
ごちうさで始める線画の自動着色(1)~データセットのEDA~


KaggleにあったGochiUsa_Facesデータセットを使って、ごちうさキャラの線画の自動着色で遊んでみました。この投稿では下準備として、データセットのEDAをします。
目次
GochiUsa_Facesデータセット
これなに?:ごちうさのキャラの顔画像を集めたもの。
https://www.kaggle.com/rignak/gochiusa-faces
全部で4万枚、サイズは16.12GB。Kaggleの画像データセットにしては比較的お手軽サイズ。
このデータセットのいいところは、もちろんキャラが可愛くて癒やしなこともあるのですが、画像解像度が高めの画像を多く集めているところ。小さい解像度のアニメ画像を集めたデータセットはあるが、そこそこ大きいサイズは見当たらない。ごちうさで完結しているのでキャラ数が限定的で、かつどのキャラの顔かアノテーションがついているところ。
今回から何個かの記事に分けて「GochiUsa Facesデータセット」で遊んでみます。
データセットの構造
ダウンロードすると3つのフォルダーと1つのPDFが出てきます。
- additional_dataset
- main_dataset
- test_dataset
- GochiUsa_Dataset.pdf
PDFではいろいろ面白い分析しています。
「main_dataset」と「test_dataset」が主要キャラ(9人)で、「additional_dataset」がサンプル数の少ないサブキャラクターの画像です。
今回は主要キャラのみ扱います。主要キャラのみ考えると「main_dataset」が訓練データ、「test_dataset」がテストデータとなります。
ただし、main_datasetとtest_datasetでデータソースが異なるようです。main_datasetはアニメのキャプチャ中心、test_datasetは(おそらく)ファンアートが中心です。ただし、PDFによると、主要キャラを画像分類すると、9割以上の精度が出たとのことです(後述)。今回はこのデータソースの差は無視しますが、ソースの差が問題になるケースで有効かもしれません。実践的ですね。

(a)がmain_dataset、(b)がtest_dataset、(c)がadditional_datasetです(画像はPDFより)。(a), (b)のキャラクターは、左から
- ブルーマウンテン
- チノ
- 千夜
- ココア
- マヤ
- メグ
- モカ
- リゼ
- シャロ
(c)のキャラクターは左から、
- あんこ(甘兎庵のオスうさぎ)
- 千夜の祖母
- ココアの母
- 凛(青山ブルーマウンテンの編集者)
- リゼの父
- サキ(チノの母親)
- タカヒロ(チノの父)
- ティッピー
- ユラ
データ数と解像度の関係
PDFより。画像の幅の分布です。
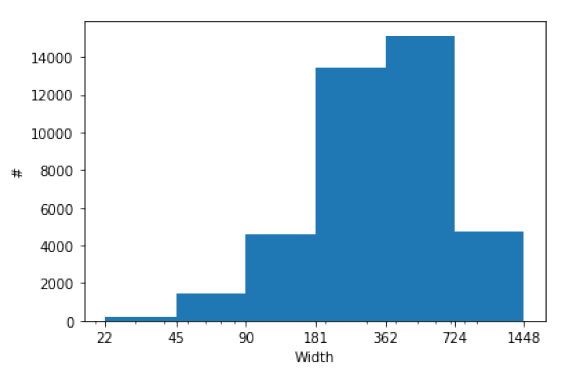
中央値が362ピクセル付近で、高解像度のサンプルが多め。
キャラごと、データセットごとに特定サイズ以上のサンプルが何枚あるか数えてみましょう。ここでの特定サイズとは「画像の幅の高さのうち小さい方の値が一定値以上か」で判定します。
from PIL import Image
import glob
import pandas as pd
def count_images(root_dir):
dirs = sorted(glob.glob(root_dir + "/*"))
characters = [d.replace("\\", "/").split("/")[-1] for d in dirs]
min_sizes = [0, 64, 128, 256, 320, 512]
df = pd.DataFrame(0, columns=min_sizes, index=characters)
for i, d in enumerate(dirs):
files = sorted(glob.glob(d + "/*"))
for f in files:
with Image.open(f) as img:
for j, min_image_size in enumerate(min_sizes):
if min(img.size) >= min_image_size:
df.iloc[i, j] += 1
return df
print(count_images("archive/main_dataset/main_dataset"))
main_dataset
| キャラ/サイズ | 0 | 64 | 128 | 256 | 320 | 512 |
|---|---|---|---|---|---|---|
| Blue Mountain | 1607 | 1553 | 1399 | 1133 | 939 | 623 |
| Chino | 12941 | 12707 | 11836 | 8900 | 7601 | 4098 |
| Chiya | 7283 | 7150 | 6793 | 5304 | 4500 | 2340 |
| Cocoa | 12223 | 12023 | 11334 | 8839 | 7479 | 3888 |
| Maya | 4747 | 4695 | 4440 | 3144 | 2574 | 1090 |
| Megumi | 4040 | 4005 | 3825 | 2732 | 2189 | 832 |
| Mocha | 1241 | 1220 | 1154 | 980 | 835 | 493 |
| Rize | 9052 | 8884 | 8307 | 6428 | 5425 | 2623 |
| Sharo | 6445 | 6344 | 5933 | 4509 | 3792 | 1888 |
| 小計 | 59579 | 58581 | 55021 | 41969 | 35334 | 17875 |
test_dataset
| キャラ/サイズ | 0 | 64 | 128 | 256 | 320 | 512 |
|---|---|---|---|---|---|---|
| Blue Mountain | 47 | 47 | 47 | 38 | 28 | 8 |
| Chino | 1525 | 1525 | 1522 | 1289 | 1026 | 401 |
| Chiya | 513 | 513 | 512 | 453 | 374 | 132 |
| Cocoa | 489 | 489 | 488 | 414 | 315 | 119 |
| Maya | 131 | 131 | 130 | 118 | 85 | 30 |
| Megumi | 93 | 93 | 92 | 83 | 73 | 26 |
| Mocha | 57 | 57 | 57 | 55 | 42 | 14 |
| Rize | 507 | 507 | 506 | 421 | 336 | 117 |
| Sharo | 534 | 534 | 534 | 419 | 299 | 111 |
| 小計 | 3896 | 3896 | 3888 | 3290 | 2578 | 958 |
mainとtestでそこまで大きくは解像度の分布は変わらないようです。
additional_dataset
| キャラ/サイズ | 0 | 64 | 128 | 256 | 320 | 512 |
|---|---|---|---|---|---|---|
| Anko | 13 | 11 | 10 | 9 | 8 | 2 |
| Anzu | 140 | 140 | 138 | 46 | 20 | 13 |
| Chiya’s Grandmother | 41 | 41 | 41 | 25 | 10 | 1 |
| Cocoa’s Mother | 266 | 266 | 263 | 200 | 180 | 103 |
| Kano | 170 | 170 | 165 | 88 | 64 | 10 |
| Karin | 84 | 84 | 82 | 38 | 15 | 0 |
| Mai | 196 | 196 | 191 | 116 | 108 | 60 |
| Miki | 78 | 78 | 75 | 21 | 15 | 10 |
| Nacchan | 133 | 133 | 122 | 67 | 29 | 17 |
| Rei | 147 | 146 | 139 | 66 | 42 | 17 |
| Rin | 439 | 433 | 422 | 323 | 271 | 123 |
| Rize’s Father | 88 | 85 | 84 | 41 | 33 | 22 |
| Saki | 156 | 146 | 113 | 77 | 66 | 32 |
| Takahiro | 682 | 679 | 629 | 274 | 110 | 28 |
| Tippy | 78 | 75 | 56 | 36 | 16 | 2 |
| Yura | 83 | 83 | 81 | 74 | 74 | 42 |
| 小計 | 2794 | 2766 | 2611 | 1501 | 1061 | 482 |
additionalが9人以上いました。小数サンプルなのでここは無視してもいいでしょう。Few-shot Learningをやりたいときには使えそうですね。
アスペクト比の分布
主要キャラクターについてアスペクト比の分布を見てみます。
指標として「縦÷横を、底が2のlogを取ったもの」と比較します。この値が0なら正方形、1なら縦が横の2倍、-1なら横が縦の2倍を表します。
import matplotlib.pyplot as plt
import numpy as np
def plot_aspect_ratios(root_dir):
dirs = sorted(glob.glob(root_dir + "/*"))
characters = [d.replace("\\", "/").split("/")[-1] for d in dirs]
root_dir_base = root_dir.replace("\\", "/").split("/")[-1]
fig = plt.figure(figsize=(10, 10))
for i, d in enumerate(dirs):
files = sorted(glob.glob(d + "/*"))
ar = []
for f in files:
with Image.open(f) as img:
width, height = img.size
ar.append(np.log2(height/width))
n = int(np.ceil(np.sqrt(len(dirs))))
ax = fig.add_subplot(n, n, i+1)
ax.hist(ar, bins=50)
ax.set_yscale('log')
ax.set_title(characters[i])
fig.suptitle(root_dir_base)
fig.savefig(f"{root_dir_base}.png")
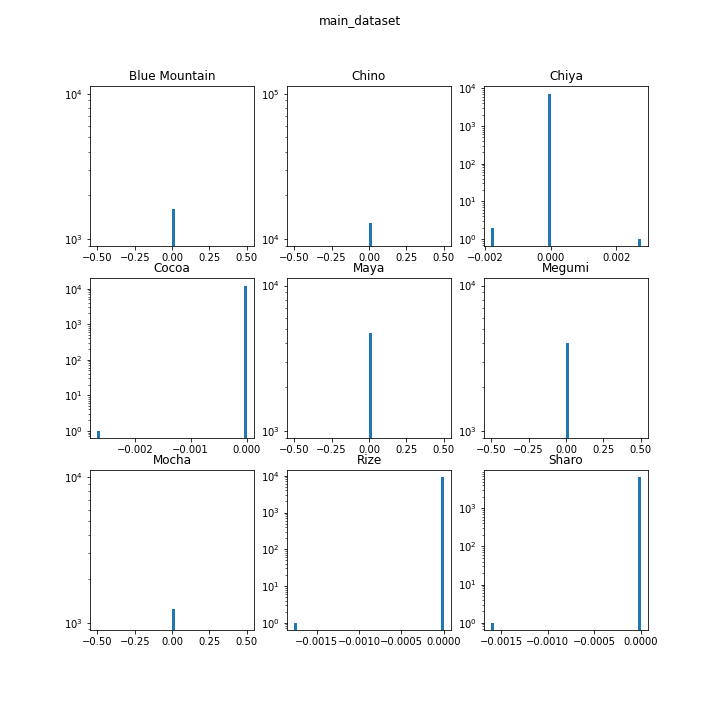
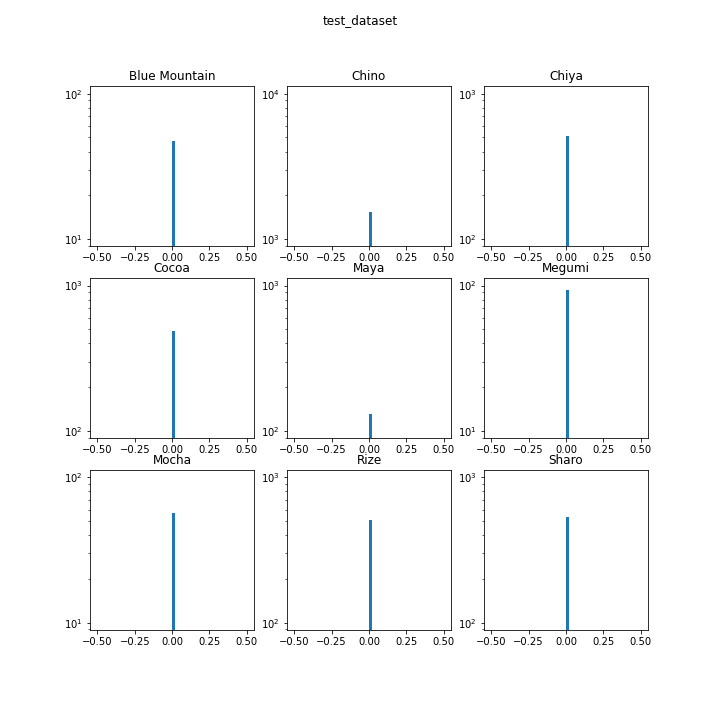
ほとんどヒストグラムが一本線になったので、縦軸を対数にしてみました。それでも一本線なので、データセットはほぼ正方形ということがわかります。綺麗なデータセットで扱いやすいでしょう。
単純に画像分類してみると
今回画像分類が趣旨ではないのですが、「画像分類したときにどのぐらいの精度が出るの?」というのは疑問としてあります。
データセット付属のPDFでは、128×128の解像度でInception V3で訓練したときの混同行列がありました。これはtest_datasetに対する精度です。
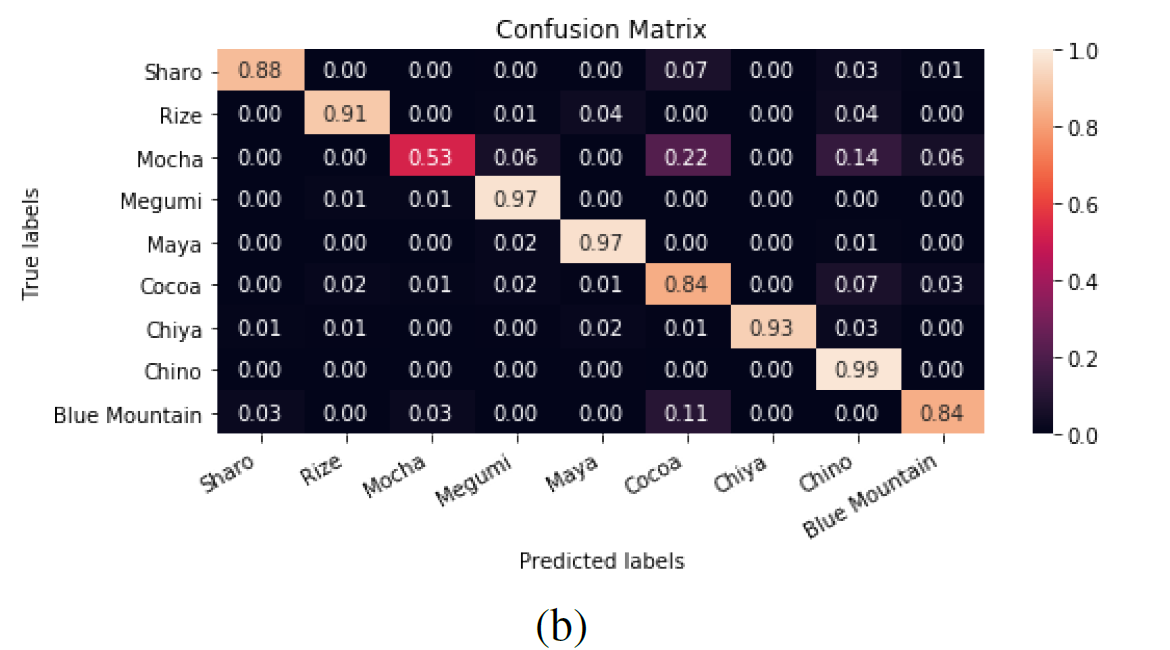
大半のキャラは概ね9割以上出ています。チノちゃんは母数が多いだけあって99%の精度があります。混同しやすいのがモカとココアで、これは両者が姉妹なので仕方がないでしょう。
青山ブルーマウンテンも精度が若干低いですが、データセットに不均衡があるのでこれは仕方ないでしょう。不均衡データとしては結構実践的かもしれませんね。
予告
次の投稿では、線画の自動着色のための下準備、TFRecordの作成していきます。
次回はこちら:https:blog.shikoan.com/gochiusa-02
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー