。しかし、nvidia-dockerでは、GPUドライバはDockerイメージ側でやってくれるので、Dockerイメージの更新(「docker run」のバージョンだけ変える)だけですべて対応できます。これが非常に嬉しいポイントです。
また、各環境はあくまでDockerイメージなので、異なるCUDAのバージョン/異なるPyTorchのバージョンを1つのPCに共存させることが可能です。PyTorchではあまり問題になりませんが、バージョンの依存性の強いTensorFlowでは嬉しい仕様ではないでしょうか。ここでは書きませんが、「CUDA on WSL User Guide」では、TensorFlowのセットアップもあります。
GPUドライバのインストール
こちらのページから「Get CUDA Driver」をクリックし、インストールします。
https://developer.nvidia.com/cuda/wsl
ここでのオペレーティングシステムは、WSLを使う場合でもWindowsにしましょう。WSL関係なく普通にGPUドライバをインストールする場合と同じです。インストール済みの場合でも更新しておくといいでしょう。
WSL2の開始
スタートメニューから、「Windows PowerShell」もしくは「コマンドプロンプト」を開き、
wsl.exe --install
WSLをインストールしたのち、アップデートします。
wsl.exe --update
このアップデートをしないとPyTorchのイメージをdocker runしたときにエラーしたことがあるので、アップデートはしたほうが良いです。
wsl.exe
WSLを起動するとユーザー名・パスの設定を求められますが、適当に設定しましょう。
nvidia-docker2のインストール
Dockerをインストールします。以下の処理は場合によって「Permission Denied」と怒られることがありますが、その場合はsudoをつけてください。
curl https://get.docker.com | sh
リポジトリとGPGキーを設定します。
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
NVIDIAランタイムパッケージとその依存関係をインストールします。
sudo apt-get update
sudo apt-get install -y nvidia-docker2
WSL2の別のウィンドウを開き、Dockerデーモンを再起動します。
sudo service docker stop
sudo service docker start
PyTorchのDockerイメージのインストール
次のコマンドの「xx.xx」を適切なバージョンに置き換えて実行するだけで、インストールから起動まで完了します。
docker run --gpus all -it --rm --shm-size=8g nvcr.io/nvidia/pytorch:XX.XX-py3
https://catalog.ngc.nvidia.com/orgs/nvidia/containers/pytorch
バージョン番号は、こちらのページを参考にしてください。バージョンはLinuxのOSバージョンとは関係なく、Dockerのイメージのバージョンです。
また公式ドキュメントでは、–shm-sizeの指定はありませんが、デフォルトではShard Memoryが64Mしかなく、「DataLoader worker (pid xxx) is killed by signal: Bus error. 」というエラーで怒られるので、Shared Memoryの拡張を推奨です。この例では8GBにしていますが、PCの性能に応じて調整してください。
インストールが終わるとこのような画面がでるはずです。
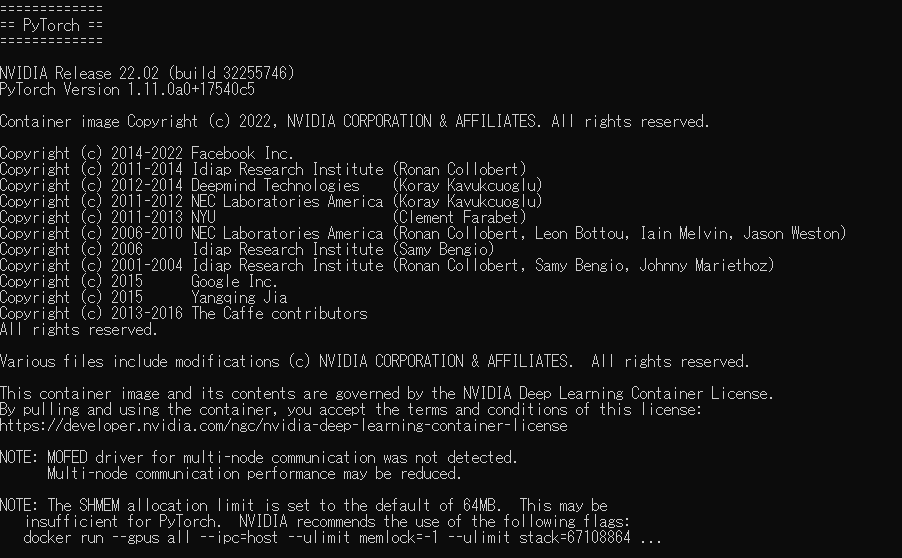
PyTorchのバージョンは1.11.0aでした。かなり最新のバージョンがインストールされているようです(PyTorchの公式では安定版が1.10.2)。
環境を確認する
ここの実行は任意です。nvidia-smiを実行します。
nvidia-smi
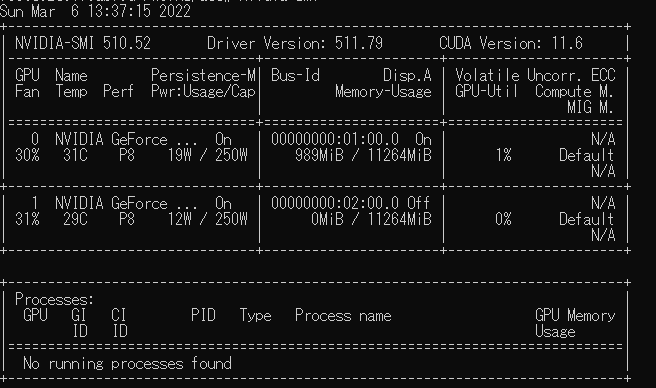
このようにGPUが認識されているのがわかります。
PyTorchから認識しているGPUの数を数えましょう。Pythonを起動します。
Python 3.8.12 | packaged by conda-forge | (default, Oct 12 2021, 21:59:51)
[GCC 9.4.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import torch
>>> print(torch.cuda.is_available())
True
>>> print(torch.cuda.device_count())
2
このように実行していきます。import以下は、「GPUが利用できるか」「GPUの数」を表します。GPUの数は利用しているPCによって異なります。
ファイルコピー
Windowsで開発して、WSL2内で起動しているndivia-docer内にファイルをコピーしたい(あるいはその逆)というケースは少なからずあります。
結論から言うとこれは可能です。こちらの記事を参考にしてください。
今いる環境がどれなのかわからなくなるケースがあります。コマンドラインが、
- 「ユーザー名@PC名」:ホスト側のコマンドライン
- 「root@82c8175abf0d:/workspace#」:コンテナ側のコマンドライン
となっています。rootの@以下は、イメージのIDを示します。ホスト側のコマンドラインが表示されないときは、WindowsのスタートメニューからUbuntuを開くとホスト側のコマンドラインが起動します。
ホスト側から、コンテナIDを確認するには、
sudo docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
82c8175abf0d nvcr.io/nvidia/pytorch:22.02-py3 "/opt/nvidia/nvidia_…" 20 hours ago Up 20 hours 6006/tcp, 8888/tcp interesting_austin
コンテナIDの「82c8175abf0d」が一致しているのがわかります。
Windows→コンテナ間へのコピー
ホスト側のコマンドラインでLinuxコマンドでコピーすることを想定します。
WindowsのGドライブ直下にshinano.txtというファイルがあったとします。これをホスト側のコマンドラインで表示するには次のようにします。
~$ cat /mnt/g/shinano.txt
信濃の国は十州に
境連ぬる国にして
聲ゆる山はいや高く
流るる川はいや遠し
松本伊那佐久善光寺
四つの平は肥沃の地
海こそなけれ物さわに
万ず足らわぬ事ぞなき
Windows11のWSL2の場合、Windows側のドライブは勝手にマウントされ、「/mnt/ドライブ名」でホスト側のプロセスから表示できます。
一方でコンテナ側のパスは、コンテナ側で表示されているコンテナID(root@82c8175abf0dなら「82c8175abf0d」)を使い、「82c8175abf0d:/workspace」のように表記します。
例えば、Windows直下の「G:/shinano.txt」をコンテナの「/content」直下にコピーしたい場合は、
sudo docker cp /mnt/g/shinano.txt <コンテナID>:/workspace/shinano.txt
このケースではコンテナIDは「82c8175abf0d」なので、
sudo docker cp /mnt/g/shinano.txt 82c8175abf0d:/workspace/shinano.txt
とします。
実際に、コンテナ側のコマンドラインでディレクトリを表示すると、
root@82c8175abf0d:/workspace# ls
NVIDIA_Deep_Learning_Container_License.pdf README.md data docker-examples examples shinano.txt tutorials
「shinano.txt」がコピーされているのがわかります。
コンテナ→Windowsのコピー
コンテナからWindowsのコピーを想定してみましょう。今は例として、コンテナ側でインターネットからファイルをDLし、Windowsにコピーしてみます。
wget https://www.pref.nagano.lg.jp/koho/kensei/gaiyo/shoukai/documents/shinano-japanese.mp3
実際に「ls」で確認すると、
root@82c8175abf0d:/workspace# ls
NVIDIA_Deep_Learning_Container_License.pdf data examples shinano.txt
README.md docker-examples shinano-japanese.mp3 tutorials
「shinano-japanese.mp3」がダウンロードされているのがわかります。これをWindowsにコピーするには、
ホスト側操作の場合、
sudo docker cp 82c8175abf0d:/workspace/shinano-japanese.mp3 /mnt/g/shinano-japanese.mp3
Gドライブにコピーされている「shinano-japanese.mp3」を再生すると信濃の国が流れると思います。
コンテナ側操作の場合は、DockerイメージにDockerがインストールされていないと怒られてしまいました。多分インストールすればできると思います(丸投げ)
実行速度比較
PyTorchの実行はWindowsからもできますが、WSL2のUbuntuの大きな美味しいメリットとして、Windows経由よりも格段に訓練速度が速くなるというのがあります。
ResNet50でCIFAR-10を30エポック訓練してみます。環境は以下の通りです。
- GPU:RTX 2080Ti(GPUは1枚で訓練)
- メモリ:64GB
- CPU:Core i9-9900K
- OS:Windows 11 Pro
- Windows側のPyTorchのバージョン:’1.10.1+cu113′
- nvidia-docker側のPyTorchのバージョン:’1.11.0a0+17540c5′
- IOの条件を揃えるために、システムドライブで検証
- nvidia-dockerには、コンテナ側のコマンドで「pip install pytorch-lightning」のみ追加インストール
- Windowsもコマンドプロンプトから実行
条件は以下の3つです。これらをWindows/WSL2のnvidia-dockerで訓練速度を比較します。
- 通常のPyTorchでResNet50を訓練
- PyTorch lightningのFP32でResNet50を訓練
- PyTorch lightningのMixed Precision(FP16)でResNet50を訓練
3はPyTorch lightningのTrainerに「precision=16」するだけです。Windows/WSL+nvidia-dockerで各3回試行しました。
結果
数字は秒です。最初はWindows+コマンドラインの場合
| 手法 | 1回目 | 2回目 | 3回目 | 平均 |
|---|---|---|---|---|
| PyTorch | 920.5 | 921.7 | 912.0 | 918.1 |
| Lightning | 1077.8 | 1081.3 | 1073.9 | 1077.7 |
| Lightning(Mixed) | 1014.9 | 1012.7 | 1013.2 | 1013.6 |
次はWindows11のWSL2+nvidia-dockerの場合です。
| 手法 | 1回目 | 2回目 | 3回目 | 平均 |
|---|---|---|---|---|
| PyTorch | 463.3 | 471.8 | 466.8 | 467.3 |
| Lightning | 498.6 | 503.2 | 522.1 | 508.0 |
| Lightning(Mixed) | 446.6 | 430.9 | 446.1 | 441.2 |
WSL2のほうが総じて倍ぐらいの速度が出ていることがわかります。おそらくCUDAの計算がLinuxのほうが最適化かかっているのだと思われます。これはなかなか衝撃的な結果になりました。
コード
長いのでGistで
https://gist.github.com/koshian2/5dc8d01efe4f6db6eab948a067005ac2
まとめ
WSL2+nvidia-dockerはWin11で手軽に利用でき、訓練速度がWindowsネイティブよりも倍ぐらい速い
倍ぐらい速いというと、もはや1世代後のGPUを使っているのと同じぐらいなので、速度を求めるならぜひWSL2を使うべきだと思います。デバッグはGUIでやりやすいWindowsでやって、本番の訓練はWSL2がやりやすそうです。
少なくとも、Win11ならWSL2を手軽に利用できるので、Win10を持っている人は11に上げる理由はかなりあると思います。WSL2以外のGUIもそこまで変わらないです。
また、nvidia-dockerは機械学習に必要なライブラリがインストールされているので、Colab感覚で利用することは可能です。サンプル動かしてポイだとColabのほうが楽でしょうが、長時間訓練することを考えるとnvidia-dockerは選択肢としてはかなりありだと思います。Colabはいつ改悪されるかわからないですからね。
ぜひ使いこなしてみてください。
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー