
YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information


- タイトル:YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information
- 著者:Chien-Yao Wang, I-Hau Yeh, Hong-Yuan Mark Liao
- URL:https://arxiv.org/abs/2402.13616
- カンファ:ECCV2024
目次
ざっくりいうと
- YOLOv9は、軽量モデルでの情報ボトルネック問題を解決するため、プログラム可能な勾配情報(PGI)を提案し、信頼性の高い勾配を生成することで深層の特徴量が重要な情報を保持。
- PGIは訓練時のみ補助的な可逆ブランチを使用し、推論時のコスト増加なしにモデルの性能を向上させ、さらにCSPNetとELANを組み合わせた新しい軽量ネットワークアーキテクチャGELANを設計した。
- 提案手法はMS COCOデータセットでの物体検出タスクで評価され、既存のリアルタイム物体検出器と比較して優れた精度と効率性を示し、YOLOv9のMITライセンス版実装も公開された。
YOLOv9のMIT実装ができている
YOLO(物体検出のモデル)の系列は長らくGPLやAGPLばかりでライセンス上使えないことが多かったが、そのMIT版が実装されている(YOLOv7とv9対応)
https://github.com/WongKinYiu/YOLO
論文要約 By Gemini1.5 Pro
この論文の内容を60秒で読めるように、以下の問いに一問一答で答えます。
- この論文において解決したい課題は何?
深層学習モデル、特に軽量モデルにおける、層を深くするにつれて情報が失われる「情報ボトルネック」問題と、既存の深層監視手法が軽量モデルに適していない問題の解決。
- 先行研究だとどういう点が課題だった?
情報ボトルネックへの対策として、可逆アーキテクチャ、マスクモデリング、深層監視などが提案されていたが、それぞれ推論コストの増加、目標損失との競合、誤り蓄積などの問題があった。特に、深層監視は非常に深いネットワークでしか効果を発揮せず、軽量モデルには適用が難しかった。
- 先行研究と比較したとき、提案手法の独自性や貢献は何?
プログラム可能な勾配情報(PGI)という新しい概念を提案し、補助的な可逆ブランチを通じて信頼性の高い勾配を生成することで、深層の 特徴が重要な情報を維持できるようにした。また、勾配経路計画に基づいた新しい軽量ネットワークアーキテクチャである一般化効率層集約ネットワーク(GELAN)を設計した。PGIは深層監視と異なり、軽量モデルにも適用可能であり、多様なモデルサイズに対応できる。
- 提案手法の手法を初心者でもわかるように詳細に説明して
提案手法は、主要ブランチ(推論用)、補助可逆ブランチ(信頼性の高い勾配生成用)、多レベル補助情報(学習計画制御用)の3つの要素から成るPGIと、CSPNetとELANを組み合わせたGELANという新しいネットワーク構造を使用します。
- GELAN: CSPNetのように、任意の計算ブロックを柔軟に組み込めるようにELANを拡張した構造。これにより、パラメータ数、計算量、精度、推論速度のバランスを最適化。
- PGI: 補助可逆ブランチは、深層監視のように中間層に予測層を挿入する代わりに、可逆構造を持つブランチを追加。これにより、情報ボトルネックによる情報の損失を軽減し、信頼性の高い勾配を生成。多レベル補助情報は、補助可逆ブランチからの勾配情報を集約し、主要ブランチに渡すことで、深層監視で発生する誤り蓄積問題を軽減。推論時には補助可逆ブランチは使用されないため、推論速度への影響はない。
- 提案手法の有効性をどのように定量・定性評価した?
MS COCOデータセットを用いた物体検出タスクで評価。既存のリアルタイム物体検出器と比較し、パラメータ数、計算量、平均精度(AP)を指標に評価。また、ランダムな初期重みを持つネットワークの出力特徴マップを可視化し、情報ボトルネックの影響とPGIによる改善効果を定性的に分析。
- この論文における限界は?
PGIにおける可逆ブランチの設計や多レベル補助情報の統合方法など、更なる最適化の余地がある。
- 次に読むべき論文は?
- YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors.
- CSPNet: A new backbone that can enhance learning capability of CNN.
- Designing network design strategies through gradient path analysis.
論文中のコードはhttps://github.com/WongKinYiu/yolov9 にあります。

概要
これまでのアプローチの多くは、入力データがフィードフォワード処理中に無視できない量の情報損失を持つ可能性があることを無視してきた。これは偏った勾配フローにつながる

異なるネットワークのアーキテクチャーに対する初期重みの特徴マップの可視化。(e)がGELANが提案手法で、目的関数を計算するために信頼できる勾配情報を提供
- 一般的には「情報ボトルネック」と言われる。現状の解決策は3つ
- 可逆アーキテクチャー:繰り返し入力データを用いて、明示的に情報を保持
- デメリット→繰り返し入力される入力データを結合するための追加の層が必要で、推論コストが大幅に増加
- マスクモデリング:再構成損失による、暗黙的な情報の保持
- デメリット→データとの誤った関連付けを行ってしまう
- 深層監視(deep supervision):情報をあまり失っていない浅い特徴を、ターゲットにマッピングを事前に確立し、深い層に情報を伝えるようにする
- デメリット→エラーの蓄積が生じ、浅い層で情報を失うとリカバーできない
- 可逆アーキテクチャー:繰り返し入力データを用いて、明示的に情報を保持
- これらのデメリットは、特に難しいタスク、小さなモデルで顕著に現れる。
- programmable gradient information(PGI:プログラム可能な勾配情報)の提唱
- 補助的な可逆分岐によって信頼性の高い勾配を実現
情報ボトルネック原理と可逆関数

- Iは相互情報量、f,gは変換関数。レイヤーが増えるとどんどん情報損失が起こりやすくなる
- 関数自体の性能をあげちゃえばいいでしょ(モデルサイズを大きくする)→深さよりも幅が重要であることの裏付け
- 非常に深いニューラルネットワークでの、信頼性の低い勾配の根本的な解決ではない
関数rが可逆関数vを持つとき、データXは情報は情報を失うことなく可逆関数により変換される(ζとψはパラメーター)

- 実はこの単純な例は、PreAct ResNetで実践されてるよ!
- PreAct ResNetは1000層みたいに超絶深い場合はうまくいく
- でもただパスしてるだけだから、ディープニューラルネットワークが必要な意味ないじゃん
- レイヤー数が少ない場合は、PreAct ResNetがResNetより悪くなるケースが報告されており、これも説明可能
- データをターゲットにマッピングする関数を直接見つけるのが難しい
マスクモデリングなら逆関数見つけられるじゃん! Mはマスク

- 逆関数を見つけるためには:変分オートエンコーダーか拡散モデル
- 軽量モデルに適用すると、大量の生データに対して、パラメーターされにくくなる
- 情報ボトルネックの理論により、フィードフォワードで多くの情報を失ってしまう
- じゃあ、浅くて軽量なニューラルネットワークに適した、新たな学習方法が必要ですよね!(←この論文の目的)
手法
PGI
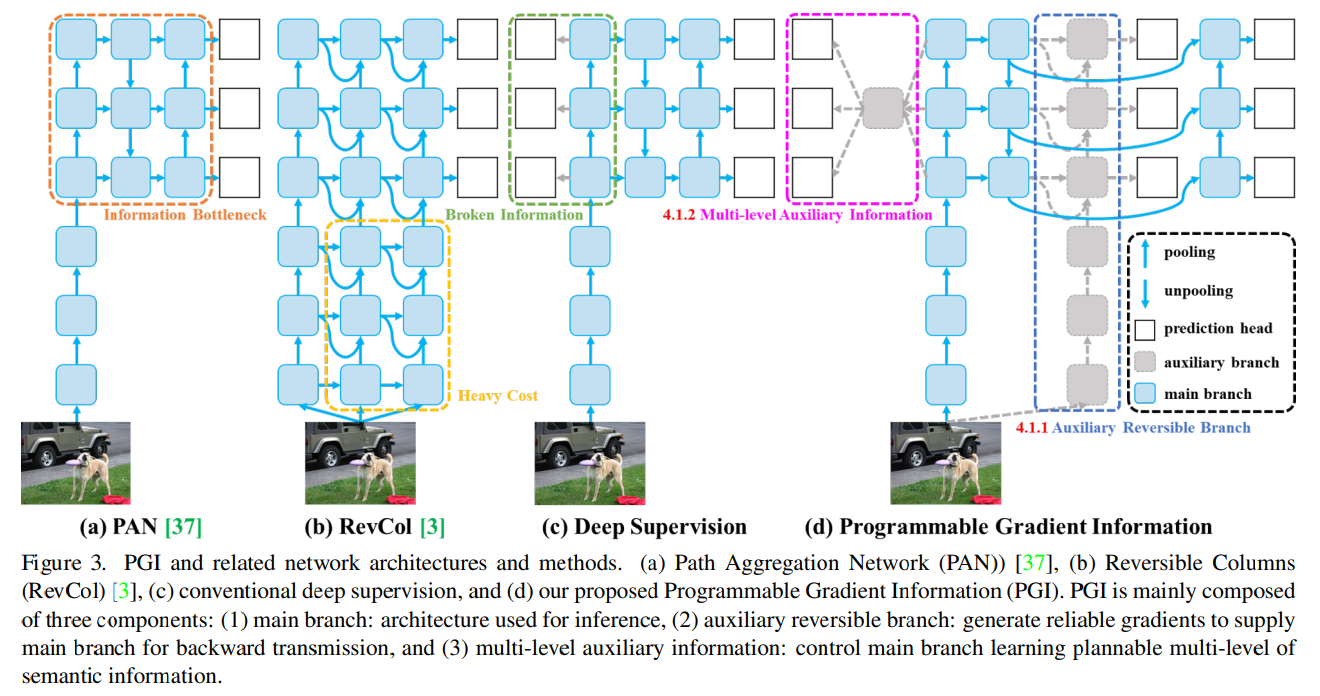
- 訓練時のみ使う、Auxiliaryブランチを使用し、情報損失を抑えて勾配の正確性を高める(d)
- 推論時はメインブランチだけなので、計算コストは増加しない
- 可逆アーキテクチャーは重い
- 深い層から浅い層への接続を追加したら20%増加
- 高解像度計算(bの黄色いブロック)を入れたら推論時間が2倍
- 可逆ブランチって訓練時だけあればよくて、別に推論時はいらないですよね?
- Deep Supervisionの図(c)にある、複数の解像度の情報統合も物体検出では必要だけど、そもそも深い層って情報失ってる
GELAN
- 先行研究からのアーキテクチャーの改善。パラメータ数、計算量、精度、推論速度のバランスを最適化でき、スケーラブル。
- GELAN が従来の畳み込み演算子のみを使用して、深さ方向の畳み込みに基づいて開発された最先端の方法よりも優れたパラメーター効率

結果
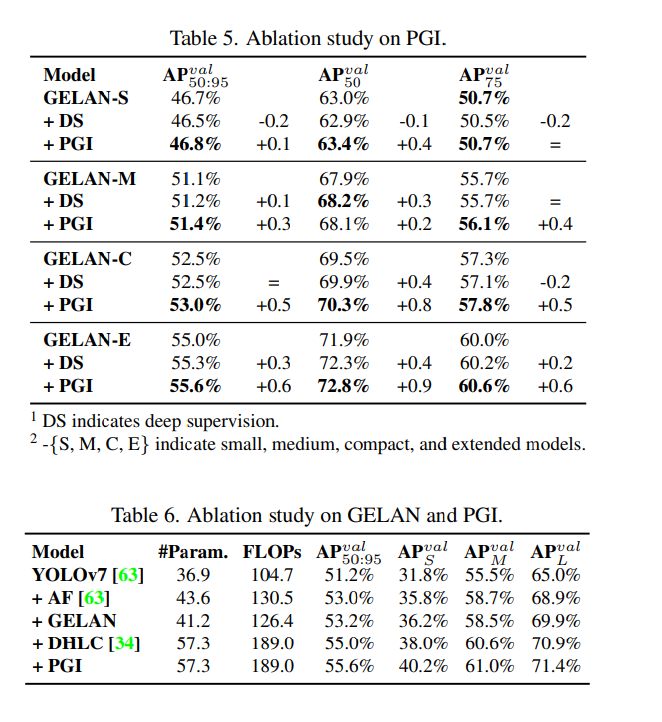

深い層でも完全に情報が保持できる
所感
- PGIの有効性は理論から実験まできれいに示されている
- Auxiliary Branchを入れるという発想自体は、おそらく昔から検討されているので、差分を出しにくかったからGELANを入れたって感じなのだろうか
- GELANは割と取ってつけたような感じで、PGIと組み合わせたら良かったみたいな説明
- ECCV 2024にアクセプトされている
- 2024年になってPreAct ResNetの話を見るとは思わなかった
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー