
論文まとめ:Large Language Models are Zero-Shot Reasoners
Posted On 2022-12-01


- タイトル:Large Language Models are Zero-Shot Reasoners
- 著者:Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, Yusuke Iwasawa
- 所属:東京大学、Google Research
- カンファ:NeurIPS 2022
- 論文URL:https://arxiv.org/abs/2205.11916
- コード:https://github.com/kojima-takeshi188/zero_shot_cot
目次
ざっくりいうと
- 大規模言語モデル(LLM)で算術問題などを解くための連鎖的なプロンプト「Zero-shot-CoT」を提唱
- GPT-3に「ステップバイステップで考えよう」を追加するだけで、MultiArithのゼロショット精度が17.7%→78.7%でSoTA
- LLMに隠された高レベルでマルチタスクの認知能力を引き出すことができる

- (a): GPT-3の通常のFew-shot(Brown et al., 2020)
- (b): 標準的な質問と回答の例ではなく、ステップバイステップの推論例をLLMに与える思考連鎖プロンプティング(CoT)を提案(Wei et al., 2022)
- (c):通常のZero-shot
- (d):Zero-shot-CoTは、例題(few-shot)またはテンプレート(zero-shot)の形で先行するタスク固有のプロンプトエンジニアリングと異なり、汎用的でタスクにとらわれない
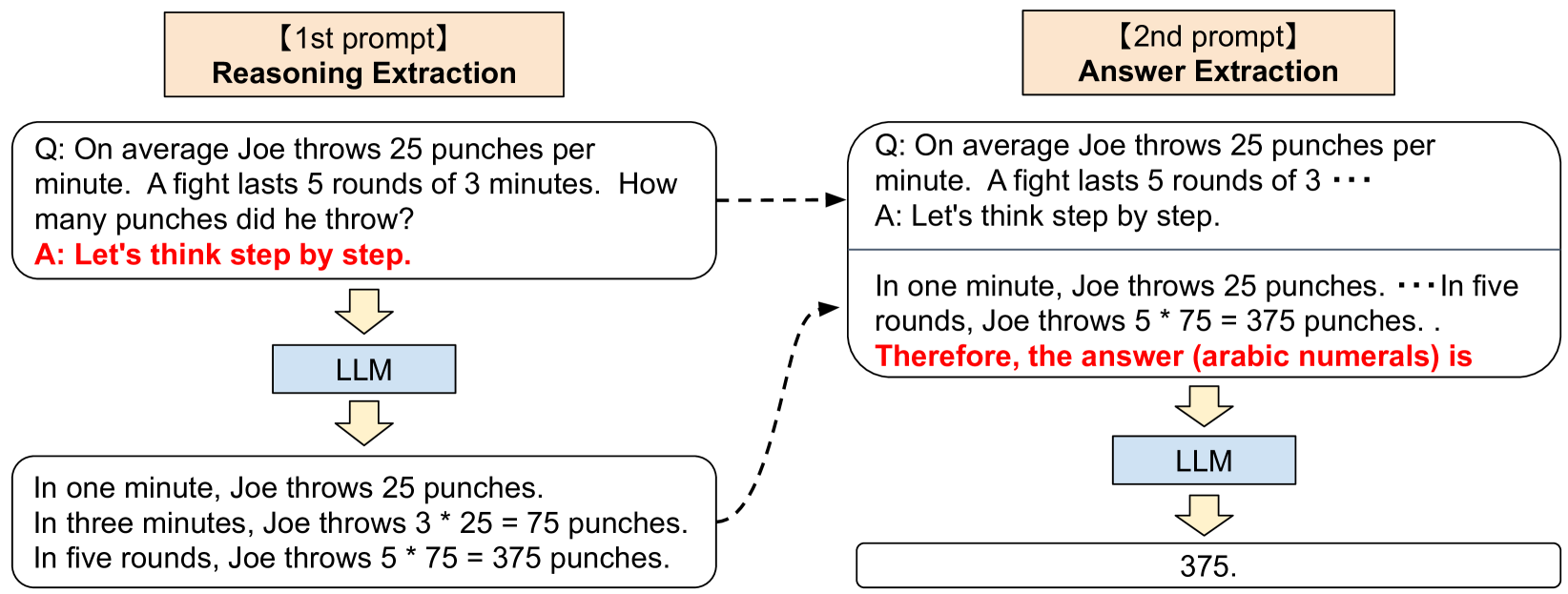
Zero-shot Chain of Thought(Zero-shot CoT)
- Zero-shot-CoTは単純だが、二段構えのプロンプトを使っている点が巧妙
- 1段階目では「推論抽出」
- 2段階目では「回答抽出」
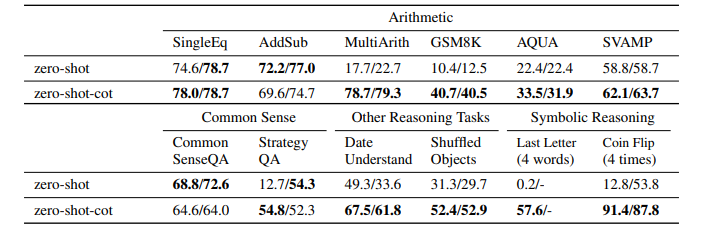
結果
データセット
- 算術推論
- SingleEq、AddSub:多段階の計算を必要としない簡単な問題
- MultiArith、AQUA-RAT、GSM8k、SVAMP:解くために多段階の推論が必要な高難易度データセット
- コモンセンス推論
- CommonsenseQA:事前知識に基づく推論が必要な複雑なセマンティクスを持つ質問
- StrategyQA:質問に答えるための暗黙のマルチホップ推論が必要
- 記号推論
- Last letter Concatenation:各単語の最後の文字を連結する
- Coin flip:コインをひっくり返した/ひっくり返さなかった後、コインがまだ表であるかどうか
- 人間には簡単だが、言語モデルでは平坦なスケーリングカーブとなる
モデル
特に断りなければGPT-3のTextdavinci-002 (175B)を使用
定量評価
多段階推論が必要なタスクで特に性能向上が著しい
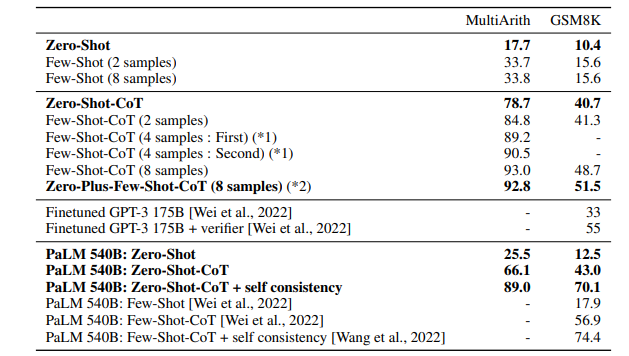
Zero-Shot-CoTの時点で、Finetuneを超える。Few-shotな設定にするとより精度が上がる。
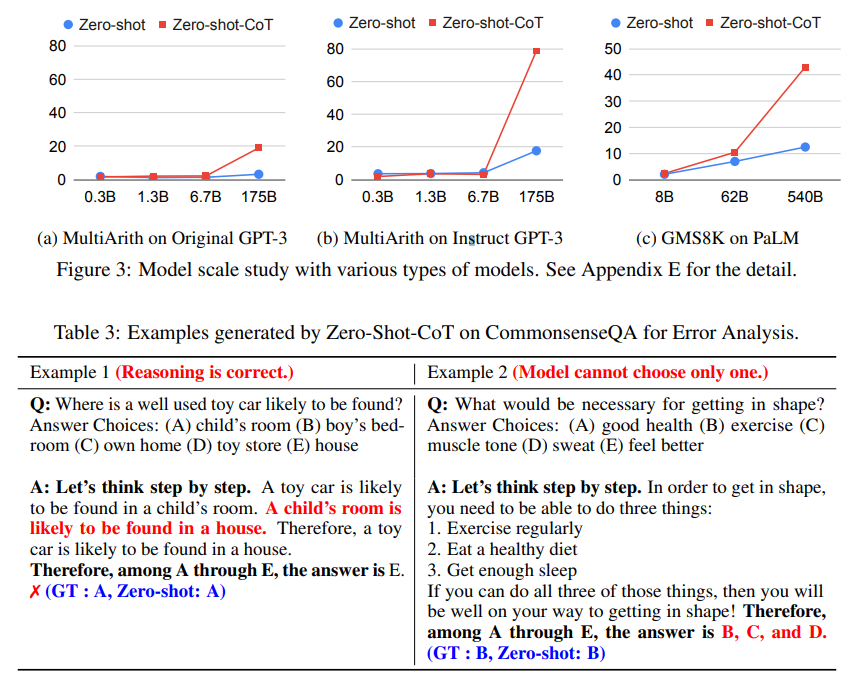
モデルを大きくすると急激に性能が向上する
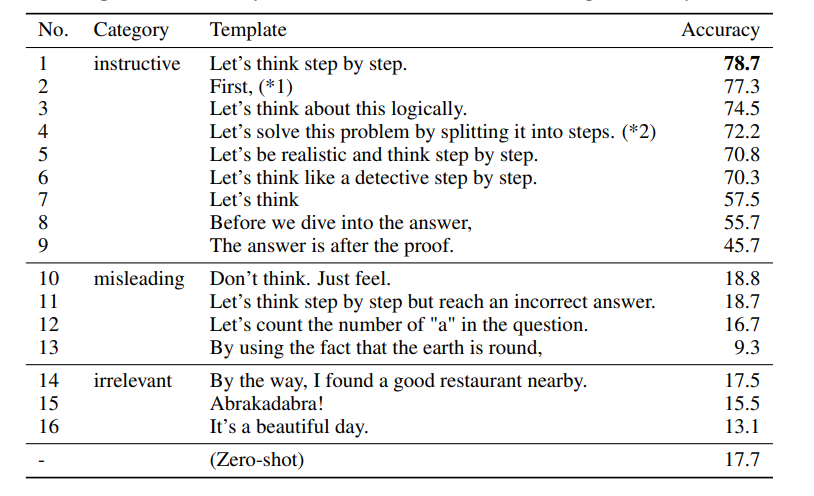
プロンプトをいろいろ試したところ「Let’s think step by step」が最も良かった
主張
- 連鎖的にプロンプトを入れるケースは先行研究でもあったが「Xの定義はなにか」のようなタスク固有のプロンプトであった。提案手法はタスク固有ではなく汎用的なプロンプトであり、時間のかかるファインチューニングやサンプルエンジニアリングを必要としない
- 提案手法はマルチタスクプロンプトであり、LLMの「広い汎化」あるいは広い認知能力を引き出すもの。我々の研究が、LLMを用いた論理推論研究のみならず、LLMの持つ他の幅広い認知能力の発見を加速させるための参考となることを期待
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー