
論文まとめ:Playable Environments: Video Manipulation in Space and Time


* タイトル:Playable Environments: Video Manipulation in Space and Time
* 著者:Willi Menapace, Stéphane Lathuilière, Aliaksandr Siarohin, Christian Theobalt, Sergey Tulyakov, Vladislav Golyanik, Elisa Ricci
* 論文:https://arxiv.org/abs/2203.01914
* カンファ:CVPR2022
* プロジェクトページ:https://willi-menapace.github.io/playable-environments-website/
* コード:https://github.com/willi-menapace/PlayableEnvironments
目次
ざっくりいうと
- 既存のビデオに対して、オブジェクトの動きやカメラの向きをコントロールして新たな動画を生成する「Playable Environments」を提唱
- NeRF+生成モデルの流れ(例:GIRAFFE)を踏襲しつつ、ゲームのようにユーザーが複数のオブジェクトをコントロールしつつ、教師なしでオブジェクトのコントロールの表現を獲得可能。
- GANだけよりも、NeRFベースと組み合わせることで、オブジェクトをコントロール可能なビデオ生成において、SoTAのパフォーマンスを達成。
Playable Environmentsとは
ゲームのように、プレイヤーやカメラがコントロールできるビデオ生成のこと。モデリングベースでは扱いづらい動的なスタイルも扱える。
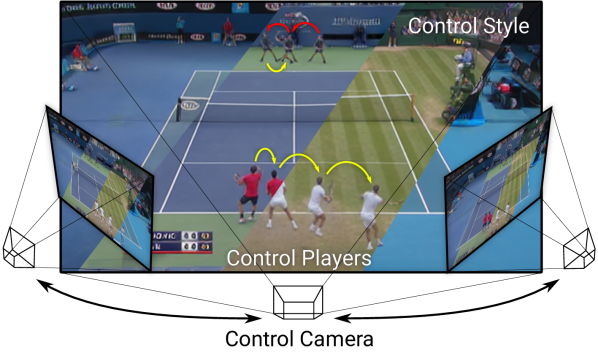
Playable Environmentsの6個の特徴。

先行研究との位置づけは、GIRAFFEやGANcraftを複数の単眼動画像、複数の移動・変形物体、多様な物体やシーン外観に汎化できるように拡張したもの。
手法
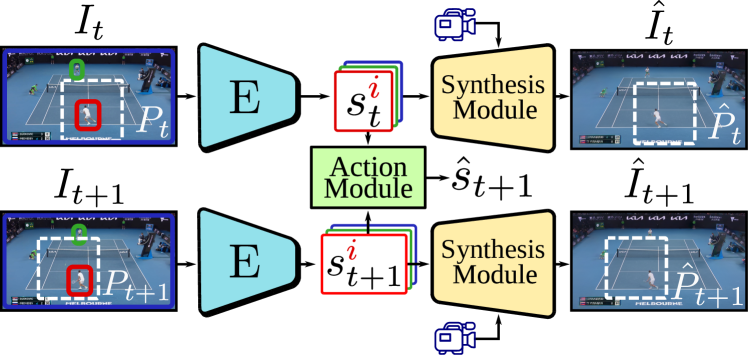
入力データは、オブジェクトごとのBounding Boxがついたフレーム画像。時点tの画像$I_t$と、時点t+1の画像$I_{t+1}$が入力に与えられ、$s_t^i\to s_t^{i+1}$への離散的な動きを行動ラベル$a_t^{i}\in{1,\cdots,K}$を用いて教師なしで学習する。$K$はハイパーパラメーター。
- Action Module(特性1):テスト時に、ユーザが選択したアクションを次のフレーム生成の条件とするために使用
- Synthesis Module:デコーダネットワークは、カメラ制御を可能にするため(特性2)に、すべてのオブジェクトの状態とカメラパラメータを組み合わせて入力フレームを再構築。
→アクションモジュールと合成モジュールは別々のフェーズで学習
特性3を満たすために、オブジェクトのカテゴリーを静的なものと動的なものに分ける。
- 静的なオブジェクト:背景
- 動的なオブジェクト:プレイ可能なオブジェクト(例:人間)
$s_t^i=(x_t^i, w_t^i, \pi_t^i)$と表現し、
- $x_t^i$が位置
- 静的なオブジェクト:固定
- 動的なオブジェクト:メラパラメータとそのバウンディングボックスが与えられると、バウンディングボックスの下辺の中点を地表面に投影することで近似
- $w_t^i$がスタイル (特性5)
- $\pi_t^i$がオブジェクトのポーズ (特性4)
Synthesis Module
カメラコントロール(特性2)
NeRFと同じ。NeRFでは3次元上の点の体積密度$\sigma$と輝度$c$に対し、レイ$r$を投射しレイキャスティングにより、ボリュームレンダリングにより出力を計算する。ボクセルで例えるなら体積密度はRGB値、輝度は不透明度に相当。
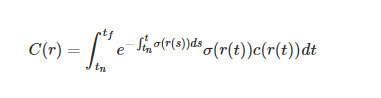
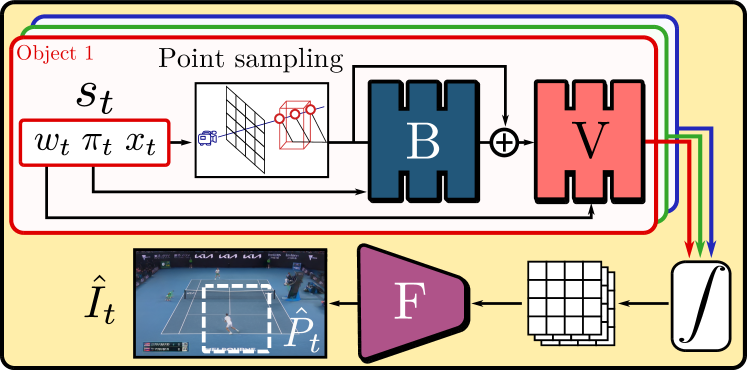
マルチオブジェクト(特性3)
MLPのVにより、各オブジェクトの特徴をを個別に計算。図の「∫」はボリュームレンダリングプロセスで、Vはレイキャスティングの各レイ${x_p}_{p=1}^N$の特徴量$f_p$と不透明度$\sigma_p$を$f_p, \sigma_p=V(x_p)$と表現。
B→Vは正準空間(canonical space)からの符号化
変形可能なオブジェクト(特性4)
ここは位置についてのただの回帰モデル。Bは正準空間での位置。最終的にレイ$r$上の点$x_p$に対応する、オブジェクトの位置$\tilde{x_p}$を求めたい。
$$\tilde{x_p}=x_p+B(x_p, \pi_t)$$
オブジェクト固有の位置$x_t$ではなく、レイ上の位置$x_p$と書いてあるので、いったんレイキャスティングをしてサンプリングをしていると考えられる(図のPoint sampling)
外観の変更(特性5)
AdaINをベースにした埋め込みスタイルの埋め込み表現モデル$V$を使用
ロバスト性(特性6)
キャリブレーションとローカライズの誤差に対するロバスト性。超解像のようなアップサンプリングモジュール$F$を用意する。ここでの入力は、低解像度でチャンネル数が多い。ロバスト性と同時にNeRFのレイの数を大幅に減らすことができ、メモリ消費量的に美味しい。
Action Module
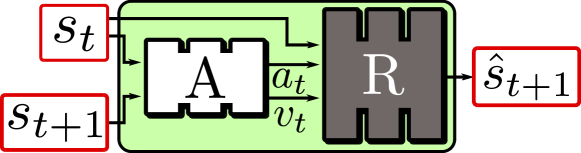
Actionモジュールは連続する$s_t$、$s_{t+1}$のフレームが与えられたとき、ラベル$a_t$の表現$v_t$を獲得するもの。
モチベーションとしては、オブジェクトを移動したりしてコントロール済みの状態$\hat{s}_{t+1}$を求めたい。
ただ直接$\hat{x}_{t+1}$を学習すると現在のカメラと独立した動きを学習することが確認されたので、
$$\hat{x}_{t+1}=x_t+M\Delta$$
と学習した。ここで$M$はカメラの座標を表現する回転行列、$\Delta$はカメラの座標系でのオブジェクトの動き。
損失関数
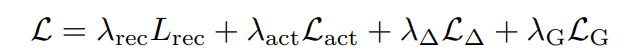
Reconstruction loss
- $L_{rec}$:特徴量ベースのL2ロス。$t=1\to T$に対して、$s_t, \hat{s}_t$のL2ロスを取る
Action learning losses
- $L_{act}$:先行研究のロスを使いまわし。$s_t$と$\hat{s}_t$で、行動のラベルが等しいかどうかの確率を学習。画像は先行研究より。

- $L_{\Delta}$:オブジェクトの動き$\Delta$を学習。ラベルごとの確率で重みづけたL2ロスを計算。「オブジェクトのモーションの数J × ミニバッチ数K」のペアをとり、似たオブジェクトの動きを同一のアクション$a_t$に紐づけるように促す。

Temporal Discriminator
Playableなビデオ生成のための既存の研究は、オブジェクトが非現実的な動きをしたり、時間軸が不自然なことがある。時間方向の1DConvを用いた「Temporal Discriminator」というネットワークを導入する。
GANのロスは「Action Module」と「Temporal Discriminator」に適用。
評価
データセット
Minecraftの動画や、テニスの試合の動画のデータセットを使用
定量評価
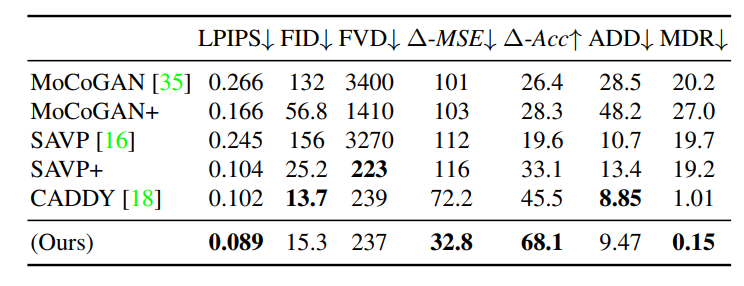
- $\Delta$:オブジェクトの動き
- ADD:各オブジェクトのDetection Distance
- MDR:Missing Detection Rate
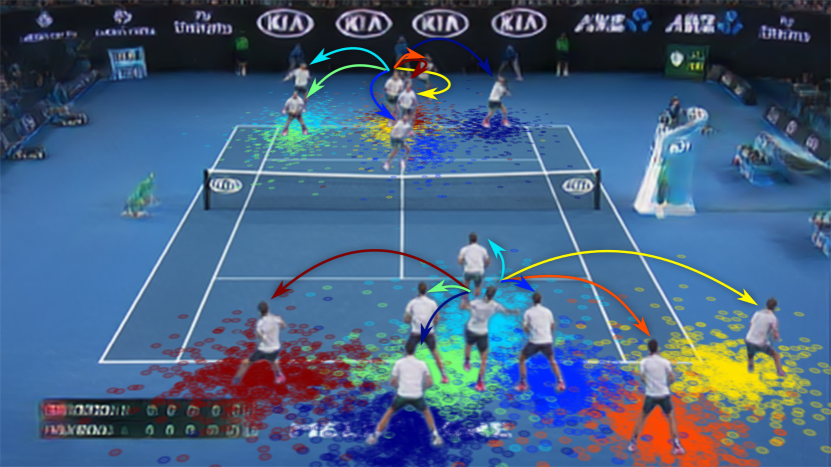
この図は矢印方向に入力を与えたとき、実際のプレーヤーがどこに動いたのかを示すプロット。
まとめと感想
- NeRF+GANという最近よくある風潮だが、3Dゲームのようにオブジェクトを動かせるのは面白い。ついにここまできてかという印象
- 内部でどのような表現が獲得できているのか純粋に気になる
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー