
ColabのTPUでNASNet Largeを訓練しようとして失敗した話


ColabのTPUはとてもメモリ容量が大きく、計算が速いのでモデルのパラメーターを多くしてもそこまでメモリオーバーor遅くなりません。ただし、あまりにモデルが深すぎると訓練の初期設定で失敗することがあります。NASNet Largeを訓練しようとして発生しました。これを見ていきます。
目次
CIFAR-10を5万枚1バッチで処理できる驚異の容量
Qiitaの記事が予想以上の反響で驚きましたが、実際TPUのメモリ性能は凄まじいです。Qiitaの記事の表の再掲になりますが、AlexNet(全結合層なし)でCIFAR-10を分類してみると、GPUとの差は歴然です。
| batch_size | TPU (s/epoch) | TPU (us/step) | GPU (s/epoch) | GPU (us/step) |
|---|---|---|---|---|
| 256 | 20 | 407 | 28 | 567 |
| 1,024 | 10 | 197 | 27 | 534 |
| 4,096 | 6 | 115 | OOM | OOM |
| 8,192 | 5 | 110 | OOM | OOM |
| 16,384 | 5 | 94 | OOM | OOM |
| 50,000 | 4 | 82 | OOM | OOM |
GPUは1バッチ4096枚でメモリーオーバー(OutOfMemory)してしまいましたが、TPUは一気に5万枚突っ込んでもピンピンしています。GPUはK80ですが、NVIDIAの中の人によるとGPU2基のうち半分のみ使っているそうです(1GPUあたり12GB)。
一方のColabのTPUはTPUv2を使っているそうです。

この画像は2018/9/27に行われたTensorFlow and Deep Learning Singaporeの発表資料より引用しました。
Colab版とは異なりますが、有料のColud版のTPUもありこちらは2017年に登場しました。これはCloud版のTPUv2について述べたものですが、Googleの発表資料によると、TPUv2のチップはコアと8GBメモリがそれぞれ2つから成る構成です。
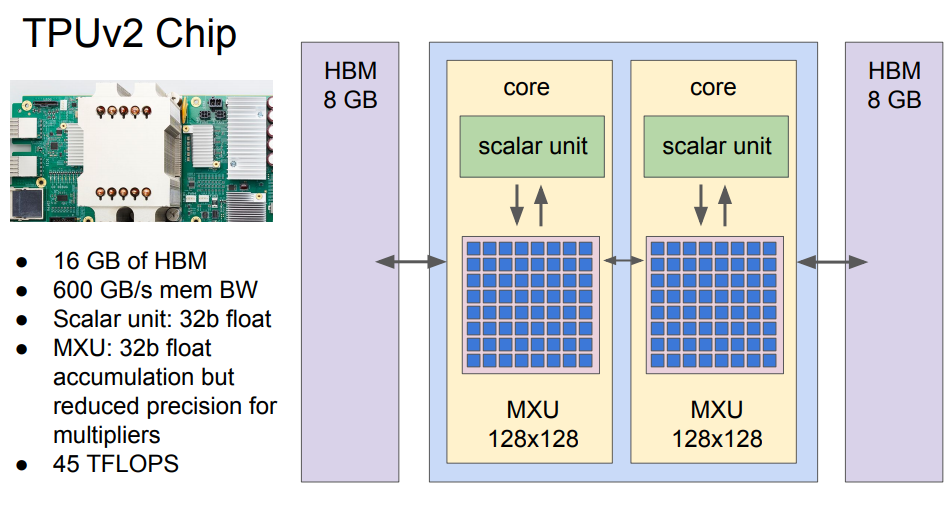
チップ1個で最大45TFlops出るそうです。そしてこのチップを4個つなげて1つのTPUv2のユニットとなります。

つまりこの発表資料にあるとおり、180TFlops、64GBのHBMメモリであると言えることができます。
正直こんなおばけ性能の計算ユニットが無料で使えるとはにわかには信じがたいのですが、「Colab版のHBMメモリが64GBあるのではないか?」と匂わせるようなエラーメッセージがありました。これはCIFAR-100を5万枚1バッチで入れてTPUのHBMメモリが溢れたときのエラーメッセージです。
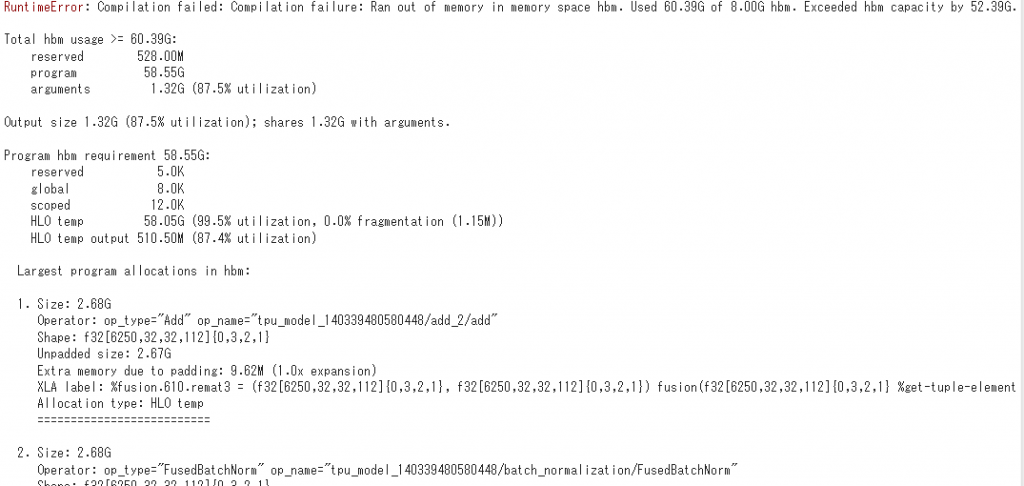
「Used xxG of 8.00G hbm」というメッセージから、1つのチップにあるHBMメモリのうちの1つが8GBであることを指しています。TPUでの計算はバッチを8分割してコアごとに均等に振り分けて計算します。例えば、バッチサイズが1024なら1コアあたり128サンプル計算するというわけです。TensorFlowのTPUのパフォーマンスガイドのページに載っていますが、「バッチサイズを128の倍数や8の倍数にしなさい」というのはこれが理由です。このエラーメッセージにも、5万個のサンプル8分割、つまり1コアあたり6250個(6250, 32, 32, 112)となっているのがわかります。
つまり、Colab版のエラーメッセージが1コアあたりのものであるから、1コアあたりHBMが8GBあり、全体でもTPUv2のユニットと同じ64GBのHBMメモリがあるのではないかと考えることができます。Colab版が8コアあるのは起動時のメッセージで出てくるので信用していいと思います。
しかし、180TFlopsという値はにわかには信じられませんね。以前使われていた有料のCloud版だったらそのぐらい出てもおかしくはないと思いますが、無料のColab版では何らかの制限がかかっていてもおかしくはないと思います。少なくとも精度も違うし構造も違うので、GPUのFlopsと同じ尺度で見れないことは確かですし、最初のAlexNetの例だと、同一バッチサイズでもColabのGPUのせいぜい2.5倍ぐらい、GPUのバッチサイズ256とTPUのバッチサイズ5万を比べて7倍ぐらい速い程度なので、仮に180TFlopsだったとしても、MAXの速度を出す条件というのは相当限られているなというのが正直な印象です。もしかするとTensorFlowのAPIを直接書くともっと速度が出るのかもしれませんね。
ちなみに現在Cloud版で使われているTPUv3は1ポッドあたりv2の8倍の100PFlops以上が出るそうです。ポッドあたりなので正確な比較ではないですが、こちらは金取っているのでColab版より速いというのはまあ当然でしょう。
TPUが有利になる条件を考える
さて、TPUが有利になる条件を考えましょう。とりあえず前回の実験からわかったことは、
- バッチサイズを大きくするとTPUは極端に速くなる。GPUでも同様だが、TPUのほうがより顕著に現れる。
- MLP(多層パーセプトロン)よりCNN(畳み込みニューラルネットワーク)のほうが、TPUの性能を活かしやすい
ということがわかりました。Googleが45TFlopsや180TFlopsなんて言うぐらいだから、とりあえずTPUの計算性能はむちゃくちゃ高性能であるという仮定をおきましょう。ただ実際性能を活かしきれなかったり、遅くなってしまうのは何らかのボトルネックがあると考えるべきです。ボトルネックというのがどこにあるかはわかりませんが、少なくとも次のようなことは言えるのではないでしょうか。
- 小さい画像のほうがVMのRAM/TPUのメモリに全部格納できて速そう
- パラメーターの多いCNNのほうが(CNNのパラメーター数と計算量はだいたい比例するので)、畳み込みの計算が支配的になってTPUの良さが生かされそう
ちなみにKerasの組み込みアプリケーションにパラメーター数8000万オーバーという特大ネットワークNASNet Largeがあります。ただ結論から言うと、TPUでの初期設定でハングアップしてしまいました。ちなみにGPUではバッチサイズ1024でもギリギリ訓練できました(本当ギリギリなので頻繁にOOMします)。以下その失敗例を書いていきます。
NASNet Large
NASNetとは、Googleによって、AutoMLを使って自動学習で作られたというネットワークです。元の論文。KerasにはNASNetが2種類組み込まれており、パラメーター数の少ないMobile版とパラメーター数の多いLarge版があります。ネットワークの構成はさておき、特筆すべきはLarge版のパラメーターの多さとモデルの深さです。まずはそれを確かめてみましょう。
from keras.applications import NASNetLarge
nasnet = NASNetLarge(input_shape=(32,32,3), include_top=False)
nasnet.summary()
print("NASNetLargeのレイヤー数", len(nasnet.layers))
転移学習用に全結合層は除外しました(include_top=False)。本来のNASNetLargeの入力解像度は(331, 331)ですが、最低縦横32以上の解像度から使える。つまり極端な話CIFARでも使えます。
Downloading data from https://github.com/fchollet/deep-learning-models/releases/download/v0.8/NASNet-large-no-top.h5
343613440/343608736 [==============================] - 3s 0us/step
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) (None, 32, 32, 3) 0
__________________________________________________________________________________________________
stem_conv1 (Conv2D) (None, 15, 15, 96) 2592 input_1[0][0]
__________________________________________________________________________________________________
#####
# 中略
#####
Total params: 84,916,818
Trainable params: 84,720,150
Non-trainable params: 196,668
__________________________________________________________________________________________________
NASNetLargeのレイヤー数 1019
あまりにも長すぎて途中省略してしまいましたが、パラメーター数84,916,818、レイヤー数1019という化物クラスのモデルです。係数だけで330MB近いというの末恐ろしい。全部見たければこちらにあるのでどうぞ。NASNetMobile版はこちら。
ちなみにもっとパラメーターが多いモデルとしてVGG16/19がありますが、これは係数の大部分が全結合層なので、転移学習として使うとかなり見掛け倒しな結果になります。
from keras.applications import VGG19
vgg19_withtop = VGG19(include_top=True)
vgg19_withtop.summary()
print("VGG19(全結合層あり)のレイヤー数", len(vgg19_withtop.layers))
print()
vgg19_notop = VGG19(include_top=False)
vgg19_notop.summary()
print("VGG19(全結合層なし)のレイヤー数", len(vgg19_notop.layers))
Total params: 143,667,240
Trainable params: 143,667,240
Non-trainable params: 0
_________________________________________________________________
VGG19(全結合層あり)のレイヤー数 26
Total params: 20,024,384
Trainable params: 20,024,384
Non-trainable params: 0
_________________________________________________________________
VGG19(全結合層なし)のレイヤー数 22
VGG19の1.43億のパラメーターが、全結合層を外したことで2000万まで減ってしまいましたね。転移学習の場合は通常全結合層を除外して新しく作り直すので、VGG19の実際のパラメーター数は20Mということになります。全結合層を外しても85M近くパラメーターがあるNASNet Largeのほうが段違いで多いです。
ぜひNASNet Largeで訓練したかったのだが、残念なことにあまりに深すぎてTPU版は初期設定に失敗してしまいました。実際に訓練しようとすると、このままハングアップし、2,3時間放置しても処理が進みません。
Epoch 1/50
INFO:tensorflow:New input shapes; (re-)compiling: mode=train, [TensorSpec(shape=(128, 32, 32, 3), dtype=tf.float32, name='input_10'), TensorSpec(shape=(128, 100), dtype=tf.float32, name='dense_target_10')]
INFO:tensorflow:Overriding default placeholder.
INFO:tensorflow:Remapping placeholder for input_1
INFO:tensorflow:Cloning Adam {'lr': 0.0010000000474974513, 'beta_1': 0.8999999761581421, 'beta_2': 0.9990000128746033, 'decay': 0.0, 'epsilon': 1e-07, 'amsgrad': False}
INFO:tensorflow:Get updates: Tensor("loss/mul:0", shape=(), dtype=float32)
INFO:tensorflow:Started compiling
INFO:tensorflow:Finished compiling. Time elapsed: 410.46163058280945 secs
INFO:tensorflow:Setting weights on TPU model.
こうなるとVM再起動するか、リセットするかしかなくなります。ちなみにColabのGPU版では、バッチサイズが1024でもNASNet Largeは訓練できました。ただ相当ギリギリで頻繁にOOM出します(以下は運良くOOM出なかったケースです)。こんだけ深いモデルをバッチサイズ1024で訓練できるというのはかなりすごい。
Using TensorFlow backend.
Epoch 1/3
50000/50000 [==============================] - 301s 6ms/step - loss: 4.3608 - acc: 0.0606
Epoch 2/3
50000/50000 [==============================] - 219s 4ms/step - loss: 2.7928 - acc: 0.3123
Epoch 3/3
50000/50000 [==============================] - 219s 4ms/step - loss: 1.8328 - acc: 0.5046
まとめ
TPUではパラメーターが多いケースのほうが、計算処理が支配的になってより速さが生かされそうですが、NASNet Largeのようにレイヤー数1000オーバーというあまりに深いモデルでは、TPUが重みの初期設定に失敗してハングアップすることがあります。なので、この後パラメーターが多くて浅めのモデルを別に作ってみました。これはまた別の記事で報告する予定です。
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー