
論文まとめ:Extremely Simple Activation Shaping for Out-of-Distribution Detection
Posted On 2022-11-23


- タイトル:Extremely Simple Activation Shaping for Out-of-Distribution Detection
- 著者:Andrija Djurisic, Nebojsa Bozanic, Arjun Ashok, Rosanne Liu
- 論文URL:https://arxiv.org/abs/2209.09858
- プロジェクトページ:https://andrijazz.github.io/ash/
- コード:https://github.com/andrijazz/ash
目次
ざっくりいうと
- ニューラルネットワークの学習データについて、分布内(ID)か、分布外(OOD)かを見分ける研究
- 訓練済みネットワークのロジットの直前の値を使い、上位○%をマスクし、エネルギースコアを計算する
- 非常に単純な仕組みながらSoTAの性能を達成
忙しい人向け
これでOODの検知ができる
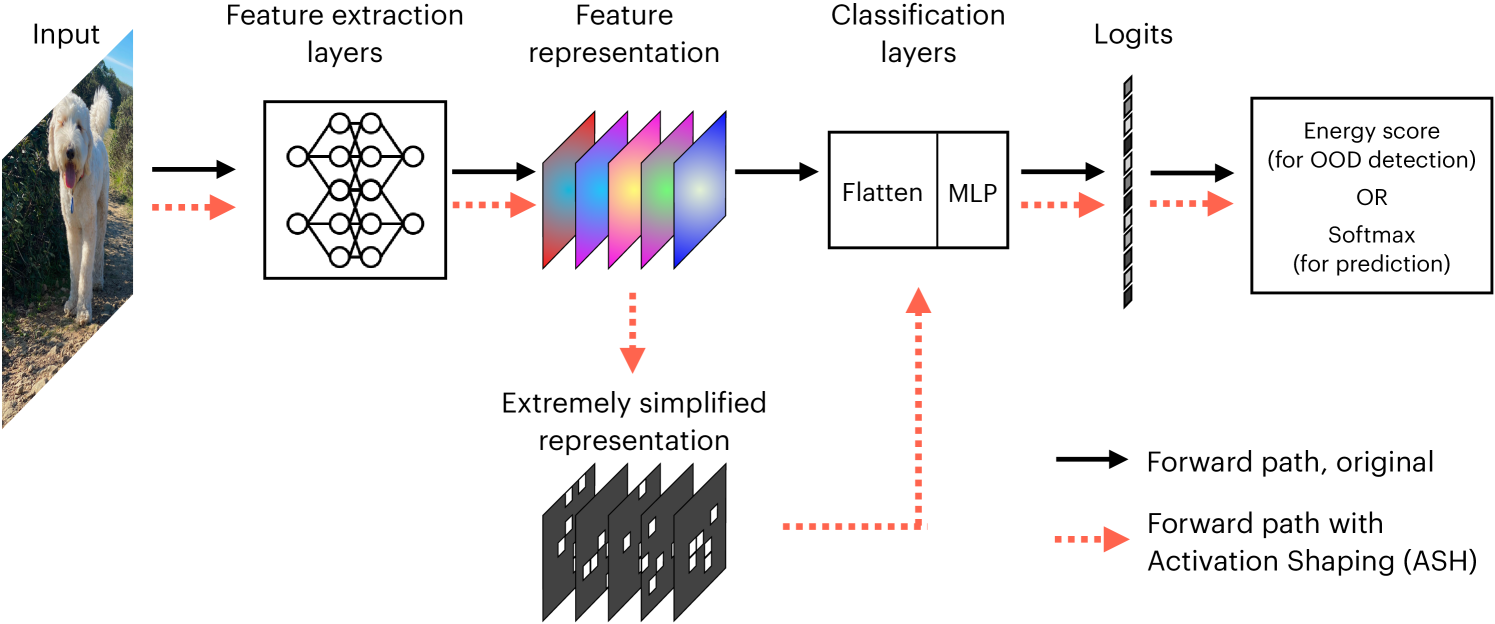
OOD検知の流れ
- モデル(例:分類器)を訓練する。ここで学習したデータをin-distribution(ID)とする。
- モデルの係数を固定
- 推論時にout-of-distribution(OOD)のデータを与える。
- モデルに与えられたデータがIDかOODかを区別するために、モデルの出力からスコアを出す検出器を作る
- OOD検知の性能を様々な指標で評価
スコアってどう出すの?
負のエネルギースコア(negative energy score)を求める。
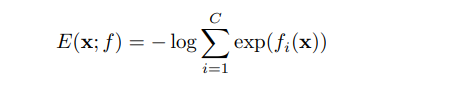
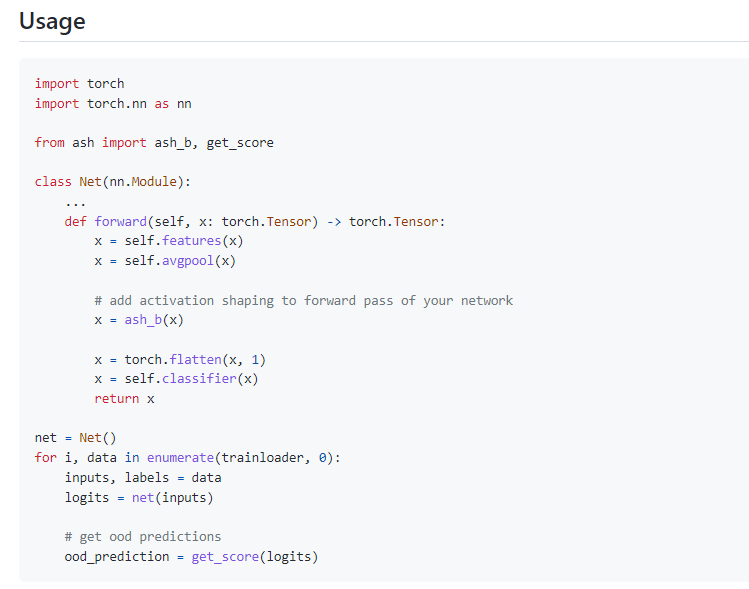
分類モデルのロジットを使うだけで、OOD検知の部分で新たに訓練はしない。
ASH
ASHではASH-P、ASH-B、ASH-Sという3手法を検証。
- (共通)活性化関数の値の大部分を除去する。具体的には、表現全体(Global Abverage Poolingの値)のTop-p%にあたるしきい値tを求め、しきい値以下の部分を0で埋める
- 3つのアルゴリズムからなる
- ASH-P:何もしない。PruningのPで、「Pruning is all we need」
- ASH-B:しきい値以上の部分に定数値を埋める。BinaryのB
- ASH-S:しきい値で除去した割合に応じて、しきい値以上の値に定数倍をかける。ScaleのS

定量評価
SoTAだった。ASH-Pは悪い。
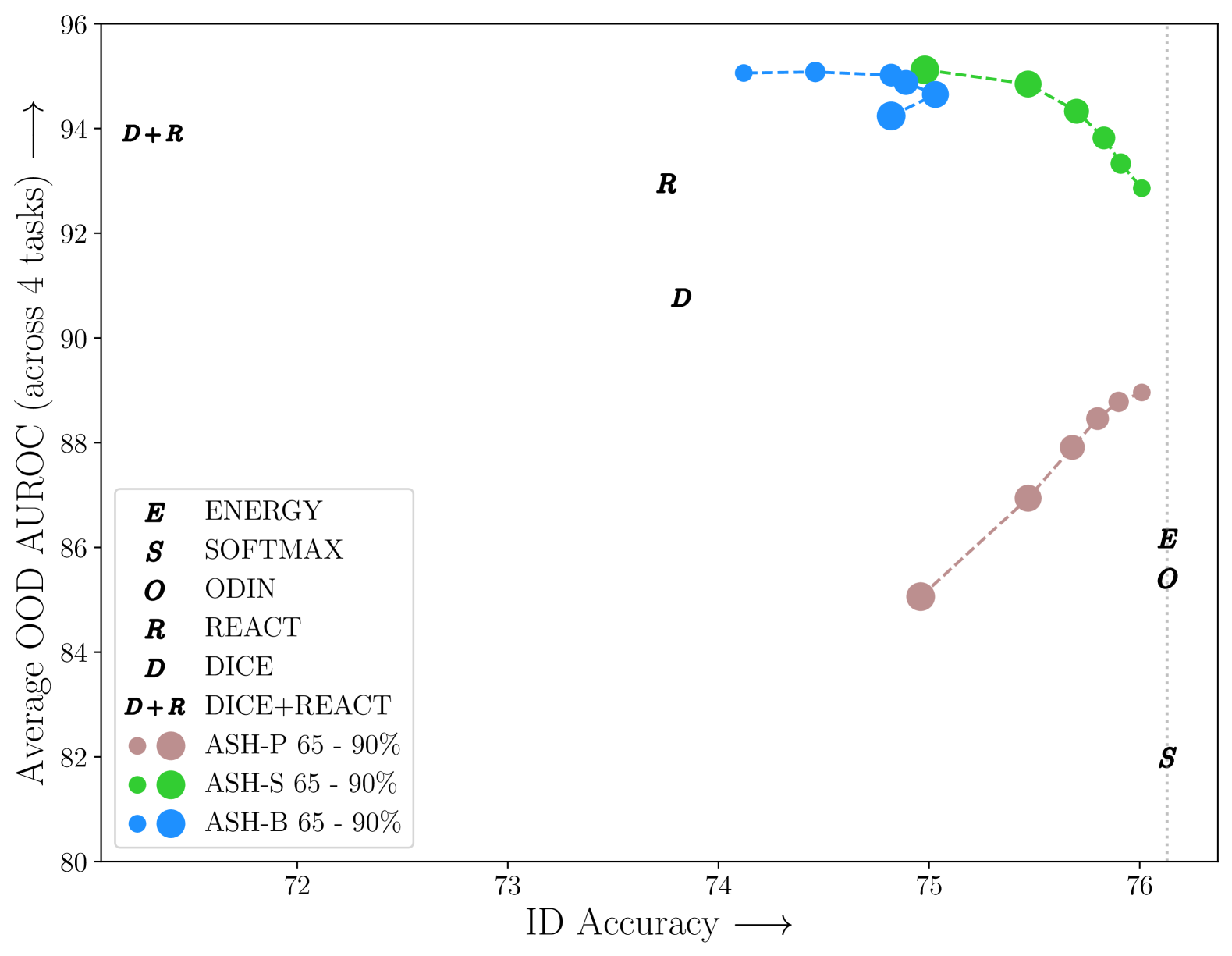
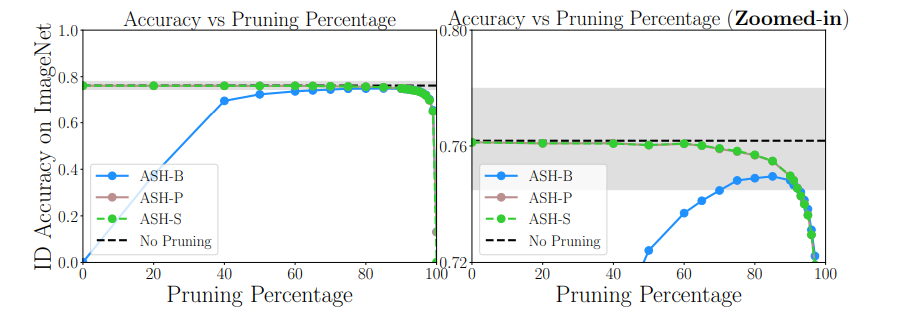
ID(in-distribution)の精度とpの関係
結局ASH-Sが一番安定する。削りすぎるとIDの精度が悪くなる
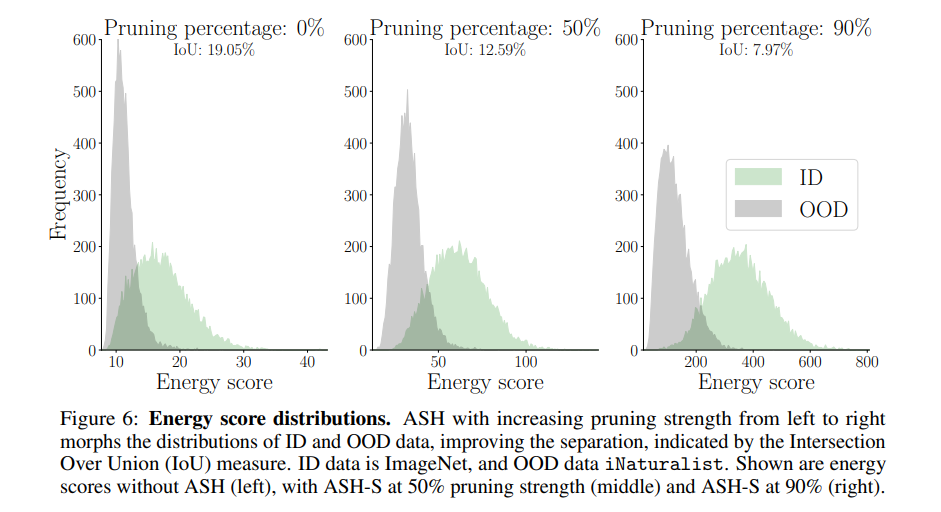
Energy Scoreとpの関係
pの値を大きくして削らないと、Energy ScoreのID/OODの差が小さくなる。ある程度削ったほうがROCは高くなる(=ヒストグラムでのIoUが小さくなる)
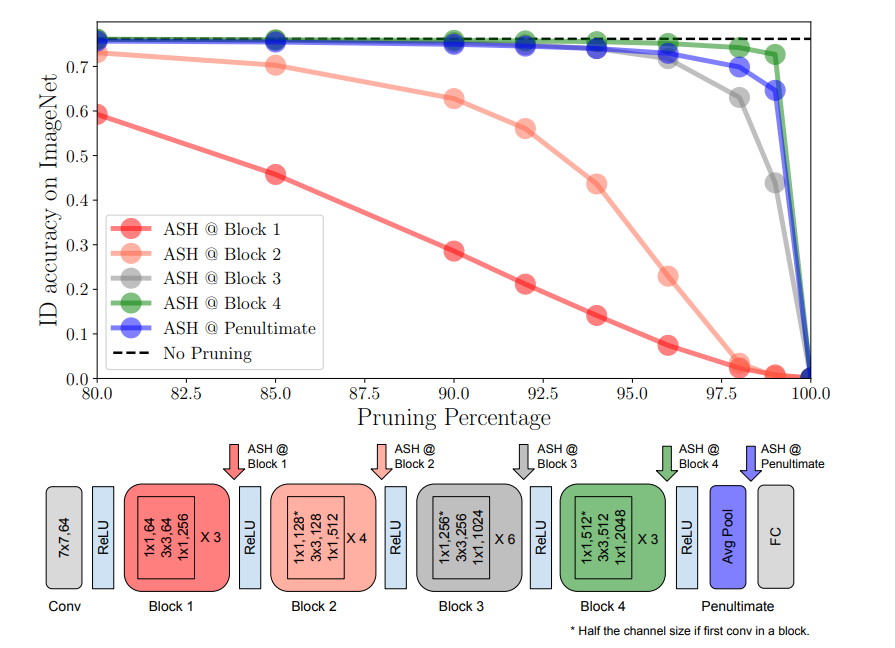
どこでASHをとるか?
IDの精度ベースで、Global Average Poolingの直前(4th)が良い。ネットワークの前の値を使うと明確に悪くなるので、セマンティックな空間で取るのが重要。
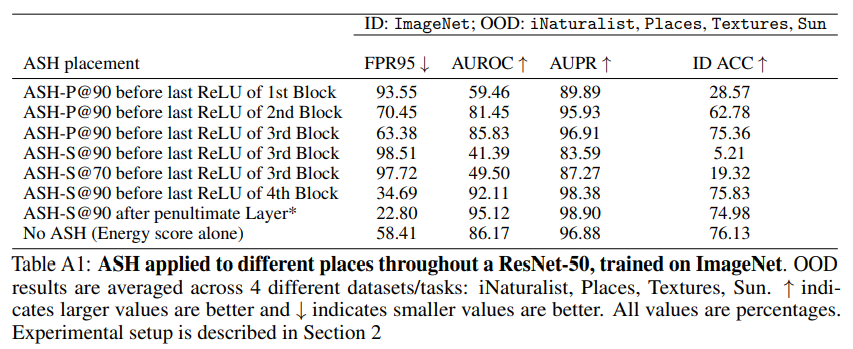
一方でID/OODのROCを見ると、Global Average Poolingのあとのほうが若干良い。
感想
- 非常に単純ながら強力な性能で素晴らしい
- OOD検知という点だけでなくいろんな応用ができそう
- 画像以外でも応用できるかも?
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー