
pix2pixを1から実装して白黒画像をカラー化してみた(PyTorch)


pix2pixによる白黒画像のカラー化を1から実装します。PyTorchで行います。かなり自然な色付けができました。pix2pixはGANの中でも理論が単純なのにくわえ、学習も比較的安定しているので結構おすすめです。
目次
はじめに
PyTorchでDCGANができたので、今回はpix2pixをやります。今回は白黒画像のカラー化というよくありがちな例をやってみます。
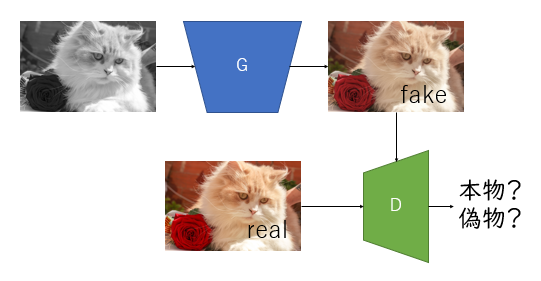
あとで理論的な解説をしますが、やっていることは上図のとおりです。pix2pixはGANの一種です。Generatorに白黒画像を入れ偽のカラー画像を作り、Discriminatorに本物をカラー画像を入れ、min-maxゲームで互いを訓練していきます。
GANというとモード崩壊や勾配消失が怖いというイメージがありますが、pix2pixは訓練がかなり安定しているので応用が十分期待できるでしょう。
もとの論文:
P. Isola, J. Zhu, T. Zhou, A. A. Efros. Image-to-Image Translation with Conditional Adversarial Networks. CVPR, 2017.
https://arxiv.org/abs/1611.07004
Conditional-GAN
論文読んでいると、pix2pixはConditional GAN(cGAN)の一種として書かれています。DCGANは完全にノイズから画像を生成するのに対し、conditional GANは例えばMNISTでは、どの数字かというラベルの情報+ノイズで生成します。「pix2pixの場合はノイズもラベルもなかったはずだよな。なんでConditional GANなんだろう?」と思いましたが、白黒画像が「条件」となっているわけなんですね。DCGANのノイズも条件なんですが、ノイズが条件の条件付き確率ってノイズ項が消せちゃいますので。
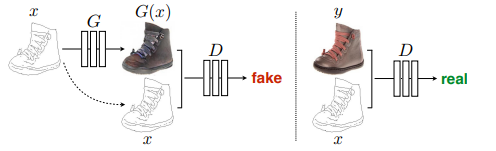
pix2pixの損失関数
pix2pixはGANの一種なので、DCGANと損失関数が似ています。DCGANと異なる点は、Gにピクセル単位のL1損失を入れているということです。
こちらは普通のGANの損失関数です。
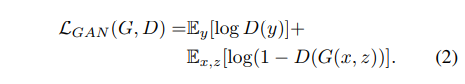
こちらがpix2pixの損失関数です。
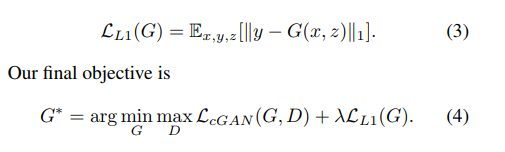
Generatorの部分だけ変わっているので、Dは共通です。
λはL1損失と交差エントロピーの比率を決めるハイパーパラメータで、論文はλ=100で実験しています。高めのλを使うと元画像に近くなるので、これは直感的にはわかりやすいです。
実装上はGの損失関数は
- DCGAN : BCEWithLogits(d_out_fake, ones)
- pix2pix : BCEWithLogits(d_out_fake, ones) + lambda * L1Loss(fake, real)
のような形になります。ただ足すだけですね。
PatchGAN
これがPix2pixの面白いところですが、Dの判定が画像全体を本物・偽物で識別するのではなく、画像全体をパッチに分割してパッチ単位で本物・偽物を識別します。論文ではこれをPatchGANと読んでいます。
実装上は全く難しくなくて、YOLOを思い出せばいいのです。ある解像度の入力に対して、CNNの最後の層の解像度が(batch, 512, 3, 3)なら(NCHWフォーマット)とします。YOLOではCNNの位置不変性により、3×3の分割エリア/Sliding Windowに対して物があるかどうかを判定しているにすぎません。物があるかどうかを、「各Sliding Windowに対して本物かどうか」を判定すればPatch GANになります。

こういうイメージです。YOLOと一緒です。
実装上は、DCGANで本物/偽物と学習させたい場合のy_trueのテンソルが、
ones = torch.ones(512)
zeros = torch.zeros(512)
なら、PatchGANの場合は、
ones = torch.ones(512, 1, 3, 3)
zeros = torch.zeros(512, 1, 3, 3)
とすればいいだけです。これは最終層が3×3解像度で、バッチサイズが512のケースです。
色空間変換
この問題では、白黒画像の自動着色を行っているので、一般的なRGB色空間よりも、明るさと色差を分離したYCrCb色空間を経由したほうがより直接的な訓練ができるようになります。PyTorchでの色空間変換はこちらを参照してください。
PyTorchで行列(テンソル)積としてConv2dを使う
https://blog.shikoan.com/conv2d-matmul/
また、GやDで「YCrCb色空間」といったときは特に断りがなければYもCrCbも-1~1スケールです。本来のYCrCb色空間ではYは0~1、CrCbは-0.5~0.5のスケールです。詳細は末尾のコードを見てください。
G:YCrCb色空間, D:RGB色空間(成功例)
一番うまく行った(と思われる)例です。
序盤からかなり早く着色が進みます。これは色空間変換の効果です(特に、NonGANのただのU-Netだと顕著な傾向があります)。
画像データはもともRGB色空間ですが、Gに食わせる前にYCrCbへの色空間の変換を行います。そして、Gの入力をYCrCbのY・出力をCrCbとします。その後、Gの入力のYと出力のCrCbを足し合わせた画像を偽画像として、RGB色空間に戻します。Dの本物/偽物の判別はRGB色空間で行います。
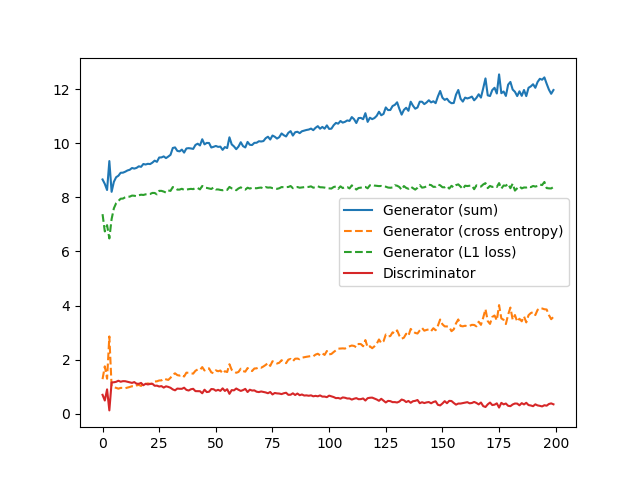
DとGの損失推移です。Dの損失がゆるやかに減少し、Gの損失がゆるやかに増加しているのがわかります。Gの内訳を見ると、L1損失はほぼ変わらないのに対し、Cross Entropyだけが増えているのがわかります。これは通常のDCGANでも見られる現象です。
G:YCrCb色空間, D:YCrCb色空間(着色がおかしい?)
次にDの色空間をRGB色空間ではなく、YCrCb色空間とします。
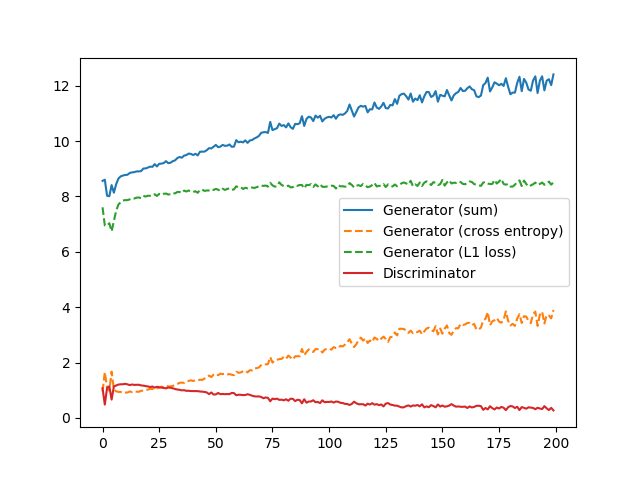
エラー推移は先程と変わりませんが、着色がどうも違和感があります。CrCb(赤と青の色差)で見ているので、赤と青のモヤっとした部分が目立つようになります。Dの色空間はRGBのほうがよさそうです。
G:RGB色空間, D:RGB色空間+グレースケール画像(Dが強くなりすぎてうまくいない)
これはGもDもRGB色空間で行う例です。Gの入力はRGB色空間から生成したグレースケール画像、出力はRGB色空間のカラー画像としています。Dの入力はRGB色空間のカラー画像です。
ただし、Pix2pixの論文で読むと「Gの入力をDの入力に再度入れなさい」と書いているので、Gで使ったグレースケールの画像をDの入力に入れ、Dの入力は4チャンネルとなっています。ここは議論の余地があると思います。なぜなら、
- もとのRGB色空間から生成したグレースケールの画像は、RGB画像についての関数だから、DにRGB画像を入れた時点で既にグレースケールの成分は入っている
- Pix2pixの論文の定義にしたがってDにもRGB画像とグレースケールの両方を入れるべきだ
という2つの考え方があるからです。このケースでは(2)を選択しました。(1)も後ほど試してみます。
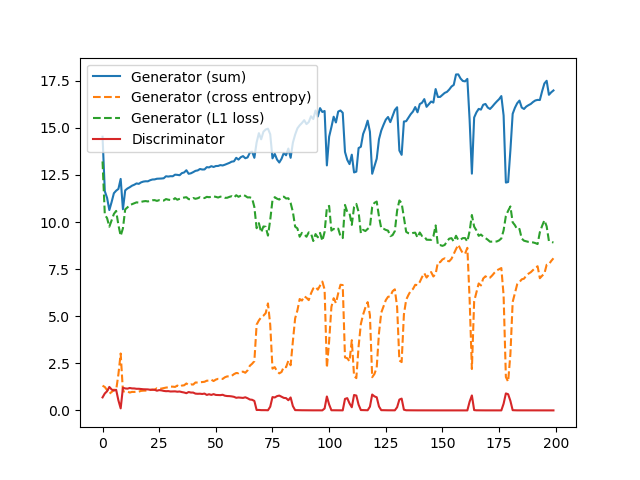
ただし、このケースでは訓練が安定しませんでした。Dのロスが低くなりすぎる(強くなりすぎる)と、以降Dのロスが振動して暴れだします。途中まで上手く行っていたが、どれも似たようなセピア調の着色になってしまう、着色が失われてしまいます。
G:RGB色空間, D:RGB色空間(まあまあうまくいく)
順番は前後してしまいましたが、これが最初に試したケースです。Dにグレースケールの画像を入れません(チャンネル数は3です)。先程の(1)の考えた方です。
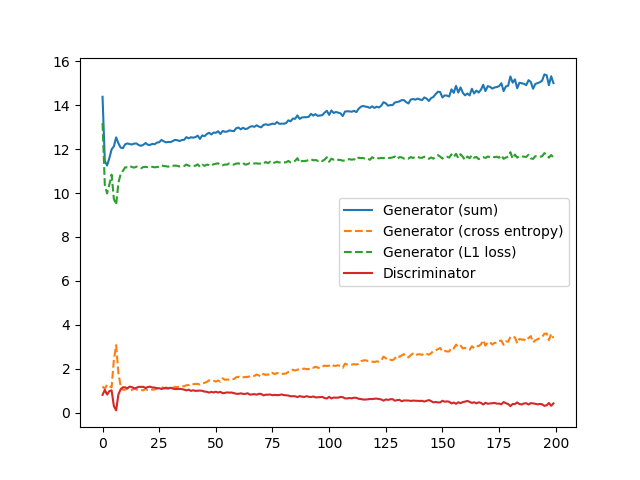
結果はまあまあうまくいきました。GをYCrCbにしたケースとどっちが着色がいいかは好みがあるでしょう。
このケースでは、Gの入力であるグレースケールの画像を、Dに入れないほうがうまくいきました。
Gの色空間にともなう損失関数の変更
補足事項ですが、Gの色空間を変えた場合はGの損失関数を以下のように変えています。
- Gの色空間がRGB : 交差エントロピー + 100 × RGB色空間でのL1損失
- Gの色空間がYCrCb : 交差エントロピー + 75 × CrCb(YCrCb色空間からYを除外)でのL1損失 + 25 × RGB色空間でのL1損失
YCrCb色空間でRGBのL1損失を入れている理由は、Non-GANの場合に、YCrCbだけの損失関数だと、白や黒に近いような場所で極端な着色になってしまうからです。それを打ち消すためにRGB色空間でのL1損失を入れています。
まとめ
pix2pixを実装できました。結構手軽にできて学習も安定してるし、結果もそれっぽいのでコスパはかなり高そうです。
細かい話だと、白黒画像のカラー化の場合はDもGもRGB色空間か、GがYCrCbでDがRGB色空間がよさそうです。
コード
全てGistに上がってます。訓練時間は2080Tiが2枚で5時間程度でした。エポック間に謎の間が20~30秒あってここが短縮できればもっと高速になるはずです。
- rgb_rgb.py : GもDも色空間がRGB。Dがグレースケールありの例。なしの場合はtorch.cat等を外せばいいだけなので、やっていることが理解できていればいじれるはずです。
- ycrcb_rgb.py : GがYCrCbで、DがRGBのケースです。成功例として紹介したのがこちら。
- ycrcb_ycrcb.py : GもDもYCrCbのケースです
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー