
Aurora Searverlessのゼロキャパシティを試す


Aurora Serverless v2の自動停止と再開を試し、ゼロキャパシティからの復帰が約15~18秒であることを確認します。ベクトルデータベースを用いた構成で、生じるレイテンシーとコスト削減効果を検証してみます。
目次
はじめに
- AWSの定番RDSのAuroraのサーバーレス版「Aurora Searverless」がゼロキャパシティに対応したので試してみた
- Aurora SearverlessはAuroraキャパシティユニット(ACU)単位での課金体系で、今までは最小が0.5ACUだった。ACUは時間あたりUSD 0.15。
- 最小の0.5ACUでも1ヶ月ずっとつけておくと54USDかかってしまうので、手軽に試すにはちょっと値段が張る
- 今回はベクトルデータベースを例にして、ゼロキャパシティ版を試し、実際どの程度のレイテンシーで停止から復帰できるのかを調べてみた
自動停止からの復帰時間の理論値
ちなみに理論的な停止からの復帰のレイテンシーは、AWSで公式ドキュメントがある
The resumption time is improved in Aurora Serverless v2 compared with Aurora Serverless v1. The time to resume is typically approximately 15 seconds if the instance was paused for less than 24 hours. If the instance is paused for longer than 24 hours, the resume time might be longer.
インスタンスがいったん一時停止すると、再接続には15秒程度かかります。
また、停止期間が24時間を超えると “deeper sleep”モードとなり、接続に30秒以上かかる場合があります。
Amazon Aurora Serverless v2が最小キャパシティ0に対応し、自動停止・再開が可能になりました
ともある。実際に測ったところ15秒ちょいだった。
実験
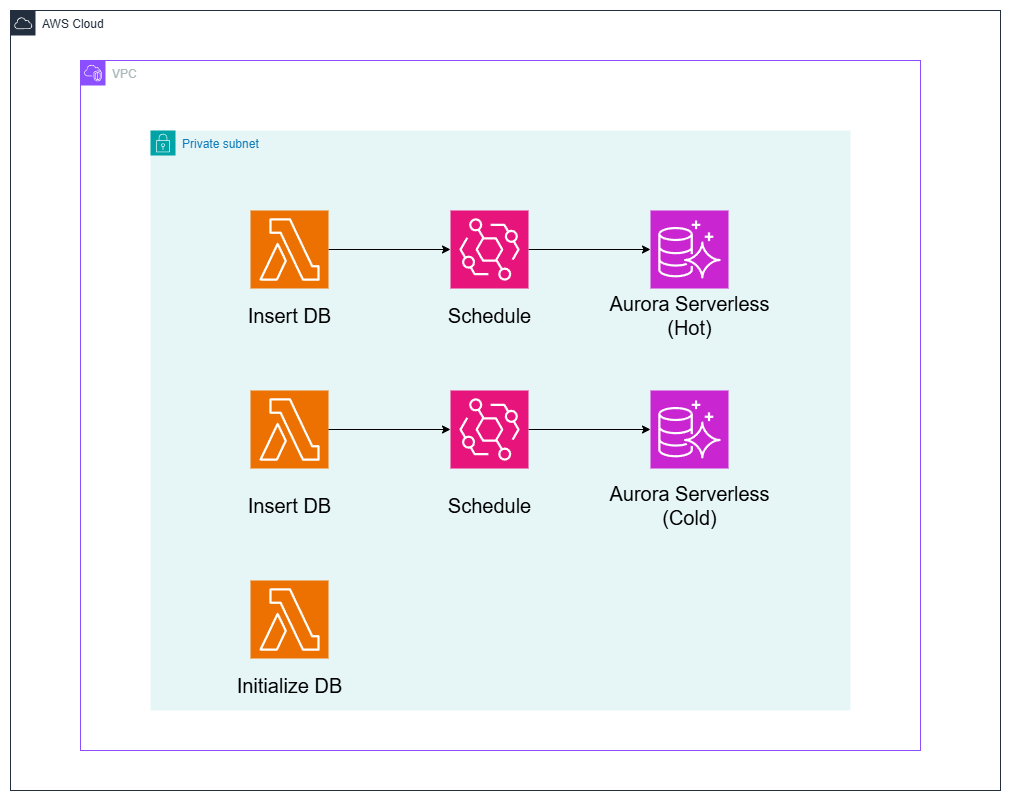
以下の構成で作る。自動停止なしのAurora Serverless(Hot)、自動停止ありで最小が0のAurora Searverless(Cold)を作る
- Hot
- ACUは0.5~0.1
- 自動停止は設定しない
- Cold
- ACUは0~1
- 自動停止は5分(最小値)
- いずれのRDSに対しても12分置きにレコードを書き込むLambdaを実行し、両者の書き込みに必要な時間を比較する
以下の構成図で作る
結果
左がHot、右がColdの結果。
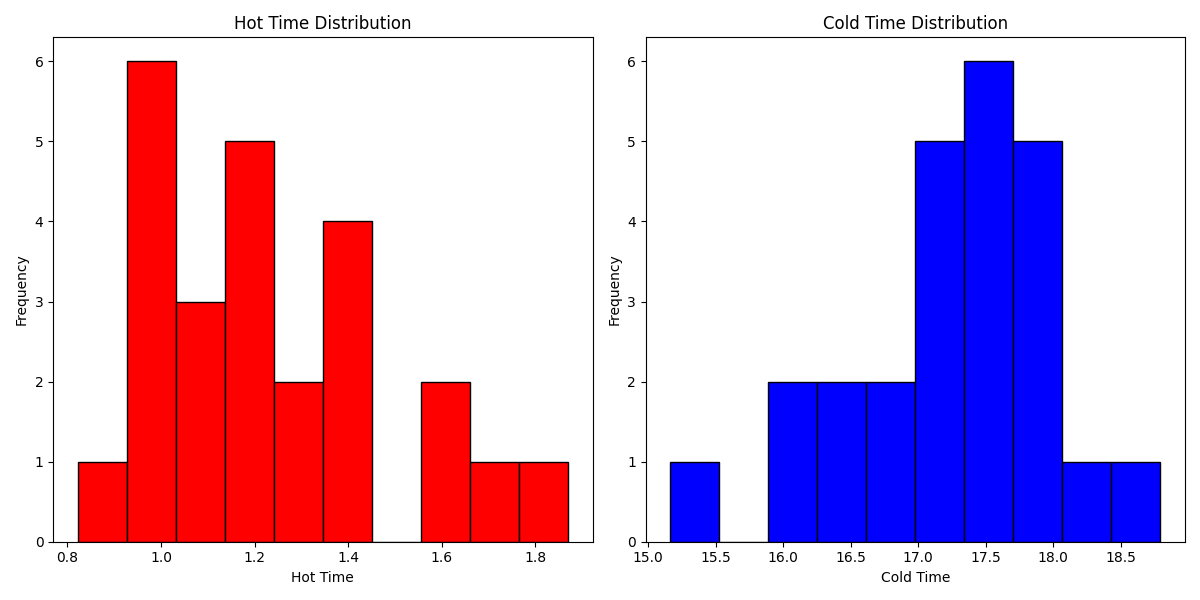
Hotだと1~2秒で終わっているのに、Coldだと16~18秒かかっている。自動停止からの復帰のオーバーヘッドが15秒というのはほぼ正しいようだ。
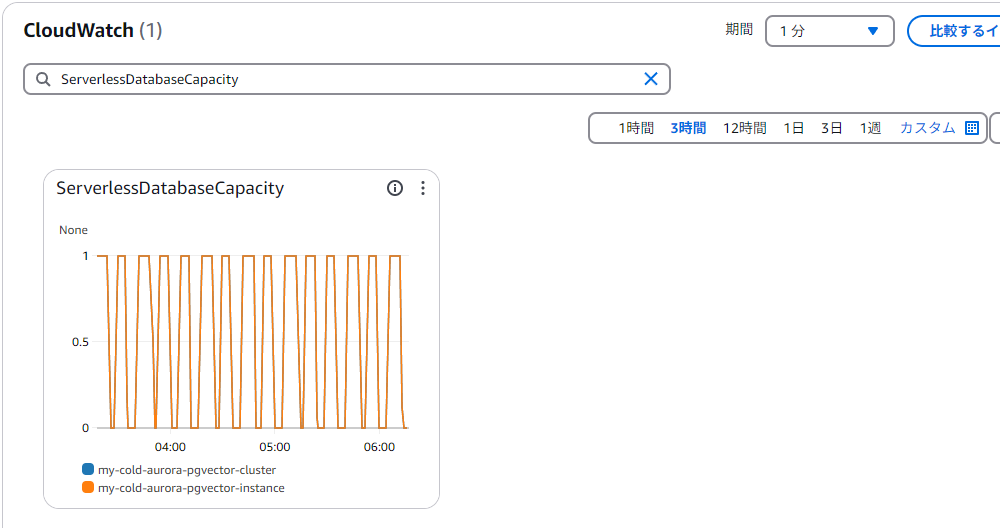
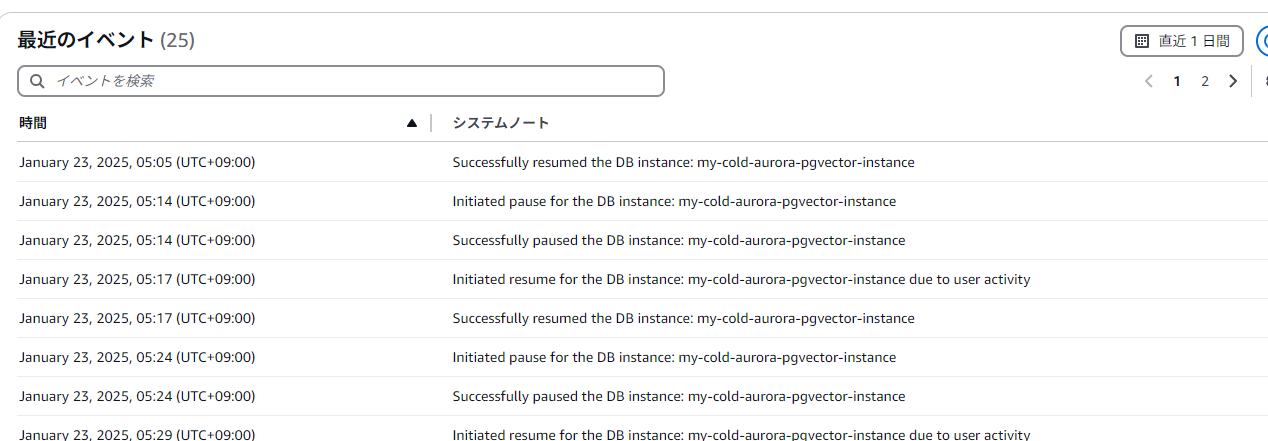
また、コールド側のDBのモニタリングは以下のようなジグザグになっているはず(
ServerlessDatabaseCapacity)。ログとイベントは以下のようにStopとStartを繰り返しているのが想定している状態
CloudWatch Logs Insightのクエリ
こんなクエリで集計できる
fields @timestamp, experiment, aurora_type, elapsed
| filter experiment = "experiment_02"
| filter aurora_type = "hot" # coldと切り替え
| sort @timestamp desc
| limit 100
ゼロキャパシティではIDが飛ぶ現象
やってみてわかったこととして、ゼロキャパシティだと(おそらく一時停止の影響だが)、IDが飛ぶということがわかった。
ゼロキャパシティ(Cold)の場合の連続した実行のログ
2025-01-23T05:29:56.998+09:00 {“elapsed”: 17.35119605064392, “aurora_type”: “cold”, “new_id”: 793, “experiment”: “experiment_02”}
2025-01-23T05:41:57.222+09:00 {“elapsed”: 17.251522064208984, “aurora_type”: “cold”, “new_id”: 826, “experiment”: “experiment_02”}
自動停止を設定していない(Hot)の場合の連続した実行ログ
2025-01-23T05:45:05.863+09:00 {“elapsed”: 1.5753412246704102, “aurora_type”: “hot”, “new_id”: 50, “experiment”: “experiment_02”}
2025-01-23T05:55:05.357+09:00 {“elapsed”: 1.0150485038757324, “aurora_type”: “hot”, “new_id”: 51, “experiment”: “experiment_02”}
Hotの場合はIDが連番だが、Coldの場合は大きく間が空いている。この理由をGPT-o1に聞いたところ、
Aurora PostgreSQL では ID の生成にシーケンスを用いており、パフォーマンス向上のためシーケンス値をある程度キャッシュしています。このため、サーバーが停止するタイミングでキャッシュされた未使用のシーケンス値が破棄され、次回起動時にはその飛び先から使用が再開されるために ID が大きく飛んでしまいます。
特に Aurora Serverless (AutoStop を有効化) の場合、インスタンスが自動停止・再起動を頻繁に行う関係で、キャッシュしていたシーケンス値が破棄されやすく、結果として ID が大幅にスキップしやすくなります。一方、常時起動のインスタンスであればシーケンスキャッシュは途切れず連続して消費されるため、ID が飛びにくく見えます。
シーケンスが連番を完全に保証しないのは PostgreSQL(Aurora PostgreSQL を含む)としては仕様の範囲内であり、ID の値に連番性を厳密に求める場合は別の方法 (更新テーブルをロックした上での自前カウンタを使うなど) を検討する必要があります。通常は、主キーなど一意性が守られていれば問題ないため、ID 飛びは運用上はあまり気にしなくてもよいケースがほとんどです。
とのことだった。
ディレクトリ構成
以下のようなディレクトリ構成
.
├── aurora.tf
├── bastion_ec2.tf
├── lambda.tf
├── main.tf
├── aurora_lambda_src
│ ├── initialize_database.py
│ └── insert_row.py
└── lambda_layers
└── postgres.zip
各ファイル・ディレクトリの説明:
- aurora.tf: Auroraデータベースの設定ファイル
- bastion_ec2.tf: (オプション)踏み台サーバー用の設定
- lambda.tf: AWS Lambda関数の設定ファイル
- main.tf: メインのTerraform設定ファイル
- aurora_lambda_src/: Lambda関数で使用するPythonスクリプトを格納するディレクトリ
- initialize_database.py: データベースの初期化スクリプト
- insert_row.py: データベースに行を挿入するスクリプト
- lambda_layers/: Lambdaレイヤーを格納するディレクトリ
- postgres.zip: PostgreSQLドライバーなどを含むレイヤーのZIPファイル
Terraformファイル
aurora.tf
- Auroraは最新のバージョンを使えば(現在は16.6)ゼロキャパシティはサポートされる
serverlessv2_scaling_configuration以下のmin_capacityを0にすればゼロキャパシティになるseconds_until_auto_pauseは300秒で最小値。ただ、Lambdaのアクセスがあって落ちるまで若干ラグがある(実測7分ぐらい)なので、定期実行は余裕を見て設定する。
# 与えられているサブネット ID を使って DB Subnet Group を作成
resource "aws_db_subnet_group" "aurora_subnet_group" {
name = "aurora-subnet-group"
subnet_ids = var.private_subnet_ids
description = "Subnet group for Aurora Serverless"
}
data "aws_subnet" "private_subnets" {
for_each = toset(var.private_subnet_ids)
id = each.value # ここに対象のサブネットIDを指定
}
# Aurora のマスターパスワードを Secrets Manager に格納するための準備(ランダム生成 → Secret → Secret Version)
resource "random_password" "aurora_password" {
length = 16
special = true
override_special = "!#$%&*()-_=+[]{}<>:?" # 利用したい特殊文字の制限があれば適宜修正
}
resource "aws_secretsmanager_secret" "aurora_password" {
name = "aurora-master-password"
description = "Master password for Aurora PostgreSQL stored in Secrets Manager"
# Terraform destroy 時に即削除されるようにする設定
recovery_window_in_days = 0
}
resource "aws_secretsmanager_secret_version" "aurora_password_version" {
secret_id = aws_secretsmanager_secret.aurora_password.id
secret_string = random_password.aurora_password.result
}
# セキュリティグループ (例: ポート 5432 を開放)
resource "aws_security_group" "aurora_sg" {
name = "aurora-postgres-sg"
description = "Allow inbound PostgreSQL traffic"
vpc_id = var.vpc_id
ingress {
description = "PostgreSQL port"
from_port = 5432
to_port = 5432
protocol = "tcp"
cidr_blocks = [for key, value in data.aws_subnet.private_subnets : value.cidr_block]
}
egress {
from_port = 0
to_port = 0
protocol = "-1"
cidr_blocks = ["0.0.0.0/0"]
}
}
# Aurora Serverless クラスターの作成
resource "aws_rds_cluster" "aurora_pgvector" {
cluster_identifier = "my-aurora-pgvector-cluster"
engine = "aurora-postgresql"
engine_version = "16.6" # 実行時に利用可能な最新バージョンに合わせる
master_username = "postgres"
master_password = aws_secretsmanager_secret_version.aurora_password_version.secret_string
db_subnet_group_name = aws_db_subnet_group.aurora_subnet_group.name
# Aurora Serverless v2 のスケーリング設定
serverlessv2_scaling_configuration {
min_capacity = 0.5 # 必要に応じて変更
max_capacity = 1.0 # 必要に応じて変更
}
vpc_security_group_ids = [
aws_security_group.aurora_sg.id
]
storage_encrypted = true
deletion_protection = false
# テストや開発用で最終スナップショットを取らずに削除する場合
skip_final_snapshot = true
}
# Aurora Serverless クラスターのインスタンスを作成
resource "aws_rds_cluster_instance" "aurora_pgvector_instance" {
identifier = "my-aurora-pgvector-instance"
cluster_identifier = aws_rds_cluster.aurora_pgvector.id
engine = aws_rds_cluster.aurora_pgvector.engine
# Serverless v2 用インスタンスクラス (Aurora)
instance_class = "db.serverless"
db_subnet_group_name = aws_db_subnet_group.aurora_subnet_group.name
}
##### Zero scale
# Aurora Serverless クラスターの作成
resource "aws_rds_cluster" "cold_aurora_pgvector" {
cluster_identifier = "my-cold-aurora-pgvector-cluster"
engine = "aurora-postgresql"
engine_version = "16.6" # 実行時に利用可能な最新バージョンに合わせる
master_username = "postgres"
master_password = aws_secretsmanager_secret_version.aurora_password_version.secret_string
db_subnet_group_name = aws_db_subnet_group.aurora_subnet_group.name
# Aurora Serverless v2 のスケーリング設定
serverlessv2_scaling_configuration {
min_capacity = 0.0 # 必要に応じて変更
max_capacity = 1.0 # 必要に応じて変更
seconds_until_auto_pause = 300
}
vpc_security_group_ids = [
aws_security_group.aurora_sg.id
]
storage_encrypted = true
deletion_protection = false
# テストや開発用で最終スナップショットを取らずに削除する場合
skip_final_snapshot = true
}
# Aurora Serverless クラスターのインスタンスを作成
resource "aws_rds_cluster_instance" "cold_aurora_pgvector_instance" {
identifier = "my-cold-aurora-pgvector-instance"
cluster_identifier = aws_rds_cluster.cold_aurora_pgvector.id
engine = aws_rds_cluster.cold_aurora_pgvector.engine
# Serverless v2 用インスタンスクラス (Aurora)
instance_class = "db.serverless"
db_subnet_group_name = aws_db_subnet_group.aurora_subnet_group.name
}
(オプション):bastion_ec2.tf
踏み台サーバーのコード。基本これはいらない。最初のクエリテストしたいときは有効。ただDBモニタリングツールなど使ってコネクション張りっぱなしにしておくと、自動停止が作動しないので注意する。
data "aws_region" "current" {}
##########################
# IAMロールおよびプロファイル設定
##########################
# EC2がSession Managerを利用するためのIAMロールを作成
resource "aws_iam_role" "ssm_role" {
name = "ec2_sample_ssm_role"
assume_role_policy = jsonencode({
Version = "2012-10-17",
Statement = [{
Effect = "Allow",
Principal = {
Service = "ec2.amazonaws.com"
},
Action = "sts:AssumeRole"
}]
})
}
# Session Manager用のポリシーをIAMロールにアタッチ
resource "aws_iam_role_policy_attachment" "ssm_attach" {
role = aws_iam_role.ssm_role.name
policy_arn = "arn:aws:iam::aws:policy/AmazonSSMManagedInstanceCore"
}
# IAMロールにSecrets Managerアクセス用のインラインポリシーを追加
resource "aws_iam_role_policy" "ssm_secrets_access" {
name = "ssm-secrets-access"
role = aws_iam_role.ssm_role.id
policy = jsonencode({
Version = "2012-10-17",
Statement = [
{
Effect = "Allow",
Action = [
"secretsmanager:GetSecretValue",
"secretsmanager:DescribeSecret"
],
Resource = aws_secretsmanager_secret.aurora_password.arn
}
]
})
}
# IAMインスタンスプロファイルの作成
resource "aws_iam_instance_profile" "ssm_profile" {
name = "ec2_sample_ssm_profile"
role = aws_iam_role.ssm_role.name
}
resource "aws_security_group" "ec2_sg" {
name = "sample_ec2_sg"
description = "A security group for EC2"
vpc_id = var.vpc_id
egress {
description = "Allow all outbound traffic"
from_port = 0
to_port = 0
protocol = "-1"
cidr_blocks = ["0.0.0.0/0"]
ipv6_cidr_blocks = ["::/0"]
}
}
# EC2インスタンス設定(user_data は LF 改行で保存する)
resource "aws_instance" "ubuntu_ssm" {
ami = data.aws_ami.ubuntu.id
instance_type = "t3.small"
subnet_id = var.private_subnet_ids[0]
vpc_security_group_ids = [aws_security_group.ec2_sg.id]
iam_instance_profile = aws_iam_instance_profile.ssm_profile.name
associate_public_ip_address = false
tags = {
Name = "Ubuntu-SSM"
Backup = "Yes"
}
}
# 最新のUbuntu 24.04 LTSのAMIを取得する例
data "aws_ami" "ubuntu" {
most_recent = true
owners = ["099720109477"] # CanonicalのAMI所有者ID
filter {
name = "name"
values = ["ubuntu/images/hvm-ssd-gp3/ubuntu-noble-24.04-amd64-server-*"]
}
filter {
name = "architecture"
values = ["x86_64"]
}
filter {
name = "virtualization-type"
values = ["hvm"]
}
}
lambda.tf
- DBに接続するためのLambda。Hot/Cold、レコードの追加/初期化で2×2の4個定義する。
- DBのパスワードはSecrets Managerに入れておく
# IAMロール作成
resource "aws_iam_role" "lambda_role" {
name = "aurora_lambda_role"
assume_role_policy = jsonencode({
Version = "2012-10-17"
Statement = [{
Action = "sts:AssumeRole"
Effect = "Allow"
Principal = {
Service = "lambda.amazonaws.com"
}
}]
})
}
# IAMポリシー:LambdaがSecrets ManagerおよびAuroraにアクセスするための権限を付与
resource "aws_iam_role_policy" "lambda_policy" {
name = "aurora_lambda_policy"
role = aws_iam_role.lambda_role.id
policy = jsonencode({
Version = "2012-10-17"
Statement = [
{
Effect = "Allow",
Action = [
"secretsmanager:GetSecretValue",
"secretsmanager:DescribeSecret"
],
Resource = aws_secretsmanager_secret.aurora_password.arn
}
]
})
}
# VPCアクセス用マネージドポリシーのアタッチ
resource "aws_iam_role_policy_attachment" "attach_vpc_policy" {
role = aws_iam_role.lambda_role.name
policy_arn = "arn:aws:iam::aws:policy/service-role/AWSLambdaVPCAccessExecutionRole"
}
# Lambda Layer を作成
resource "aws_lambda_layer_version" "postgres" {
filename = "lambda_layers/postgres.zip"
layer_name = "postgres_layer"
compatible_runtimes = ["python3.12"]
source_code_hash = filebase64sha256("lambda_layers/postgres.zip")
}
data "archive_file" "lambda_zip" {
type = "zip"
source_dir = "${path.module}/aurora_lambda_src"
output_path = ".cache/aurora_lambda.zip"
}
locals {
lambda_functions = {
hot_aurora_insert_function = {
handler = "insert_row.lambda_handler"
host = aws_rds_cluster.aurora_pgvector.endpoint
aurora_type = "hot"
schedule = "rate(10 minutes)"
}
hot_aurora_initialize_function = {
handler = "initialize_database.lambda_handler"
host = aws_rds_cluster.aurora_pgvector.endpoint
aurora_type = "hot"
schedule = null
}
cold_aurora_insert_function = {
handler = "insert_row.lambda_handler"
host = aws_rds_cluster.cold_aurora_pgvector.endpoint
aurora_type = "cold"
schedule = "rate(12 minutes)"
}
cold_aurora_initialize_function = {
handler = "initialize_database.lambda_handler"
host = aws_rds_cluster.cold_aurora_pgvector.endpoint
aurora_type = "cold"
schedule = null
}
}
experiment_id = "experiment_02"
scheduled_lambdas = {
for name, details in local.lambda_functions :
name => details if details.schedule != null
}
}
# Lambda関数の作成
resource "aws_lambda_function" "aurora_lambda" {
for_each = local.lambda_functions
function_name = each.key
role = aws_iam_role.lambda_role.arn
handler = each.value.handler
runtime = "python3.12"
filename = data.archive_file.lambda_zip.output_path
source_code_hash = filebase64sha256(data.archive_file.lambda_zip.output_path)
layers = [aws_lambda_layer_version.postgres.arn]
environment {
variables = {
AURORA_HOST = each.value.host
AURORA_PORT = "5432"
AURORA_DB_NAME = "postgres"
AURORA_USER = "postgres"
AURORA_TYPE = each.value.aurora_type
SECRET_NAME = "aurora-master-password"
REGION = "ap-northeast-1"
EXPERIMENT_ID = local.experiment_id
}
}
vpc_config {
subnet_ids = var.private_subnet_ids
security_group_ids = [aws_security_group.aurora_sg.id]
}
# タイムアウトやメモリなどの設定は必要に応じて調整
timeout = 60
memory_size = 512
}
# 定期実行が必要なLambda
# EventBridgeルールの作成
resource "aws_cloudwatch_event_rule" "schedule" {
for_each = local.scheduled_lambdas
name = each.key
schedule_expression = each.value.schedule
}
# EventBridgeターゲットの作成
resource "aws_cloudwatch_event_target" "lambda_schedule_target" {
for_each = local.scheduled_lambdas
rule = aws_cloudwatch_event_rule.schedule[each.key].name
target_id = "lambda"
arn = aws_lambda_function.aurora_lambda[each.key].arn
}
# Lambda関数に対するEventBridgeからの呼び出し許可の設定
resource "aws_lambda_permission" "allow_eventbridge" {
for_each = local.scheduled_lambdas
statement_id = "AllowEventBridgeInvoke-${each.key}"
action = "lambda:InvokeFunction"
function_name = aws_lambda_function.aurora_lambda[each.key].function_name
principal = "events.amazonaws.com"
source_arn = aws_cloudwatch_event_rule.schedule[each.key].arn
}
main.tf
外部変数
# 外部から与えられるプライベートサブネットのID
variable "private_subnet_ids" {
type = list(string)
description = "Aurora Serverless を配置するサブネットのリスト"
}
variable "vpc_id" {
type = string
description = "Aurora を作成する VPC の ID"
}
Pythonコード
aurora_lambda_src/initialize_database.py
import os
import boto3
import psycopg
from botocore.exceptions import ClientError
# 環境変数から接続情報を取得
AURORA_HOST = os.environ.get("AURORA_HOST")
AURORA_PORT = int(os.environ.get("AURORA_PORT", "5432"))
AURORA_DB_NAME = os.environ.get("AURORA_DB_NAME")
AURORA_USER = os.environ.get("AURORA_USER")
SECRET_NAME = os.environ.get("SECRET_NAME")
REGION = os.environ.get("REGION", "ap-northeast-1")
def get_secret():
"""
Secrets Manager から Aurora のパスワードを取得する関数
"""
session = boto3.session.Session()
client = session.client(
service_name='secretsmanager',
region_name=REGION
)
try:
get_secret_value_response = client.get_secret_value(SecretId=SECRET_NAME)
except ClientError as e:
print(f"Error retrieving secret: {e}")
raise e
if 'SecretString' in get_secret_value_response:
secret = get_secret_value_response['SecretString']
return secret
else:
decoded_binary_secret = get_secret_value_response['SecretBinary']
return decoded_binary_secret
def initialize_database():
"""
Aurora PostgreSQL に接続し、pgvector拡張機能の設定やテーブルの初期化を行う関数
"""
conn = psycopg.connect(
host=AURORA_HOST,
port=AURORA_PORT,
dbname=AURORA_DB_NAME,
user=AURORA_USER,
password=get_secret()
)
try:
with conn.cursor() as cur:
# pgvector 拡張機能の有効化
cur.execute("CREATE EXTENSION IF NOT EXISTS vector;")
# 既存のテーブルが存在する場合は削除
cur.execute("DROP TABLE IF EXISTS vector_table;")
# ベクトルデータ用のテーブル作成
cur.execute("""
CREATE TABLE vector_table (
id SERIAL PRIMARY KEY,
content TEXT,
embedding VECTOR(1536)
);
""")
# ivfflat インデックスの作成
# テーブル名、カラム名を実際のものに合わせて修正してください
cur.execute("""
CREATE INDEX IF NOT EXISTS vector_table_embedding_idx
ON vector_table
USING ivfflat (embedding) WITH (lists = 100);
""")
conn.commit()
except Exception as e:
conn.rollback()
print(f"Error during initialization: {e}")
raise e
finally:
conn.close()
def lambda_handler(event, context):
try:
initialize_database()
result = {
'statusCode': 200,
'body': "データベースの初期化が完了しました。"
}
except Exception as e:
result = {
'statusCode': 500,
'body': f"エラーが発生しました: {str(e)}"
}
return result
aurora_lambda_src/insert_row.py
import os
import boto3
import random
import psycopg
import time
import json
from pgvector.psycopg import register_vector
from botocore.exceptions import ClientError
# 環境変数から接続情報を取得
AURORA_HOST = os.environ.get("AURORA_HOST")
AURORA_PORT = int(os.environ.get("AURORA_PORT", "5432"))
AURORA_DB_NAME = os.environ.get("AURORA_DB_NAME")
AURORA_USER = os.environ.get("AURORA_USER")
AURORA_TYPE = os.environ.get("AURORA_TYPE")
SECRET_NAME = os.environ.get("SECRET_NAME")
EXPERIMENT_ID = os.environ.get("EXPERIMENT_ID", "default")
REGION = os.environ.get("REGION", "ap-northeast-1")
def get_secret():
"""
Secrets Manager から Aurora のパスワードを取得する関数
"""
session = boto3.session.Session()
client = session.client(
service_name='secretsmanager',
region_name=REGION
)
try:
get_secret_value_response = client.get_secret_value(SecretId=SECRET_NAME)
except ClientError as e:
print(f"Error retrieving secret: {e}")
raise e
if 'SecretString' in get_secret_value_response:
secret = get_secret_value_response['SecretString']
return secret
else:
decoded_binary_secret = get_secret_value_response['SecretBinary']
return decoded_binary_secret
def insert_vector(conn, content, embedding_vector):
"""
Aurora PostgreSQL にベクトルデータを挿入する関数
"""
with conn.cursor() as cur:
insert_query = """
INSERT INTO vector_table (content, embedding)
VALUES (%s, %s)
RETURNING id;
"""
cur.execute(insert_query, (content, embedding_vector))
inserted_id = cur.fetchone()[0]
conn.commit()
return inserted_id
def lambda_handler(event, context):
# Aurora PostgreSQL に接続
start_time = time.time()
conn = psycopg.connect(
host=AURORA_HOST,
port=AURORA_PORT,
dbname=AURORA_DB_NAME,
user=AURORA_USER,
password=get_secret()
)
register_vector(conn)
try:
# サンプルデータの設定
sample_content = "これはサンプルのコンテンツです。"
sample_embedding = [random.random() for _ in range(1536)]
# データを挿入
new_id = insert_vector(conn, sample_content, sample_embedding)
# 所要時間
elapsed = time.time() - start_time
result = {
"elapsed": elapsed,
"aurora_type": AURORA_TYPE,
"new_id": new_id,
"experiment": EXPERIMENT_ID
}
print(json.dumps(result, ensure_ascii=False))
result = {
'statusCode': 200,
'body': f"データが挿入されました。新しいレコードのID: {new_id}"
}
except Exception as e:
result = {
'statusCode': 500,
'body': str(e)
}
finally:
conn.close()
return result
Lambdaレイヤー
以下のライブラリをインストールしてZipで固める。
pgvector==0.3.6
psycopg[binary]==3.2.4
これが便利
DockerでAWS LambdaのレイヤーのZipファイルを一括生成する
所感
- 18秒ぐらいのラグが耐えられれば結構あり
- API Gatewayで使う想定だと29秒タイムアウトと相性はよくなさそう。ただし、最近クォーターが解除できるようになって若干粘れるようになったらしいので、ここが許容できるのなら結構コスト削減できる可能性はある
- 思ったよりラグの分散が少ない(いきなり1分ぐらいコールドスタートあるとかない)のでそこは信頼してもいいかも
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー