
pix2pix HDのCoarse to fineジェネレーターを考える


pix2pix HDの論文を読んでいたら「Coarse to fineジェネレーター」という、低解像度→高解像度と解像度を分けて訓練するネットワークの工夫をしていました。pix2pixはGANですが、このジェネレーターや訓練の工夫は、Non-GANでも理屈上は使えるはずなので、この有効性をImage to imageの教師あり学習におけるU-Netの代用として調べてみました。
目次
要点
pix2pix HDのCoarse to fineジェネレーターを、Non-GANの教師あり学習のImage to imageのタスクに適用したところ、出力画質の観点では優位性が確認できなかった。むしろCoarse to fine modelを一気に訓練(train all)したほうが、個別訓練(train each)よりも出力画質が上がった。それどころか、Coarse to fine modelの一気訓練は、学習曲線において普通のU-Netとほとんど変わらなかった。
Coarse to fineジェネレーター
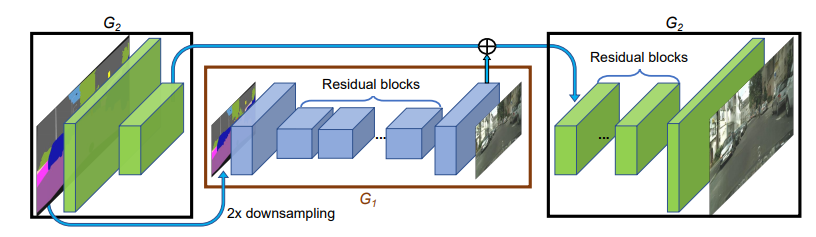
画像はpix2pix HDの論文より。pix2pix HDではジェネレーターを工夫していて、このように低解像度→高解像度の順に訓練をしています。これを論文では、Coarse to fineジェネレーターと呼んでいます。このジェネレーターが高画質での出力を行う上での一つの特徴になっています。
pix2pix HDはGANの一種ですが、このジェネレーターだけ取り出せば、GAN以外でも使えそうな気はします。例えば、一般的なU-Netにこの低解像度→高解像度への訓練を加えれば、もしかしたら解像度が上がるかもしれません。今回はこれに焦点を当てます。つまり、Coarse to fineジェネレーターのGAN以外への汎用性を確かめるのが主眼です。
関連する研究
GAN以外に解像度別に訓練する研究は、Stacked Auto Encoderがあります。解像度別に訓練するのは、GANで初出のものではないです。
GANだとProgressive-GANは低い解像度から高い解像度への訓練を行っています。これは2019年現在のモダンなGANのベースラインとなっているGANでもあり(例:StyleGANはこれがベース)、GANの中ではかなりコアなテクニックとなっている部分です。
GANであろうがなかろうが、解像度別に訓練するというのは直感的には理解しやすいです。なぜなら、画像の生成において、粗い→細かいように訓練していくのは、人間の絵を書いていくプロセスに似ています。そして、そのほうが構造を理解しやすいのではないかと思われるのです(あくまで直感的な話)。
さらに、Stacked Auto Encoderを念頭に置くと、例えばAuto Encoderで訓練するような場合でも、「あれ、これ解像度別に訓練したら画質良くなるんじゃない?」みたいなことは頭の片隅で浮かんだりします。それを一度ちゃんと確かめておこうということで行ったのがこの記事です。
モデル設定
本来はU-Netで訓練するようなモデルを、Coarse to fineジェネレーターのような低解像度→高解像度で訓練します。今回は3種類用意しました。
1.Coarse to fine model
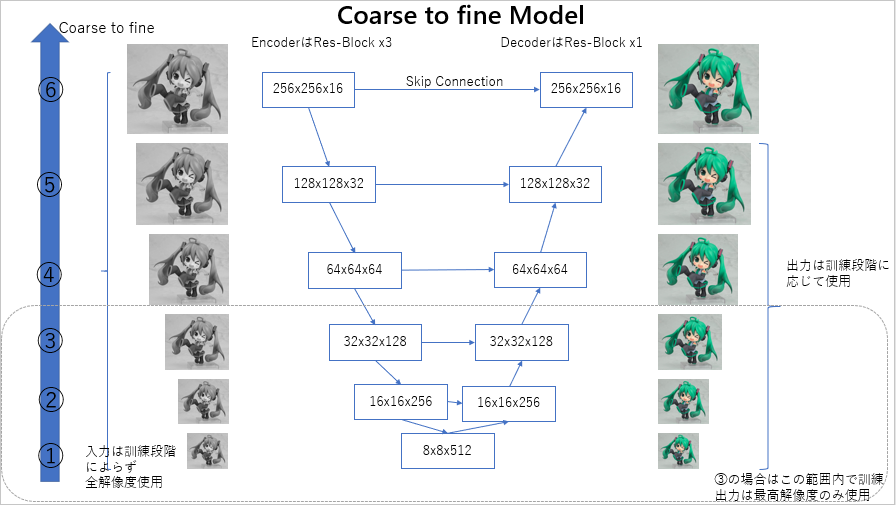
pix2pix HDのCoarse to fineジェネレーターをU-Netベースに移植したものです。オリジナルでは2段階の訓練でしたが、こちらでは解像度に合わせて6段階の訓練に変更しています。この図では、入力がグレースケール、出力がカラーとなっていますが、これは白黒画像のカラー化を想定したものです。
解像度が低い順に(1), (2), ……, (6)とし、段階的に訓練する場合は(1)→(6)と訓練します。(6)の訓練段階は通常のU-Netとほぼ同じになります。ただし、U-Netと異なるのは、解像度別に異なるサイズの入力を同時に入れていることで、通常のU-Netでは(6)の入力のみになるのに対して、このCoarse to fine modelでは(1)から(6)の入力を、訓練段階を問わずすべて使います。ただし、出力はU-Net同様最高解像度のものを1つ使います。例えば、訓練段階が(6)なら256×256の(6)の出力のみ、訓練段階が(3)なら64×64の出力のみ使用します。
このモデルに対して、段階的に訓練、一気に訓練の2つのケースを比較します。
- 段階的に訓練(train each):(1), (2), (3)……, (6)と解像度別に訓練。最初の50エポックは(1)を訓練。次の10エポックは(1)の係数を固定して(2)を訓練、60エポック目から(1)の係数固定をといて(1)と(2)を同時に訓練。100エポック目で(2)の係数を固定して(3)の訓練を開始、110エポック目で(2)の固定をやめて(1)~(3)を同時に訓練。これを繰り返して(6)の訓練が終わるまで300エポック繰り返す。
- 一気に訓練(train all):(1)~(6)を一気に訓練する。やっていることは段階的に訓練の最終段階と一緒。300エポック行う。
段階的に訓練する場合の係数固定は、pix2pix HDで使われていた手法です。pix2pix HDの場合は、この係数固定を行うことで高画質の層が、訓練された低画質の情報を使って「情報の上乗せ」をすることを確認しています。逆にいえば、固定をしないと高画質の層の訓練開始時に、せっかく訓練した低画質の層の係数が破壊されてしまったり、低画質の層の情報が無視されてしまったりします。
2. Coarse to fine Auto Encoder
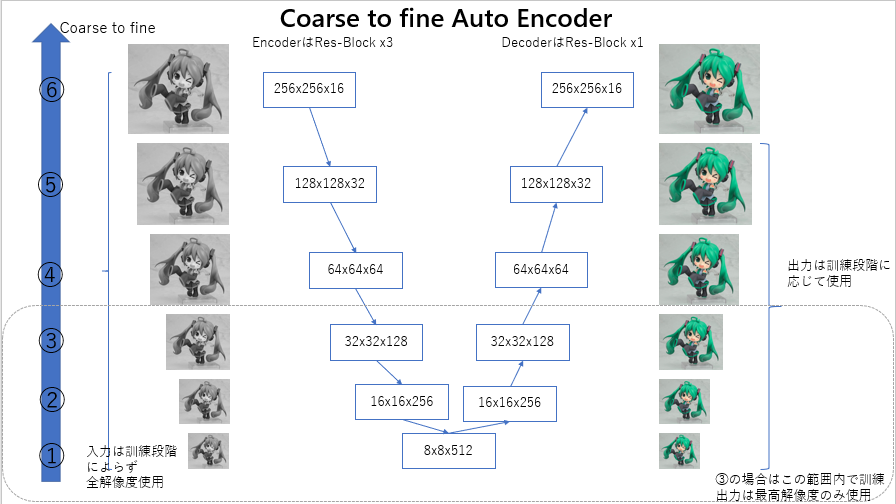
1のCoarse to fine modelからU-NetにあるSkip Connectionを抜いたものです。仕組み的にはStacked Auto Encoderに近いものになります(これは内側から訓練しているけど)。これも同様に、段階的に訓練(train each)、一気に訓練(train all)する場合で比較します。
3. U-Net
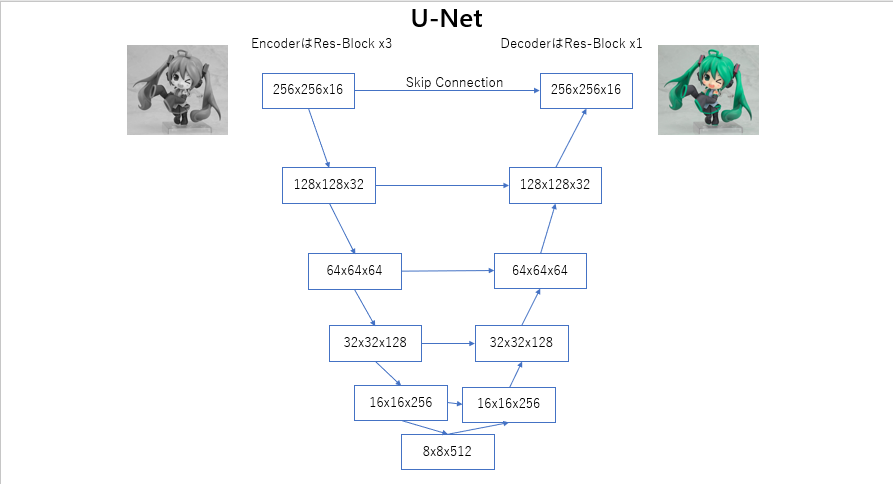
ごく普通のU-Net(ライクな)ネットワークです。こちらは一気に訓練する場合のみ計測します。
実験
これらの3つのモデル、計5つの訓練方法に対して、それぞれ2つの訓練タスクを用意します。したがって10個のケースが存在します。
全てにおいて使うデータはKaggleのMyWaifuListデータセットを使います。前処理としてカラー画像のみを抽出しました。カラー画像の抽出は、チャンネル単位でのピクセルの相関係数を取り、その相関行列の平均が0.995より低いものをカラー画像としました。その中から2048枚をテスト画像として除外し、訓練画像は12443枚となっています。
タスク1:白黒画像のカラー化
カラーのデータを機械的にグレースケール化して、白黒画像を入力に、カラー画像を出力として訓練します。これにより、グレースケールの画像をニューラルネットワークを使って自動的に着色することができます。
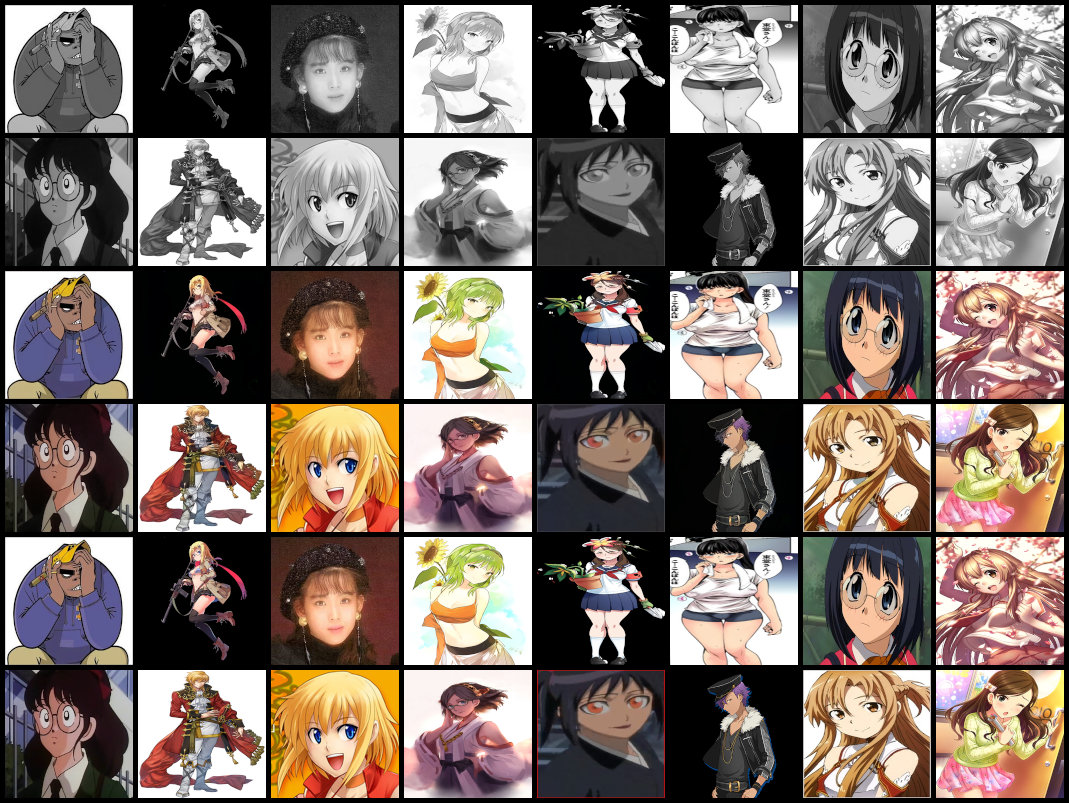
上から入力、出力(予測)、Ground Truthです。U-Netで訓練したもので訓練データですが、このようなイメージです。
タスク2:モザイク除去
カラー化と同じ要領で、カラーのデータに対して機械的にモザイクを付与しこれを入力、モザイクを付与しない画像を出力として訓練します。これにより、モザイク除去をニューラルネットワークを使って自動的に行うことができます。

上から入力、出力(予測)、Ground Truthです。機械的にモザイクを付与する操作は次のようにします。
- 256×256にリサイズした画像に対して、16倍のスケール倍率でNearest Neighborのダウンサンプリング→16倍のスケールでNearest Neighborのアップサンプリング
- さらに半径4のガウシアンぼかし
これにより得られたものが入力(図の一番上)となります。図はU-Netで訓練した訓練データです。
損失関数・評価関数
損失関数はL1ロスのみ使います。y_trueとy_predのピクセル単位のL1ロスのみで訓練します。
評価関数はPSNRを使います。これをtrainとtest(val)で計測します。
訓練方法による比較
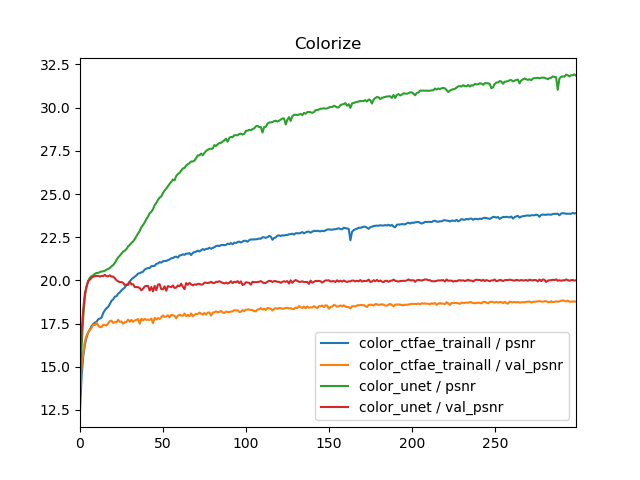
train all, train eachによる比較を行います。タスクは白黒画像のカラー化で、3モデル計5つの訓練方法でTrain PSNR, Val PSNRを比較したものです。
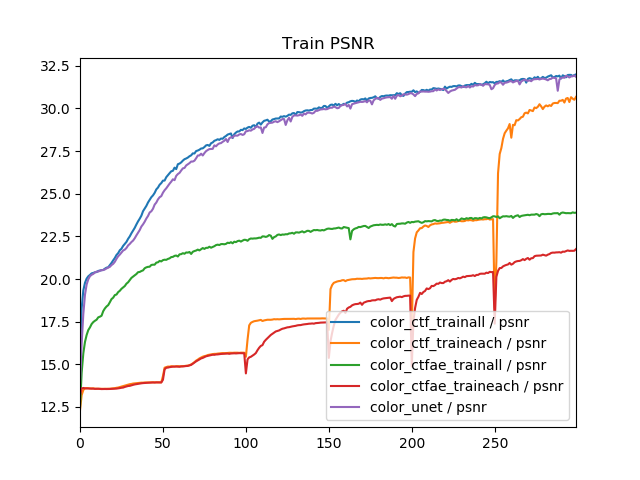
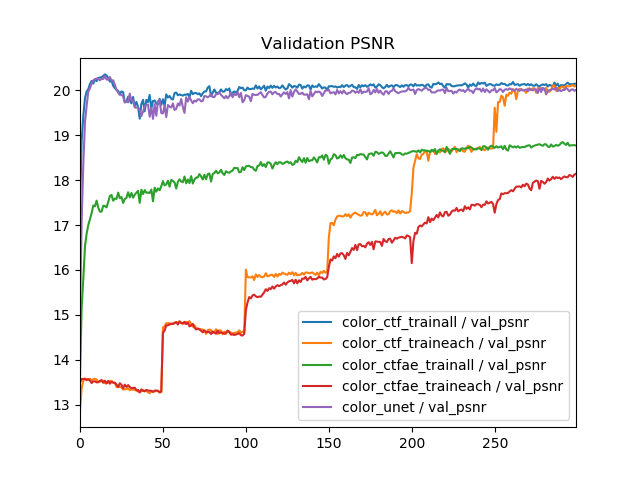
これから次のことがわかります。
- 訓練方法(train all, train each)を変えても画質は良くならない。エポック単位では、むしろtrain eachにしたほうが画質が下がる。
- Coarse to fine モデル+train allとU-Netの学習曲線はほぼ同じ。
- train allよりtrain eachのほうが収束も遅い(エポック単位)
ただし、train allよりtrain eachのほうが収束が遅いというのはあくまでエポック単位の話であって、時間単位で見ると必ずしもそうでない可能性はあります。なぜなら、train allは1エポックあたりの時間は一定ですが、train eachでは低解像度を訓練しているときと、高解像度を訓練しているときでは1エポックあたりの時間が異なるからです。そこで1エポックあたりの実測値(秒)で比較してみます。
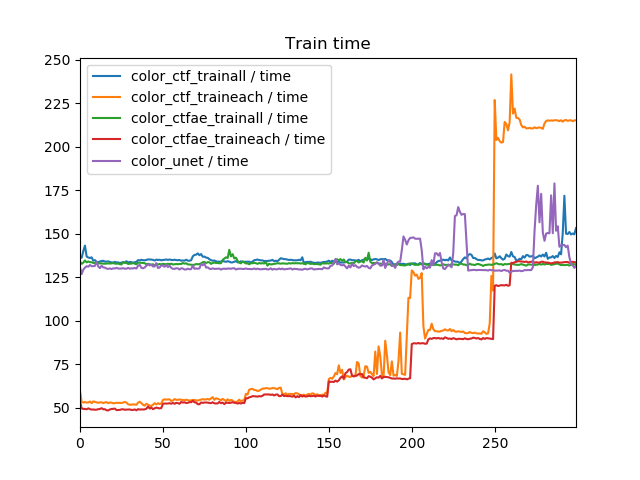
「color_ctf_traineach」だけなぜか大きくなってしまいましたが、理論的にはtrain eachの最終段階の1エポックあたりの所要時間と、train allの1エポックあたりの所要時間は等しくなります(モデルが同一になるから)。所要時間の和を計算したところ、color_ctfae_trainallが40644秒で、color_ctfae_traineachが22319秒でした。したがって、訓練の所要時間はtrain_allはtrain_eachのおおよそ2倍必要だということがわかります。
これを考えると、train_eachが300エポックかかってたどり着いた画質に、train_allが150エポック以内にたどり着けば、一気に訓練したほうが画質も速度も良いということになります。train_allを基準に考えたときに、Coarse to fine model(U-Netベース)の場合はだいたい150エポック、Coarse to fine Auto Encoderの場合は100エポックで、train_eachの抜いています。したがって、256×256の解像度かつNon-GANにおいては、train_eachをするのは画質的にも速度的にも良くないだろうというのが考えられます。
タスクを変えてみる
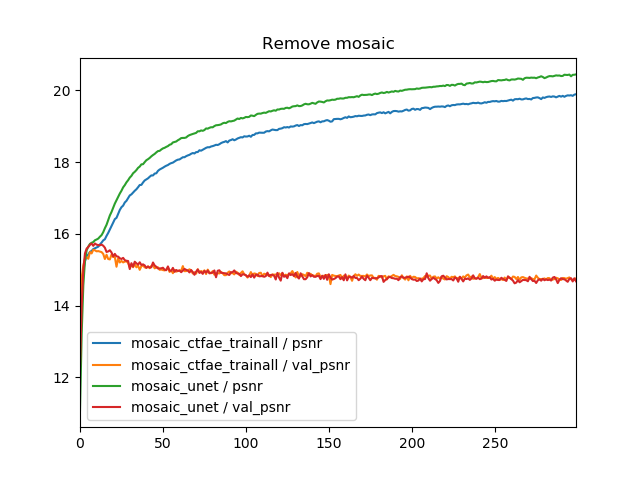
「train eachが悪いのはタスクによる問題だろう」という疑問も当然あるので、モザイク除去のほうでも同様にグラフを書いてみました。
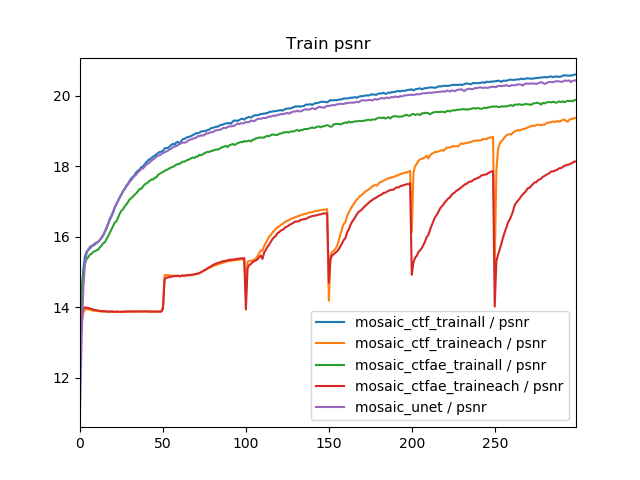
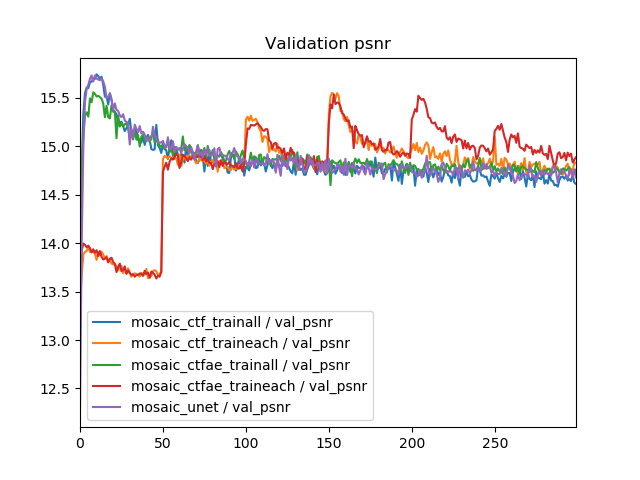
Val PSNRの解釈が難しいですが、全般的にオーバーフィッティングが激しいので、val_psnrが良いのはtrainとvalの差が少ないからで、ネットワークや訓練方法ではなく原因としてはオーバーフィッティングが原因であると考えられます。つまり、train_allとtrain_eachによる差は、Train PSNRのとおりで、やはりタスクを変えてもtrain_eachのほうが悪くなると解釈できます。
複数の解像度の入力(U-Net vs Coarse to fine modelのtrain all)
Coarse to fine modelのtrain allとU-Netの異なる点は、入力解像度が複数あるという点ですが、それはどのように効いているでしょうか。タスク別に(1)Coarse to fine modelのtrain allと(2)U-Netの比較をしてみます。
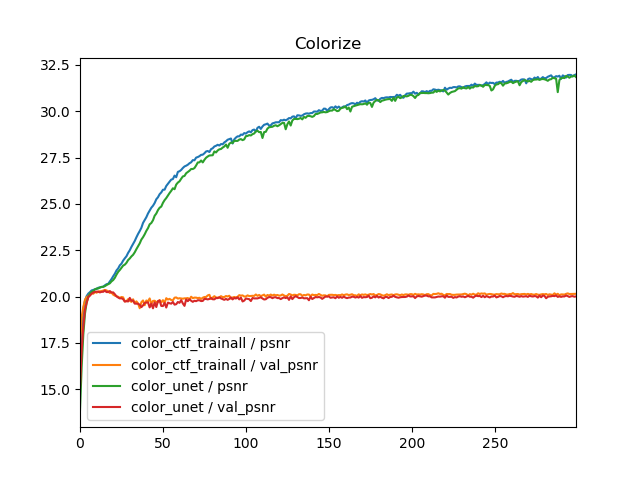
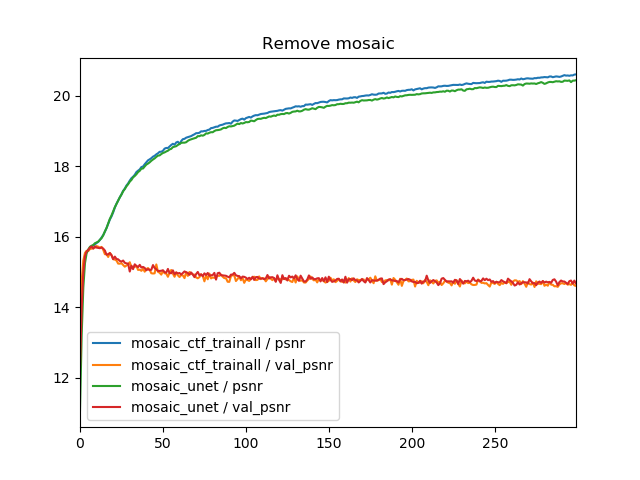
学習曲線は全くといっていいほど同じになりました。U-Netベースでは異なる解像度の入力を複数使うことはほぼ効いていないということがわかります(ぶっちゃけNon-GANだったら普通のU-Netでいい)
Skip Connectionの有無(U-Net vs Coarse to fine Auto Encoderのtrain all)
U-Netがいいのか、AutoEncoderがいいのかというのはたびたび気になりますが、タスク別に(1)Coarse to fine Auto Encoderのtrain allと、(2)U-Netを比較してみます。この結果は基本的にはU-Netのほうが良くなるはずです。なぜなら、Auto Encoderは画像の全エリアの描画しているのに大して、U-NetはEncoderとDecoderのSkip Connectionでコピーできるので。
その結果はPSNRでも現れていて、U-NetのほうがPSNRが同じ~やや良い結果となっています。
目視での評価
U-NetとAuto Encoderの差がほぼないようなケース、例えばこの場合のモザイク除去のようなケースでは、出力を比較すると次のようになります(訓練データ)。上から順にCoarse to fine Auto EncoderとU-Netの、各画像は入力、Pred、Ground Truthになります。


人間の見た目ではイマイチ違いがわからないというのがが正直なところですが、見方によってはAuto Encoderのほうが自然とかもあるかもしれません。PSNRと人間の見た目で自然かは別問題なので、そこの議論の余地はありそうです。
まとめ
今回の実験からわかったこと、わからなかったことをまとめます。
わかったこと
- 教師あり学習では、個別に訓練(train each)より、一気に訓練(train all)したほうが画質は良くなりそう
- Coarse to fine modelで一気に訓練する(train all)のと、ただのU-Netは学習曲線がほとんど変わらない。少なくともNon-GANでは、画質面において、訓練分割のメリットがほとんど確認できない。
- Auto Encoderライクなモデルより、U-NetのほうがSkip Connectionが効いている分、出力画質が上がりやすい。
- 256×256の解像度では、Coarse to fineの優位性は確認できなかった。HD解像度程度ならどうなのかは不明。
わからなかったこと
- 今回調べたのは教師あり学習(Non-GAN)のケース。GANの場合、Coarse to fineをしたほうが学習の安定性が増すかどうかは、今回の実験からではわからない。
- Coarse to fineをすると、画像の構造性(顔や手といったパーツ)を学習できるのかもしれないが、それは今回の実験からはわからない。ただし、PSNR指標での画質面の優位性は確認できなかった。
- 個別訓練において(train each)は、一気に訓練する(train all)より倍ぐらい速くなるので、HD解像度のように計算量が天文学的になると、速度面においては意味あるのかもしれない。
- HD解像度になると、pix2pix HDのようなCoarse to fineをしたほうが画質がよくなるのかもしれない。しかし、計算量が膨大すぎるので手元にあるGPUでは容易に再現できない。
コード
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー