
Aurora Data APIで踏み台なしでSQLを実行する


Aurora Data APIを使えば、セキュリティグループの開放や踏み台サーバーが不要でHTTPS経由の直接クエリ実行が可能になります。Terraformやboto3との連携も容易で、特にPoCのときにシンプルかつセキュアに構築できる点が魅力です。
目次
はじめに
- SAPの勉強してたら、Aurora Data APIという、Auroraに対するSQLクエリを踏み台サーバーなしで安全に実行できる機能を知ったので試してみた
- Data APIを使うと、セキュリティグループや踏み台、SQLのドライバなどを管理することなく、ローカルからboto3のコードで一発でSQLクエリを実行できる。
Aurora Data APIとは
- Aurora Data APIは、Amazon Aurora(特にAurora Serverless)に対して提供される、HTTPベースのAPI
- このAPIを利用することで、従来のデータベース接続を必要とせずに、直接SQLクエリを実行することができる
セキュリティグループの開放が不要
- 通常、Amazon Auroraなどのデータベースに接続する際には、セキュリティグループを設定して特定のIPアドレスやポートからのアクセスを許可する必要がある。
- しかし、Aurora Data APIを使用するとセキュリティグループを開放する必要がないのには以下のような理由がある:
- HTTPSベースの通信:Aurora Data APIは、インターネット経由でAWSのマネージドサービスに対してHTTPSリクエストを送信。これにより、データベース自体に直接接続する必要がなくなる。
- AWS内部の通信: Data APIはAWS内部のネットワークを経由してAuroraデータベースと通信する。そのため、外部から直接データベースにアクセスする必要がなく、セキュリティグループを開放する必要がない。
- その一方でセキュアに通信されており、Data APIのためにパブリックサブネットに移動する必要ない。
Aurora DataAPIを使うには
- リージョンとバージョン:公式記事を参照。MySQL、PostgreSQLが対応で、プロビジョンド・Serverless両方対応。最新版なら問題なく行ける。東京リージョン対応。Serverlessならゼロキャパシティと併用可能
- 認証情報をSecrets Managerに登録:Data APIをコールする際にSecrets ManagerのARNを指定して呼び出す必要があり、Secrets Managerはusername, passwordをキーに持ったJSONで定義。Terraformで書く場合は以下のようにする。
- AuroraをTerraformで定義する際は、
enable_http_endpoint = trueを追加するだけ - Data APIはboto3から実行可能
resource "aws_secretsmanager_secret_version" "aurora_password_version" {
secret_id = aws_secretsmanager_secret.aurora_password.id
# Data APIが要求する "username", "password" キーを含むJSON構造で設定する
secret_string = jsonencode({
username = "postgres" # Aurora クラスタの master_username に合わせること
password = random_password.aurora_password.result
})
}
全体のTerraformのコード
Auroraの定義はミニマムでOK。踏み台サーバーもセキュリティグループの穴あけもいらずに、プライベートサブネットにDBを入れておくだけでOK。
# 与えられているサブネット ID を使って DB Subnet Group を作成
resource "aws_db_subnet_group" "aurora_subnet_group" {
name = "aurora-subnet-group"
subnet_ids = var.private_subnet_ids
description = "Subnet group for Aurora Serverless"
}
data "aws_subnet" "private_subnets" {
for_each = toset(var.private_subnet_ids)
id = each.value # ここに対象のサブネットIDを指定
}
# Aurora のマスターパスワードを Secrets Manager に格納するための準備(ランダム生成 → Secret → Secret Version)
resource "random_password" "aurora_password" {
length = 16
special = true
override_special = "!#$%&*()-_=+[]{}<>:?" # 利用したい特殊文字の制限があれば適宜修正
}
resource "aws_secretsmanager_secret" "aurora_password" {
name = "aurora-master-password"
description = "Master password for Aurora PostgreSQL stored in Secrets Manager"
# Terraform destroy 時に即削除されるようにする設定
recovery_window_in_days = 0
}
resource "aws_secretsmanager_secret_version" "aurora_password_version" {
secret_id = aws_secretsmanager_secret.aurora_password.id
# Data APIが要求する "username", "password" キーを含むJSON構造で設定する
secret_string = jsonencode({
username = "postgres" # Aurora クラスタの master_username に合わせること
password = random_password.aurora_password.result
})
}
# セキュリティグループ (例: ポート 5432 を開放)
resource "aws_security_group" "aurora_sg" {
name = "aurora-postgres-sg"
description = "Allow outband PostgreSQL traffic"
vpc_id = var.vpc_id
# Data API使うだけならインバウンド不要
egress {
from_port = 0
to_port = 0
protocol = "-1"
cidr_blocks = ["0.0.0.0/0"]
}
}
# Aurora Serverless クラスターの作成
resource "aws_rds_cluster" "aurora_pgvector" {
cluster_identifier = "my-aurora-pgvector-cluster"
engine = "aurora-postgresql"
engine_version = "16.6" # 実行時に利用可能な最新バージョンに合わせる
db_subnet_group_name = aws_db_subnet_group.aurora_subnet_group.name
master_username = jsondecode(
aws_secretsmanager_secret_version.aurora_password_version.secret_string
)["username"]
master_password = jsondecode(
aws_secretsmanager_secret_version.aurora_password_version.secret_string
)["password"]
# Aurora Serverless v2 のスケーリング設定
serverlessv2_scaling_configuration {
min_capacity = 0.0 # 必要に応じて変更
max_capacity = 1.0 # 必要に応じて変更
seconds_until_auto_pause = 300
}
vpc_security_group_ids = [
aws_security_group.aurora_sg.id
]
storage_encrypted = true
deletion_protection = false
# テストや開発用で最終スナップショットを取らずに削除する場合
skip_final_snapshot = true
# Data API向けにここを追加
enable_http_endpoint = true
}
# Aurora Serverless クラスターのインスタンスを作成
resource "aws_rds_cluster_instance" "aurora_pgvector_instance" {
identifier = "my-aurora-pgvector-instance"
cluster_identifier = aws_rds_cluster.aurora_pgvector.id
engine = aws_rds_cluster.aurora_pgvector.engine
# Serverless v2 用インスタンスクラス (Aurora)
instance_class = "db.serverless"
db_subnet_group_name = aws_db_subnet_group.aurora_subnet_group.name
}
ローカルからDBにレコードを追加
boto3のコードでレコードを追加してみる。data/prime_ministers.jsonに以下にJSONが保存されているものとする。
ポイントは以下の通りで、
- 認証情報はSecrets Managerで渡す
import json
import boto3
# 作成時に設定したパラメータをハードコード (ARN は動的に取得)
region_name = "ap-northeast-1" # Aurora が動作しているリージョン
database_name = "postgres" # Aurora DB 名
cluster_identifier = "my-aurora-pgvector-cluster" # DB クラスタ識別子
secret_name = "aurora-master-password" # シークレット名 (Secrets Manager 上の名前)
# 実行時に動的に取得する ARN を呼び出し側からグローバルに参照できるようにする (後段の execute_sql などで使用)
DB_CLUSTER_ARN = None
SECRET_ARN = None
# RDS Data Service クライアントは後ほど初期化
rds_data = None
boto_session = boto3.Session(profile_name="hogehoge")
def get_rds_client():
"""
RDS (通常の制御 API) 用のクライアントを返す
"""
return boto_session.client("rds", region_name=region_name)
def get_secrets_manager_client():
"""
Secrets Manager 用のクライアントを返す
"""
return boto_session.client("secretsmanager", region_name=region_name)
def get_rds_data_client():
"""
RDS Data Service 用のクライアントを返す
"""
return boto_session.client("rds-data", region_name=region_name)
def fetch_db_cluster_arn(rds_client, cluster_id):
"""
クラスタ識別子 (cluster_id) をもとに、DB Cluster ARN を取得して返す
"""
response = rds_client.describe_db_clusters(
DBClusterIdentifier=cluster_id
)
# 例: response["DBClusters"][0]["DBClusterArn"] がクラスタの ARN
return response["DBClusters"][0]["DBClusterArn"]
def fetch_secret_arn(secrets_client, secret_name):
"""
シークレット名をもとに、Secrets Manager 上の Secret の ARN を取得して返す
"""
# describe_secret で SecretId=secret_name を指定し、ARN を取得
response = secrets_client.describe_secret(
SecretId=secret_name
)
return response["ARN"]
def execute_sql(sql, parameters=None):
"""
Aurora Data API に対してクエリを実行するためのヘルパー関数
"""
if parameters is None:
parameters = []
response = rds_data.execute_statement(
secretArn=SECRET_ARN,
database=database_name,
resourceArn=DB_CLUSTER_ARN,
sql=sql,
parameters=parameters
)
return response
def create_table_if_not_exists():
"""
prime_ministers テーブルがなければ作成する。ID, name のみ含む。
"""
sql = """
CREATE TABLE IF NOT EXISTS prime_ministers (
id INTEGER NOT NULL PRIMARY KEY,
name TEXT
);
"""
execute_sql(sql)
def get_max_id():
"""
テーブル内の MAX(ID) を取得。空の場合は 0 で返す。
"""
sql = "SELECT COALESCE(MAX(id), 0) AS max_id FROM prime_ministers;"
response = execute_sql(sql)
records = response.get("records", [])
if len(records) == 0 or len(records[0]) == 0:
return 0
max_id = records[0][0].get("longValue", 0)
return max_id
def insert_one_record(new_id, name_value):
"""
テーブルにレコードを 1 件 INSERT
"""
sql = "INSERT INTO prime_ministers (id, name) VALUES (:id, :name);"
parameters = [
{"name": "id", "value": {"longValue": new_id}},
{"name": "name", "value": {"stringValue": name_value}}
]
execute_sql(sql, parameters)
def select_all_records():
"""
テーブルの全データを取得して返す
"""
sql = "SELECT id, name FROM prime_ministers ORDER BY id;"
response = execute_sql(sql)
all_rows = []
for row in response.get("records", []):
_id = row[0].get("longValue")
_name = row[1].get("stringValue")
all_rows.append((_id, _name))
return all_rows
def main():
global DB_CLUSTER_ARN, SECRET_ARN, rds_data
# 1. RDS / Secrets Manager クライアントを作成し、ARN を動的に取得
rds_client = get_rds_client()
secrets_client = get_secrets_manager_client()
DB_CLUSTER_ARN = fetch_db_cluster_arn(rds_client, cluster_identifier)
SECRET_ARN = fetch_secret_arn(secrets_client, secret_name)
# 2. RDS Data Service を初期化
rds_data = get_rds_data_client()
# 3. テーブルがなければ作成
create_table_if_not_exists()
# 4. 現在のテーブルから最大 ID を取得し、次の ID を決める
max_id = get_max_id()
next_id = max_id + 1
# 5. JSON を読み込み (data/prime_ministers.json から)
json_file_path = "data/prime_ministers.json"
with open(json_file_path, "r", encoding="utf-8") as f:
prime_ministers_data = json.load(f)
if len(prime_ministers_data) == 0:
print("JSON データが空です。処理を終了します。")
return
# 6. 次のID-1 を JSON データ数 で割った余りを index にしてデータを取得
index = (next_id - 1) % len(prime_ministers_data)
selected_record = prime_ministers_data[index] # 例: {"generation": 4, "name": "松方 正"}
# 7. テーブルに 1 件だけ挿入 (ID と name)
insert_one_record(next_id, selected_record["name"])
# 8. 全レコードを取得して表示
results = select_all_records()
print("現在の prime_ministers テーブルの内容:")
for r in results:
print(f"ID={r[0]}, Name={r[1]}")
if __name__ == "__main__":
main()
これを実行するたびに以下のようにレコードが追加されていく。
# 1回目
現在の prime_ministers テーブルの内容:
ID=1, Name=伊藤 博文
# 2回目
現在の prime_ministers テーブルの内容:
ID=1, Name=伊藤 博文
ID=2, Name=黑田 清隆
# 3回目
現在の prime_ministers テーブルの内容:
ID=1, Name=伊藤 博文
ID=2, Name=黑田 清隆
ID=3, Name=山縣 有朋
非常に簡単なので、PostgreSQLを手軽に試したい、PoCで利用したいというときは非常に便利だと思う。
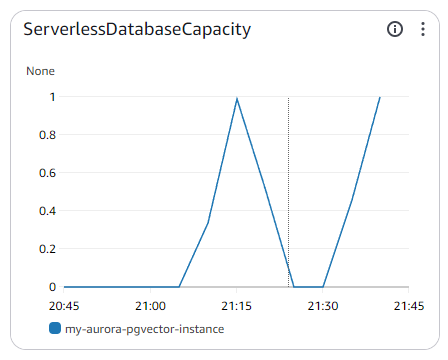
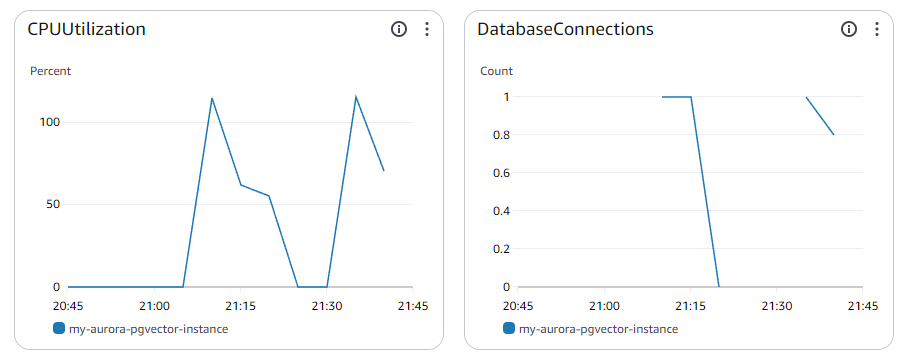
データベースの自動停止にかかっていると以下のようなエラーが出るが、15秒ぐらい待って再実行すると正常に実行されるはず。逆にいうと、これは正常にコネクションが切断されて自動停止が効いているという証拠になる。踏み台サーバーだとコネクションが維持されていて、自動停止が作動せず延々とAurora Serverlessが課金されるという問題があるのでそれ対策にはいい。
…:my-aurora-pgvector-instance is resuming after being auto-paused. Please wait a few seconds and try again.
Data API実行時にAuroraのメトリクス
いたって普通。自動停止も正常に作動している。連続してローカルからコードを実行しても接続数が「1」のまま。
注意点
Aurora Data APIは、複数文のSQLクエリを実行しようとするとエラーになる。すなわち、DROP DATATABLE ... とCREATE TABLE...は一気には実行できずに、2回に分けて実行になる。
コストは以下の通り(東京リージョン)
- リクエスト数 (月間) 価格 (100 万あたり):
- 最初の 10 億件のリクエスト USD 0.42
- 10 億件を超えるリクエスト USD 0.24
Data API では、API が使用されている場合にのみ料金が発生します。最低料金や初期費用は不要です。お支払いいただくのは、アプリケーションで行う API とデータリクエストに対してのみです。Data API リクエストデータペイロードは、API に送信されるデータまたは API から受信されるデータのリクエストあたり 32 KB で計測されます。API リクエストデータのペイロードサイズが 32 KB を超える場合、32 KB ずつ増加するごとに追加の 1 API リクエストが課金されます。 たとえば、ペイロードが 35 KB の場合、2 つの API リクエストに対して課金されます。
https://aws.amazon.com/jp/rds/aurora/pricing/
よほど大規模なペイロード返さなければ微々たるものだと思う。
所感
- これはかなり強い。PoC的な使い方だとかなり刺さるはず
- Data APIのオーバーヘッドがどの程度あるのかわからないが、実験で使えたらすごそう
- Lambda→RDSのときに、教科書的なRDS Proxy挟むというのがいらなくなるかもしれない?
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー