
CLIPから見るAttentionの有用性


Attentionはこれまでの研究から多く有用性は報告されていたのですが、ネットワークの内側で使われることが多く、わかりやすく差を体感できる例を自分は知りませんでした。今回はCLIPのAdapterという点から、Attentionの有無による精度比較を行ってみます。
目次
はじめに
Adapterとは
最近研究でよく見られるようになりました。基盤モデルのような大きな事前訓練済みモデルに対し、小さなネットワークを差し込み、その部分のみ訓練することで任意の訓練データに対して適用させるものです。ファインチューニングとの違いは以下の通りです。
- Adapter
- 追加小さなネットワークのみ訓練、元モデルは訓練しない
- 訓練速度が速い
- 元モデルはそのままなので、破滅的忘却に悩まされるリスクが減る
- ファインチューニング
- モデルの全体ないし、末尾の特定層のみ訓練
- 特に元モデルが大きくなると、訓練速度がAdapterに比べると遅い
- 元モデルを変えてしまうので、破滅的忘却の問題が起こる
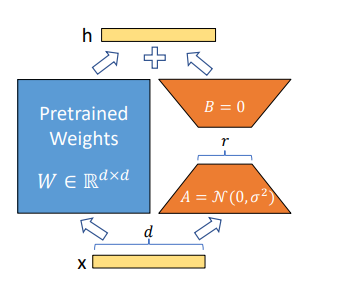
画像生成では、Stable Diffusionを特定データに適用させる際によく使われるLoRAがこのAdapterの一種です。LoRAの正式名称は「LoRA: Low-Rank Adaptation of Large Language Models」(元論文)とあるように、AがAdaptationで、元はNLPの(LLMの)論文です。Stable Diffusionで使われているのはこの応用というわけです(図はLoRAの論文より)。
Stable Diffusionの特定データセットへの適用というと、以前はDreamBoothが使われていましたが、LoRAのほうが訓練が速く、少ないGPUメモリでできるというのは、画像生成では経験的によく知られています。Redditのこの図がわかりやすいですね。
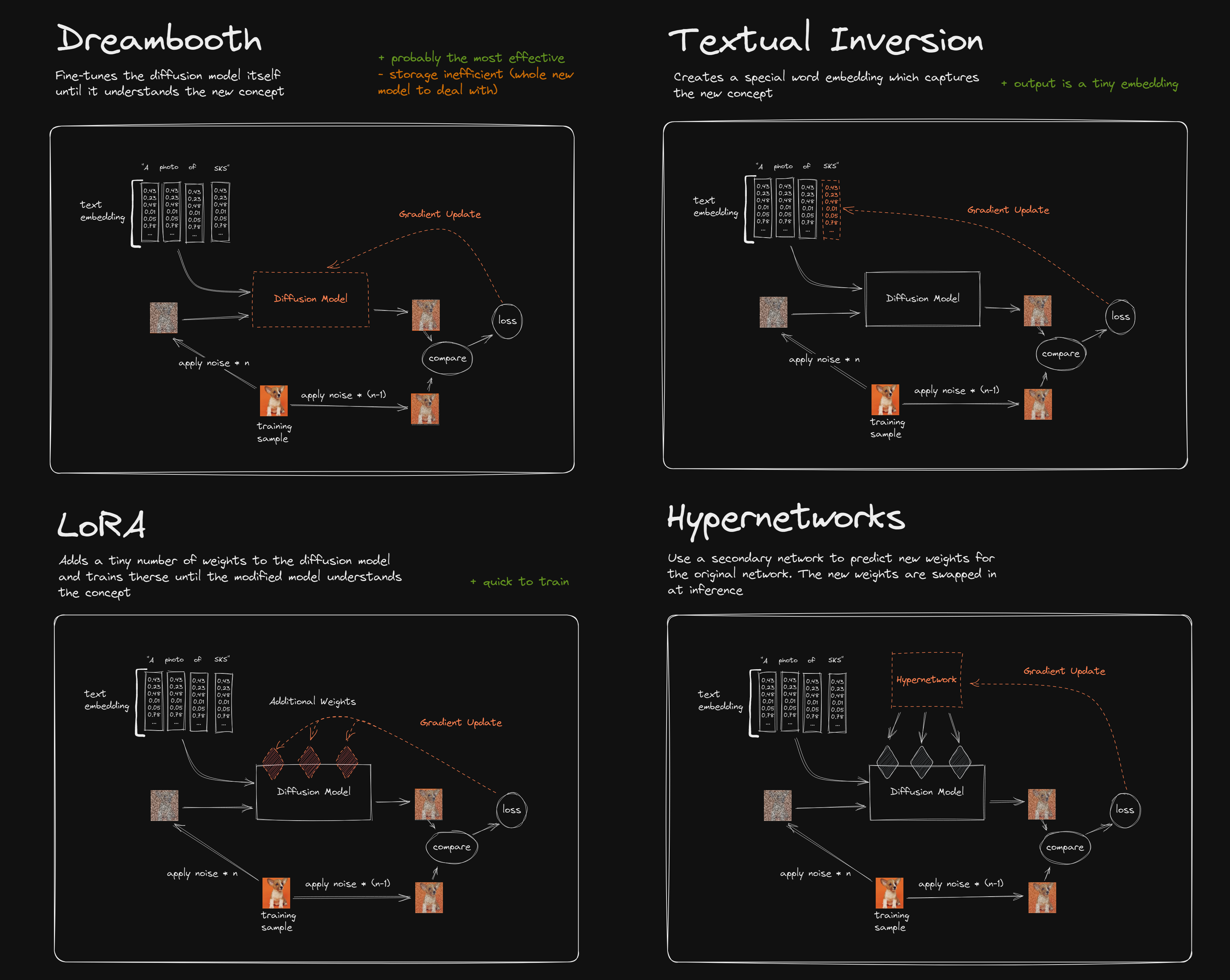
図のように、Stable DiffusionにおけるLoRAとは、拡散モデルに対して追加のレイヤー(Additional Weights)を挿入し、そこのみ訓練する(Gradient Update)するというものです。その何の通り、Adapterの代表例といえるでしょう。
CLIPとは
OpenAIにより2021年に発表されたVision&Languageモデルです。Stable Diffusionでもモデルの根幹をなすなど、2023年現在ではありとあらゆる最新モデルに活用されています。(OpenAIのリポジトリより)
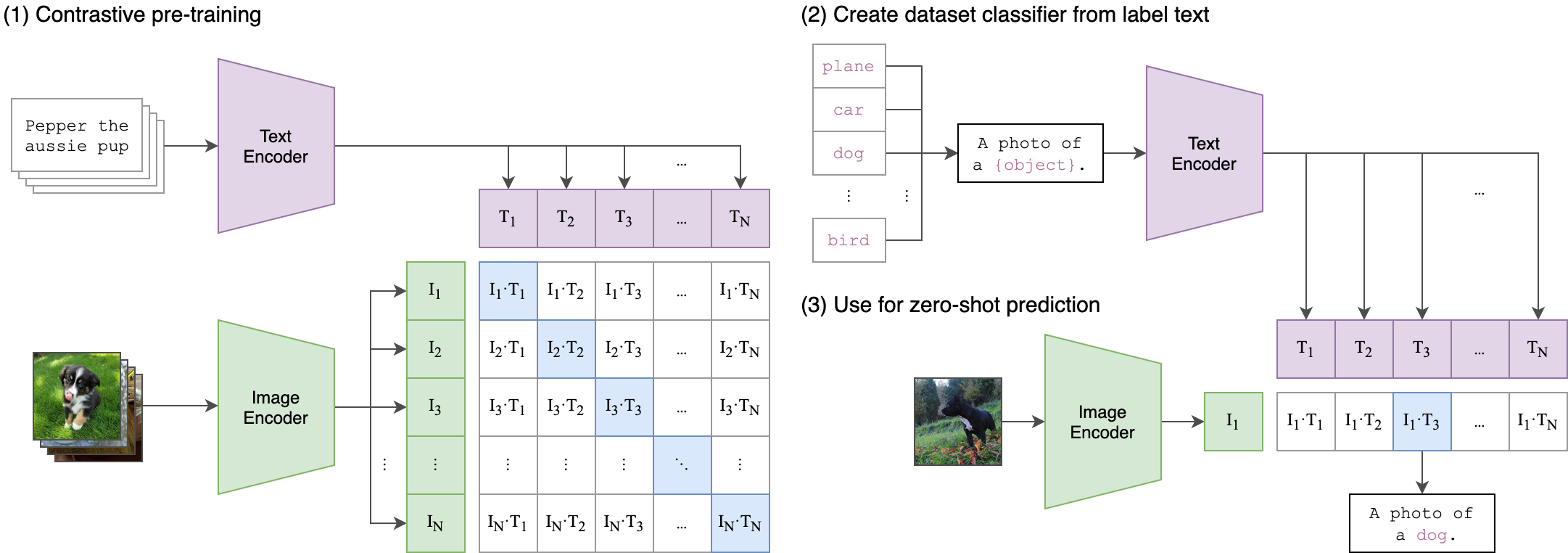
CLIPの大きな有用性の一つは、膨大なデータの事前訓練をすることで、ゼロショット推論ができる点です。訓練データがなくても一定の精度が出るという従来の常識を覆す結果となっています。
このCLIPもFew-shotや教師あり学習の文脈から活用したいという需要があります。よく使われるものでも600MB程度(ViT-B-32)、大きなものは10GBと膨大なサイズなため、ファインチューニングするのが大変です。また、CLIPとは膨大な事前訓練から細かなコンテクストを学習しているため、ファインチューニングをしてしまうと、破滅的忘却により学習した細かなコンテクストを忘れてしまうという問題があります。これに対してはいくつか解決法が考案されていますが、Adapterを使うというのが一つの大きな流れになっています。
CLIPにおけるAdapter
Linear-Probe
これはOpenAIのCLIPで考案されている手法です。手法はとても単純で、CLIPのVision Encoderの末尾にロジスティック回帰を突っ込むだけです。
原著の論文ではこれをAdapterとは呼んでいませんが、広義にはAdapterとみなせるため、ここではAdapterとして扱います。
「Text側はどうするの?」という疑問はありますが、捨てます。後で見ますが、これでも精度出ます。
CLIP Adapter
「CLIP Adapter」という研究が比較的よく知られています。はい、名前に何のひねりもありませんね笑
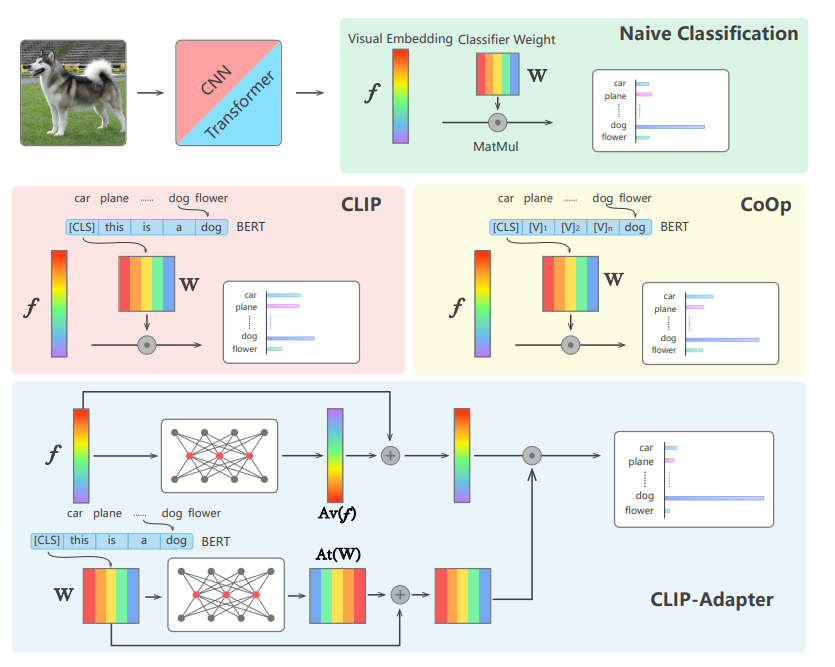
CoOpもCLIPのAdapterとして有名な研究ですがここでは割愛しましょう。CLIP-AdapterではCLIPが出力した画像の出力に対し、学習可能なボトルネック構造を持ったブランチを追加し、最後にテキストの出力をかけて適用させるものです。文章で説明してもよくわかりませんね。。コードで見ましょう。公式コードからです。
class Adapter(nn.Module):
def __init__(self, c_in, reduction=4):
super(Adapter, self).__init__()
self.fc = nn.Sequential(
nn.Linear(c_in, c_in // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(c_in // reduction, c_in, bias=False),
nn.ReLU(inplace=True)
)
def forward(self, x):
x = self.fc(x)
return x
class CustomCLIP(nn.Module):
def __init__(self, cfg, classnames, clip_model):
super().__init__()
self.image_encoder = clip_model.visual
self.text_encoder = TextEncoder(cfg, classnames, clip_model)
self.logit_scale = clip_model.logit_scale
self.dtype = clip_model.dtype
self.adapter = Adapter(1024, 4).to(clip_model.dtype)
def forward(self, image):
image_features = self.image_encoder(image.type(self.dtype))
x = self.adapter(image_features)
ratio = 0.2
image_features = ratio * x + (1 - ratio) * image_features
text_features = self.text_encoder()
image_features = image_features / image_features.norm(dim=-1, keepdim=True)
text_features = text_features / text_features.norm(dim=-1, keepdim=True)
logit_scale = self.logit_scale.exp()
logits = logit_scale * image_features @ text_features.t()
return logits
Adapterの実装は、ただのボトルネック構造を持ったFC層です。
CustomCLIPの部分がCLIP Adapterの実装で、CLIPの出力(image_features)からブランチを作ります。それをAdapterに食わせて、元のimage_featuresとratioで線形平均を取ります。ここの実装は、ResNetのSkip Connectionの部分と直感的にはほぼ一緒です。
あとは、CLIPのゼロショット推論と同じようにしてロジットを吐きます。出力されたロジットはクロスエントロピーの損失関数で学習していきます。結果、Adapterの部分だけ学習が進むというわけです。
この記事でやること
CLIPにおけるAdapterの部分に、Attentionを突っ込むことで、Attentionの有用性を直感的に理解する
これが目標です。具体的には以下の方法で検証します。
- Linear-Probeを実装する
- Linear-Probeに、Attentionブランチを入れて実装する
- CLIP Adapterを実装する
データセットは、CLIPでは比較的精度を出しづらい「FGVCAircraft」というデータセットを使います。これは「Boeing 737-700」のような飛行機の型番を当てるものです。
準備
事前準備として、CLIPのテキスト・画像の特徴量を吐き出します。CLIPの部分は訓練しないので、最終層の出力をキャッシュしてデータセットを作ることで高速化できます。
import torch
import open_clip
from tqdm import tqdm
import torchvision
device = "cuda:1"
def extract_latents(dataset, clip_model, clip_tokenizer):
dataloader = torch.utils.data.DataLoader(dataset, batch_size=256, shuffle=False, num_workers=1)
# extract latent text extractor
list_of_classes = list(dataset.class_to_idx.keys())
prompt_templates = [
'a photo of a {}, a type of aircraft.',
'a photo of the {}, a type of aircraft.',
]
all_text_latents = []
for c in list_of_classes:
text = [f.format(c) for f in prompt_templates]
text = clip_tokenizer(text).to(device)
with torch.no_grad():
text_features = clip_model.encode_text(text)
text_features /= text_features.norm(dim=-1, keepdim=True)
text_features = text_features.mean(dim=0, keepdims=True)
text_features /= text_features.norm(dim=-1, keepdim=True)
all_text_latents.append(text_features.cpu())
all_text_latents = torch.cat(all_text_latents, dim=0)
all_images, all_Y = [], []
for X, y in tqdm(dataloader):
X = X.to(device)
with torch.no_grad():
image_features = clip_model.encode_image(X)
image_features /= image_features.norm(dim=-1, keepdim=True)
all_images.append(image_features.cpu())
all_Y.append(y)
all_images = torch.cat(all_images, dim=0)
all_Y = torch.cat(all_Y, dim=0)
result = {
"class_names": dataset.class_to_idx,
"text": all_text_latents,
"image": all_images,
"y": all_Y
}
return result
def main():
clip_model, _, clip_preprocess = open_clip.create_model_and_transforms(
'ViT-B-32', pretrained='laion2b_s34b_b79k',
device=device)
clip_tokenizer = open_clip.get_tokenizer('ViT-B-32')
trainset = torchvision.datasets.FGVCAircraft(split="train", download=True, root="./dataset", transform=clip_preprocess)
valset = torchvision.datasets.FGVCAircraft(split="val", download=True, root="./dataset", transform=clip_preprocess)
train_latent = extract_latents(trainset, clip_model, clip_tokenizer)
val_latent = extract_latents(valset, clip_model, clip_tokenizer)
torch.save(train_latent, "cache/train_vit32_fgvc.pt")
torch.save(val_latent, "cache/val_vit32_fgvc.pt")
if __name__ == "__main__":
main()
なお、このモデルでのValデータのゼロショット精度は23.79%でした。
Linear-Probe
Sklearnを使う方法と、NNベースを比較してみます(やっていることは同じですが)。クラス数あたりの訓練データの数を、1, 2, 5, 10, 全部と比較してみます。訓練データ全体で約3300枚あります。Valの数は変化させません。
Skelarnを使う方法
import torch
import torch.utils.data
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
import numpy as np
from utils import load_dataset
device="cuda:1"
def main(enable_normalize):
result = {
1: 0,
2: 0,
5: 0,
10: 0,
"all": 0
}
for key in result.keys():
n_sample_per_class = key if key != "all" else None
trainset, text_embedding = load_dataset("train", n_sample_per_class)
train_loader = torch.utils.data.DataLoader(trainset, batch_size=32, shuffle=False, num_workers=1)
valset, _ = load_dataset("val", None)
val_loader = torch.utils.data.DataLoader(valset, batch_size=32, shuffle=False, num_workers=1)
X_train, y_train = [], []
X_val, y_val = [], []
for X_img, y in train_loader:
X_train.append(X_img.numpy())
y_train.append(y.numpy())
for X_img, y in val_loader:
X_val.append(X_img.numpy())
y_val.append(y.numpy())
X_train = np.concatenate(X_train)
y_train = np.concatenate(y_train)
X_val = np.concatenate(X_val)
y_val = np.concatenate(y_val)
if enable_normalize:
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_val = scaler.transform(X_val)
clf = LogisticRegression(max_iter=1000)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_val)
acc = (y_pred == y_val).mean()
result[key] = acc
print(key, acc)
print(result)
if __name__ == "__main__":
main(True)
Logistic Regressionなので仕方ないっちゃ仕方ないですが、最初にStandard Scalerを入れるかどうかで結構精度変わります。
| 1 | 2 | 5 | 10 | all | |
|---|---|---|---|---|---|
| SklearnのLogistic Regression、Standard Scalerなし | 19.92% | 22.14% | 28.20% | 34.53% | 46.23% |
| SklearnのLogistic Regression、Standard Scalerなし | 19.74% | 24.57% | 33.15% | 41.70% | 54.43% |
「all」になると、Standard Scalerの有無で8%程度変わるそうです。(Logistic Regressionなのでそりゃそう)
NNを使う方法
ニューラルネットワークを使う場合は、Standard Scalerを例えばBatchNormなどで代用します。同様にできます。
import torch
import torch.utils.data
from utils import load_dataset
import torchmetrics
from tqdm import tqdm
class SimpleLinearProbe(torch.nn.Module):
def __init__(self, enable_bn):
super().__init__()
if enable_bn:
self.bn = torch.nn.BatchNorm1d(512)
else:
self.bn = None
self.fc = torch.nn.Linear(512, 100)
def forward(self, x):
if self.bn is not None:
x = self.bn(x)
x = self.fc(x)
return x
device = "cuda:1"
def main(enable_bn):
result = {
1: 0,
2: 0,
5: 0,
10: 0,
"all": 0
}
for key in result.keys():
n_sample_per_class = key if key != "all" else None
trainset, text_embedding = load_dataset("train", n_sample_per_class)
train_loader = torch.utils.data.DataLoader(trainset, batch_size=32, shuffle=True, num_workers=4)
valset, _ = load_dataset("val", None)
val_loader = torch.utils.data.DataLoader(valset, batch_size=32, shuffle=False, num_workers=4)
model = SimpleLinearProbe(enable_bn).to(device)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-4)
metric = torchmetrics.Accuracy(task="multiclass", num_classes=100)
max_val_acc = 0.0
text_embedding = text_embedding.to(device)
for epoch in range(200):
metric.reset()
model.train()
for X_img, y in tqdm(train_loader):
X_img, y = X_img.to(device), y.to(device)
optimizer.zero_grad()
y_pred = model(X_img)
loss = criterion(y_pred, y)
loss.backward()
optimizer.step()
metric(y_pred.argmax(dim=-1).cpu(), y.cpu())
print(f"Epoch {epoch:03} | Train accuracy : {metric.compute()}")
metric.reset()
model.eval()
for X_img, y in tqdm(val_loader):
with torch.no_grad():
X_img, y = X_img.to(device), y.to(device)
y_pred = model(X_img)
metric(y_pred.argmax(dim=-1).cpu(), y.cpu())
val_acc = metric.compute()
max_val_acc = max(val_acc, max_val_acc)
print(f"Epoch {epoch:03} | Val accuracy : {val_acc}")
result[key] = max_val_acc
print(key, max_val_acc)
print(result)
if __name__ == "__main__":
main(True)
やはり、BatchNormを入れたほうが高い精度になりました。
| 1 | 2 | 5 | 10 | all | |
|---|---|---|---|---|---|
| SklearnのLogistic Regression、Standard Scalerなし | 19.74% | 24.57% | 33.15% | 41.70% | 54.43% |
| NNのLinear-Probe BNなし | 14.88% | 22.56% | 29.88% | 36.48% | 46.59% |
| NNのLinear-Probe BNあり | 16.86% | 23.01% | 32.82% | 41.94% | 54.49% |
特にクラスあたりの数1、2のようなFew-shotな設定で、SklearnのほうがBNありよりも高いケースが見受けられます。Sklearnが訓練データ全体を一括で正規化しているのに対し、BatchNormはバッチ単位で正規化しているため、正規化の平均・分散の信頼度が一括のほうが高く、一括でやったほうがそのゆらぎが少ないのが一因かと思われます。
Text情報を使う
LinearProbeはImage Encoderの出力しか使いませんでした。Text Encoderの情報は捨てているのでちょっともったいないです。ただ、Text Encoderの出力とImage Encoderの出力は次元が違うため、これらを単純な線形回帰でつなげるのは自明ではありません。具体的には、
- Image : $(N, C)$
- Text : $(K, C)$
という出力です。ここで、$N$は画像のデータ数、$C$は隠れ層の次元数、$K$はクラス数を示します。単にImageの横にTextをつなげてしまうと、$NK$次元数(このデータセットなら51200次元)も追加されてしまうため、次元の呪いが起きてしまいます。
ImageとTextをつなげて線形回帰する方法は、いくつか考えられます。
- $IT^T$というロジットの次元($(N, K)$)に置き換えて評価する
- Imageの情報と、ロジットの情報をつなげて($(N, C+K)$)評価する
直感的には、Imageよりもロジット、ロジットよりも全盛りのほうが精度が出そうなように思えます。しかし、結果はそうはなりません。
| Image | Logit | 1 | 2 | 5 | 10 | all |
|---|---|---|---|---|---|---|
| ✓ | 19.74% | 24.57% | 33.15% | 41.70% | 54.43% | |
| ✓ | 19.95% | 23.85% | 33.96% | 40.14% | 50.17% | |
| ✓ | ✓ | 20.07% | 24.81% | 34.11% | 41.91% | 54.04% |
Logitのみの場合は、Imageのみの場合より全般的に精度が出ていません。これはLogitでドット積を取ってしまうことで、情報の一部が落ちてしまうことを表しています。
ImageとLogitを併用する場合は、Few-shotな設定で若干精度の向上が見受けられますが、正直誤差レベルで、Image単独とそれほど差がありません。併用した場合の実装は以下のようになります。
import torch
import torch.utils.data
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
import numpy as np
from utils import load_dataset
device="cuda:1"
def main():
result = {
1: 0,
2: 0,
5: 0,
10: 0,
"all": 0
}
for key in result.keys():
n_sample_per_class = key if key != "all" else None
trainset, text_embedding = load_dataset("train", n_sample_per_class)
train_loader = torch.utils.data.DataLoader(trainset, batch_size=32, shuffle=False, num_workers=1)
valset, _ = load_dataset("val", None)
val_loader = torch.utils.data.DataLoader(valset, batch_size=32, shuffle=False, num_workers=1)
A_train, X_train, y_train = [], [], []
A_val, X_val, y_val = [], [], []
for X_img, y in train_loader:
X_train.append(X_img.numpy())
A_train.append((X_img@text_embedding.T).numpy())
y_train.append(y.numpy())
for X_img, y in val_loader:
X_val.append(X_img)
A_val.append((X_img@text_embedding.T).numpy())
y_val.append(y.numpy())
X_train = np.concatenate(X_train)
A_train = np.concatenate(A_train)
y_train = np.concatenate(y_train)
X_val = np.concatenate(X_val)
A_val = np.concatenate(A_val)
y_val = np.concatenate(y_val)
X_train = np.concatenate([X_train, A_train], axis=-1)
X_val = np.concatenate([X_val, A_val], axis=-1)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_val = scaler.transform(X_val)
clf = LogisticRegression(max_iter=1000)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_val)
acc = (y_pred == y_val).mean()
result[key] = acc
print(key, acc)
print(result)
if __name__ == "__main__":
main()
Linear-ProbeにAttentionブランチを追加する
CLIP Adapterを参考に、LinearProbeにAttentionブランチを追加します。
Attentionとは、$softmax(QK^T)V$(Query, Key, Value)と計算するので、以下のコードのattention path以下のような実装でOKです(Attentionとはなんぞやという説明はいっぱいあるのでこのへん読んでください)。一般的にはこれはCross Attentionになるはずです。
※Attentionありの場合は、特にデータ数の多い場合でTrain lossの収束が遅い傾向があったため、400エポック訓練しています
import torch
import torch.utils.data
from utils import load_dataset
import torchmetrics
from tqdm import tqdm
import numpy as np
class AttentionLinearProbe(torch.nn.Module):
def __init__(self, ratio):
super().__init__()
self.bn1 = torch.nn.BatchNorm1d(512)
self.bn2 = torch.nn.BatchNorm1d(512)
self.bn3 = torch.nn.BatchNorm1d(512)
self.fc = torch.nn.Linear(512, 100)
self.ratio = ratio
self.n_sqrt = np.sqrt(512)
def forward(self, img, text):
x = self.bn1(img) # (N, C)
# attention path
y = self.bn2(text)
adapter = x @ y.T # (N, K)
adapter = torch.softmax(adapter / self.n_sqrt, dim=-1) @ y # (N, C)
x = x * (1-self.ratio) + adapter * self.ratio
# x = x / x.norm(dim=-1, keepdim=True)
x = self.bn3(x)
x = self.fc(x)
return x
device = "cuda:1"
def main(ratio):
print("--- ratio : ", ratio, "---")
result = {
1: 0,
2: 0,
5: 0,
10: 0,
"all": 0
}
for key in result.keys():
n_sample_per_class = key if key != "all" else None
trainset, text_embedding = load_dataset("train", n_sample_per_class)
train_loader = torch.utils.data.DataLoader(trainset, batch_size=32, shuffle=True, num_workers=4)
valset, _ = load_dataset("val", None)
val_loader = torch.utils.data.DataLoader(valset, batch_size=32, shuffle=False, num_workers=4)
model = AttentionLinearProbe(ratio).to(device)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-4)
metric = torchmetrics.Accuracy(task="multiclass", num_classes=100)
max_val_acc = 0.0
text_embedding = text_embedding.to(device)
# うまくロスが落ちきれなかったので400epochにした
for epoch in range(400):
metric.reset()
model.train()
for X_img, y in tqdm(train_loader):
X_img, y = X_img.to(device), y.to(device)
optimizer.zero_grad()
y_pred = model(X_img, text_embedding)
loss = criterion(y_pred, y)
loss.backward()
optimizer.step()
metric(y_pred.argmax(dim=-1).cpu(), y.cpu())
print(f"Epoch {epoch:03} | Train accuracy : {metric.compute()}")
metric.reset()
model.eval()
for X_img, y in tqdm(val_loader):
with torch.no_grad():
X_img, y = X_img.to(device), y.to(device)
y_pred = model(X_img, text_embedding)
metric(y_pred.argmax(dim=-1).cpu(), y.cpu())
val_acc = metric.compute()
max_val_acc = max(val_acc, max_val_acc)
print(f"Epoch {epoch:03} | Val accuracy : {val_acc}")
result[key] = max_val_acc
print(key, max_val_acc)
print(result)
if __name__ == "__main__":
main(0.4)
なお、これもBNの有無でやや大きく変わり、Pre BN(コードでいうbn1, 2)とPost BN(コードでいうbn3)の有無で調べると(ratio=0.4で固定させます)、
| Pre BN | Post BN | 1 | 2 | 5 | 10 | all |
|---|---|---|---|---|---|---|
| ✓ | 21.36% | 28.23% | 33.09% | 39.42% | 50.74% | |
| ✓ | 18.36% | 24.09% | 33.33% | 42.15% | 54.70% | |
| ✓ | ✓ | 23.70% | 28.47% | 36.45% | 43.50% | 54.73% |
| (Attentionなし) | 16.86% | 23.01% | 32.82% | 41.94% | 54.49% |
以下のことがわかります
- Attentionなし、ありで比べると、ありのほうが高い精度。
- BNはPreもPostもあったほうが順当に精度が高い
特にFew-shotでの効きがいいですね。ちなみに先程の単純なロジットとの結合と比較してみましょう。
| 1 | 2 | 5 | 10 | all | |
|---|---|---|---|---|---|
| Attentionなし(NN) | 16.86% | 23.01% | 32.82% | 41.94% | 54.49% |
| Image+Logit(Sklearn:N×(C+K)) | 20.07% | 24.81% | 34.11% | 41.91% | 54.04% |
| Attentionあり(NN) | 23.70% | 28.47% | 36.45% | 43.50% | 54.73% |
Attentionありのほうが一貫して高くなることを確認できました。純粋な行列積を横に足した場合とくらべて、Attentionのほうが非線形性が増え、良い特徴抽出ができるということを示します。
Attentionの面白い点は、「モデル全体の非線形性は増えているものの、学習パラメーターは0」という点です(BatchNormや最後の線形回帰の部分は学習パラメーターありますが、Attentionの有無には直接関係ありません)。近年のモデルでAttentionが好まれるのはこのへんの特性なのではないかなと思います。
CLIP-Adapter
ソースコードが公開されていたので、CLIP Adapterもついでに実装してみました。
CLIP AdapterはAttentionを使わず、Auto Encoderのようなボトルネック構造をAdapterとして使ったものです(ただし、Auto Encoderも行列分解の一種なので、行列分解という点ではこれもAttentionの類似パターンとみなすことができます。ただし、FC層の学習パラメーターはあります)。
import torch
import torch.utils.data
from utils import load_dataset
import torchmetrics
import torch.nn.functional as F
import open_clip
from tqdm import tqdm
import numpy as np
class CLIPAdapter(torch.nn.Module):
def __init__(self, logit_scale, ratio):
super().__init__()
self.bn = torch.nn.BatchNorm1d(512)
self.adapter1 = torch.nn.Linear(512, 128, bias=False)
self.adapter2 = torch.nn.Linear(128, 512, bias=False)
self.logit_scale = np.exp(logit_scale)
self.ratio = ratio
def forward(self, img, text):
x = self.bn(img)
# adapter path
adapter = F.relu(self.adapter1(x))
adapter = F.relu(self.adapter2(adapter))
x = x * (1-self.ratio) + adapter * self.ratio
x = x / x.norm(dim=-1, keepdim=True)
logit = self.logit_scale * x @ text.T
return logit
device = "cuda:1"
def main(ratio):
print("--- ratio : ", ratio, "---")
result = {
1: 0,
2: 0,
5: 0,
10: 0,
"all": 0
}
clip_model, _, clip_preprocess = open_clip.create_model_and_transforms(
'ViT-B-32', pretrained='laion2b_s34b_b79k',
device=device)
for key in result.keys():
n_sample_per_class = key if key != "all" else None
trainset, text_embedding = load_dataset("train", n_sample_per_class)
train_loader = torch.utils.data.DataLoader(trainset, batch_size=32, shuffle=True, num_workers=4)
valset, _ = load_dataset("val", None)
val_loader = torch.utils.data.DataLoader(valset, batch_size=32, shuffle=False, num_workers=4)
logit_scale = clip_model.logit_scale.detach().cpu().numpy()
model = CLIPAdapter(logit_scale, ratio).to(device)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-4)
metric = torchmetrics.Accuracy(task="multiclass", num_classes=100)
max_val_acc = 0.0
text_embedding = text_embedding.to(device)
for epoch in range(400):
metric.reset()
model.train()
for X_img, y in tqdm(train_loader):
X_img, y = X_img.to(device), y.to(device)
optimizer.zero_grad()
y_pred = model(X_img, text_embedding)
loss = criterion(y_pred, y)
loss.backward()
optimizer.step()
metric(y_pred.argmax(dim=-1).cpu(), y.cpu())
print(f"Epoch {epoch:03} | Train accuracy : {metric.compute()}")
metric.reset()
model.eval()
for X_img, y in tqdm(val_loader):
with torch.no_grad():
X_img, y = X_img.to(device), y.to(device)
y_pred = model(X_img, text_embedding)
metric(y_pred.argmax(dim=-1).cpu(), y.cpu())
val_acc = metric.compute()
max_val_acc = max(val_acc, max_val_acc)
print(f"Epoch {epoch:03} | Val accuracy : {val_acc}")
result[key] = max_val_acc
print(key, max_val_acc)
print(result)
if __name__ == "__main__":
main(0.4)
CLIP AdapterはLinearProbeと異なる点がいくつかあります。
- Linear-Probeはあくまで(Branchを追加するものの)、ImageEncoderの出力に対してFC層を噛ませて分類するもの(訓練時と推論時でクラス群を変えることは不可能)
- CLIP Adapterは分類のロジットに変換するのは、Text Encoderの出力とドット積をとるもので、Adapterを入れたとしてもゼロショット推論は可能(訓練時と推論時でクラス群を変えても機能する)
なので、思想的にはかなり異なる部分がある点には注意が必要です。あくまで分類精度を比較すると、
| 1 | 2 | 5 | 10 | all | |
|---|---|---|---|---|---|
| Logistic + Attentionなし(NN) | 16.86% | 23.01% | 32.82% | 41.94% | 54.49% |
| Logistic + Attentionあり(NN、r=0.4) | 23.70% | 28.47% | 36.45% | 43.50% | 54.73% |
| CLIP Adapter ratio=0.1 | 29.49% | 30.42% | 35.73% | 40.89% | 51.25% |
| CLIP Adapter ratio=0.2 | 29.31% | 31.08% | 36.24% | 40.02% | 51.16% |
| CLIP Adapter ratio=0.4 | 29.04% | 30.54% | 35.70% | 39.84% | 51.19% |
Few-shotではCLIP Adapterの精度が大きく良かったが、Shot数が増えていくにつれて、LinearProbeのようなロジスティック回帰ベースのほうが良くなったという結果になりました。
それ以外の手法
CLIP Adapter以外にもAttentionベースのAdapterはあるため、純粋に精度を上げたいのならそちらを使うのが良いでしょう。いくつか挙げておきます。
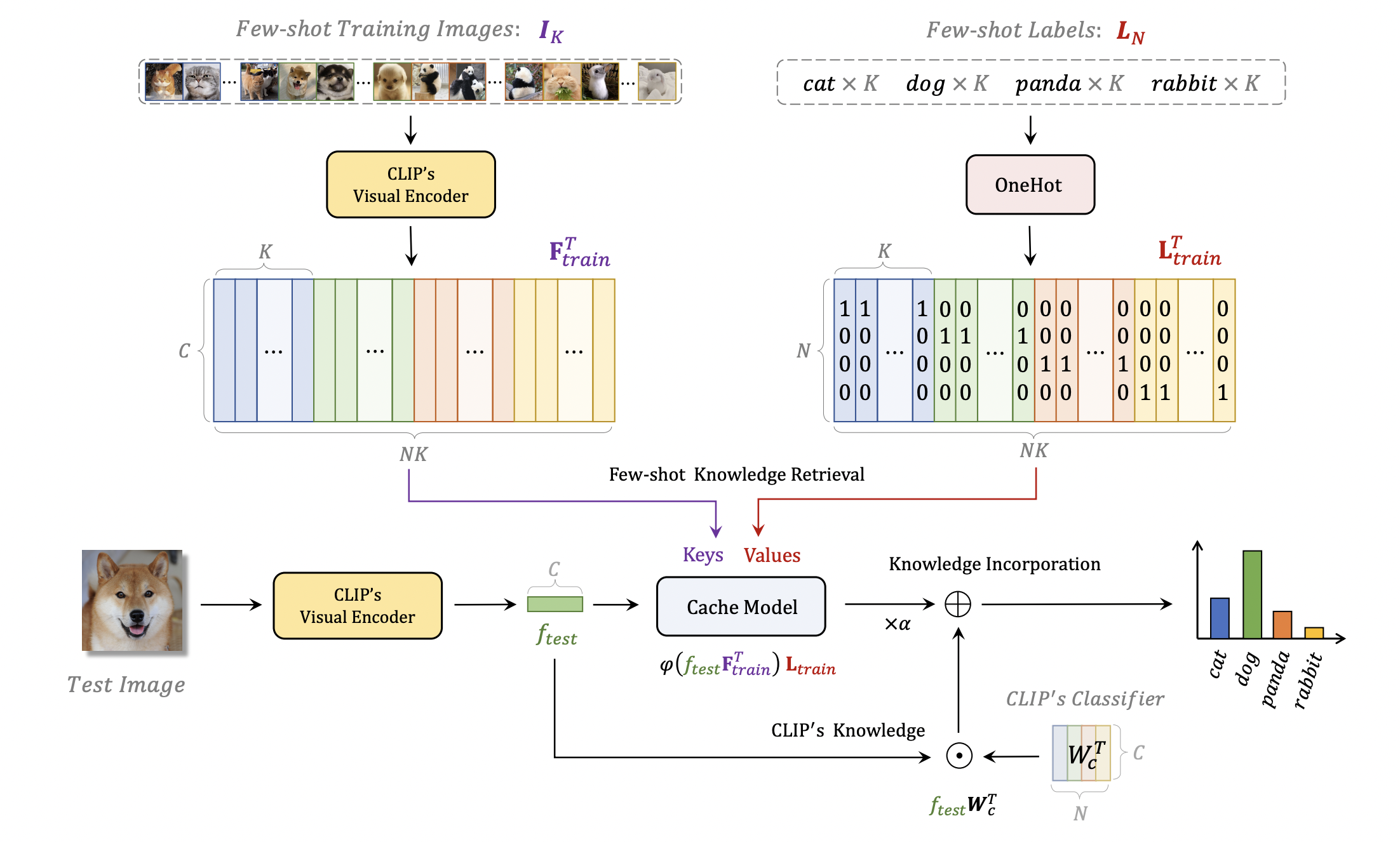
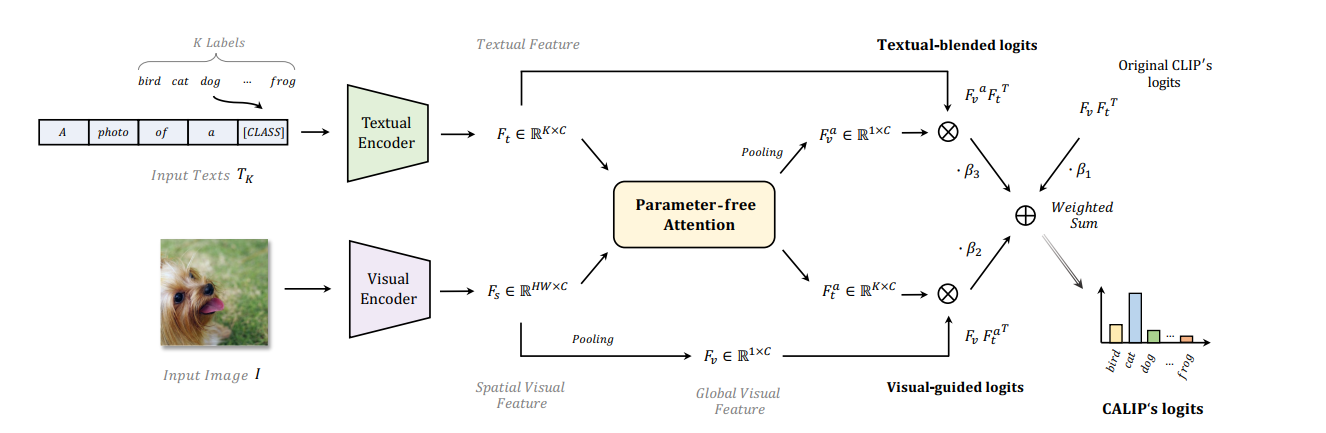
CALIPは内容的にはとても近かったのですが、Codeが「Avaliable in few days」のまま4ヶ月間放置されていたので割愛します(再現しようとしたらやり方が悪かったのかうまくいかなかったです)。
まとめ
- CLIPのLinearProbeにAttentionブランチを追加すると、追加しない場合とくらべて、わかりやすく精度上がった
- 純粋に精度を上げたい場合だと、より最新のAdapterを使ったほうがいいこともある。CLIPAdapterはFew-shotの場合に特に上がった
Attentionの効果はかなりわかりやすく出たので、これをNN内でうまく活用することで、ツヨツヨモデルが出来上がるというのも納得行くでしょう。
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー