
論文まとめ:BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
Posted On 2023-02-02


- タイトル:BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
- 著者:Junnan Li, Dongxu Li, Silvio Savarese, Steven Hoi(Saleforce Research)
- 論文URL:https://arxiv.org/abs/2301.12597
- コード:https://github.com/salesforce/LAVIS/tree/main/projects/blip2
- HuggingFace:https://huggingface.co/spaces/taesiri/BLIP-2
目次
ざっくりいうと
- 視覚言語(V&L)モデルにおいて、事前学習コストを減らしつつ精度を出すための研究
- 事前訓練済みの画像モデル、大規模言語モデルをそのまま使い、「Q-Former」というモダリティアラインメント機構を導入することで、高いゼロショット転移能力や言語生成を維持
- Flamingo80Bより54倍少ない学習パラメーターで、SoTA性能を達成
概要
- 大規模モデルの訓練のため、Vision-Language(V&L)事前訓練がますます高コストになっているので、減らしたい
- 言語モデル、特に大規模言語モデル(LLM)は、強力な言語生成能力とゼロショット転移能力がある
- 事前学習中にLLMを凍結したい理由:破滅的忘却、計算コスト
- ユニモーダルなモデルを、V&L事前学習に活用するには、クロスモーダルアライメントの促進が重要
- LLMは画像を見ていないため、V&Lのアライメントが困難
- 既存の手法(FrozenやFlamingo)はテキスト生成の損失関数に頼っていて、アラインメント機能が不十分
- BLIP-2では、このアラインメントを取るためにクエリ変換器(Q-Former)を提唱
- 画像エンコーダーとLLMの渡しの役割のボトルネックモジュール。両者間の表現のギャップを埋めたい
- Q-Formerは学習可能なクエリベクトル群
- 学習するのはQ-Formerの部分
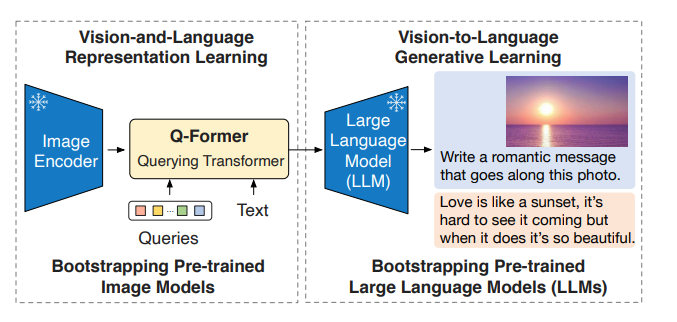
- BLIP-2は、事前学習済みの画像エンコーダーと、固定の大規模言語モデルからV&Lのブートストラップすることで事前学習を効率化。2段階からなる
- 1段階目:固定の画像エンコーダーから、V&Lの表現をブートストラップ
- 2段階目:固定の言語モデルから、画像→言語の生成をブートストラップで学習
- 既存の手法より、学習パラメーターが著しく少ないが、様々なV&LタスクでSoTA。
- ゼロショットVQAv2では、Flamingo80Bより、54倍少ない学習パラメーターで、8.7%上回る性能
- 言語の指示に従った、画像→テキストのゼロショット生成ができ、画像をインプットとした対話も可能

手法
Q-Formerの構造
Q-Formerは2つのサブモジュールからなる
- 画像変換器(左):画像エンコーダーと対話して視覚特徴抽出
- テキスト変換器(右):入力テキストをエンコードし、デコーターとして機能
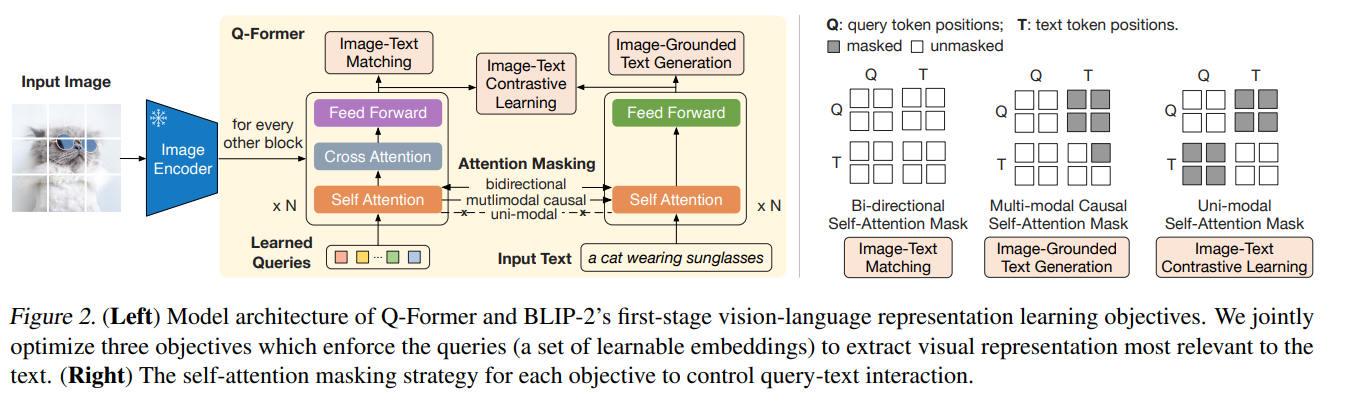
- Q-FormerはBERTbaseで188Mのパラメーターからなり、事前学習済みの係数で初期化
- Learned Queriesの部分は、画像エンコーダーの特徴量をボトルネックにする構造
- 例:ViT-L/14が257×1024の特徴 → Q-FormerのクエリZが32×768
- お気持ち:テキストに最も関連する視覚情報をクエリに抽出させたい
3つのマッチング戦略(図の右)ごとに、異なるSelf-Attention Maskを使う
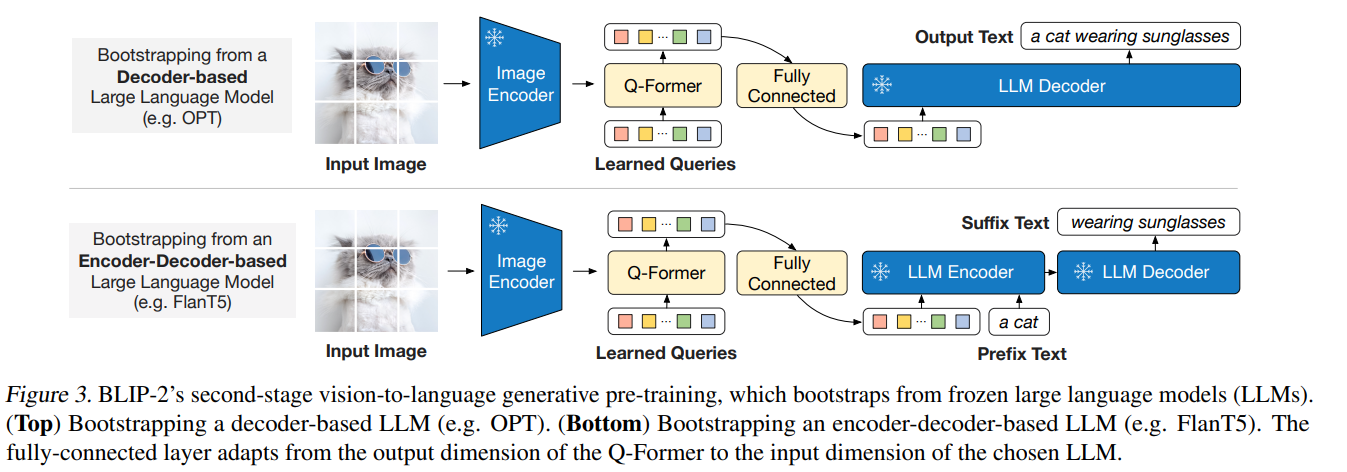
- モデル全体図としては、Q-FormerをLLMにFC層を通じて接続する
- FC層:クエリの埋め込み→LLMのテキスト埋め込みへの投射
- LLMがいい感じに出力するための、プロンプトの最適化
学習方法
(少ししか記述がなく、モデルの二段階と学習の二段階が同じ「stage」と表現されているため、若干わかりづらい)
- 学習の1段階目
- Q-Formerの出力を、テキストの表現に最も一致させるように学習
- (私の勝手な想像)Q-FormerのContrastive Learningだけやる
- 学習の2段階目
- LLMをつなげてテキスト生成させて学習
事前学習のデータセット
- 全部で1.29億枚
- ほとんどがLAION400Mからで1.15億枚
- COCOやCC3M、CC12Mなども使用
学習リソース
- 学習ステップ数:1段階目が250kステップ、2段階目が80kステップ
- ViT-G+FlanT5-XXLで、40GBのA100が16枚で、1段階目が6日以内、2段階目が3日以内
- この手のモデルにしては学習コストは軽い
結果
学習パラメーターが少なく、SoTAだった。Flamingoとの比較がわかりやすい
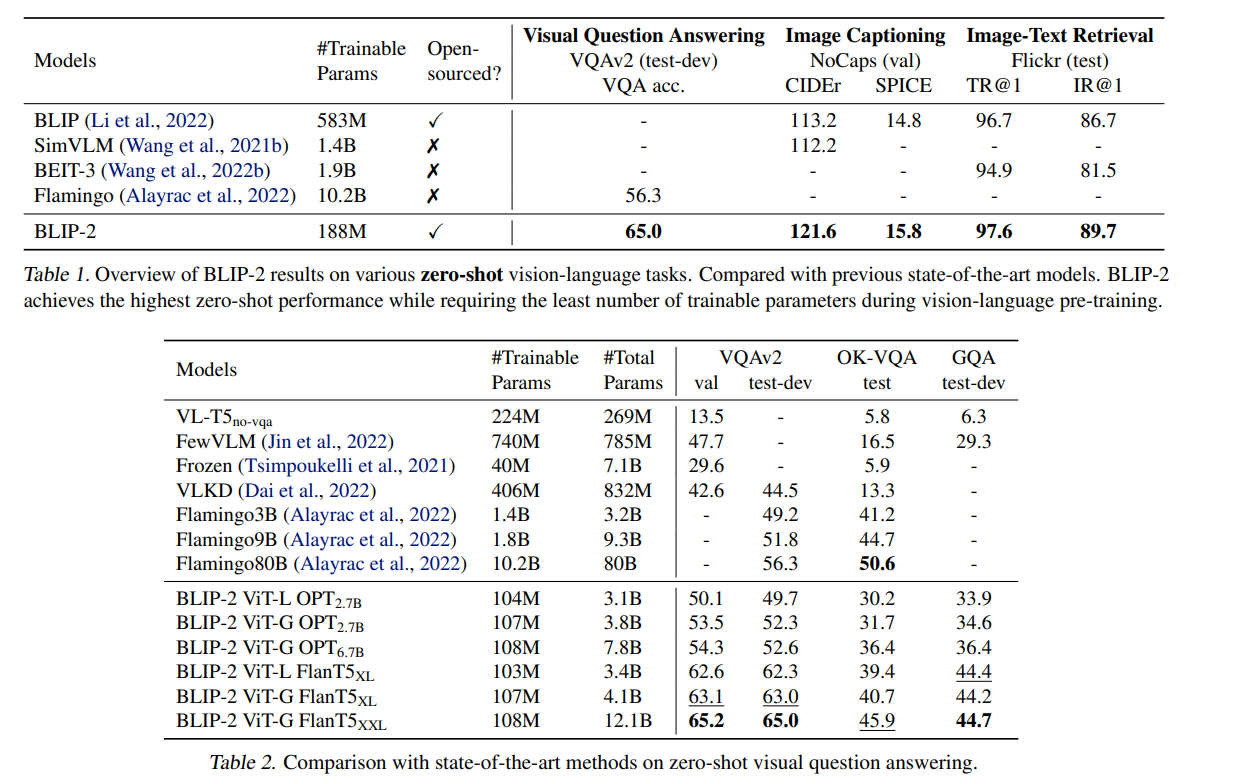
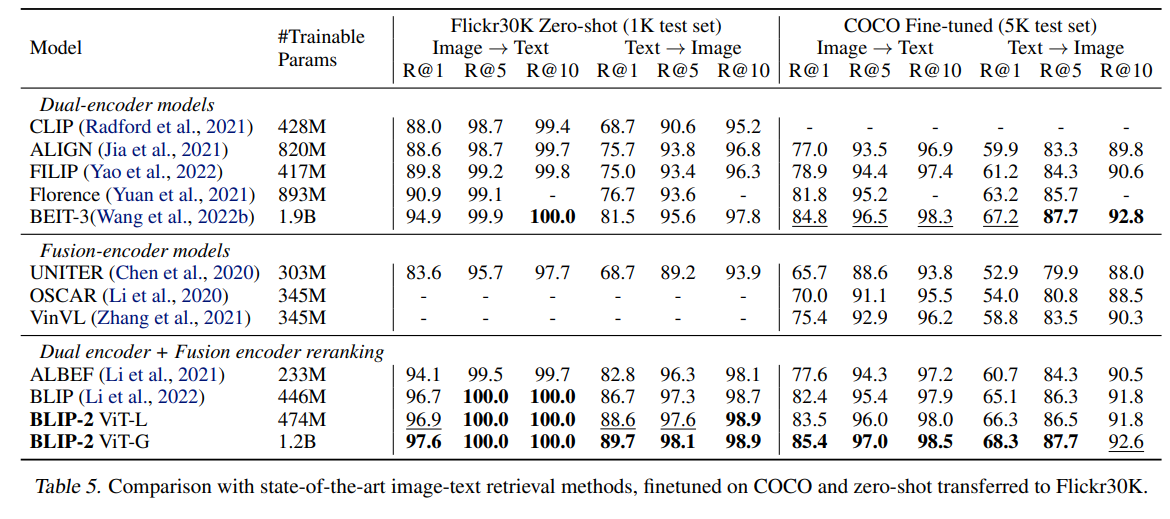
画像-テキストの検索タスクの結果。Flicker 30KのZeroshotでTop1で97.6%はすごい。CLIP派生のモデル(ALIGNやFlorenceなど)とくらべて、Text→Imageの検索が急速によくなっている
使ってみた所感
- Saleforceがいい感じのライブラリを作っているので、とても簡単に使えて便利。モデルを公開してくれて商用利用もできるのが◎
- (最近のモデル特有だが)非常にメモリがいる
- FlanT5-XXLのモデルの場合、メモリ64GBでギリギリ
- 推論も時間かかり、16vCPUのインスタンスでCPU、1サンプル6分程度かかることもある(おそらくトークンの長さ次第)
- 時間気にしないでやるなら良さそう。GPUで使うのはVRAM確保が大変そう
- 最大モデルで、ChatGPTのようなリアルタイムな対話生成は(ご家庭にあるような環境だと)まだ厳しそう
- HuggingFaceのデモがT4で動いているので、OPT2.7Bぐらいに絞れば行けそう
- (BLIPからできるが)マルチモーダルな特徴抽出ができるため、これが面白そう
- https://github.com/salesforce/LAVIS#unified-feature-extraction-interface
- 23/2/2現在できるのは、ALBEFとBLIPだけでBLIP-2ではできないらしい
所感
- (この手のV&L Grounding系は理解が難しい論文が多いが)、「Q-Formerの部分だけ学習させる」がメインで発想は単純
- 訓練コストは(ご家庭にあるGPUレベル基準だと)多いのか少ないのかわからないが、この手のモデルにしては訓練コストが少ない。使うときはデプロイ周りがちょっと大変そう
- ツヨツヨ訓練済みLLMを使えるのは強い。当たり前のようにFlanT5を使っていたのが驚いた
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー
One Comment