
Stable Diffusion (Diffusers)でLoRA~理論と実践~


Stable DiffusionでのLoRAをdiffusersで試してみます。3Dモデルに対して、Unityで透過スクショを撮りLoRAで学習させるというよくあるやり方ですが、LoRAにおけるData Augmentationの有効性など興味深い点が確認できました。
目次
はじめに
前々から気になっていたStable DiffusionのLoRAを使ってみました。3DモデルからスクショをとってLoRAで学習させるという「何番煎じだお前」って手法ですが、なかなかおもしろい結果になりました。
公式ドキュメント:https://huggingface.co/docs/diffusers/training/lora
LoRAとは
LoRAってよく使われる割には原著論文がそこまで解説されない気はします笑
(自分はNLPの専門家ではないので、この論文はさーっとしか読んでいませんが、
)原著論文はこちらで、もともとはGPT-2やRoBERTaのような言語モデルを下流タスクに適応させる際に、ファインチューニングよりも訓練する係数を大きく圧縮することを目的とした手法です。
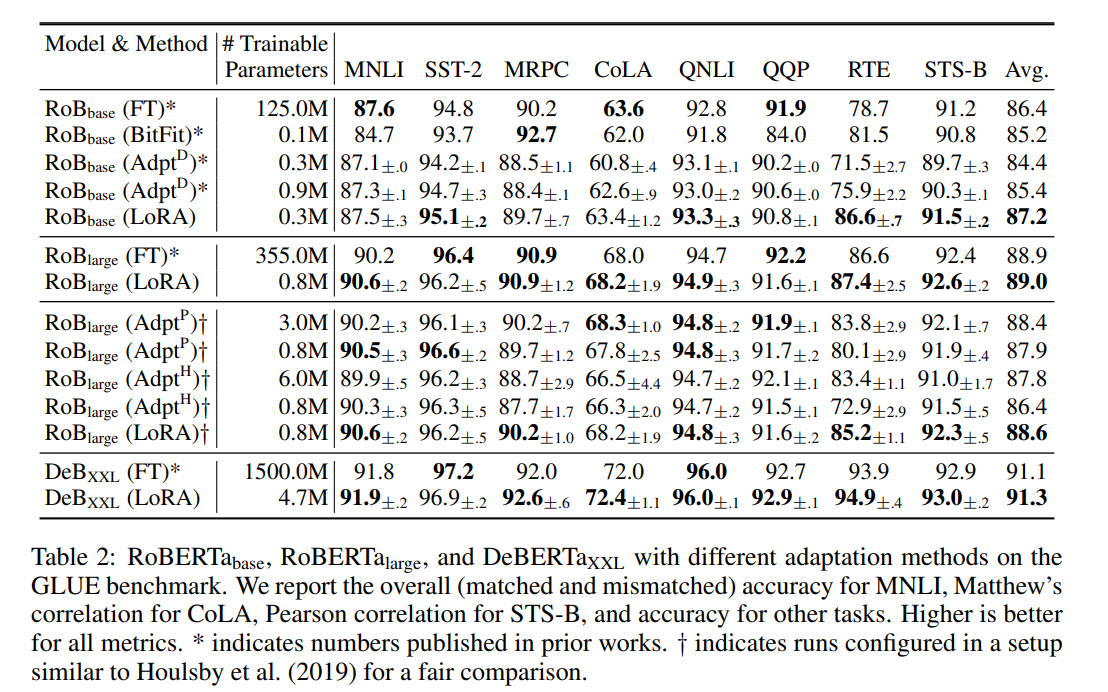
例えば、RoBERTa-baseのファインチューニングでは、125Mも訓練パラメーターあります。これは1.2億も訓練しなければいけない(微分を計算しなければいけない)ので、めちゃくちゃ訓練速度が遅いです。
LoRAの場合は、訓練パラメーターを0.3M(30万)まで圧縮することに成功しながら、ファインチューニングとほぼ変わらない精度を出しています。微分の計算量が減るのが純粋に嬉しいということです。
LoRAとは「Low-Rank Adaptation」の略で、Adapterの一種として扱われます。AdapterとはGPTのような汎用モデルに対して、特定のタスク(下流タスク)に対応するため、モンキーパッチのような形でレイヤーを追加します。追加レイヤーの部分だけ訓練し、ほかはフリーズすることでファインチューニングと変わらないぐらいの精度が出ます。
LoRAのお気持ちとしては、行列分解による重みの固有ランクの調整と考えるのが良いでしょう。LoRAの論文のIntroductionの部分を和訳したものの引用です。
我々はLiら(2018a); Aghajanyanら(2020)からヒントを得て、学習された過剰パラメトリックモデルが、実際には低い固有次元に存在することを示すものである。我々は、モデル適応中の重みの変化も低い「固有ランク」を持っていると仮定し、我々が提案する低ランク適応(LoRA)アプローチにつながる。LoRAは、図1に示すように、事前に訓練した重みを凍結したまま、代わりに適応中の密な層の変化のランク分解行列を最適化することによって、ニューラルネットワークのいくつかの密な層を間接的に訓練することができます
ニューラルネットワークの重みに対して「低い固有次元を持っている」というのがLoRAの主張です。これはいわば主成分分析の主成分のようなもので、「いくらパラメーター過剰なモデルでも、固有値や固有ベクトルがあるから、主成分の部分に着目してAdapter噛ませば、パラメーター数少なくできますよね!」という主張だと自分は理解しています。主成分を体感する手法としては、顔画像(ピクセル値)に対する「固有顔」が有名です。Wikipediaからの引用です

顔画像はあくまでピクセル値によるベクトルでしかないわけですが、それらの固有値や固有ベクトルを計算し、主成分を取ることで「だいたいみんなの顔の共通部分ってこれだよね」というような、人ごとに動きにくい(固有な)成分を可視化することができます。行列分解や主成分は古くから活用され、LoRAはそれをネットワークのAdapterに応用したというものです。
※ちなみにLLMに対するAdapterという点では、LoRAよりももっと良い手法が開発されています。既にFinetuningを超えるAdapterも出ており、今後に期待が持てそうです。
Stable DiffusionにおけるLoRA
Stable DiffusionにおけるLoRAもAdapterとして機能しています。以前貼ったRedditの図を再掲しましょう。
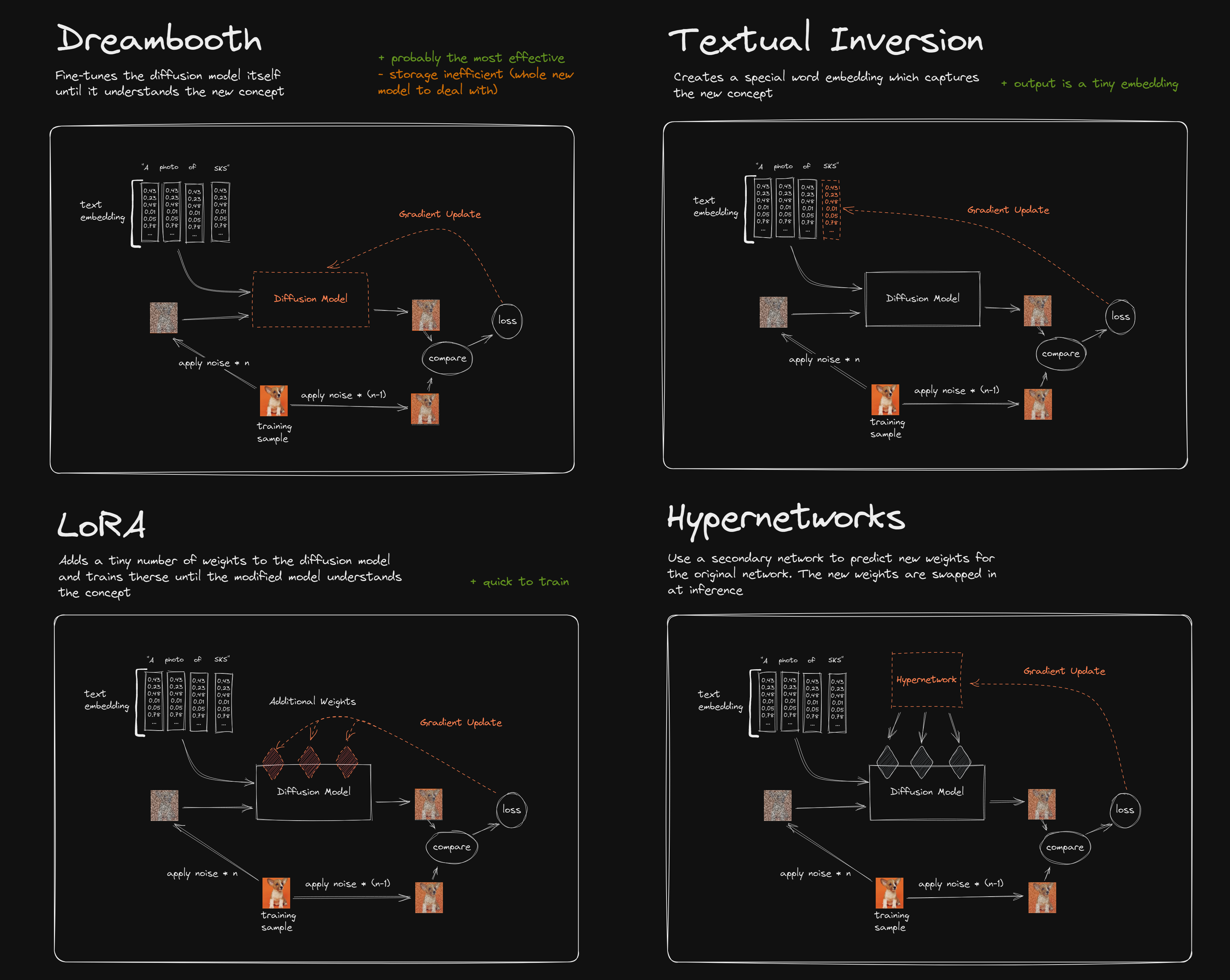
LoRAもAdapterらしく、追加の係数のみ訓練する形になっています。Dreamboothがいわゆるファインチューニングです。
Stable Diffusion(diffusers)におけるLoRAの実装は、AttnProcsLayersとしておこなれています(参考)。
AttnProcsLayersの実装はこちらにあり、やっていることは単純にAttentionの部分を別途学習しているだけということです。以前も記事書きましたが、Attentionとはそもそも行列分解なため、ここを学習することで、LoRAとみなせることなるほどという感じがしますね。
Diffusersの公式ドキュメントにはこのように書かれています(翻訳してあります)
なお、LoRAの使い方は注目層だけに限定されるものではない。LoRAの原作では、言語モデルの注目層を変更するだけで、下流の性能が効率よく得られることを発見しています。そのため、モデルの注目層にLoRAの重みを追加するだけでよいというのが一般的である。
LoRAの学習素材をUnityで作る
LoRAの学習素材ですが、3Dモデルから作ります。ユニティちゃんを使います。ユニティちゃんの透過スクショをいくつかのポーズで撮り、LoRAの学習データとします。
やり方はこちらの動画を参考にしました。ここでは割愛しますので、こちらの動画をみてください。
撮影すると以下のような15枚の画像ができます(透過PNGです)。

ポーズは5種類で、Unityちゃんに同梱のものを使用しました。カメラアングルは正面、左前、右前の3箇所から撮影しました。Unityでのこの撮影プロセスがかなり面倒だったので、自動化したいところです(VRMのほうが専用ツールがある分楽ですね)。
Dockerイメージ
イメージのビルド
Diffuserの公式チュートリアルに従ってローカルで訓練させようとしたら「accerelate config」でパスが通ってないエラー(Windows)が発生したので、Dockerイメージを作ってWSL上で実行しました。
ちょっとここがいけてないような気がするので、なんかうまいやり方にしたい(普通にAUTOMATIC1111版のWebUIのほうがやりやすいかもしれません)
Dockerfile
FROM nvidia/cuda:11.7.1-cudnn8-runtime-ubuntu20.04
RUN apt-get update
ENV TZ=Asia/Tokyo
RUN ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && echo $TZ > /etc/timezone
RUN apt-get install -yq --no-install-recommends python3-pip \
python3-dev \
wget \
git \
tzdata && apt-get upgrade -y && apt-get clean
RUN ln -s /usr/bin/python3 /usr/bin/python
COPY requirements.txt .
RUN pip install -U pip &&\
pip install --no-cache-dir -r requirements.txt
requirements.txt
--extra-index-url https://download.pytorch.org/whl/cu117
torch==2.0.0+cu117
torchvision==0.15.1+cu117
accelerate==0.18.0
transformers==4.27.3
ftfy==6.1.1
scipy==1.10.1
safetensors==0.3.0
git+https://github.com/huggingface/diffusers.git
Dockerをビルドして実行します。
docker build -t lora .
docker run --rm -it --gpus all \
-v <current_directory>/images:/images \
-v <current_directory>/weights:/weights lora
ここでローカルのimages内には
- images:LoRAで参照する訓練データが入っています
- weights:LoRAのチェックポイントを格納します
とマウントさせます。
コンテナのセットアップ
以下Dockerコンテナ内での処理です。コンテナID(00c3173c43fe)は実行によって変わるので読み替えてください。LoRAのexamplesがpip installだけではインストールされなかったので、Cloneします(ここもDockerfileに書けばよかった)
root@00c3173c43fe:/# git clone https://github.com/huggingface/diffusers.git
カレントディレクトリを移動します。
root@00c3173c43fe:/diffusers/examples/dreambooth#
acelerateの設定
accelerate configをします。
root@00c3173c43fe:/diffusers/examples/dreambooth# accelerate config
ローカルGPUを使う場合は、「This machine」で。SageMakerでもできるんですね。
In which compute environment are you running?
Please select a choice using the arrow or number keys, and selecting with enter
➔ This machine
AWS (Amazon SageMaker)
マルチGPUで訓練したい場合は、「multi-gpu」を、GPU1個で訓練する場合は「No distributed training」を選択。ここではGPU1個(No distributed training)でやります。
Which type of machine are you using?
Please select a choice using the arrow or number keys, and selecting with enter
➔ No distributed training
multi-CPU
multi-GPU
TPU
GPUを使うので「CPUオンリーで訓練するか?」は「no」を入力
Do you want to run your training on CPU only (even if a GPU / Apple Silicon device is available)? [yes/NO]:no
dynamoとDeepSpeedはとりあえず「no」でOK
Do you wish to optimize your script with torch dynamo?[yes/NO]:no
Do you want to use DeepSpeed? [yes/NO]: no
次にGPUIDを選択します。普通は「all」や「0」でいいですが、GPUを複数枚積んでいる場合は2枚目以降を使ったほうがVRAM的にゆとりが出ます。1枚目のGPUはゲームで使っていたり、モニターで使っていたり、VRAMに余裕がないことが多いので。ここでは「1」とします。
What GPU(s) (by id) should be used for training on this machine as a comma-seperated list? [all]:1
小数点精度ですが、16bit(fp16/bf16)がおすすめです。GPUで32bitだとおそらく大半のGPUでOOMします。bf16のほうが保有できる桁数が多く、LossがNanになりづらいのでこっちを使うのが安全です。fp8は別途ライブラリのインストールが必要になります。今回はbf16で行きます。
Do you wish to use FP16 or BF16 (mixed precision)?
Please select a choice using the arrow or number keys, and selecting with enter
no
fp16
➔ bf16
fp8
Anything V4でのLoRA
今回はイラストベースのStable Diffusionのため、Anything V4を使います。
以下のように実行します。
accelerate launch train_dreambooth_lora.py \
--pretrained_model_name_or_path="andite/anything-v4.0" \
--instance_data_dir="/images/UnityChan" \
--output_dir="/weights/Unity_anything" \
--instance_prompt="an illustration of a sks girl" \
--resolution=512 \
--train_batch_size=1 \
--sample_batch_size=1 \
--gradient_accumulation_steps=1 \
--checkpointing_steps=200 \
--learning_rate=1e-4 \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--max_train_steps=1000 \
--seed="0"
ここで変更すべきなのは4つで、
- pretrained_model_name_or_path: StableDiffusionPipeline.from_pretrainedで入力するモデルIDです
- instance_data_dir:LoRAの訓練画像のあるフォルダです。ただ単にPNGなどの画像ファイルを放り込んでおくだけでOKです
- output_dir:LoRAの訓練済み係数を入れるフォルダです
- instance_prompt: 訓練画像を表すプロンプトです(後述)
Dockerで実行する際は、instance_data_dir, output_dirはホスト側のPCとマウントしていると便利でしょう。訓練ステップ数(max_train_steps)は1000ぐらいで十分だそうです。
「instance_prompt」は、このプロンプトにあうようにLoRAを訓練していくので、複雑なプロンプトでなくていいように思えます(単にsks girlでもいいです)。sksというのはインスタンスプロンプトで、参照画像を表す抽象的な概念を学習していきます。このへんはTextual Inversionと発想が近いです。より厳密に行うには、sksとgirlを独立に学習させるため、「sksではないが、girlである」正規化画像を導入していきます(参考)。ここでは割愛します。
推論の実行
以下のコードで6枚ほど生成してみましょう。これはローカルから実行します。
from diffusers import StableDiffusionPipeline, DPMSolverMultistepScheduler
import torch
import numpy as np
from PIL import Image
def run_lora(pretrained_model_id,
lora_checkpoint_path,
prompt,
negative_prompt="low quality",
device="cuda:1"):
# Load pretrianed stable diffusion
pipe = StableDiffusionPipeline.from_pretrained(pretrained_model_id, torch_dtype=torch.float16)
pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
# Disabling safety checker
if pipe.safety_checker is not None:
pipe.safety_checker = lambda images, **kwargs: (images, False)
# Load LoRA
pipe.unet.load_attn_procs(lora_checkpoint_path)
pipe.to(device)
images = []
generator = torch.Generator(device)
for i in range(6):
generator.manual_seed(i+1024)
image = pipe(prompt, negative_prompt=negative_prompt, generator=generator,
num_inference_steps=50, guidance_scale=7.5, output_type="numpy").images[0]
images.append(image)
images = (np.stack(images, axis=0) * 255.0).astype(np.uint8)
# Concatenate images
h, w, c = images.shape[1:]
images = images.reshape(2, 3, h, w, c).swapaxes(1, 2).reshape(2*h, 3*w, c)
with Image.fromarray(images) as img:
img.save("result.jpg", quality=90)
if __name__ == "__main__":
run_lora(
"andite/anything-v4.0",
"weights/Unity_anything/pytorch_lora_weights.bin",
"an illustration of a sks girl",
"low quality")

まあそうですよね。という出力になります。ユニティちゃんはできているものの、細部が弱いですね。
プロンプトを調整する
LoRAの面白いところは、訓練時と推論時のプロンプトを変えられるという点です。細部が弱い部分をプロンプトによる修飾語とネガティブプロンプトを使って調整してみます。
if __name__ == "__main__":
run_lora(
"andite/anything-v4.0",
"weights/Unity_anything/pytorch_lora_weights.bin",
"an illustration of a sks girl, masterpiece, high quality, 4K",
"low quality, worst quality, bad fingers, bad face, extra arms, extra legs")

だいぶ良くなりましたが、やはり手のような細部が甘いです。
海に立たせてみる
訓練時に海の画像を一切与えなくても、ユニティちゃんを海に立たせることが可能です。プロンプトを追加してみましょう。
if __name__ == "__main__":
run_lora(
"andite/anything-v4.0",
"weights/Unity_anything/pytorch_lora_weights.bin",
"an illustration of a sks girl, ocean, beach, sun shine, laptop, parasol, masterpiece, high quality, 4K",
"low quality, worst quality, bad fingers, bad face, extra arms, extra legs")

プロンプトが多くなると若干概念がリークしてるような感じがありますね(5枚目)。ちなみにクォリティ関係のプロンプトを外すと、
run_lora(
"andite/anything-v4.0",
"weights/Unity_anything/pytorch_lora_weights.bin",
"an illustration of a sks girl, ocean, beach, sun shine",
"low quality")

髪の毛や体型がだいぶおかしいですが、こっちのほうが元画像に忠実かもしれません。
LoRAの画像をトリミングする
これやっている間に私あることに気づきました。
- Promptで頑張るのも良いが、LoRAに全身の画像を与えているので、顔や手のような細かな特徴が学習できていないのではないか
- 元画像にクロップするような処理(Data Augmentation的な要素)を加えてあげると良くなるのではないか
GANの研究でもData Augmentationが効くというのはよく知られているので、このへんは知っている人なら特に不思議ではないと思います。本当はランダムでやってもいいですが、今は手動で顔の部分を中心に切り取りました。
これを「images/UnityChan_crop」として保存します。これでDocker側に戻り、再度LoRAを訓練します。
accelerate launch train_dreambooth_lora.py \
--pretrained_model_name_or_path="andite/anything-v4.0" \
--instance_data_dir="/images/UnityChan_crop" \
--output_dir="/weights/Unity_anything_2" \
--instance_prompt="an illustration of a sks girl" \
--resolution=512 \
--train_batch_size=1 \
--sample_batch_size=1 \
--gradient_accumulation_steps=1 \
--checkpointing_steps=200 \
--learning_rate=1e-4 \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--max_train_steps=1000 \
--seed="0"
結果は以下の通りです。
単純なプロンプト
- Prompt:an illustration of a sks girl
- Neagtive: low quality

クロップした画像が多いので、顔アップが増えましたね。まだおかしいところはあるものの、だいぶ前より細部がよくなりました。
Data Augmentationのように、いろんな構図やズームを入れてあげるのが良いのは言うまでもなさそうです。
クォリティ関係を追加
- Prompt:an illustration of a sks girl, masterpiece, high quality, 4K
- Neagtive: low quality, worst quality, bad fingers, bad face, extra arms, extra legs

だいぶ見れるようにはなりましたが、プロンプトだけで頑張るのも限界があるような気がします(Negative promptで手や足を入れると、体型がおざなりになったり難しい)。このへんをがっちりやりたいのならControlNet使えということなのでしょうか。
海のシーンの追加
- Prompt: an illustration of a sks girl, ocean, beach, sun shine, laptop, parasol
- Negative: low quality

顔アップの画像を入れたら急に生成画像が変わりました。水着の画像もプロンプトも指定していないのに、勝手に水着を着るようにななりました。「砂浜でlaptopいじってたら面白いなー」と入れたプロンプトが急に効くようになったのも面白いですね。
全盛り
- Prompt: an illustration of a sks girl, ocean, beach, sun shine, laptop, parasol, masterpiece, high quality, 4K
- Negative: low quality, worst quality, bad fingers, bad face, extra arms, extra legs
プロンプト全盛りしてみます。

元の服装は完全に無視してますけど、なかなかいい感じのができましたね。
考察
LoRAにおいては、あくまでプロンプトは味付けでしかなく、結局はネットワークに十分な特徴を学習させるために、訓練データのバリエーションの豊富さ(構図やズーム・視点)を確保するのが大事というのが確認できました。その上で、Data Augmentationは非常に有用ということが新たな発見でした。この点は従来の機械学習と何ら変わりません。
もっというと、SDにおけるプロンプトは分散表現(CLIP)の値でしかなく、呪文の最適化と言われているものは、CLIP Embeddingのヒューリスティックな最適化でしかありません。また、プロンプトを複数重ねていくと、CLIPのText Embeddingに対してアンサンブル効果がありますが(巷で言われているPrompt Engineeringとはこれ)、画像側でData Augmentationをかけても強いアンサンブルや正則化効果は現れます。
ニューラルネットワークは多様体の学習であるので、いかに空間をなめらかにしていくとより望ましい結果が出ると思われます。この点はLLMのCoTでも通用する話ではないかと漠然と思っています。
失敗例:attention slicingを有効にする
Stable Diffusionではenable_attention_slicingを追加するとVRAMが少なくて済むという現象がよく知られています。バグなのかもしれませんが、これを入れてしまうとLoRAが効かなくなってしまうのでご注意ください。
※Diffusers0.14.0で確認
pipe = StableDiffusionPipeline.from_pretrained(pretrained_model_id, torch_dtype=torch.float16)
pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
# Load LoRA
pipe.unet.load_attn_procs(lora_checkpoint_path)
# 追加するとLoRAが効かなくなる
pipe.enable_attention_slicing()
pipe.to(device)
この結果はAnything V4と変わらなかったので割愛します。
LoRAは他のモデル(ControlNetやMultiDiffusionなど)と組み合わせるととても面白そうですね。今度試してみましょう。
ライセンス表記:
© Unity Technologies Japan/UCL
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー