
エージェント設計パターンによるRAG品質の改善

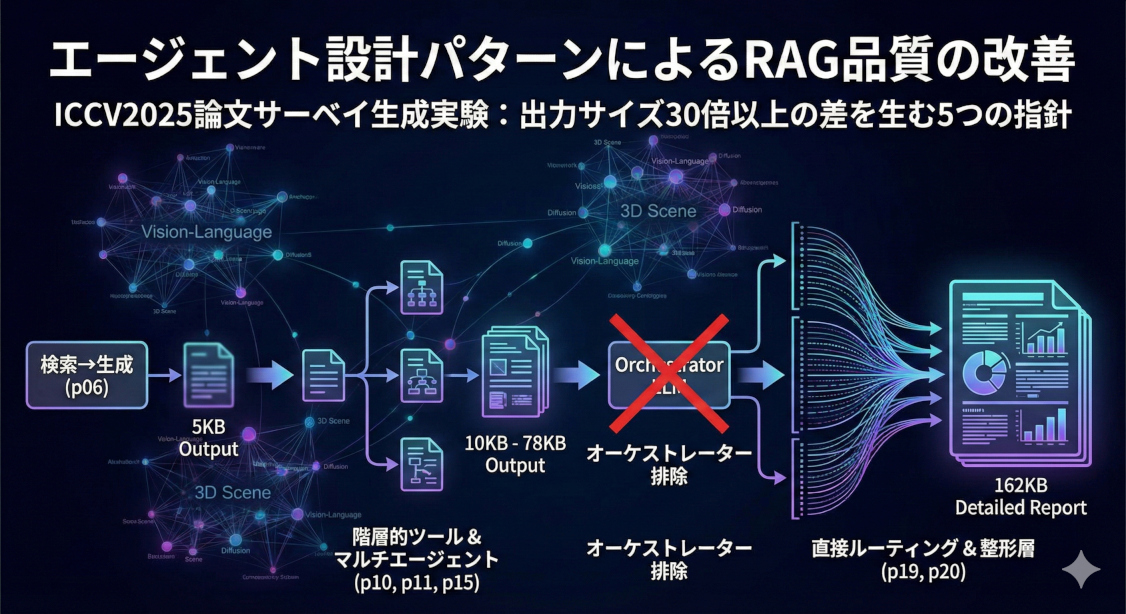
ICCV2025採択論文2,113本を対象としたサーベイ生成実験により、エージェント設計パターンの違いが出力品質に決定的な差を生むことが明らかになりました。特に「オーケストレーターの排除」が逆に詳細なレポートを生むという直感に反する結果など、実用的なRAG構築のための5つの重要な設計指針を詳解します。
目次
はじめに
単純なRAG(Retrieval-Augmented Generation)では、「検索して、結果を渡して、生成する」という一直線のフローになります。しかし、複雑な分析タスク——例えば数千本の論文から研究トレンドを俯瞰するサーベイ生成——では、この単純なアプローチには限界があります。
本記事では、ICCV2025(コンピュータビジョンのトップ会議)に採択された2,113本の論文を対象に、「ICCV2025のトレンドを教えて」という質問に対するサーベイ生成を行い、エージェント設計の違いが出力品質にどう影響するかを実験的に検証しました。
結論を先に述べると、設計パターンの違いで出力は5KB〜162KBと大きく変化し、品質にも明確な差が生まれました。
本記事で紹介する主要な実験と発見は以下の通りです:
| 実験 | 設計のポイント | 出力サイズ |
|---|---|---|
| p06 → p10 | ツール設計の改善 | 5KB → 10KB |
| p11 vs p12 | マルチエージェントのパターン選択 | 13KB vs 4KB |
| p15 | 2段階パイプライン(分析→統合) | 78KB |
| p19 vs p20 | LLMルーティング省略 vs 整形層追加 | 46KB vs 162KB |
コードと結果のリポジトリ:https://github.com/koshian2/RAG-Agent-Design-Patterns
※この記事はClaude Codeで書かせました
実験環境
データソース
- 対象: ICCV2025採択論文 2,113本(arXivからダウンロードしたため、マッチングできないものがあり20%ほど対象が減少)
- 保存先: Qdrant(ベクトルDB)に論文の埋め込みを格納
- 前処理: 論文を14の統合トピック、63の細分化トピックに階層的に分類済み
共通条件
- 質問: 「ICCV2025のトレンドを教えて」
- モデル: Claude Sonnet(一部実験でOpusも使用)
- フレームワーク: Strands Agents SDK
事前準備: データパイプライン(p03, p08)
エージェント実験の前に、以下の2ステップでデータを準備しました。
Step 1: 論文要約の生成(p03)
– ICCV2025採択論文2,113本のPDFを取得
– OpenAIのAPI で各論文を構造化要約(コスト対策のために、使うページ数は絞る)
– 出力: 論文ごとのJSON(summary, contributions, methodsなど)
Step 2: トピック分類(p08)
– BERTopicによる自動クラスタリング
– UMAP + HDBSCANで論文をグループ化
– GPT-4oでトピックラベルを生成
– 14個の統合トピックに階層的に集約
これにより、「ベクトル検索だけでなく、階層的なトピック構造を活用した分析」が可能になりました。p10以降の階層的ツール(get_topic_overview, drill_down_topic)は、このp08の出力を活用しています。
Step1で使用したシステムプロンプト
system_prompt = """You will receive images and text from each page of a research paper in alternating order.
Your task is to produce a single JSON object that strictly matches the schema below.
CRITICAL OUTPUT RULES:
1) Output MUST be valid JSON only. Do not output any additional text before or after the JSON.
2) Do NOT include headings, labels, prefixes, approximations, or markers such as:
"≈", "~", "about", "around", "100-word summary:", "200-word summary:", "Summary:", bullet labels, or any similar preface.
3) Each field value MUST be plain narrative prose (sentences/paragraphs). No list markers ("- ", "* ", "1)"), no section titles.
4) Word counts are strict per field (count words separated by whitespace):
- paper_overview: EXACTLY 100 words
- prior_research_limitations: EXACTLY 100 words
- novelty_and_contributions: EXACTLY 100 words
- methodology_details: EXACTLY 100 words
- results_and_validation: EXACTLY 100 words
- discussion_and_limitations: EXACTLY 100 words
- summary: EXACTLY 200 words
5) Keep the content faithful to the paper. Do not invent facts. If something is unclear, state it briefly within the word limit.
Return JSON with these exact keys and in this exact structure:
{
"paper_overview": "",
"prior_research_limitations": "",
"novelty_and_contributions": "",
"methodology_details": "",
"results_and_validation": "",
"discussion_and_limitations": "",
"summary": ""
}
Step2は、Bertopic+HDBSCANで階層クラスタリングしたところ、トピック間の階層性をいい感じにBertopicと(Claude Codeが)束ねてくれたので、Qdrantのデータ構造側に取り込むことができました。トピックを可視化するとこうなりました。
第1章: ツール設計が思考を構造化する(p06 → p10)
ベースライン(p06): 単純な検索ツール
最もシンプルな構成として、単一のエージェントにsearch_papersツールのみを与えました。
参考コード:p06
┌─────────────────────────────────────────────────────────┐
│ p06 構成図 │
├─────────────────────────────────────────────────────────┤
│ │
│ ┌─────────────────────────────────────────┐ │
│ │ RAG Agent (Sonnet) │ │
│ │ │ │
│ │ System: 論文を分析してトレンドを報告 │ │
│ └──────────────────┬──────────────────────┘ │
│ │ │
│ ▼ │
│ ┌────────────────┐ │
│ │ search_papers │ │
│ │ (自由検索) │ │
│ └────────┬───────┘ │
│ │ │
│ ▼ │
│ ┌────────────────┐ │
│ │ Qdrant │ │
│ │ (ベクトルDB) │ │
│ └────────────────┘ │
│ │
└─────────────────────────────────────────────────────────┘
@tool
def search_papers(query: str, top_k: int = 20) -> str:
"""論文をセマンティック検索する"""
results = qdrant_client.search(
collection_name="papers",
query_vector=embed(query),
limit=top_k
)
return format_results(results)
エージェントは自由にクエリを発行し、検索結果を元にレポートを生成します。
## 1. Diffusion Transformerの全面的な進化
- 「X2I」「STIV」「UniVG」など、多数の論文がDiTベースの生成モデルを提案
- U-NetからDiTへの大規模シフトが明確
## 2. 3D Gaussian Splattingの爆発的進化
- レンダリング品質の向上
- Inverse Rendering
- 特殊センサー対応
...
トレンドの列挙としては悪くありませんが、定量的なデータ(論文数、比率)がなく、どのトピックがどれほど重要かが伝わりません。
また、ベクトルDBに対するクエリ作成がLLMの事前知識に基づいており、カンファレンスの新たなトレンドを反映しているとはいえません。
改善版(p10): 階層的ツール群
p10では、データの構造に合わせた専用ツールを設計しました。
参考コード:p10
┌─────────────────────────────────────────────────────────┐
│ p10 構成図 │
├─────────────────────────────────────────────────────────┤
│ │
│ ┌─────────────────────────────────────────┐ │
│ │ Trend Agent (Sonnet) │ │
│ │ │ │
│ │ System: 階層的にトピックを探索して │ │
│ │ トレンドを分析 │ │
│ └──────────────────┬──────────────────────┘ │
│ │ │
│ ┌───────────────┼───────────────┐ │
│ ▼ ▼ ▼ │
│ ┌──────────┐ ┌─────────────┐ ┌─────────────┐ │
│ │ topic │ │ drill_down │ │ topic │ │
│ │ overview │ │ _topic │ │ summary │ │
│ │ (14件) │ │ (63件) │ │ (論文詳細) │ │
│ └────┬─────┘ └──────┬──────┘ └──────┬──────┘ │
│ │ │ │ │
│ └───────────────┴────────────────┘ │
│ │ │
│ ▼ │
│ ┌────────────────┐ │
│ │ 階層的トピック │ │
│ │ データ │ │
│ └────────────────┘ │
│ │
└─────────────────────────────────────────────────────────┘
@tool
def get_topic_overview() -> str:
"""14の統合トピックの一覧と論文数を取得"""
return json.dumps(integrated_topics)
@tool
def drill_down_topic(topic_id: int) -> str:
"""指定トピックの細分化トピック一覧を取得"""
return json.dumps(fine_topics[topic_id])
@tool
def get_topic_summary(fine_topic_id: int, limit: int = 20) -> str:
"""細分化トピックの論文サマリーを取得"""
return fetch_summaries(fine_topic_id, limit)
@tool
def search_papers(query: str, top_k: int = 20) -> str:
"""キーワードによる自由検索"""
...
## 全体傾向
ICCV2025には**2,113本**の論文が採択され、14の統合トピックに分類されています。
### 支配的なトピックと論文分布
1. **Vision-Language Models(580件、27.5%)** - 圧倒的最多
2. **3D Scene Reconstruction(394件、18.7%)** - 第2位
3. **Motion & Interaction Generation(189件、8.9%)**
トップ2トピックだけで全体の**46%以上**を占め、ビジョン・言語の統合と
3D理解がコンピュータビジョン研究の中心軸となっています。
考察: なぜツール設計で品質が変わるのか
ツールはエージェントの「行動の選択肢」を定義します。
- p06: 自由検索のみ → エージェントは「何を検索するか」を自分で考える必要がある
- p10: 階層的ツール → エージェントは自然に「まず全体像を把握 → 詳細を掘り下げ」という思考パターンに誘導される
結果として、p10では論文数や比率といった定量データが自然に出力に含まれるようになりました。ツール設計は、エージェントの思考フローを暗黙的に規定するのです。
第2章: マルチエージェント化の効果と落とし穴(p11 vs p12)
方法A: Agent-as-Tool パターン(p11)
参考コード:p11
複数の専門エージェントを作成し、それらをツールとしてオーケストレーターに渡すパターンです。
┌─────────────────────────────────────────────────────────────────────┐
│ p11 構成図 (Agent-as-Tool) │
├─────────────────────────────────────────────────────────────────────┤
│ │
│ ┌────────────────────────────┐ │
│ │ Orchestrator (Sonnet) │ │
│ │ │ │
│ │ 「適切な専門家に依頼」 │ │
│ └─────────────┬──────────────┘ │
│ │ │
│ ┌────────────────────┼────────────────────┐ │
│ │ │ │ │
│ ▼ ▼ ▼ │
│ ┌───────────────┐ ┌───────────────┐ ┌───────────────┐ │
│ │ Overview Agent│ │Drilldown Agent│ │ Search Agent │ │
│ │ (Sonnet) │ │ (Sonnet) │ │ (Sonnet) │ │
│ │ │ │ │ │ │ │
│ │ 全体傾向分析 │ │ 特定トピック │ │ キーワード │ │
│ │ │ │ 深掘り │ │ 検索 │ │
│ └───────┬───────┘ └───────┬───────┘ └───────┬───────┘ │
│ │ │ │ │
│ ▼ ▼ ▼ │
│ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ │
│ │topic_overview│ │topic_summary │ │search_papers │ │
│ │drill_down │ │search_papers │ │ │ │
│ └──────────────┘ └──────────────┘ └──────────────┘ │
│ │
│ ※ 各エージェントがツールとしてオーケストレーターに渡される │
│ ※ オーケストレーターはエージェントの出力を直接ユーザーに返す │
│ │
└─────────────────────────────────────────────────────────────────────┘
# 専門エージェントの定義
overview_agent = Agent(
model=model,
system_prompt="全体傾向を分析する専門家です",
tools=[get_topic_overview, drill_down_topic]
)
drilldown_agent = Agent(
model=model,
system_prompt="特定トピックを深掘りする専門家です",
tools=[get_topic_summary, search_papers]
)
# オーケストレーターにエージェントをツールとして渡す
orchestrator = Agent(
model=model,
system_prompt="質問に応じて適切な専門家に依頼してください",
tools=[overview_agent, drilldown_agent, search_agent]
)
出力結果(13KB): 各トピックの詳細分析、横断的技術トレンド、今後の研究方向性まで含む包括的なレポート。
方法C: Tool Wrapping パターン(p12)
エージェント呼び出しを@toolでラップし、オーケストレーターが結果を見て次の行動を決定できるようにするパターンです。
参考:p12
┌─────────────────────────────────────────────────────────────────────┐
│ p12 構成図 (Tool Wrapping) │
├─────────────────────────────────────────────────────────────────────┤
│ │
│ ┌────────────────────────────┐ │
│ │ Orchestrator (Sonnet) │ │
│ │ │ │
│ │ 「結果を見て追加分析を判断」 │ ← 結果が返ってくる │
│ └─────────────┬──────────────┘ │
│ │ │
│ ┌────────────────────┼────────────────────┐ │
│ │ │ │ │
│ ▼ ▼ ▼ │
│ ┌───────────────┐ ┌───────────────┐ ┌───────────────┐ │
│ │analyze_ │ │analyze_topic_ │ │ search_papers │ │
│ │ overview │ │ detail │ │ @tool │ │
│ │ @tool │ │ @tool │ │ │ │
│ └───────┬───────┘ └───────┬───────┘ └───────────────┘ │
│ │ │ │
│ ▼ ▼ │
│ ┌───────────────┐ ┌───────────────┐ │
│ │ Overview Agent│ │Drilldown Agent│ ← 内部でエージェント実行 │
│ │ (Sonnet) │ │ (Sonnet) │ │
│ └───────────────┘ └───────────────┘ │
│ │
│ ※ @toolでラップされた関数がエージェントを呼び出す │
│ ※ オーケストレーターは結果を受け取り、次の行動を決定できる(はず) │
│ │
│ 【期待】結果を見て「もっと深掘りしよう」と判断 │
│ 【実際】1回の呼び出しで終了 → 4KBの短いレポート │
│ │
└─────────────────────────────────────────────────────────────────────┘
@tool
def analyze_overview(question: str) -> str:
"""全体傾向を分析"""
result = overview_agent(question)
return result # オーケストレーターが結果を見られる
@tool
def analyze_topic_detail(topic_id: int) -> str:
"""特定トピックを深掘り"""
result = drilldown_agent(f"トピック{topic_id}を分析して")
return result
orchestrator = Agent(
model=model,
system_prompt="結果を見て、必要に応じて追加の分析を依頼してください",
tools=[analyze_overview, analyze_topic_detail, search_papers]
)
期待: オーケストレーターが中間結果を見て「このトピックをもっと深掘りしよう」と判断し、追加のツール呼び出しを行う。
実際の出力結果(4KB): 期待に反して非常に短いレポート。オーケストレーターは1回のツール呼び出しで終了してしまった。
失敗分析: なぜp12は期待通りに動かなかったのか
p12の失敗にはいくつかの仮説が考えられます:
- プロンプトの曖昧さ: 「必要に応じて追加の分析を」という指示が弱く、1回の呼び出しで十分と判断された
- 結果の解釈負荷: 返ってきた長いテキストを解析して次の行動を決めるのはLLMにとって負荷が高い
- 終了条件の曖昧さ: いつ「十分」とするかの基準がない
教訓: マルチエージェントは「パターンを採用すれば動く」わけではなく、オーケストレーターの判断ロジックを明確に設計する必要がある。
第3章: 2段階パイプラインの威力(p15)
設計思想: 分析と統合の分離
p15では、以下の2段階パイプラインを採用しました。これはエージェント時代前のRAGでもよく行われていた手法で、ワークフロー型のエージェントに近いです。
参考コード:p15
┌─────────────────────────────────────────────────────────────────────┐
│ p15 構成図 (2段階パイプライン) │
├─────────────────────────────────────────────────────────────────────┤
│ │
│ ┌────────────────────────────────────────────────────────────┐ │
│ │ Stage 1: 分析フェーズ │ │
│ │ │ │
│ │ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │ │
│ │ │ Topic 1 │ │ Topic 2 │ │ Topic 3 │ │ │
│ │ │ Data │ │ Data │ │ Data │ │ │
│ │ └──────┬──────┘ └──────┬──────┘ └──────┬──────┘ │ │
│ │ │ │ │ │ │
│ │ ▼ ▼ ▼ │ │
│ │ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │ │
│ │ │ Sonnet │ │ Sonnet │ │ Sonnet │ │ │
│ │ │ (分析1) │ │ (分析2) │ │ (分析3) │ │ │
│ │ │ ツールなし │ │ ツールなし │ │ ツールなし │ │ │
│ │ └──────┬──────┘ └──────┬──────┘ └──────┬──────┘ │ │
│ │ │ │ │ │ │
│ │ ▼ ▼ ▼ │ │
│ │ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │ │
│ │ │ Report 1 │ │ Report 2 │ │ Report 3 │ │ │
│ │ └─────────────┘ └─────────────┘ └─────────────┘ │ │
│ │ │ │
│ └────────────────────────────────────────────────────────────┘ │
│ │ │
│ ▼ (全レポートを結合) │
│ ┌────────────────────────────────────────────────────────────┐ │
│ │ Stage 2: 統合フェーズ │ │
│ │ │ │
│ │ ┌─────────────────┐ │ │
│ │ │ Opus │ │ │
│ │ │ (統合) │ │ │
│ │ │ ツールなし │ │ │
│ │ └────────┬────────┘ │ │
│ │ │ │ │
│ │ ▼ │ │
│ │ ┌─────────────────┐ │ │
│ │ │ 最終レポート │ 78KB │ │
│ │ │ (横断分析、 │ │ │
│ │ │ 将来展望含む) │ │ │
│ │ └─────────────────┘ │ │
│ │ │ │
│ └────────────────────────────────────────────────────────────┘ │
│ │
│ ※ Stage 1: Sonnetが各トピックを個別に詳細分析 │
│ ※ Stage 2: Opusが全レポートを俯瞰して統合・洞察生成 │
│ ※ 両ステージともツールなし(Pythonがデータを直接渡す) │
│ │
└─────────────────────────────────────────────────────────────────────┘
# Stage 1: 各トピックの分析(Sonnet)
topic_reports = []
for topic in integrated_topics[:3]: # 上位3トピック
fine_topics = get_fine_topics(topic["id"])
summaries = get_summaries(fine_topics)
report = sonnet_agent(f"""
以下のトピックを分析してください:
トピック: {topic["name"]}
論文数: {topic["count"]}
サブトピック: {fine_topics}
論文サマリー: {summaries}
""")
topic_reports.append(report)
# Stage 2: 統合レポート生成(Opus)
final_report = opus_agent(f"""
以下の分析レポートを統合し、ICCV2025の包括的なサーベイを作成してください:
{chr(10).join(topic_reports)}
""")
出力結果(78KB)
p15は最も構造化された高品質なレポートを生成しました:
# ICCV2025 研究トレンド分析レポート
## 1. 全体傾向
### 1.1 論文数の分布と支配的トピック
...
## 2. 主要統合トピックの詳細分析
### 2.1 Vision-Language Models(580件)
#### 2.1.1 統合トピックの構造
#### 2.1.2 主要課題と技術的アプローチ
#### 2.1.3 横断的技術トレンド
...
## 3. 横断的技術トレンド
### 3.1 基盤モデルのエコシステム形成
### 3.2 拡散モデルの万能化
...
## 4. 産業応用のロードマップ
### 4.1 自動運転(Ready: 2025-2026)
### 4.2 AR/VR(Ready: 2025-2027)
...
比較: 単一ステージ(p17)との差
同じSonnetを使っても、統合フェーズを省略したp17は6KBの出力に留まりました。
| 実験 | 構成 | 出力 |
|---|---|---|
| p17 | Sonnet単一ステージ | 6KB |
| p15 | Sonnet(分析)→ Opus(統合) | 78KB |
p17は、基本的にはp11や12と近いですが、取り込むトピック数や論文数を増やしています(論文単位では、成果や定量評価を落とすなど取り込む内容のスリム化)。これを増やした結果、下位のエージェントでは良好な生成結果を得られたものの、オーケストレーターに統合された際に端折られた出力になってしまうという課題がありました。
考察: なぜ2段階が効果的か
- 役割の明確化: 分析と統合は異なるスキル。分析は「詳細を正確に抽出する」、統合は「全体を俯瞰して構造化する」
- コンテキストの最適化: Stage 1では各トピックに集中でき、Stage 2では全体像に集中できる
- モデル特性の活用: Sonnetは詳細分析に、Opusは高度な構造化・洞察生成に適している
第4章: オーケストレーター不要論と整形層の効果(p19 vs p20)
なぜオーケストレーターを排除するのか
p11〜p14、そして前章で比較対象としたp17でも、LLMがオーケストレーターとして質問を解釈し、適切なエージェントにルーティングする構成を採用していました。しかし実験を通じて、オーケストレーターの存在がむしろ品質を下げている可能性が見えてきました。
オーケストレーターの3つの問題点
1. コンテキストの無駄遣い
【p17: オーケストレーターあり】
オーケストレーターのシステムプロンプト → コンテキスト消費
質問の解釈・分類 → コンテキスト消費
専門エージェントの結果受け取り → コンテキスト消費
↓
専門エージェントが使えるコンテキストが減少
【p19: オーケストレーターなし】
質問分類 = Pythonのキーワードマッチング → コンテキスト消費ゼロ
↓
専門エージェントのコンテキストを100%レポート生成に使える
2. 情報の劣化
オーケストレーターを経由すると、専門エージェントの出力が文字列として渡される際に、意図せず情報が省略される可能性があります。
# オーケストレーター経由(p17)
result = agent(query)
return str(result.message) # ← LLMを経由することで情報が省略されうる
# 直接出力(p19)
answer = extract_text(result)
save_report(answer) # ← 専門エージェントの出力がそのまま保存
3. 責任の曖昧さ
オーケストレーターがいると、専門エージェントは「自分の出力は中間成果物」と認識し、詳細度が下がる傾向があります。
# p17の専門エージェント(オーケストレーター経由)
system_prompt = """
【重要】
- 日本語で回答してください
"""
# p19の専門エージェント(直接出力)
system_prompt = """
【重要】
- 詳細で包括的なレポートを作成すること ← 最終出力者としての責任を明示
- 日本語で回答してください
"""
「自分の出力が最終出力になる」ことを明示することで、エージェントはより詳細なレポートを生成しようとします。
p19: Python分類による直接ルーティング
上記の問題を解決するため、p19ではLLMルーティングを排除し、Pythonで決定論的に分類します。
参考コード:p19
┌─────────────────────────────────────────────────────────────────────┐
│ p19 構成図 (直接ルーティング) │
├─────────────────────────────────────────────────────────────────────┤
│ │
│ ┌──────────────┐ │
│ │ Question │ │
│ └──────┬───────┘ │
│ │ │
│ ▼ │
│ ┌────────────────────────────┐ │
│ │ Python 分類ロジック │ ← LLM不要 │
│ │ │ │
│ │ if "トレンド" in question: │ │
│ │ → overview │ │
│ │ elif "詳しく" in question: │ │
│ │ → drilldown │ │
│ └─────────────┬──────────────┘ │
│ │ │
│ ┌────────────────────┼────────────────────┐ │
│ │ │ │ │
│ ▼ ▼ ▼ │
│ ┌───────────────┐ ┌───────────────┐ ┌───────────────┐ │
│ │ Overview Agent│ │Drilldown Agent│ │ Search Agent │ │
│ │ (Sonnet) │ │ (Sonnet) │ │ (Sonnet) │ │
│ └───────────────┘ └───────────────┘ └───────────────┘ │
│ │ │
│ ▼ │
│ ┌──────────────┐ │
│ │ 最終出力 │ 46KB │
│ └──────────────┘ │
│ │
│ ※ オーケストレーターLLMを省略 → コスト・レイテンシ削減 │
│ ※ ルーティングロジックが明示的で予測可能 │
│ │
└─────────────────────────────────────────────────────────────────────┘
def classify_question(question: str) -> str:
"""質問を分類(LLM不要)"""
if any(kw in question for kw in ["全体", "トレンド", "傾向", "概要"]):
return "overview"
elif any(kw in question for kw in ["詳しく", "深掘り", "具体的"]):
return "drilldown"
else:
return "search"
def run_agent(question: str):
q_type = classify_question(question)
if q_type == "overview":
return overview_agent(question)
elif q_type == "drilldown":
return drilldown_agent(question)
else:
return search_agent(question)
出力結果(46KB): オーケストレーターLLMを省略したにもかかわらず、p17(6KB)を大幅に上回る詳細なレポートを生成。
なぜp19が優れているのか:
| 観点 | p17(オーケストレーターあり) | p19(直接ルーティング) |
|---|---|---|
| コンテキスト効率 | オーケストレーターが消費 | 100%生成に使える |
| 情報損失 | 中間層で省略リスク | 直接出力で損失なし |
| 責任の明確さ | 「中間成果物」意識 | 「最終出力者」意識 |
| 出力サイズ | 6KB | 46KB |
設計原則:
– 決定論的にできることはコードで行う(質問分類など)
– LLMには創造的・分析的タスクのみを委ねる
– 「最終出力者」という責任をエージェントに明示する
p20: 整形層の追加による構造化
p19の設計思想(オーケストレーター排除、直接ルーティング)を踏襲しつつ、整形専用のエージェントを追加したのがp20です。
目的は、専門エージェントの詳細な分析結果を、より読みやすい報告書形式に構造化することです。
参考コード:p20
┌─────────────────────────────────────────────────────────────────────┐
│ p20 構成図 (Formatter追加) │
├─────────────────────────────────────────────────────────────────────┤
│ │
│ ┌──────────────┐ │
│ │ Question │ │
│ └──────┬───────┘ │
│ │ │
│ ▼ │
│ ┌────────────────────────────┐ │
│ │ Python 分類ロジック │ │
│ └─────────────┬──────────────┘ │
│ │ │
│ ▼ │
│ ┌────────────────────────────┐ │
│ │ Specialist Agent │ │
│ │ (Sonnet) │ │
│ │ │ │
│ │ ツールを使って分析 │ │
│ └─────────────┬──────────────┘ │
│ │ │
│ ▼ (raw_report) │
│ ┌────────────────────────────┐ │
│ │ Formatter Agent │ ← 追加された層 │
│ │ (Sonnet) │ │
│ │ │ │
│ │ ツールなし │ │
│ │ 「整形のみ」を指示 │ │
│ └─────────────┬──────────────┘ │
│ │ │
│ ▼ │
│ ┌──────────────┐ │
│ │ 最終出力 │ 162KB │
│ └──────────────┘ │
│ │
│ ※ 整形層は「分類」ではなく「加工」なのでオーケストレーターとは異なる │
│ ※ 用途に応じて選択: 密度重視→p19、網羅重視→p20 │
│ │
└─────────────────────────────────────────────────────────────────────┘
# 専門エージェントの出力を取得
raw_report = specialist_agent(question)
# 整形エージェントで仕上げ
formatter = Agent(
model=model,
system_prompt="""
以下のレポートを整形してください:
- 構造を明確に
- 重複を排除
- 読みやすいフォーマットに
""",
tools=[] # ツールなし
)
final_report = formatter(raw_report)
出力結果(162KB): エグゼクティブサマリー、統計表、「残された課題と今後の方向性」を各セクションに配置した、プロフェッショナルな報告書形式。
※ただ、もともと出力が多いところに、オーケストレーターを通じて二段階で生成させることで、p20は明らかに遅いというデメリットがあります。30分ぐらい経っても終わっていなかったので、結構トークン食ってる説はあります。
現実的には、p19のオーケストレーターなしがコスパが良いのではないかと思われます。
p19とp20の使い分け
両者はオーケストレーター排除という設計思想を共有しており、用途によって選択すべきです。
| 観点 | p19 | p20 |
|---|---|---|
| 出力サイズ | 46KB | 162KB |
| 構造 | 密度重視(情報量/文字数が高い) | 網羅重視(個々の研究を詳細に記述) |
| 推奨用途 | 研究者向け、論文探索の起点 | 各研究を細かく追いたい人向け |
| 特徴 | 各手法の課題・アプローチ・新規性が明確 | 個別研究の詳細記述、章立て・統計表も整備 |
p19の強み: 具体的な手法名(VRM、SCOP、VIBE、FreeCus等)と、それぞれの「課題→アプローチ→新規性」の三段構成が明確。研究者が実際に論文を探す際に有用。
p20の強み: 「中心的な課題」「主要アプローチと革新性」「残された課題と今後の方向性」という構造が各サブトピックに一貫して適用。全体統計、エグゼクティブサマリーも完備。
設計原則としての教訓
| 原則 | p17(悪い例) | p19/p20(良い例) |
|---|---|---|
| 責任の明確化 | オーケストレーター=分類者、専門エージェント=実行者の二重構造で責任が曖昧 | 専門エージェントが最終出力まで責任を持つ |
| コンテキスト効率 | LLMに分類させてコンテキストを浪費 | 分類は決定論的ロジックで、LLMは生成に集中 |
| 情報の劣化防止 | 中間層を経由するたびに情報が省略される可能性 | 中間層なしで直接出力(p20の整形層は加工であり分類ではない) |
| 指示の明確さ | 「詳細」という指示がない | 「詳細で包括的なレポートを作成すること」と明示 |
重要な発見: オーケストレーターの設計よりも、専門エージェントへのプロンプト設計と「最終出力者」としての責任の明示が品質に大きく影響する。
まとめ: エージェント設計の5つの指針
本実験を通じて得られた知見を、設計指針としてまとめます。
1. ツール設計が思考を構造化する(p06 → p10)
- 自由度の高いツール(汎用検索)より、タスクの構造を反映したツール群を設計する
- ツールの選択肢がエージェントの思考パターンを暗黙的に誘導する
- データに階層構造があるなら、それに対応した階層的ツールを用意する
2. マルチエージェントはパターン選択が重要(p11 vs p12)
- 「マルチエージェント」という概念だけでは不十分、実装パターンで成否が分かれる
- Agent-as-Tool(p11)は専門化による網羅性向上に成功
- Tool Wrapping(p12)はオーケストレーターの判断ロジックが曖昧で失敗
- 失敗時は「なぜそのパターンが期待通り動かなかったか」を分析する
3. 2段階パイプライン(分析→統合)が効果的(p15)
- 分析と統合は異なるスキル、役割を分離することで品質向上
- モデル特性に合わせた分業(Sonnet: 詳細分析、Opus: 構造化・洞察)
- 単一エージェントに全てを任せると、どちらかが犠牲になりがち
4. オーケストレーターは品質を下げうる(p19)
- LLMルーティングはコンテキストを浪費し、情報を劣化させる
- 質問分類はPythonでのルールベース分類で十分なケースが多い
- 専門エージェントに「最終出力者」としての責任を明示することで詳細度が向上
- 決定論的にできることはコードで行い、LLMは創造的タスクに集中させる
5. 用途に応じた設計選択(p19 vs p20)
- p19(整形なし): 密度重視、研究者向け、論文探索の起点
- p20(整形あり): 網羅重視、個々の研究を細かく追いたい人向け
- エージェント追加の判断基準は「単純化か複雑化か」ではなく「用途に合っているか」
おわりに
エージェント設計は「とりあえずマルチエージェントにすれば良くなる」という単純なものではありません。本実験で示したように、ツール設計、パターン選択、パイプライン構成、ルーティング方式といった設計判断の一つ一つが、最終的な出力品質に大きく影響します。
重要なのは、各設計判断の意図と効果を明確にし、実験的に検証することです。p12のように期待通りに動かないケースも、失敗分析を通じて次の改善につながります。
本記事で紹介した実験コードは、論文サーベイ生成という特定のタスクに基づいていますが、得られた設計指針は他のRAGタスクにも応用可能です。ぜひ皆さんのプロジェクトでも、エージェント設計の選択肢を意識的に検討してみてください。
(ここまでClaude Codeが書いてところどころ自分が補足)
自分の所感
(ここは自分が書いています)
オーケストレーターがあるとむしろ劣化してしまうは衝撃でした。この例はDeep Researchに近い長文RAGの例なので、2段階のようにプリミティブな例がまだ戦えるのでしょう。
おそらくオーケストレーターは、ルールベースである必要はなく、LLMとコンテクストを共有していない(これは2段階の思想)のが大事なので、例えば軽い言語モデルや分類モデルで行うというのがもう少し発展型なのかなと思いました。
にしても、これだけの実験とレポートをClaude Codeにやらせたら1日でできてしまったのですごいですね。エージェントの設計とかあんま知らなかったのですが、設計からClaude Codeに聞いていったらかなり本質的なところまでわかったので「もはや自分はなんのためにいるのだろう」感は割とありました。
あとは今回Strands Agentsをはじめて使ったのですが、おそらくLLMのナレッジカットオフギリギリの内容かと思われるのに、かなりClaude Code側でバリバリかけてたので良かったですね。設計や抽象化が多分良いのでしょう。
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー