
論文まとめ:WebVoyager: Building an End-to-End Web Agent with Large Multimodal Models
Posted On 2024-02-01


- タイトル:WebVoyager: Building an End-to-End Web Agent with Large Multimodal Models
- 著者:Hongliang He, Wenlin Yao, Kaixin Ma, Wenhao Yu, Yong Dai, Hongming Zhang, Zhenzhong Lan, Dong Yu(浙江大学、Tencent AI Lab、西湖大学。ほぼTencent)
- URL:https://arxiv.org/abs/2401.13919
- コード:https://github.com/MinorJerry/WebVoyager (まだリポジトリ作っただけ)
目次
ざっくりいうと
- ブラウザをLLMが操作してタスク解決を行う、汎用ウェブエージェントWeb Voyagerについての研究
- 従来はHTMLなどユニモーダルだった部分を、GPT-4Vを使いマルチモーダルに拡張し、ウェブサイトのUXを反映。評価のプロトコルも作成
- マルチモーダル化したらタスクの成功率が大幅に向上した一方で、現在の限界も議論している
導入
- 既存の手法はHTMLベース
- 主な課題は、複雑で冗長なHTMLテキストの管理にあり、解決策としては、HTMLの簡略化と構造化(Nakano et al., 2021; Zhou et al., 2023; Gur et al., 2023; Deng et al., 2023)
- HTMLを視覚的なウェブページにレンダリングすることを見落としており、ウェブページに設計されたUXを活用できていない。ビジョン能力を活用することで視覚的なレンダリングが可能
- WebVoyager:WebタスクをEnd-to-endで処理するように設計されたマルチモーダルWebエージェント
- Selenium for WebVoyagerを使い、オンラインに環境を構築。インタラクティブにWeb要素にスクリーンショットとテキストコンテンツを供給
- Set-of-Mark Prompting(SoMプロンプト)に触発され、インタラクティブにWeb要素をマーキングし、意思決定を容易にする
- End-to-endのウェブエージェントをオンラインナビゲーションで評価
- Mind2Web (Deng et al., 2023) などの既存のベンチマークは、主に段階的かつオフラインの評価に焦点を当てており、エージェントは行動選択のためにあらかじめ定義されたの軌道の評価
- 既存のタスクは戦略の多様性を完全には説明できない
- 15の一般的なアクセスサイトから300のウェブタスクからなる自己構築(Wang et al.2022)法を用いて半自動的に生成される
- GAIA (Mialon et al., 2023) からレベル 1 とレベル 2 の 90 のウェブ関連タスクを抽出し、評価を充実
既存研究
- WebGPT (Nakano et al., 2021) :テキストベースのGPT-3をファインチューニング
- WebAgent (Gur et al., 2023) は、HTMLスニペットを抽出するためにT5モデルを事前学習し、FlanU-PaLMを活用して環境と対話するためのPythonコードを生成
- WebGUM (Furuta et al., 2023) は T5 (Raffel et al., 2020) と Vision Transformer (ViT) を組み合わせて、スクリーンショットとHTML テキストの両方を使用してナビゲート
- PIX2ACT (Shaw et al., 2023) は、エージェントの行動を予測するための入力として、ウェブのスクリーンショットにのみ依存
- SeeAct(Zheng et al., 2024) も大規模マルチモーダルモデル (LMM) を活用し、Web サイトでの視覚的理解とアクションを統合
手法
- 人間と同様に、WebVoyager はWeb からの視覚信号(スクリーンショットなど)を各ステップで主要な入力ソースとして受け取り
- さらにHTMLの主要要素から抽出されたテキストも考慮
- エージェントはステップごとに入力に基づいてアクションを生成し、ブラウザ環境で実行
- このプロセスはエージェントが停止を決定するまで続けられる
- 長いエピソードのスクリーンショットはエージェントを混乱させるので、直近3つのスクリーンショットを保持し、テキストクリッピングを実施
システムプロンプト

観測空間
- スクリーンショットが主な情報源
- DOMツリーやアクセシビリティツリーを処理して全体の構造を表現する負担を回避し、冗長なテキストを使わないことでエージェントの意思決定プロセスへの悪影響を減らしたい
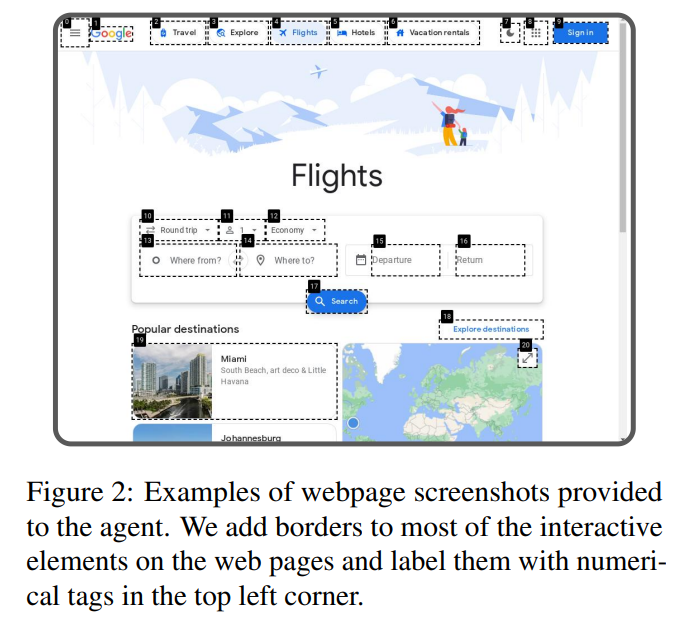
- SoMプロンプトに誘発され、対話要素のBounding Boxを付与
- 要素のそれぞれの領域に数値ラベルを持つバウンディングボックスを重ね合わせるJavascriptツールであるGPT-4V-ACTを利用
アクション
対応するアクションに遷移
- クリック
- 入力
- スクロール
- 待機(ロード待ち用)
- バック(前ページに戻る)
- 検索エンジンにジャンプ(Google)
- 回答(最終回答用)
- > task requirements. Action Format: ANSWER; [Content].
評価方法
Webサイト
評価の多様性を確保するため、Allrecipes、Amazon、Apple、ArXiv、BBC News、Booking、Cambridge Dictionary、Coursera、ESPN、GitHub、Google Flights、Google Map、Google Search、Huggingface、Wolfram Alpha など、15の代表的なウェブサイトを選定
データ構築
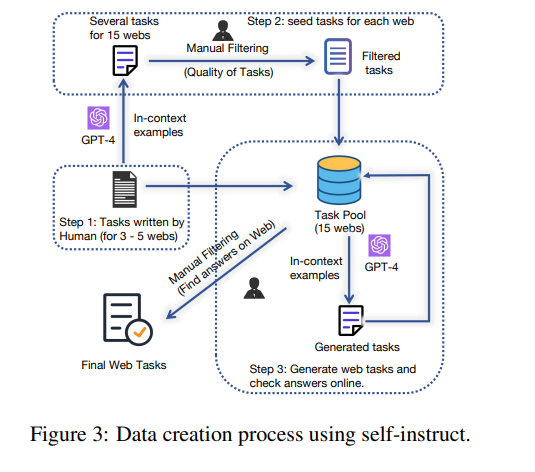
- 自己指示式(Wang et al., 2022)と人間検証を組み合わせて採用
- ステップ1
- タスクの種の生成
- Mind2Web (Yin et al., 2023; Deng et al., 2023)のウェブエージェントタスクからインスピレーションを得て、Google Flights, Google Map, Google Search, Booking, Wolfram Alpha のいくつかのタスクを手動でサンプリングして書き直す。
- これらのWebサイトの様々な機能をテストできるように、タスクの多様化を優先させる
- この処理により、タスクプールの最初の種タスクが生成され、その後の生成が行われます。
- ステップ2
- GPT-4 Turboによる種からの生成と手動検証
- GPT-4 Turboに約100の新しいタスク(20回の反復)を生成
- 生成された各タスクを手動で検証し、必要に応じて書き換えて、その高品質で、対応するウェブサイトに答えが記載されて
いることを確認する。 - 追加の種タスクとしてタスクプールに追加する
- ステップ3
- タスクプールでより多様な文脈内の例をサンプリングし、各反復で生成されたタスクを直接タスクプールに追加
- ステップ2と似ているが、人間の介在がない
- 私の所感:このデータセット構築プロセスは汎用的に使える考え方
アノテーション
- タスクの回答にアノテーションをつける
- ウェブ情報が変更される可能性があるためそれを反映したい
- 「可能性」と「黄金」の回答のラベル付
- 「黄金」:回答のリストを提供している
- 「可能性」:短期的に安定した回答を提供している
- オープンエンドなタスクの回答で、要約のような完全一致の答えを見つけることが困難なもの。
- タスクを満たす回答は複数あり、すべてをリストアップすることは現実的でないケース
- 答えがリアルタイムに変化するタスク(例:飛行機のチケット価格)
- 22.3%の質問が「黄金」
評価
- 人間による評価を採用
- エージェントとインタラクションの履歴を見せて、タスクが正常に完了したかを人間が判定
- 熟練者が1つのタスクを評価するのに1分(めっちゃハイコストなアノテーション)

- GPT-4(All-Tools)より良かった
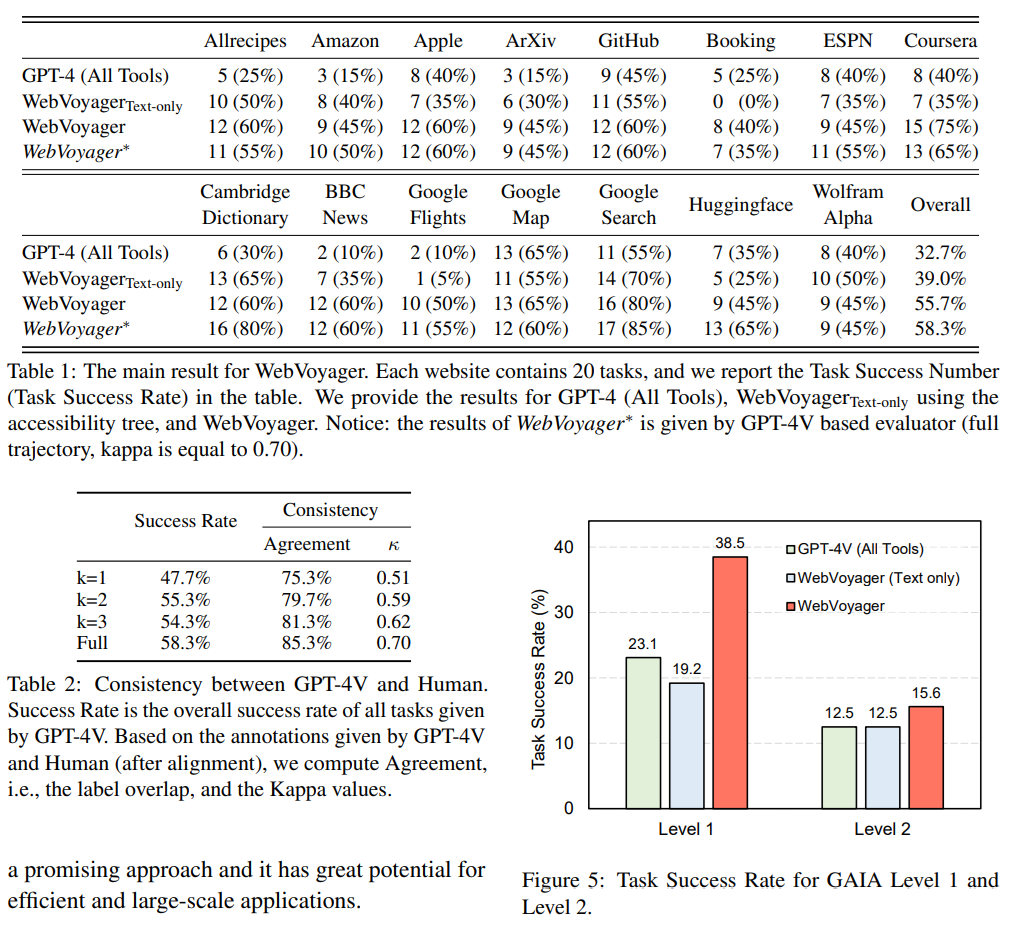
- GPT-4(All Tools)があまりよくなかった理由
- Bing検索に依存したものである
- 特定のウェブサイト(Apple、Amazon、BBC Newsなど)に直接アクセスして、検索、クリック、利用する機能に欠いています
- 汎用ウェブエージェントについての議論
- テキストと画像の両方を議論する必要がある
- 画像がない場合だと、カレンダーや複雑なコンポーネントとの対話が必要な、BookingやFlightsなどの複雑な視覚的要素を持つサイトでは著しく低下
- WebVoyager(Text Only)
- 逆に言うとCambridge DictionaryやGitHub、Google SearchのようなケースではText-Onlyでもある程度いける
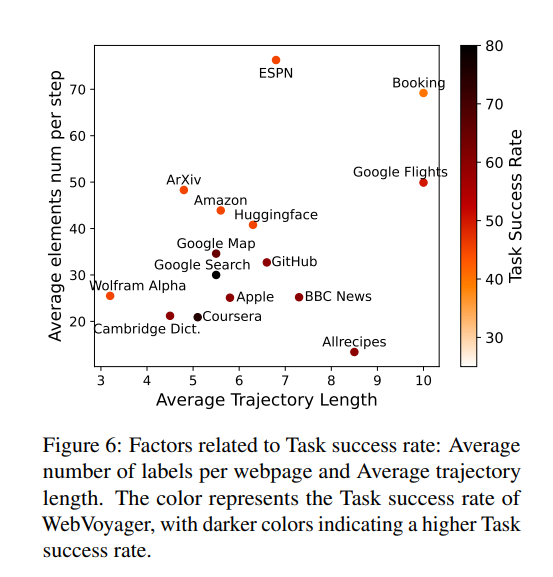
- タスクの成功率は、平均ナビゲーション回数とある程度相関があると仮定できる
- 横軸がナビゲーションの回数、縦軸が1回あたりの成功率、色がタスクの成功率
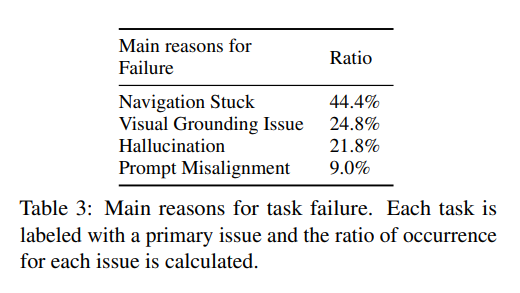
- エラーの理由
- Navigation Stuck
- 最も多い理由で、エージェントが指定の回数を使い切った
- 検索クエリが正確でなく無関係な場合。以前の行動をい修正するよりも、異なる結果を閲覧したり、間違った結果を好む
- スクロール可能な画面領域がほんの一部の場合、エージェントは正しいスクロール領域を見つけられない
- Visual Grounding Issue
- 発音や数式の文字を誤認するといった、あまり頻繁に観測できないパターンを解釈できない
- 以前の2回の観測の微妙な違いを認識できない
- 近接性による行動の誤認
- 隣接する要素間の誤認
- カレンダー上の数値を数値ラベルとして誤認
- Webサイトがミチミチ
- 私んぼ所感:近接性による誤認はテキストベースでやっても起こり得るのでここは納得できる
- ハルシネーション
- 特定の要求を見落とし、部分的に正しい答えるに落ち着く
- 例:最も安い商品を尋ねられたときに、スクリーンショットに見える安い商品に反応し、ソートを無視する
- 一見正しい行動しているのに、正しい推論経路から逸脱
- 例:間違ったテキストボックスにコンテンツを入力
- 特定の要求を見落とし、部分的に正しい答えるに落ち着く
- プロンプトの不整合
- 複雑なプロンプトを理解することは大きな課題
- 軌道が長い、文脈が長いと効果的に指示に従うことができない場合がある
- ナビゲーションエラーのほとんどはプロンプト不整合にあるのではないか
- Navigation Stuck
所感
- スクロールやクリックのたびにGPT-4Vと要素を推論にかけるのはコスト面の実現性が皆無で、「これぞ研究」という感じで逆に面白かった
- 汎用ウェブエージェントはまだ研究段階だなという所感。ただ、結構評価データセットの作り方や限界など示唆に富むものが多かった。UXを考慮する点において画像を取り入れてマルチモーダルにするというのがなるほど感
- 評価を人手でしているのがかなりスケーラビリティの限界で、これはGPT-3.5で実行し、GPT-4を人間の代理として評価するという、GPT-4Vに対して上位のマルチモーダルLLMが存在しないため。今後このへんが自動化されてくると思われる
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー