
論文まとめ:High-Resolution Image Synthesis with Latent Diffusion Models
Posted On 2022-10-06


- タイトル:High-Resolution Image Synthesis with Latent Diffusion Models
- 著者:Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, Björn Ommer
- URL:https://arxiv.org/abs/2112.10752
- カンファ:CVPR 2022
- コード:https://github.com/CompVis/latent-diffusion
目次
ざっくりいうと
- Stable Diffusionの元論文。拡散モデルの計算量を下げ、訓練・推論しやすくすることで「民主化」を目指したもの。
- 従来の拡散モデルはピクセルベースで行っているため、計算量が大きい。画像をエンコードし、潜在空間上で拡散モデルを適用することで、訓練推論とも計算量を下げ、かつ生成画像の品質を維持できる。
- テキスト-画像の生成のほか、超解像やInpaintingができ、従来の専用モデルの性能に匹敵するものとなった。
導入
高解像度画像合成の民主化
- 拡散モデル(DM)は計算量が重い
- RGB画像の高次元空間において繰り返し関数評価(および勾配計算)を必要とする
- 最も強力な拡散モデルの学習にはV100で数百日
- 推論でも50kサンプル生成にはA100で約5日
- DMの性能を損なうことなく、学習とサンプリングの両方において計算量を削減したい
潜在空間への出発
学習済みモデルの歪み率トレードオフの図
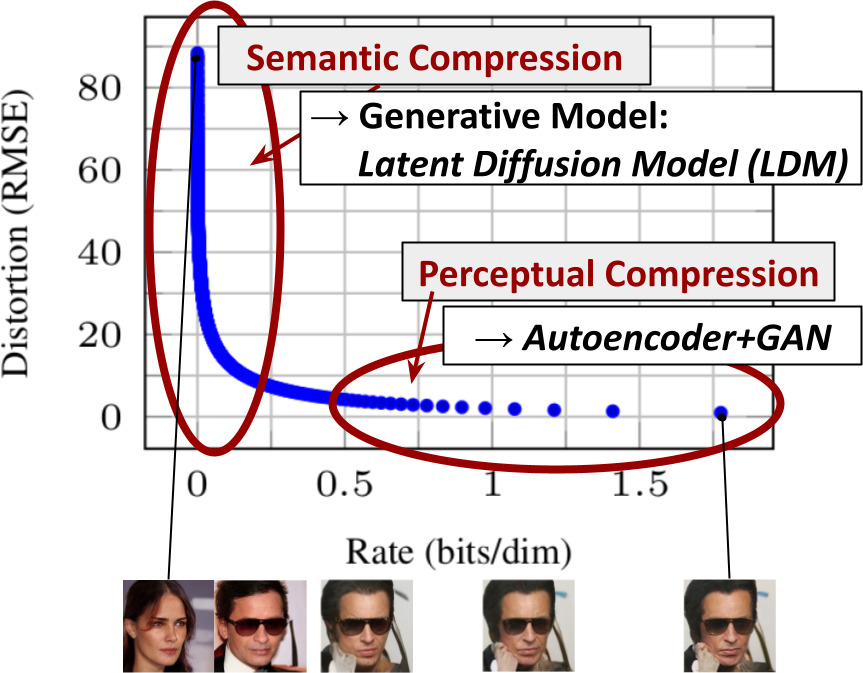
学習は大きく2つの段階に分けられる。
- 第一段階は知覚的な圧縮段階。高周波の詳細を除去するが、意味的な変化はほとんど学習されない。
- 第二段階は実際の生成モデルがデータの意味的・概念的な構成を学習する(意味的圧縮)。
知覚的に同等であるが、計算上より適した空間を見つけ、そこで高解像度画像合成のための拡散モデルを学習することが目的。
→ 知覚的に等価な低次元のオートエンコーダの学習で実現。具体的には解像度の縮小。
手法
圧縮学習と生成学習の段階を明示的に分離することを提案。そのために、画像空間と知覚的に等価な空間を学習する自動エンコードモデルを利用し、計算量を大幅に削減する。
- 高次元の画像空間から離れ、低次元の空間でサンプリングを行うため、計算効率の高いDM(拡散モデル)を得ることができる。
- UNetアーキテクチャから継承されたDMの帰納的バイアスを利用すると、空間構造を持つデータに対して特に有効であるため、従来のアプローチで要求された積極的で品質を下げる圧縮レベルの必要性を緩和できた。
- 最後に、潜在空間が複数の生成モデルの学習に利用でき、単一画像CLIPガイド付きなどの他の下流アプリケーションにも利用できる汎用圧縮モデルを得ることができた。
Pixel SpaceではなくLatent Spaceで行う拡散モデル
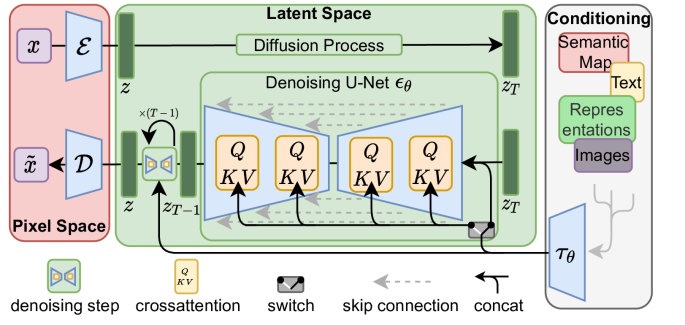
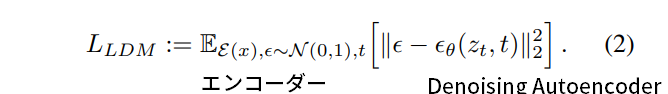
セマンティックマップやテキストによる条件付
Cross Attentionでやった
実験結果
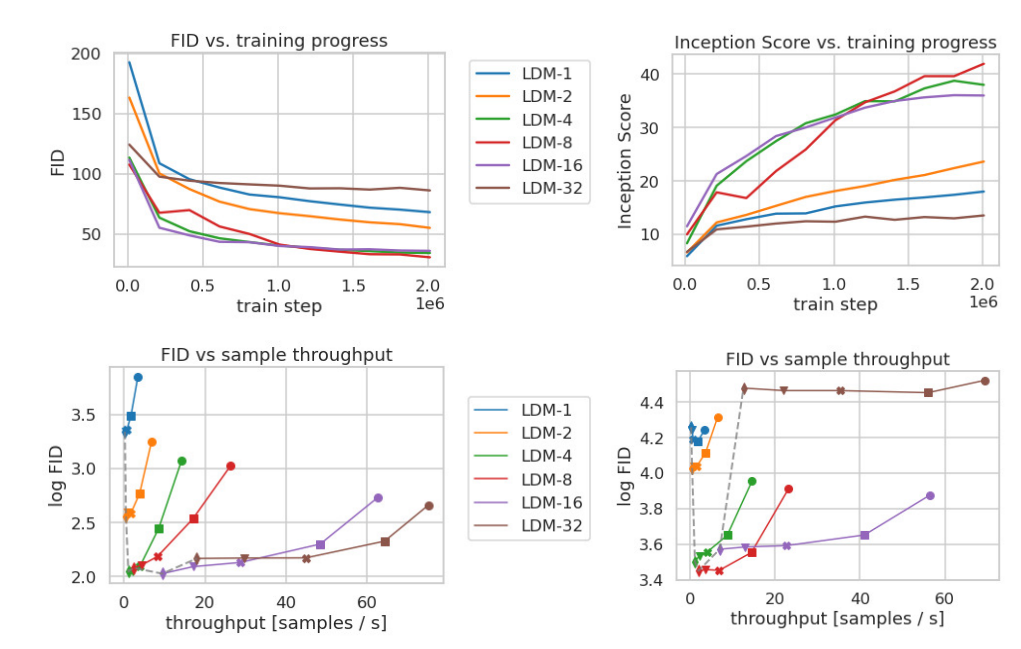
- LDM-1, 2, 4は解像度の縮小。数字が大きいほど縮小が大きい
- 上が訓練時間
- 縦軸のFIDは低いほどよい、Inception Scoreは高いほどよい。横軸は訓練の進み
- 解像度を下げるほど訓練の進みは速い
- 下が推論時間
- 横軸のスループットは高いほど良い
- グラフ上のドットは、拡散モデルのステップ数
- ステップ数を増やせば生成画質の品質は上がるが、スループットは遅くなる
- 生成画質とスループットを両立させるには、解像度を下げたほうが良い
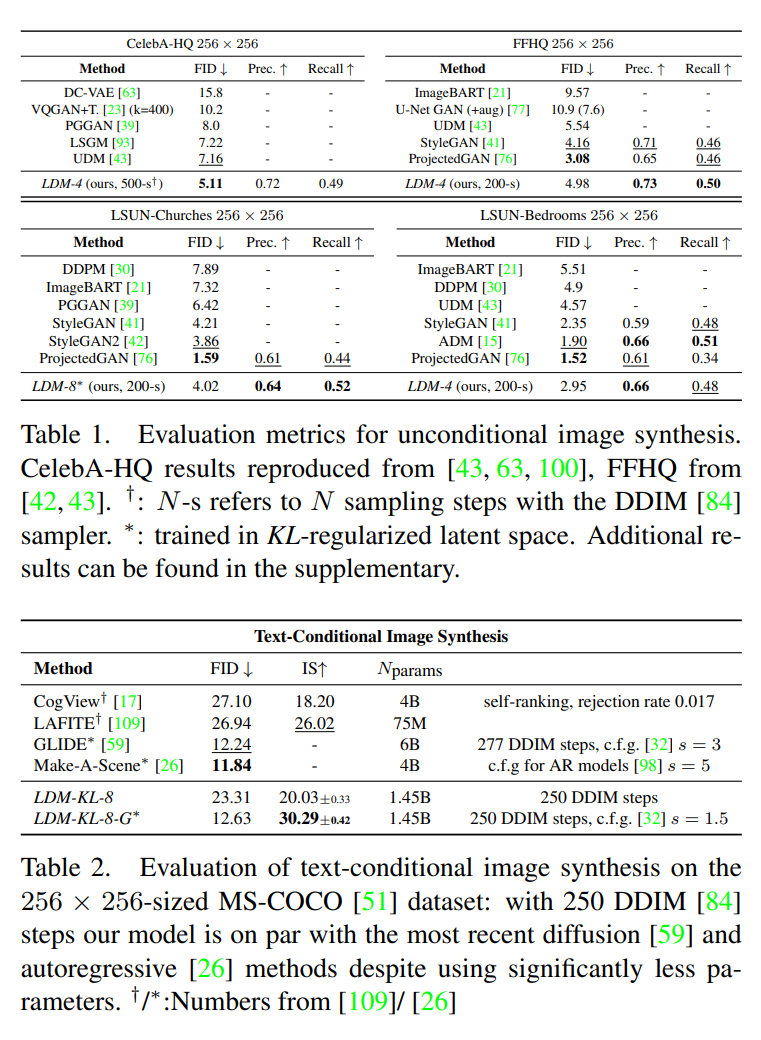
- Unconditional Synthesisでは、FIDベースでStyleGAN~StyleGAN2と同程度
- Text-Conditional Synthesisでは、FIDベースでGLIDEと同程度を、それぞれ軽量化して実装可能になった(係数が1/4)
超解像モデルとして
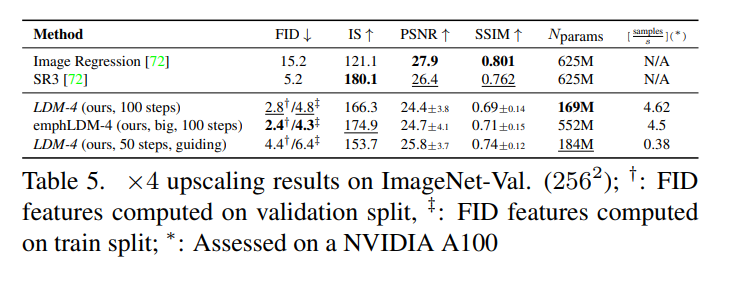
Latent Diffusionでは、Image to imageができるため、入力画像を低解像度の画像とすれば超解像が可能。これで訓練したところ、SR3のような超解像専用のモデルに匹敵する性能となった。
Inpaintingのモデルとして
LaMaやEdge ConnectのようなGANベースのInpaintingモデルよりも優秀な結果となった


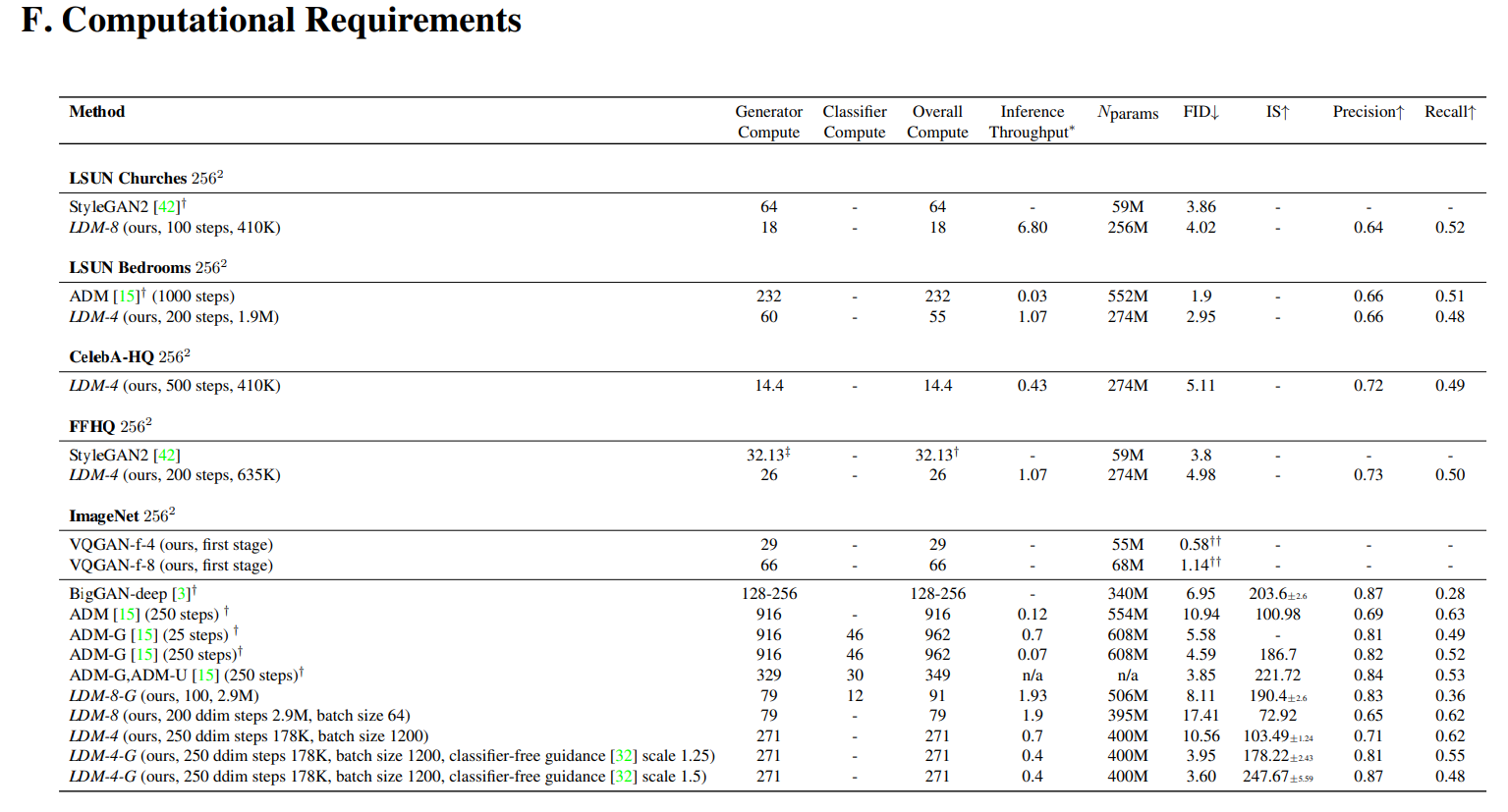
計算量
まとめと感想
- 主張としては、「次元削減してオートエンコーダの拡散モデルにしたら、生成品質損なわずに軽量化できたよ」というありがちなもの
- 最初に出たのが2021年12月なので、既存のモデルで使われている手法と近く、目新しさが少ないが、それだけ画像生成の進歩が速いのかもしれない
- 大きな貢献としては、個々の手法よりもStable DiffusionをOSSとして公開して民主化したという点ではないだろうか
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー