
論文まとめ:EVA-02: A Visual Representation for Neon Genesis


- タイトル:EVA-02: A Visual Representation for Neon Genesis
- 著者:Yuxin Fang, Quan Sun, Xinggang Wang, Tiejun Huang, Xinlong Wang, Yue Cao
- 論文URL:https://arxiv.org/abs/2303.11331
- コード:https://github.com/baaivision/EVA/tree/master/EVA-02
目次
ざっくりいうと
- MIMのターゲットをCLIPし、大規模な画像の事前訓練を追加データなしで可能にしたEVAの後継版
- NLPで導入されていたTransformerのアーキテクチャー改善を、画像の観点から導入
- MIMとCLIPの相互訓練により、EVA-01より少量のパラメーター・データで高精度を達成
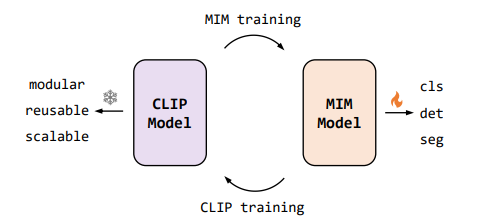
EVA-01との違い
- 小型のプレーンViTにフォーカスした
- NLPで使われているTransformerのアーキテクチャーの改善を、画像の側面から検討し、精度向上に導入した
- SwiGLU、sub-LN、RoPEの3点
- MIMのターゲットをEVA-01から作られたCLIPとした
- その結果、少ないパラメーター・少ないデータで、EVA-01を上回る下流タスク/ゼロショットの性能を報告
手法
プレーンViTのアーキテクチャーの改善
- 言語モデルのいくつかの重要なアーキテクチャーの進歩は、画像の表現学習の文脈からは検討されていなかった。これを取り込んでプレーンViTのブロック内の構造を改善する
- シグモイド線形ユニット(SiLU)/ スウィッチ活性化を持つゲート線形ユニット(SwiGLU)
- Normalizationレイヤーとしての正規化層としてsub-LN
- 2次元回転埋め込みのRoPE
SwiGLU
NLPの研究から。GLUの一種。GLUのシグモイドをSwishに置き換えたもの。元論文、PapersWithCode
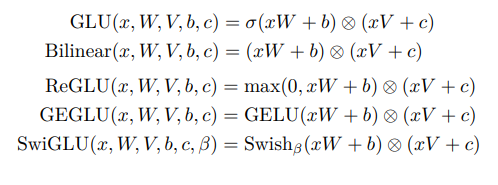
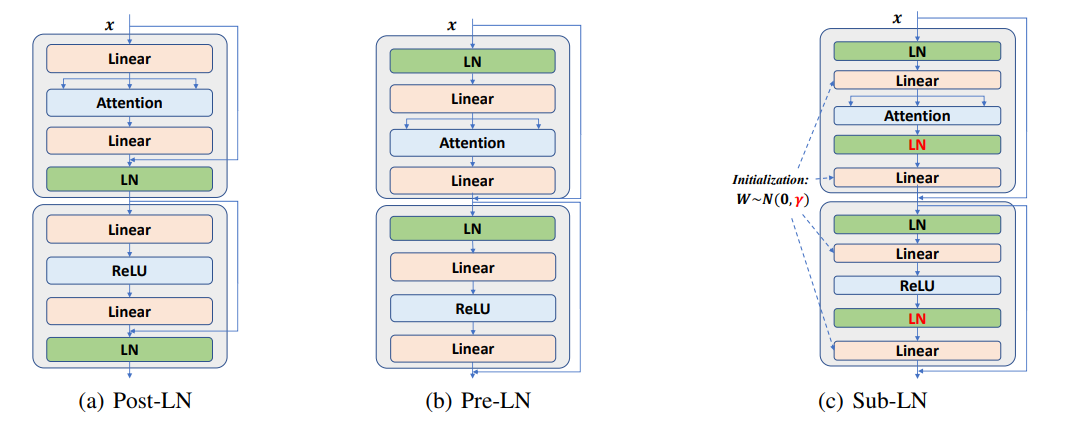
Sub-LN
NLPの研究から。従来のLayer NormはAttentionの前後どちらかに入れていたが、両方に入れ初期化を工夫することで性能向上。元論文
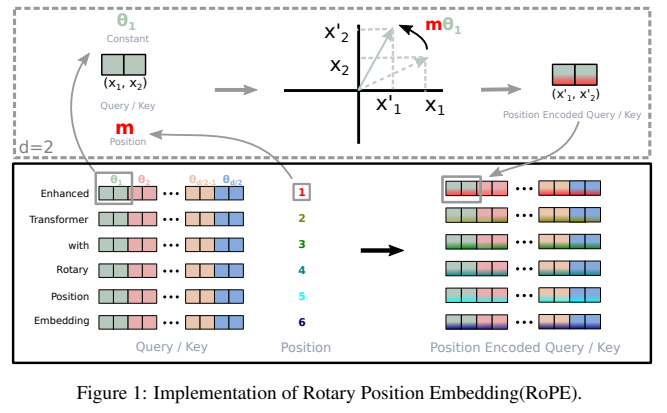
RoPE
NLPの研究から。Positinal Encodingに回転行列の要素を適用。元論文
これらのアーキテクチャーをViTに取り込んだ結果
ImageNet1Kのファンチューニング精度が上がった。ベースラインはEVA-01のCLIP
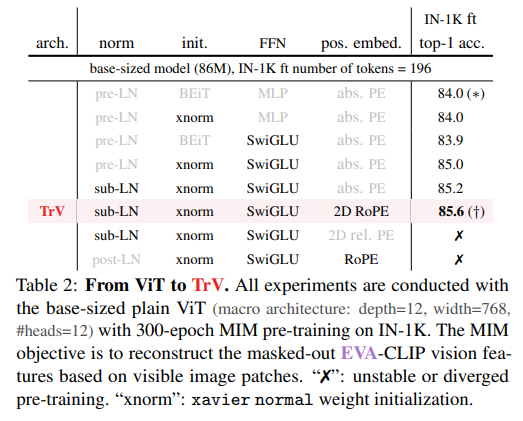
- SwiGLUは重みがランダム初期化だと平凡だが、xavier normalの初期化だとうまくいく(+1.1)
- Sub-LNはPre-LNと比較してわずかにきく(+0.2)
- 2D-RoPEは性能向上するが(+0.4)、普通のRoPEだと学習が不安定化
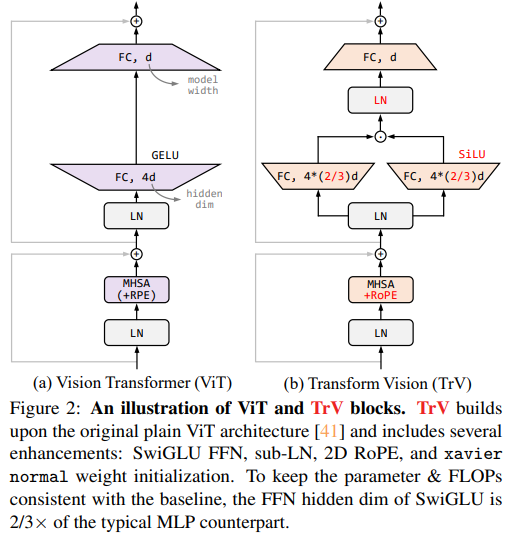
アーキテクチャーの変化。TrV(Transformer Vision)が提案の構造
事前学習の戦略
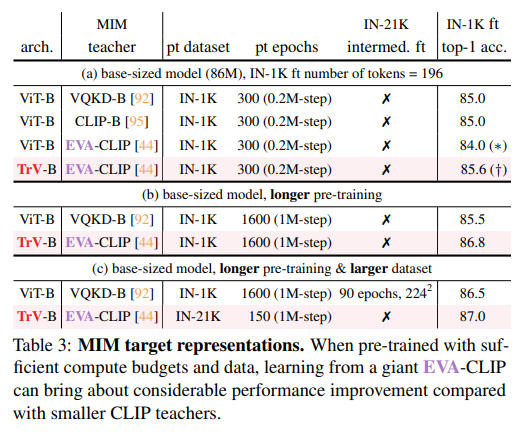
- EVA-01では、事前学習のMIMのターゲットとして既存のCLIPを使用していた
- EVA-02のMIMでは、1Bパラメーターで訓練されたEVA-01をベースとしたCLIPをMIMのターゲットとしている
- EVA-01のCLIPベースでは、短時間の訓練では既存のCLIPに劣るが、訓練時間を長くすることで精度がスケールする。また事前学習のデータセットが大きくなったときにもスケールする
- MIMはStudent-Teacherモデルとしても考えられる
- 短時間の訓練で劣るのは、EVA-01で学習された表現が複雑になって、Student側が特徴を捉えづらくなったため
- VQKD-Bという小さなモデルでは必要だった中間のファインチューニングも不要になった
様々なモデルサイズがある(たった6Mのもある)。MIMの事前訓練データはL以外はIN21Kで訓練。Merged-38Mは(CC12M、CC3M、COCOなどを統合し、CCについてはキャプションのないデータのみ使用。EVA-01と一緒)

Lは1Bパラメーターだが、実装でFP16やxFormersを使用しており、BEiTよりも訓練時間は~10%短い。
結果
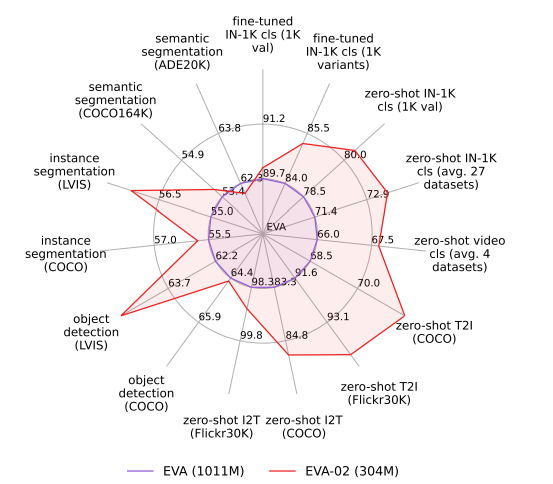
下流タスクの精度
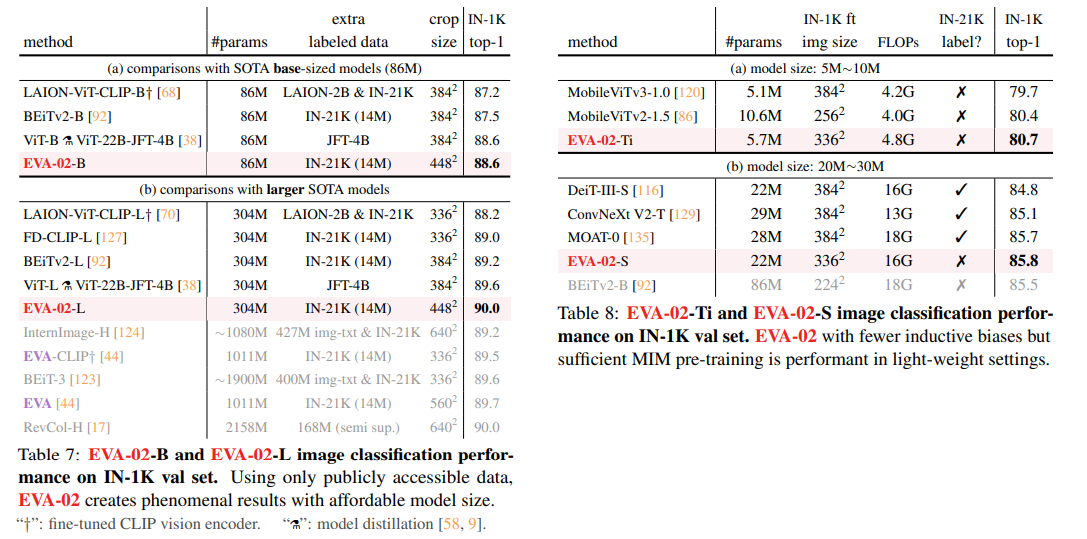
EVA-01ではパラメーター1BでImageNet 1Kのファインチューニング精度が89.7%だったのに対し、EVA02-Lでは1/3のパラメーターでファインチューニング精度90.0%になった。MIMとCLIPのよる蒸留の繰り返しの有効性が示される
CLIPの精度向上
EVA-02をベースにCLIPを作ると、EVA-01のCLIPよりも良くなった。
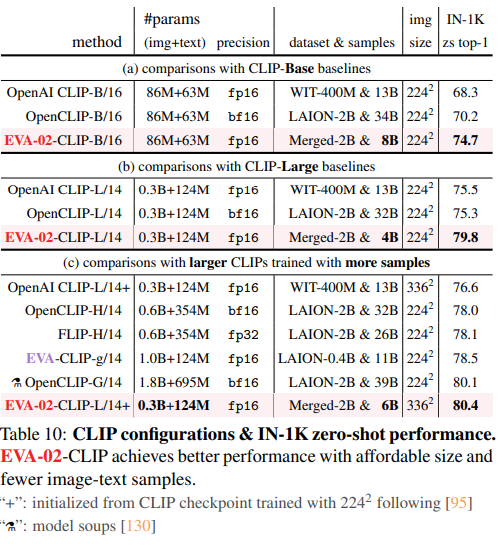
EVA-CLIPと比較して
- ゼロショット精度は+1.9%
- 画像のパラメーターは1/3
- データ数は半分
上が小さなモデルでの比較。OpenAIのCLIPよりも総じて良い。下が大きなモデルでの比較。ImageNet系が特に強い。一部強さがまちまちなのがある(おそらく訓練データセットによるもの)

検出系
EVA-02が特徴抽出気として強いため、物体検出やセグメンテーションでも優位な性能を出した。
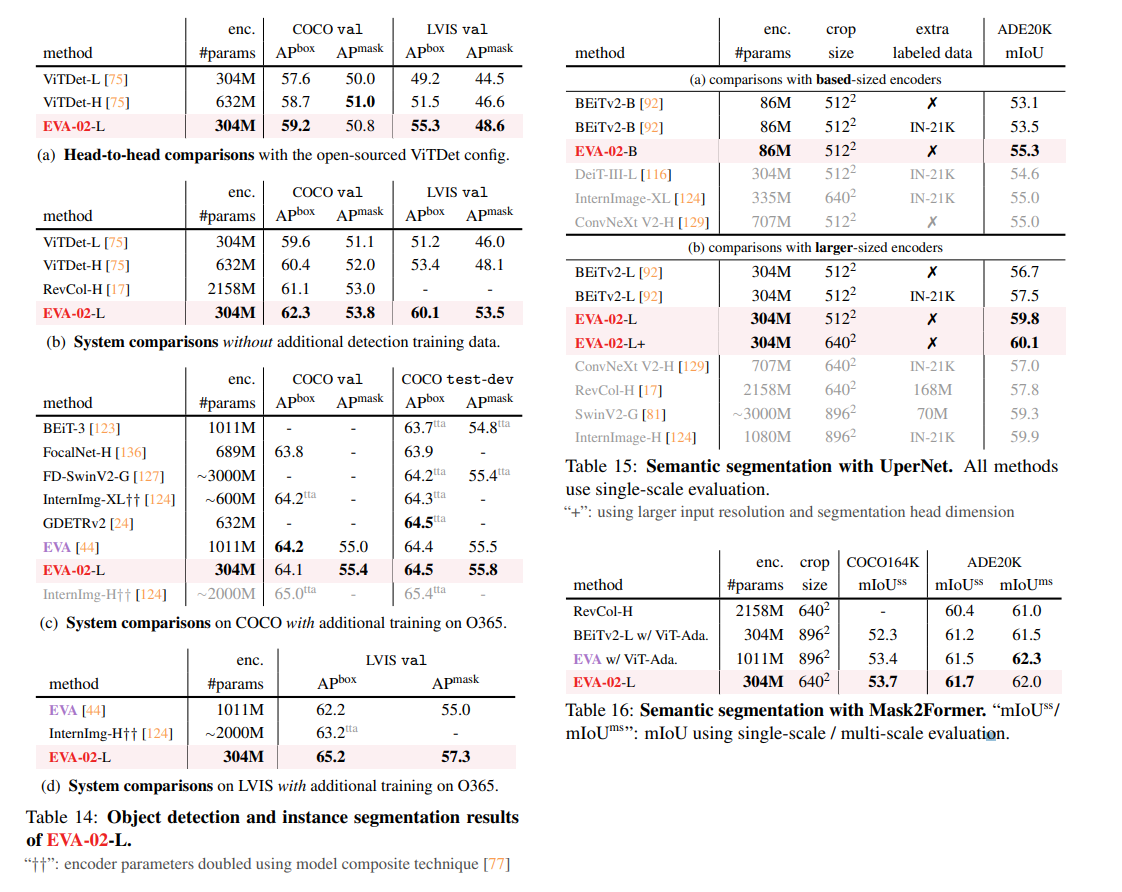
結論
- MIMとCLIPの交互学習が、ブートストラップ方式でMIMとCLIPの両方の性能を改善できることを実証
- Visionと、Vision & Languageの両方を事前訓練として有望でスケーラブルなアプローチ
所感
- 今度は2号機カラー
- 相変わらずモデル公開してくれているのがいい
- Fight together with Asukaと書いてあるが、この論文でのAsukaってなんだろう(名前こじつけてモジュール作るのかと思ってた)

Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー