
Auroraグローバルデータベースのマルチリージョンフェイルオーバーを試す


複数リージョン間でAuroraのライター/リーダーの自動昇格やグローバルテーブルの切り替え動作をTerraformで構築し、フェイルオーバーを検証した。ボタン操作だけでプライマリの切り替えが完了し、障害時にもリアルタイムでデータが同期される仕組みにより、高い可用性を実現できることを確認した。
目次
はじめに
- SAPの勉強してたらAuroraグローバルデータベースや、マルチリージョンのフェイルオーバー、リーダーインスタンスの昇格が散々出てきたのでいい加減試してみた
- 複数のリージョンにわたってAuroraのインスタンスを作って、インスタンスの削除や、グローバルテーブル側でのフェイルオーバーを試してみる
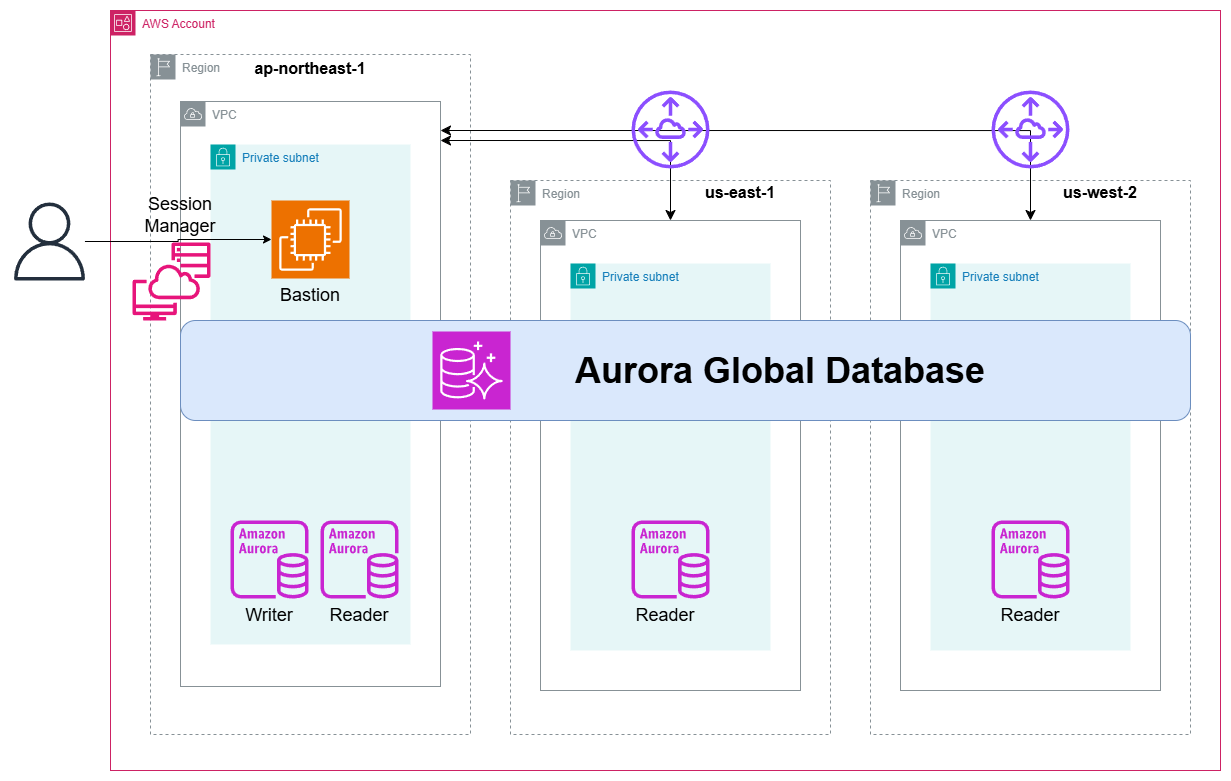
アーキテクチャー
- 作るものは結構壮大。3つのリージョンにわたってAuroraのグローバルデータベースを作り、プライマリリージョン(東京)にはライターインスタンスとリードレプリカ、他のリージョンにはリードレプリカを作る
- プライマリリージョンに踏み台(Bastion)をおいて、いろんなデータベースサーバーに対してSQLクエリを実行する
- ここからディザスターリカバリーを想定し、他リージョンのリードレプリカをプライマリに昇格させる
- 踏み台→他のリージョンの通信は、VPCをまたぐのでプライマリ→他リージョン間にVPCピアリングを確立しておく
- VPCピアリングを試す参考
- Terraformで定義するときは、アクセプター(他リージョン側の)
auto_accept = trueで自動承認できる
Auoraグローバルデータベースの作り方
できるもの
terraform applyすると以下のようなAuroraグローバルクラスタが作成される。Terraformの全体コードは末尾参照。
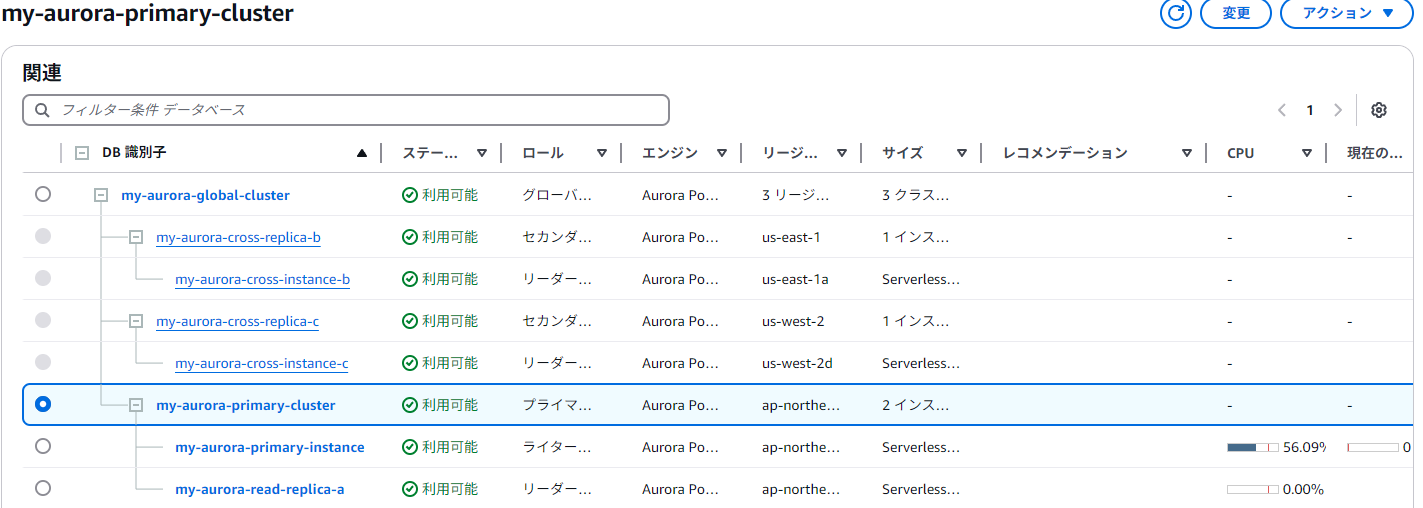
プライマリリージョン
- 普通にAurora作るときと同じだが、Auroraグローバルクラスターを作って紐づける
- マスターのユーザー名、パスワードの指定が必要
- グローバルクラスターは暗号化が必須。KMSを特にしなければAWSマネージドキー
aws/rdsが使われる。このKMSがセカンダリの指定で必要になる - ライター/リーダーは作られる順番で決まるようだ。
promotion_tierで指定することも可能で、1はライターになって、2がリーダーになるが、depends_onで指定しておくと順番は固定できる
# Aurora Global Clusterの作成
resource "aws_rds_global_cluster" "aurora_global_cluster" {
global_cluster_identifier = "my-aurora-global-cluster"
engine = "aurora-postgresql"
engine_version = "16.6" # 利用可能な最新バージョンに合わせる
storage_encrypted = true
}
resource "aws_rds_cluster" "primary_cluster" {
provider = aws
cluster_identifier = "my-aurora-primary-cluster"
engine = "aurora-postgresql"
engine_version = "16.6"
master_username = "postgres"
master_password = aws_secretsmanager_secret_version.aurora_password_version_a.secret_string
db_subnet_group_name = aws_db_subnet_group.aurora_subnet_group_a.name
# Aurora Serverless v2 のスケーリング設定
serverlessv2_scaling_configuration {
min_capacity = 0.0 # 必要に応じて変更
max_capacity = 1.0 # 必要に応じて変更
seconds_until_auto_pause = 300
}
vpc_security_group_ids = [
aws_security_group.aurora_sg_a.id
]
storage_encrypted = true
deletion_protection = false
skip_final_snapshot = true
global_cluster_identifier = aws_rds_global_cluster.aurora_global_cluster.global_cluster_identifier
}
# プライマリインスタンス
resource "aws_rds_cluster_instance" "primary_instance" {
provider = aws
identifier = "my-aurora-primary-instance"
cluster_identifier = aws_rds_cluster.primary_cluster.id
engine = aws_rds_cluster.primary_cluster.engine
instance_class = "db.serverless"
db_subnet_group_name = aws_db_subnet_group.aurora_subnet_group_a.name
promotion_tier = 1
}
# リージョンA内のリードレプリカ
resource "aws_rds_cluster_instance" "read_replica_a" {
provider = aws
identifier = "my-aurora-read-replica-a"
cluster_identifier = aws_rds_cluster.primary_cluster.id
engine = aws_rds_cluster.primary_cluster.engine
instance_class = "db.serverless"
db_subnet_group_name = aws_db_subnet_group.aurora_subnet_group_a.name
promotion_tier = 2
# ライターインスタンスを作ってからリードレプリカを作成
depends_on = [aws_rds_cluster_instance.primary_instance]
}
セカンダリリージョン
- クロスリージョンレプリカ+リーダーインスタンス
- Auroraの設定はプライマリといっしょにする必要がある
- ユーザー名とパスワードのプライマリから引き継ぐので指定はしないが(あるとエラーになる)、KMSの指定が必要。これはAuroraグローバルで暗号化を指定しているため
# リージョンCのAuroraクラスター(クロスリージョンリードレプリカ)
resource "aws_rds_cluster" "cross_region_replica_c" {
provider = aws.secondary_c
cluster_identifier = "my-aurora-cross-replica-c"
engine = "aurora-postgresql"
engine_version = "16.6"
db_subnet_group_name = aws_db_subnet_group.aurora_subnet_group_c.name
kms_key_id = "arn:aws:kms:${data.aws_region.region_c.name}:${data.aws_caller_identity.current.account_id}:alias/aws/rds"
# Aurora Serverless v2 のスケーリング設定
serverlessv2_scaling_configuration {
min_capacity = 0.0 # 必要に応じて変更
max_capacity = 1.0 # 必要に応じて変更
seconds_until_auto_pause = 300
}
vpc_security_group_ids = [
aws_security_group.aurora_sg_c.id
]
storage_encrypted = true
deletion_protection = false
skip_final_snapshot = true
global_cluster_identifier = aws_rds_global_cluster.aurora_global_cluster.global_cluster_identifier
}
# リージョンCのAuroraリードレプリカインスタンス
resource "aws_rds_cluster_instance" "cross_region_instance_c" {
provider = aws.secondary_c
identifier = "my-aurora-cross-instance-c"
cluster_identifier = aws_rds_cluster.cross_region_replica_c.id
engine = aws_rds_cluster.cross_region_replica_c.engine
instance_class = "db.serverless"
db_subnet_group_name = aws_db_subnet_group.aurora_subnet_group_c.name
depends_on = [aws_rds_cluster.cross_region_replica_c]
}
試す
踏み台サーバーへの接続
踏み台サーバーにSession Mangaerで接続する。VSCodeから接続するときはSSHキーの送信が別途発生する。
AWS Systems Manager Session Managerを用いてvscodeのRemote-SSHでEC2接続してみた
踏み台サーバーに接続できたら、プライマリーリージョンのライターインスタンスに接続して、テーブルの作成とレコードの追加を行う。プラグインはVSCodeの拡張機能のPostgreSQLを使う。拡張機能の使い方は以下のページが詳しい。
VSCodeからPostgreSQLへ接続してSQL発行まで
プライマリーリージョンのライターインスタンス
プライマリーリージョンのライターインスタンスに接続し、以下のクエリを実行してデータテーブルを作成する。レコードを追加する。
CREATE TABLE IF NOT EXISTS employees (
id SERIAL PRIMARY KEY,
first_name VARCHAR(50) NOT NULL,
last_name VARCHAR(50) NOT NULL,
email VARCHAR(100) UNIQUE NOT NULL,
hire_date DATE NOT NULL
);
INSERT INTO employees (first_name, last_name, email, hire_date) VALUES
('太郎', '山田', 'taro.yamada@example.com', '2023-01-15'),
('花子', '佐藤', 'hanako.sato@example.com', '2023-02-20'),
('次郎', '鈴木', 'jiro.suzuki@example.com', '2023-03-10'),
('美咲', '高橋', 'misaki.takahashi@example.com', '2023-04-05'),
('健一', '田中', 'kenichi.tanaka@example.com', '2023-05-25');
VSCodeのPostgreSQLの拡張機能で実行すると、次のようなメッセージが表示される。
null rows created
5 rows inserted
テーブルを表示してみる。
SELECT * from employees
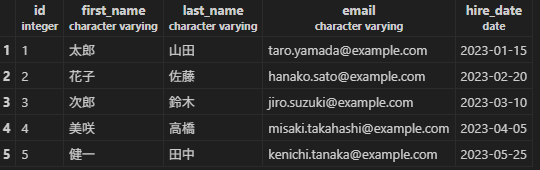
プライマリーリージョンのリーダーインスタンス
リーダーインスタンスの場合はどうだろうか。以下のクエリでテーブル全体を表示するとうまくいく。
SELECT * from employees
試しに1個のレコードを追加してみる。
INSERT INTO employees (first_name, last_name, email, hire_date) VALUES
('悠斗', '松本', 'yuto.matsumoto@example.com', '2023-06-30');
失敗する。リーダーインスタンスは本当にread-onlyらしい。
ERROR: cannot execute INSERT in a read-only transaction
クロスリージョンのリーダーインスタンス
他リージョンにも複製されているだろうか? 実行してみる
SELECT * from employees
→複製されている!
クロスリージョンレプリカとは文字通り自動的に別リージョンにデータ同期する操作。しかし、りーだー
クロスリージョンの昇格
プライマリーのライターインスタンスを削除する→プライマリーのリーダーが自動昇格
プライマリーのライターインスタンスを削除してみる
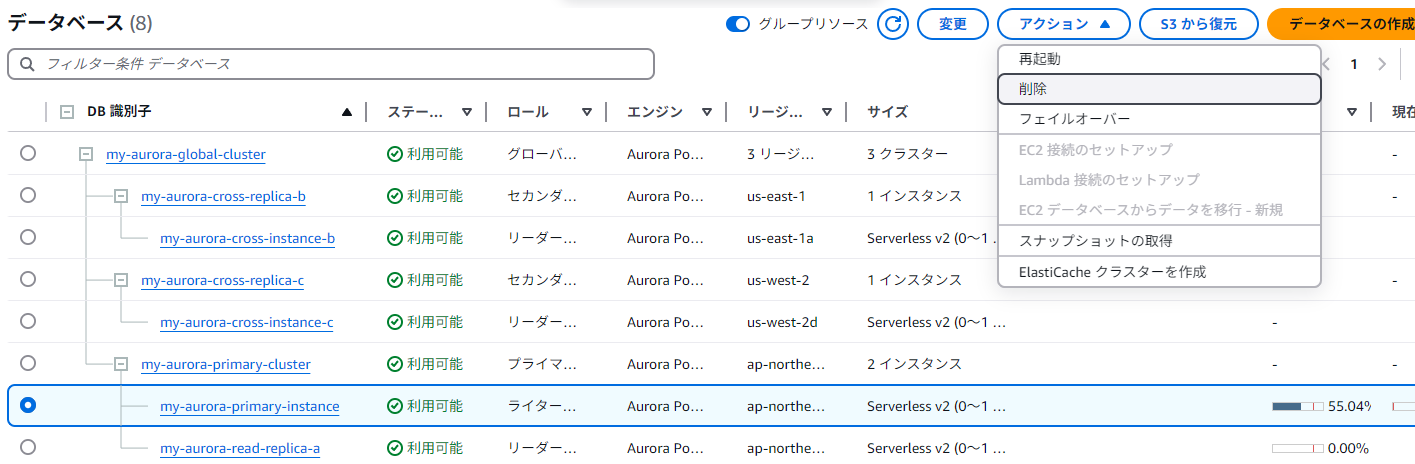
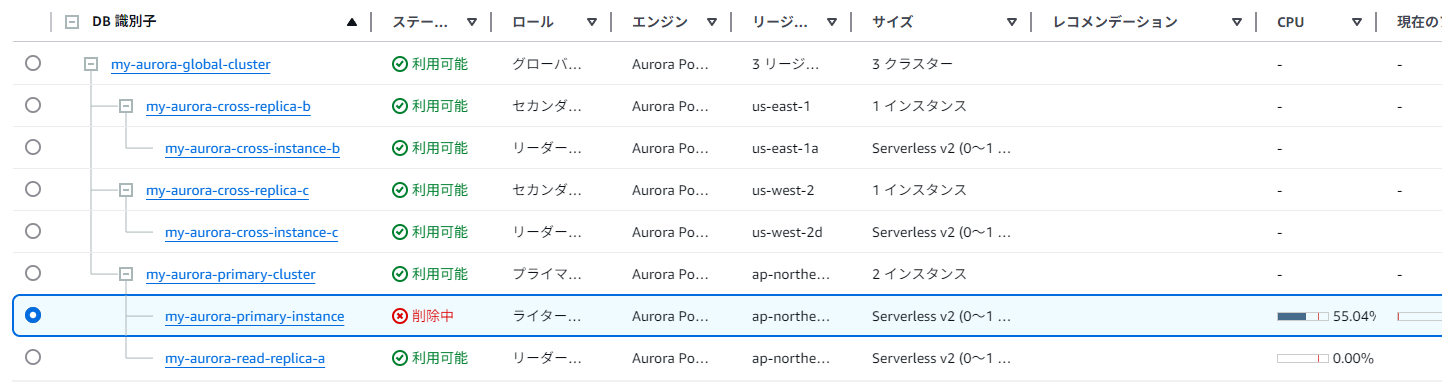
削除が完了すると、リーダーインスタンスが自動的にライターに昇格している! ただこれはAuroraグローバルテーブルの仕様というより、マルチインスタンスにおける挙動。
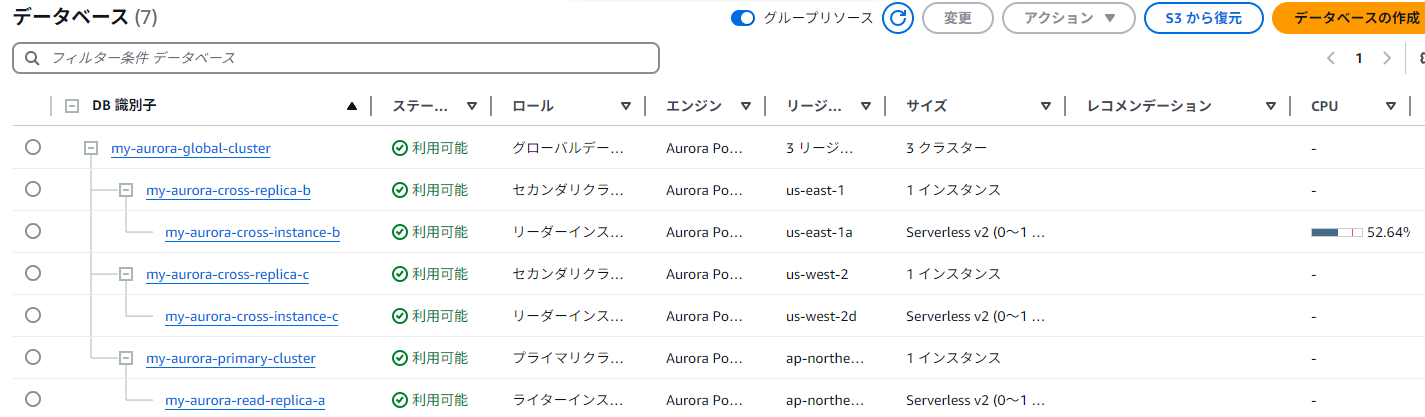
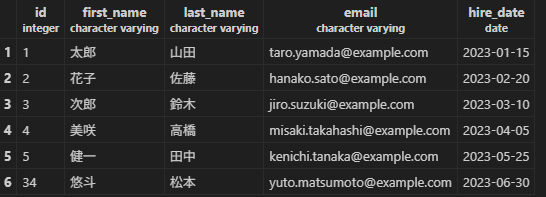
昇格後はレコード追加のクエリも普通にとおる。IDが飛んでいるのはゼロキャパシティの関係かはわからないが、飛ぶ仕様。
INSERT INTO employees (first_name, last_name, email, hire_date) VALUES
('悠斗', '松本', 'yuto.matsumoto@example.com', '2023-06-30');
SELECT * from employees
グローバルテーブルからのスイッチング
ここからがAuroraグローバルテーブルの興味深い挙動で、Auroraグローバルテーブルのほうから簡単にリージョン間のスイッチングができる。
グローバルテーブル(一番上)をクリックし、「スイッチオーバーまたはフェイルオーバーのグローバルデータベース」

今回は「切り替え」でやってみる。us-east-1をプライマリにするような切り替えにしてみる。

切り替え作業が進行中。グローバルテーブルのステータスが「切り替え」になる
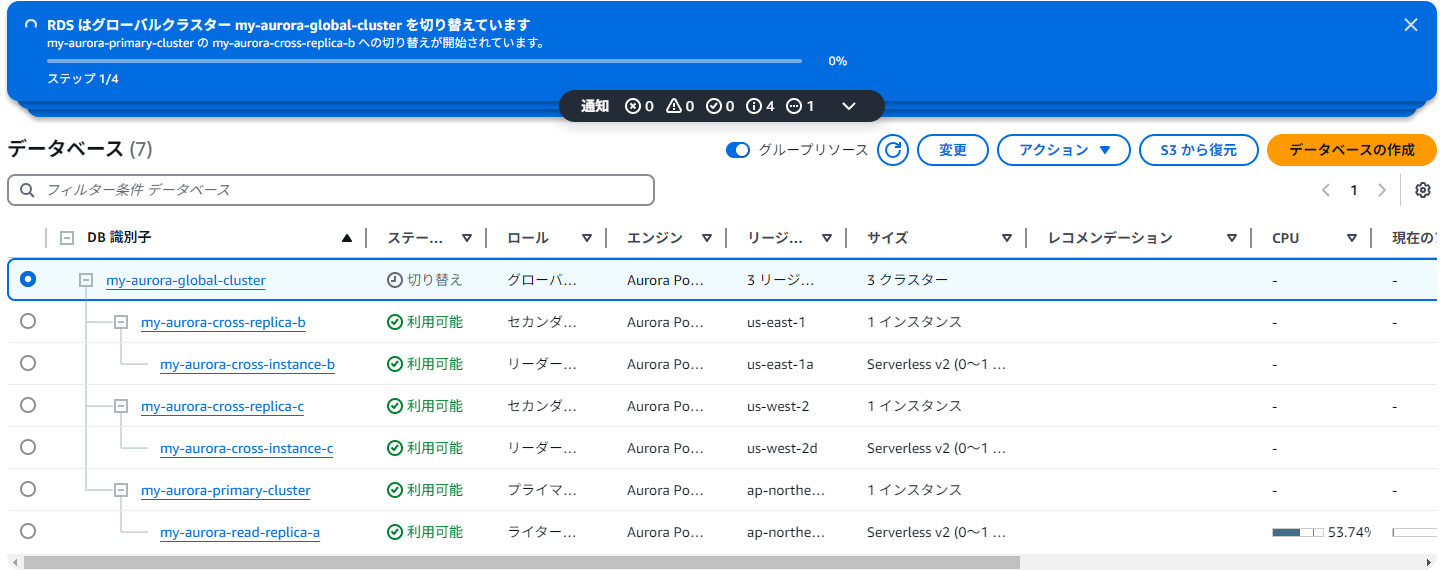
数分で切り替えが完了する。以下の変更がおきている
- もともとセカンダリだったus-east-1がプライマリに昇格
- もともとプライマリだったap-northeast-1がセカンダリに降格。続いて変更操作が走る
- us-east-1のリーダーインスタンスが、プライマリ昇格にともない、ライターインスタンスに昇格。
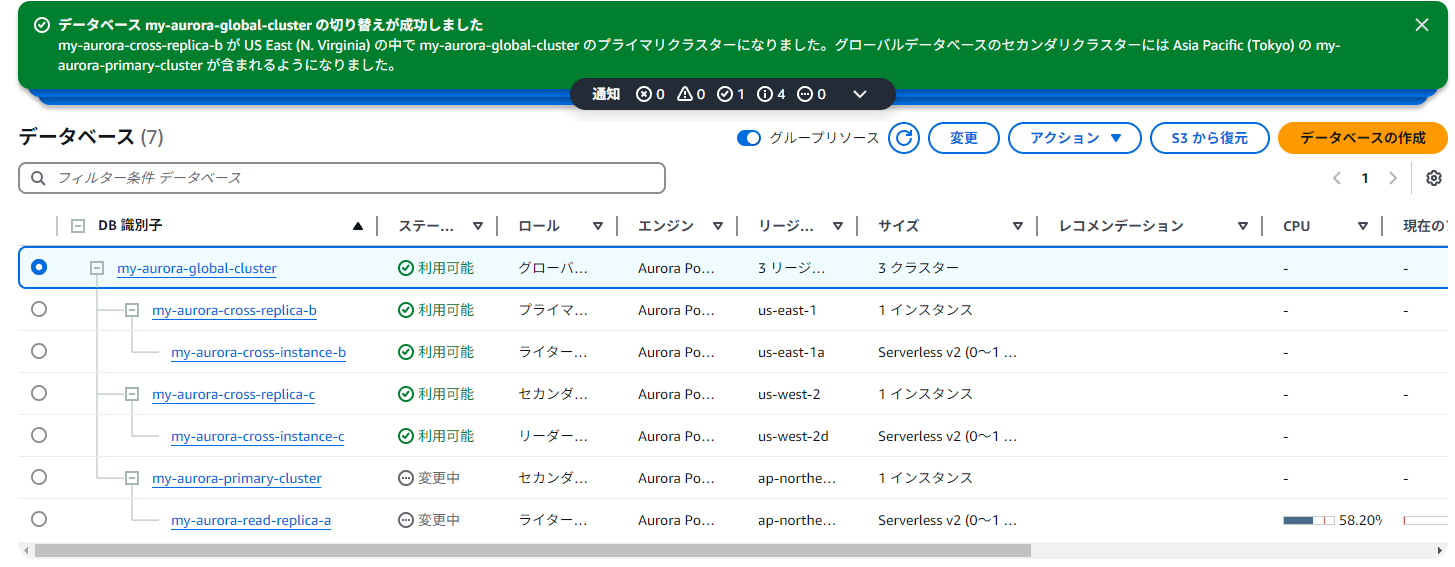
続いて、セカンダリ(ap-northeast-1)のライターインスタンスが、セカンダリ降格にともない、リーダーインスタンスに降格。
ap-northeast-1のインスタンスは以下のような変遷を辿っている
- もともとはap-northeast-1はプライマリで、ライター(A)とリーダー(B)の2個のインスタンスがいた
- ライター(A)が削除により消えたので、もともとのリーダー(B)がライターに昇格。これはプライマリリージョンがap-northeast-1にあったため。グローバルテーブルではプライマリリージョンではライターインスタンスが1個あることが保証されるようだ。
- グローバルテーブルのスイッチングにより、ap-northeast-1がセカンダリに降格。これによりライターに昇格したBはリーダーに再び降格。
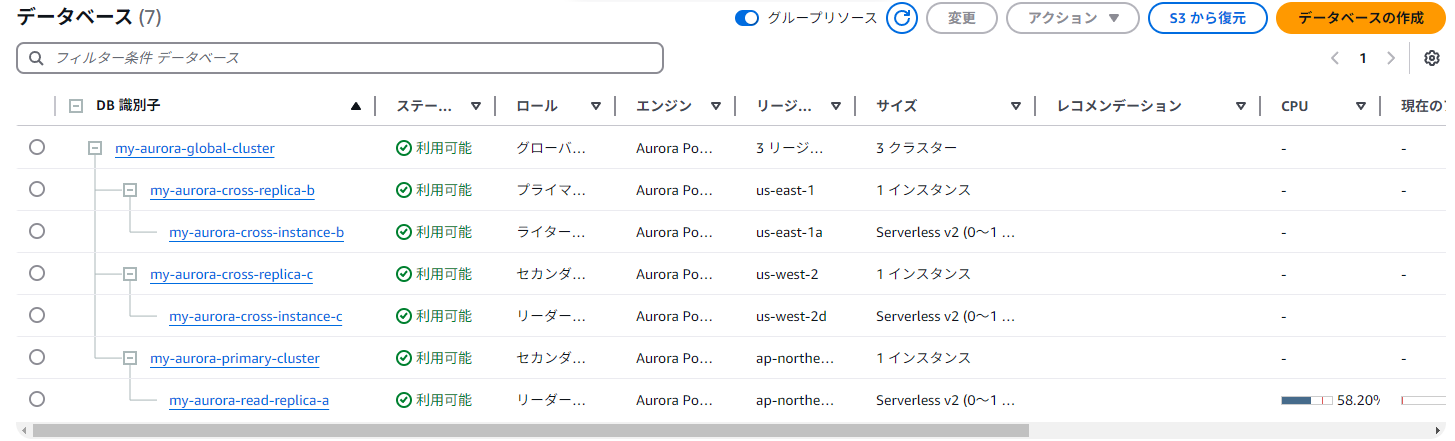
スイッチング後にap-northeast-1のインスタンスに接続してデータを追加しようとするとエラーになる。これはリーダーになったため。
INSERT INTO employees (first_name, last_name, email, hire_date) VALUES
('美和', '子供', 'miwa.kodomo@example.com', '2023-07-15');
ERROR: cannot execute INSERT in a read-only transaction
昇格したプライマリリージョンに追加
us-east-1はプライマリに昇格したのでデータの追加が可能。
INSERT INTO employees (first_name, last_name, email, hire_date) VALUES
('美和', '子供', 'miwa.kodomo@example.com', '2023-07-15');
1 row inserted
適当なリーダーインスタンスからSELECT * FROM employeesしても、反映されている

全体コード
以下のGitHubにある
https://github.com/koshian2/aurora-global-table-sample
所感
- Auroraグローバルテーブル、非常によくできている。この例だと明らかにオーバースペックだが、フェイルオーバーやスイッチングがボタンポチで完了するのはすごい
- 便利なんだけど、リソース作成時に
terraform applyで50分ぐらい待たされるのはしんどい。データベースのインスタンス作成時間かかりすぎるのよね。 - ただ、これIaCとの併用はどうするんだろう。プライマリとセカンダリの状態が、フェイルオーバーとIaCのステートで変わりそうな気はする。障害時にIaCをapplyしないとかやるんだろうか。
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー