
Python(Numpy)で画像を水平反転する方法:Data Augmentation向け


OpenCVを使わずに単純に画像を左右反転(水平反転)する方法を考えます。ディープラーニングでデータのジェネレーターを自分で実装した場合、Data Augmentationを組み込む際にも必要になります。それを見ていきましょう。
目次
左右反転自体は実は簡単
例えばNumpyの行列を左右反転させてみましょう。実はこれだけでOKです。
>>> x = np.arange(16).reshape(4,4)
>>> x
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15]])
>>> x[:, ::-1]
array([[ 3, 2, 1, 0],
[ 7, 6, 5, 4],
[11, 10, 9, 8],
[15, 14, 13, 12]])
スライス記法の「::-1」が反転を示すので、反転したい軸でこれを使えばいいだけです。ただし物体検出などでは、付随するラベルを注意深く変換しないといけないのでそこが注意が必要です。
具体例を見てみましょう。猫の画像をcat.jpgとして用意しました。かわいいですね。

これを左右反転してみます。読み込みのときだけPillowのライブラリを使っていますがそれ以外はNumpyでできます。
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
if __name__ == "__main__":
img = np.asarray(Image.open("cat.jpg"), dtype=np.uint8)
img = img[:, ::-1, :]
plt.imshow(img)
plt.savefig("cat_reverse.jpg")
まずは読み込んでNumpy配列に変換し、このNumpy配列が「y, x, color」の順で記録されているので、x軸について反転させ、あとはpyplotで表示させているだけです。

結果はこのようになります。左右反転できていますね。
アノテーションや境界箱(Bounding Box)の変換を忘れずに
特に物体検出などで必要になるのですが、画像を左右反転するだけではなくてラベルのほうも変換する必要があります。アノテーションというのは例えば顔のランドマーク検出だったら、目の位置や口の位置の座標。境界箱(Bounding Box)というのは、物体検出のここに何があるという領域(よく四角で囲まれるやつ)ですね。ここでは境界箱の例で説明します。
いま座標系を左上を(0, 0)として右下を(1, 1)としましょう。先程の猫の画像に、(x, y)の順で左上=(0.3, 0.1)、右下=(0.8, 0.95)なる境界箱を合成してみます。以下のコードです。
def draw_bbox(image_array, bbox, lwd=5):
assert image_array.dtype == np.uint8
assert min(bbox) >= 0.0 and max(bbox) <= 1.0
assert len(bbox) == 4
height, width = image_array.shape[0], image_array.shape[1]
sx, sy, ex, ey = bbox
sx, ex = int(sx*width), int(ex*width)
sy, ey = int(sy*height), int(ey*height)
img = np.copy(image_array)
filter = np.zeros(image_array.shape, dtype=np.bool)
filter[sy:(ey+lwd), sx:(ex+lwd), 0] = True
filter[(sy+lwd):ey, (sx+lwd):ex, 0] = False
img[filter] = 255 # red
return img
if __name__ == "__main__":
img = np.asarray(Image.open("cat.jpg"), dtype=np.uint8)
bbox = [0.3, 0.1, 0.8, 0.95]
merged_img = draw_bbox(img, bbox)
plt.imshow(merged_img)
plt.show()
draw_bboxの関数の前半は0~1の座標系を、幅と高さから元の座標系に戻している操作。後半は四角形を描画するための処理です。Pillowとかでも書けますがせっかくなのでNumpyだけで書きました。後半は説明のためのコードなので気にしなくていいです。
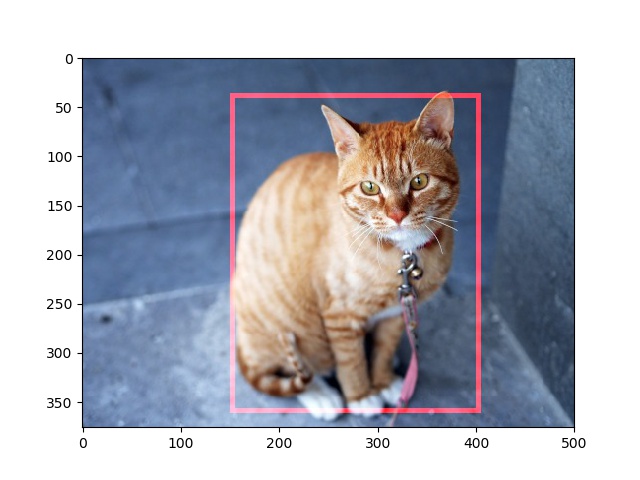
このように合成できました。さてここからがポイント。今この境界箱を書くのに指定したのは、左上と右下の座標(2点×xy=4つのパラメーター)です。左上と右下の点を水平反転するとどの座標に移動するかわかりますか?
ぱっと思い浮かぶのは、左上と右下のx座標を1から引く方法。確かにこれだと反転はします。自分もしばらくこれだけでいいと勘違いしてたのですが、x座標を1から引くだけでは半分正解で半分不正解です。実はまだあります。よく考えてください。
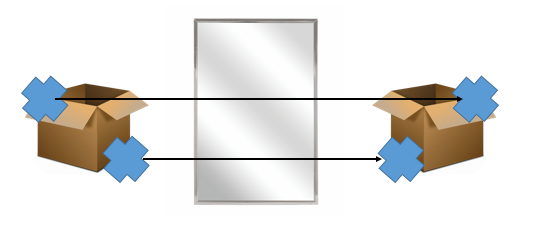
水平反転とは画像の右に鏡を置いてその鏡像を取り出すのと同じなので、元の画像の左上の点は鏡の中では右上に、元の画像の右下の点は鏡の中では左下に移動します。つまり、座標という数値上の変換だけではなく、どこがどこに移動するかそれに伴ってアノテーションはどうかわるのかという意味上の変換も必要です。例えばランドマーク検出だったら、左目の点は右目の点に、右目の点は左目の点にラベルをスワップさせてあげないといけません。そこを忘れないでください。
さてそれを加味すると、境界箱の水平反転を含めた画像の変換は次のようになります。
def horizontal_flip(img_array, bbox):
assert min(bbox) >= 0.0 and max(bbox) <= 1.0
assert len(bbox) == 4
flipped_image = img_array[:, ::-1, :]
flipped_bbox = [1-bbox[2], bbox[1], 1-bbox[0], bbox[3]]
return flipped_image, flipped_bbox
境界箱の場合は、x座標を1から引くだけではなく、左上と右下のx座標を入れ替えるのが正解です。これをプロットすると次のようになります。
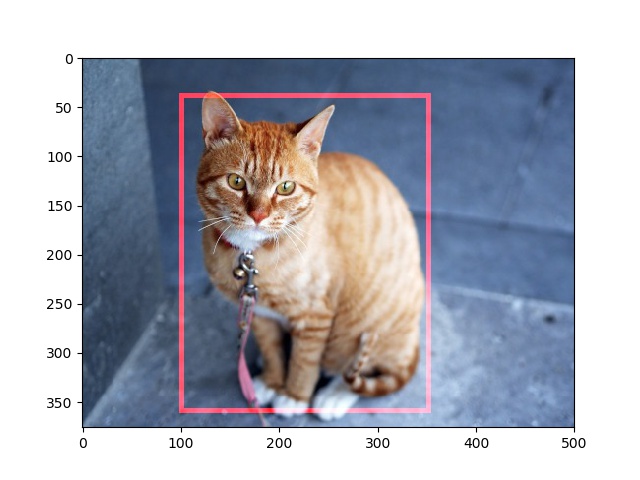
これで良いですね。
Data Augmentationでの水平反転(Horizontal flip)
最後にディープラーニングでの画像の反転に意味づけについて補足しておきます。英語ではHorizontal flipなどと呼ばれる手法で、ディープラーニングにおける典型的なData Augmentationの方法です。訓練時のみ使い、50%の確率で左右反転する方法です。
水平反転はよく使いますが垂直反転はあまり使いません。左を向いた猫と右を向いた猫はよく見ても、上下逆さまの猫はまず見ないですからね。
さて、この乱数部分ですが、numpyではなく組み込みのrandomライブラリを使うのがスマートそうです。random.random()で0~1の乱数が1個出てくるので0.5より大きいか小さいかで判定できます。
import random
def random_horizontal_flip(img_array, bbox):
if random.random() > 0.5:
return horizontal_flip(img_array, bbox)
else:
return img_array, bbox
とてもスマートに実装できますね。呼び出し部分です。
if __name__ == "__main__":
img = np.asarray(Image.open("cat.jpg"), dtype=np.uint8)
bbox = [0.3, 0.1, 0.8, 0.95]
img, bbox = random_horizontal_flip(img, bbox)
merged_img = draw_bbox(img, bbox)
plt.imshow(merged_img)
plt.show()
文字通り乱数なので、実行したタイミングによって結果が変わると思います。何回か実行してみてください。
まとめ
まとめます。
- 画像の反転は、反転したい軸を「::-1」というスライス記法で簡単に反転できる。単体の画像のNumpy配列の場合は、「y, x, c」という構成なので、2番目の軸を反転すると水平反転になる。
- 物体検出やランドマークの場合、アノテーションの変換をお忘れずに。1からx座標を引くという数値上の変換だけではなく、どのアノテーションがどこに移動するのかという意味上の変換がポイント。
以上です。アノテーションの変換はなかなか忘れがちなポイントですが、面倒でも一度簡単な例に落とし込んで試してみるとデバッグが捗ると思います。
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー