
CoCaとBLIP2を使ってみた:ImageNet、キャプション生成


CoCaとBLIP2の訓練済みモデルで遊んでみました。「ImageNet 1Kのゼロショット精度」と「キャプション生成」の2点について検証してみました。
目次
きっかけ
ほぼ同時期にBLIP2とCoCaと訓練済みモデルが公開されました。
https://twitter.com/LiJunnan0409/status/1621649677543440384
CoCaは以前から公開されていましたが、LAIONデータセットで訓練されたモデルがOpenCLIPに統合されたものとして公開されました。
Training Contrastive Captioners
BLIP2とCoCaについて
一言でいうと、BLIP2もCoCaもキャプション生成が可能なモデルです。
BLIP2
以前こちらの記事に書いたのですが、BLIP2は固定の画像エンコーダーと固定の大規模言語モデルを、学習可能なQ-Formerでつなげて、画像を起点とした対話生成が可能なシステムです。
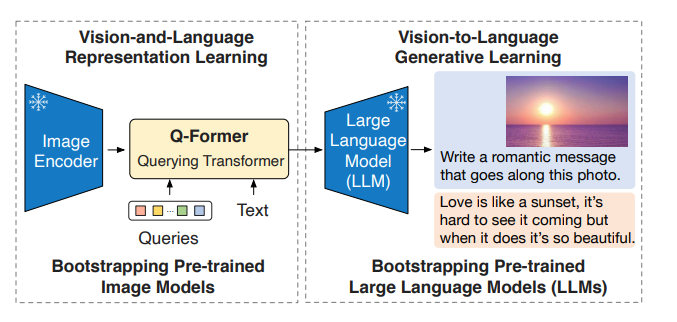
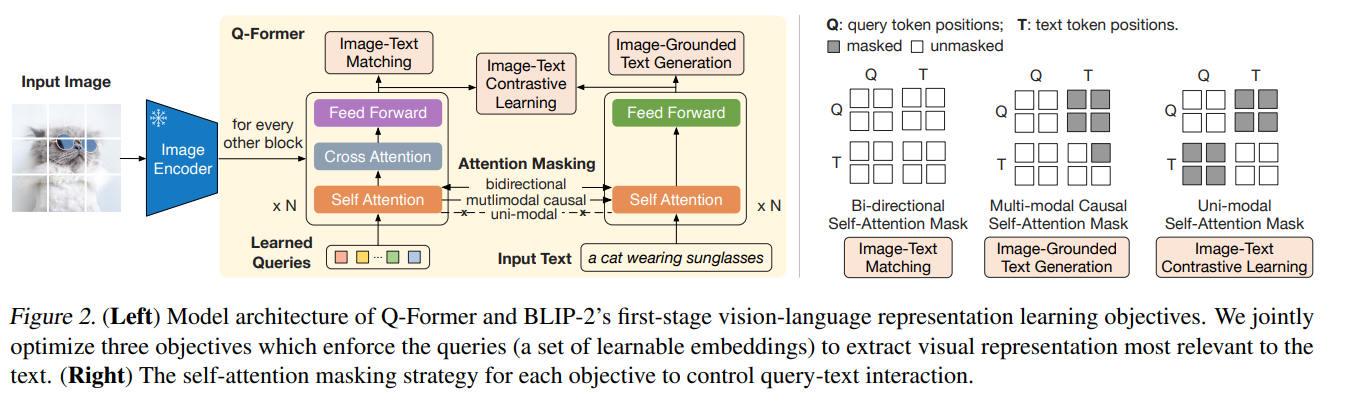
学習の1段階目でContrastive Learningをしているので、Q-Formerの出力を取ることで、CLIPライクなゼロショット推論が可能です。論文でもText-Image、Image-TextのRetrievalを行っています。
CoCa
CoCaはCLIPの拡張形で、Text-EncoderとImage-Encoderによるクロスモダリティな学習のあとに、Text-Decoderを突っ込んだものです。CLIPが右から2番目のDual-Encoder Modelです。お気持ちとしては、「Dual-Encoderでできなかったキャプション生成もできるし、Text-Decoderを入れたほうが表現の学習能力も高いよ」ということです。
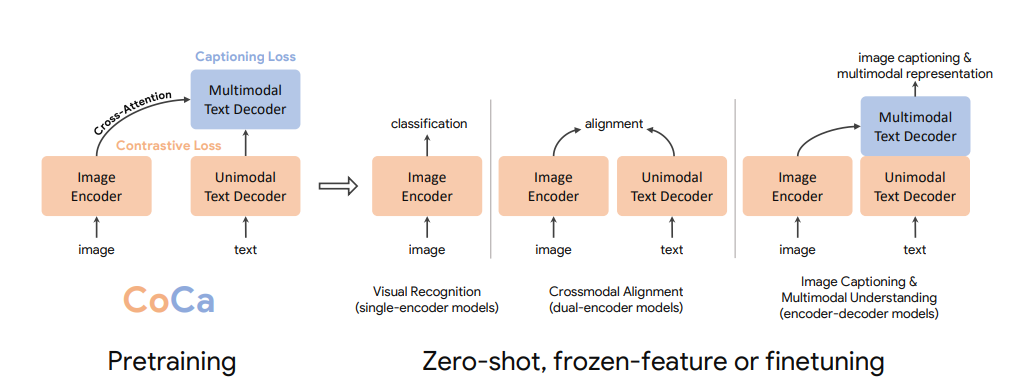
OpenCLIPのフレームワークに含まれているので、実際の使い方はCLIPと同じです。
ImageNet1Kのゼロショットの性能を調べる
実験として、ImageNet1KのValidaitionデータに対するゼロショット性能を見てみましょう。
カレントディレクトリ以下に、以下のようなフォルダ構成でImageNetのValidaitionデータが入っているとします。
- val
- n01440764
- ILSVRC2012_val_00000293.JPEG
- : :
- : :
- n15075141
- n01440764
また、クラス名とプロンプトのテンプレートとして、OpenCLIPの以下のファイルをダウンロードしておきます。
最新版のOpenCLIPをインストールしておきます。
pip install --upgrade open_clip_torch
画像のパスやアノテーション、プロンプトを読み込みます。
from imagenet_zeroshot_data import openai_imagenet_template, imagenet_classnames
import os
import glob
files = sorted([x.replace("\\", "/") for x in glob.glob("val/**/*", recursive=True) if os.path.isfile(x)])
dirnames = sorted([x.replace("\\", "/").split("/")[-1] for x in glob.glob("val/*")])
y_true = [dirnames.index(x.split("/")[1]) for x in files]
prompts = []
for cname in imagenet_classnames:
item = []
for func in openai_imagenet_template:
item.append(func(cname))
prompts.append(item)
print(len(y_true), len(files)) # 50000 50000
print(len(prompts), len(prompts[0])) # 1000 80
テストするもの
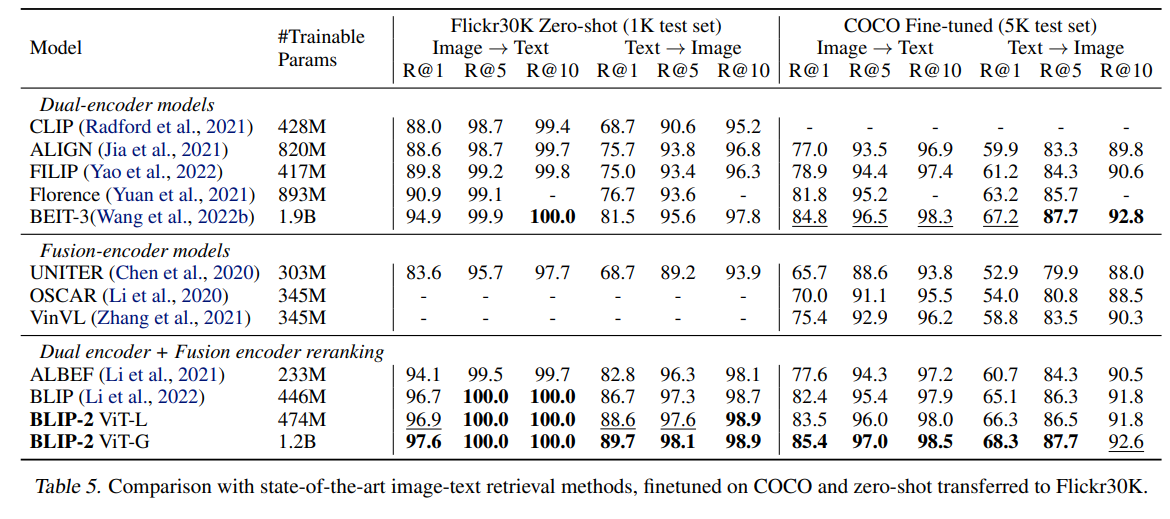
Image-Text、Text-Imageの両方で調べます。両方で調べたい気持ちとしては、BLIP2の論文を調べたときに、「CLIPからの進歩で見たときに、Image-Textは比較的サチり気味だったが、Text-Imageはかなり進歩がある」という印象があったからです。BLIP2の論文からです。
ImageNetで表すと、
- Image-Text:Val画像5万枚がどのクラスに含まれるか、というマルチクラスの精度
- Text-Image:各1000クラスについて、類似度順にソートしたときの上位50枚について(Val画像は各クラスにつき50枚含まれているため)、Ground Truthのクラスがどれだけ含まれているかというRecall@50をとる。この値をクラス間で平均する
CoCa(ViT-B/32)
import open_clip
import torch
from PIL import Image
from tqdm import tqdm
import numpy as np
model, _, transform = open_clip.create_model_and_transforms(
model_name="coca_ViT-B-32",
pretrained="laion2b_s13b_b90k",
device=device, precision="fp32"
)
tokenizer = open_clip.get_tokenizer('coca_ViT-B-32')
text_embeddings = []
for item in prompts:
text = tokenizer(item).to(device)
with torch.no_grad():
text_features = model.encode_text(text)
text_features /= text_features.norm(dim=-1, keepdim=True)
text_embeddings.append(text_features.mean(dim=0, keepdim=True))
text_embeddings = torch.cat(text_embeddings, dim=0)
text_embeddings /= text_embeddings.norm(dim=-1, keepdim=True)
print(text_embeddings.shape) # torch.Size([1000, 512])
image_embeddings = []
with torch.no_grad():
for f in tqdm(files):
image = transform(Image.open(f)).unsqueeze(0).to(device)
image_features = model.encode_image(image)
image_features /= image_features.norm(dim=-1, keepdim=True)
image_embeddings.append(image_features)
image_embeddings = torch.cat(image_embeddings, dim=0)
simiralities = image_embeddings @ text_embeddings.T
pred_classes = simiralities.cpu().numpy().argmax(axis=-1)
# Image-Textの精度
np.mean(pred_classes == np.array(y_true))
dec_indices = np.argsort(simiralities.cpu().numpy(), axis=0)[::-1, :]
text_retrieval = []
for class_idx in range(dec_indices.shape[1]):
correct_ans = np.arange(len(y_true))[np.array(y_true)==class_idx]
item = []
for ans_idx in correct_ans:
item.append(np.any(dec_indices[:50, class_idx]==ans_idx))
text_retrieval.append(np.array(item).mean())
# Text-ImageのRecall@50
np.array(text_retrieval).mean()
結果は、
- Image-Text:63.602%
- Text-Image:50.944%
でした
通常のCLIP(ViT-B/32)
この値はViT-B/32のCLIPとくらべてどうなのかが気になります。比較してみましょう。
model, _, transform = open_clip.create_model_and_transforms(
model_name="ViT-B-32",
pretrained="laion2b_e16",
device=device, precision="fp32"
)
tokenizer = open_clip.get_tokenizer('ViT-B-32')
訓練データは同じLAION2Bとしました。
- Image-Text:65.666%
- Text-Image:53.706%
結果は普通のCLIPのほうが良かったです。ただ、ブログによると、
We train both model configurations on 13B samples seen from LAION-2B
と6~7エポックぐらいしか動かしていないため、CoCaのViT-B/32は訓練が不十分な可能性があります(出てすぐなのでこれからもっといいチェックポイントが出る可能性はあります)。もう少し他のモデルとも比較してみる必要がありそうです。
ところで、普通のCLIPについては、OpenCLIPのGitHubに
ViT-B-32 LAION-2B vit_b_32-laion2b_e16 65.62
とあったため、公称値がほぼ出ていることがわかります。
CoCaの結果まとめ
CoCaでもモデル構造やFine-tuningの有無を含めてためしてみました。
| モデル構造 | モデル名 | 訓練済み係数 | Image-Text | Text-Image |
|---|---|---|---|---|
| CoCa | coca_ViT-B-32 | laion2b_s13b_b90k | 63.60% | 50.94% |
| CoCa | coca_ViT-B-32 | mscoco_finetuned_laion2b_s13b_b90k | 0.91% | 0.57% |
| CoCa | coca_ViT-L-14 | laion2b_s13b_b90k | 75.65% | 63.30% |
興味深いのはFine-tuningの有無です。MSCOCOでキャプションをFine-tuningした例では(2つ目)、ImageNetの精度がノイズレベルに低下していました。近年よく言われているように、破滅的忘却の影響が見られます。
CoCa-ViT-Lでは、75.65%もImage-Textのゼロショット精度が出ました。
通常のCLIPのまとめ
ViT-B/32とViT-L/14の通常CLIPモデルもありますので、調べてみます。
| モデル構造 | モデル名 | 訓練済み係数 | Image-Text | Text-Image |
|---|---|---|---|---|
| CLIP | ViT-B-32 | laion2b_e16 | 65.67% | 53.71% |
| CLIP | ViT-L-14 | laion2b_s32b_b82k | 75.25% | 63.28% |
ViT-Lでみたとき、CoCaとCLIPはほぼ変わらない結果になりました。チェックポイント名を見る限りでは、若干CoCa側の訓練が足りないような気がしなくもないです。
結局CoCaとCLIPの違いは、現状「キャプション生成できるかどうか」ぐらいでしょうか。
BLIP2
BLIP2も調べていたらEmbeddingを取れたのでやってみました。以下の「compute_sim_matrix」を参考にしました
LAVISをインストールします
pip install salesforce-lavis
from imagenet_zeroshot_data import openai_imagenet_template, imagenet_classnames
import os
import glob
import torch
import torch.nn.functional as F
from lavis.models import load_model_and_preprocess
from PIL import Image
from tqdm import tqdm
import numpy as np
load_model_and_preprocessはname=blip2にするのがポイントです。キャプション生成のモデル(blip2_t5, blip2_opt)では、直接特徴量を取れませんでした。model_typeはpretrainかcocoで選べます。
device = "cuda:1"
model, vis_processors, txt_processors = load_model_and_preprocess(name="blip2", model_type="pretrain", is_eval=True, device=device)
model.visual_encoder.float()
類似度の計算方法が若干CLIPと異なります。CLIPはnormで割るのでしたが、BLIP2はF.normalizeで正規化します。
text_embeddings = []
with torch.no_grad():
for item in tqdm(prompts):
text = model.tokenizer(
item,
padding="max_length",
truncation=True,
max_length=64,
return_tensors="pt",
).to(device)
text_feat = model.forward_text(text)
text_embed = F.normalize(model.text_proj(text_feat))
text_embeddings.append(text_embed.mean(dim=0, keepdim=True))
text_embeddings = torch.cat(text_embeddings, dim=0)
print(text_embeddings.shape) # torch.Size([1000, 256])
パッチ単位のEmbeddingを取っているようです。あとCLIPにはなかった射影のレイヤーが入っています。
image_embeddings = []
with torch.no_grad():
for f in tqdm(files):
raw_image = Image.open(f).convert("RGB")
image = vis_processors["eval"](raw_image).unsqueeze(0).to(device)
image_feat, vit_feat = model.forward_image(image)
image_embed = model.vision_proj(image_feat)
image_embed = F.normalize(image_embed, dim=-1)
image_embeddings.append(image_embed)
image_embeddings = torch.cat(image_embeddings, dim=0)
print(image_embeddings.shape) # torch.Size([50000, 32, 256])
クエリ→アイテムへの集計はざっくりMAXを取るようです。平均も試してみましたが、MAXのほうが良かったです。
sims_matrix = []
for image_embed in image_embeddings:
sim_q2t = image_embed @ text_embeddings.t()
sim_i2t, _ = sim_q2t.max(0)
sims_matrix.append(sim_i2t)
sims_matrix = torch.stack(sims_matrix, dim=0)
類似度の行列が出れば、あとはCLIPと同様です。
# Image->Textの精度
pred_classes = sims_matrix.cpu().numpy().argmax(axis=-1)
np.mean(pred_classes == np.array(y_true))
# Text->ImageのRecall
dec_indices = np.argsort(sims_matrix.cpu().numpy(), axis=0)[::-1, :]
text_retrieval = []
for class_idx in range(dec_indices.shape[1]):
correct_ans = np.arange(len(y_true))[np.array(y_true)==class_idx]
item = []
for ans_idx in correct_ans:
item.append(np.any(dec_indices[:50, class_idx]==ans_idx))
text_retrieval.append(np.array(item).mean())
np.array(text_retrieval).mean()
結果は以下のようになりました。
- Image-Text:64.132%
- Text-Image:45.644%
単純にEmbeddingだけ比較すると、CLIPよりも精度悪い結果となりました。これはBLIP2訓練データの数が少ないのが理由かと思います。以前の論文読んだときの記事だと、訓練データが1.29億枚。対するCLIP/CoCoの訓練データがLAION2B(20億枚)なので、15倍程度変わります。多分訓練データの数揃えたら10%ぐらい上がるのではないかと思います
pretrain=cocoの場合もまとめると以下のようになります。
| モデル構造 | モデル名 | 訓練済み係数 | Image-Text | Text-Image |
|---|---|---|---|---|
| BLIP2 | BLIP2 | pretrained(1.29億枚) | 64.13% | 45.64% |
| BLIP2 | BLIP2 | coco | 62.68% | 50.54% |
個人的に面白いのが、CoCoの場合は、CLIPのような破滅的忘却がそこまで起きていない点です。Image-Textが若干下がって、Text-Imageが大きく上がっているのが興味深いです。BLIP2のImage-Encoderは固定なので、画像側の破滅的忘却が避けられているのかもしれません。BLIP2のQ-Formerは発想的には最近流行りのAdapterに近いので、破滅的忘却を引き起こしにくいのかもしれません。
BLIP2はImageEncoderが重いのか、画像特徴量の計算に時間かかりました。2080Tiで、5万枚の推論に、pretrainの場合は1時間30分、cocoの場合は3時間かかりました。cocoで訓練されたBLIP2は、ImageEncoderが一回り大きいのではないかと思います。CLIPやCoCaのViT-Lの場合は、26分程度で終わりました。
ImageNet1Kのゼロショット結果まとめ
| モデル構造 | モデル名 | 訓練済み係数 | Image-Text | Text-Image |
|---|---|---|---|---|
| CoCa | coca_ViT-B-32 | laion2b_s13b_b90k | 63.60% | 50.94% |
| CoCa | coca_ViT-B-32 | mscoco_finetuned_laion2b_s13b_b90k | 0.91% | 0.57% |
| CoCa | coca_ViT-L-14 | laion2b_s13b_b90k | 75.65% | 63.30% |
| CLIP | ViT-B-32 | laion2b_e16 | 65.67% | 53.71% |
| CLIP | ViT-L-14 | laion2b_s32b_b82k | 75.25% | 63.28% |
| BLIP2 | BLIP2 | pretrained(1.29億枚) | 64.13% | 45.64% |
| BLIP2 | BLIP2 | coco | 62.68% | 50.54% |
結論としては、CLIPとCoCaはキャプション生成できるかどうかぐらいしか変わらない。BLIP2は訓練データが少なすぎて単純に比較できないという「まあそうですよね…」という結果になりました。IN1Kの精度という点では、CLIPが健闘したのは若干驚きでした。
キャプション生成結果
CLIP以外はキャプション生成できるということで、生成してみましょう。
import os
import glob
import numpy as np
import torch
import open_clip
from PIL import Image
import matplotlib.pyplot as plt
from lavis.models import load_model_and_preprocess
まずはランダムにターゲットの絵を選びます。
files = sorted([x.replace("\\", "/") for x in glob.glob("val/**/*", recursive=True) if os.path.isfile(x)])
np.random.seed(4545)
np.random.shuffle(files)
最初の4つをとって可視化すると次のようになります。

CoCaでのキャプション生成は以下のようにします。
def generate_coca_captions(files, model_name, pretrained):
model, _, transform = open_clip.create_model_and_transforms(
model_name=model_name,
pretrained=pretrained
)
results = []
for f in files:
img = Image.open(f).convert("RGB")
img = transform(img).unsqueeze(0)
with torch.no_grad():
generated = model.generate(img)
results.append(open_clip.decode(generated[0]).split("<end_of_text>")[0].replace("<start_of_text>", ""))
return results
BLIP2では次のようにします。
def generate_blip2_captions(files, model_name, model_type, prompt):
model, vis_processors, _ = load_model_and_preprocess(
name=model_name, model_type=model_type, is_eval=True)
results = []
for f in files:
img = Image.open(f).convert("RGB")
img = vis_processors["eval"](img).unsqueeze(0)
results.append(model.generate({"image": img, "prompt": prompt}))
return results
CoCaの生成結果
| model_name | pretrained | caption |
|---|---|---|
| coca_ViT-B-32 | laion2b_s13b_b90k | 1 9 9 2 – 1 9 9 3 new balance x – 9 0 v 2 low – top running shoes size 1 1 . 5 made in u . s . a . |
| coca_ViT-B-32 | laion2b_s13b_b90k | a white lemur is one of the most common lemurs found in south america . it is one of only two lemurs found in south america , and is one of only two lemurs found in south america . this is one of only two lemurs found in south america , and is one of only two lemurs found in south america , and is one of only two |
| coca_ViT-B-32 | laion2b_s13b_b90k | red – bellied black snake |
| coca_ViT-B-32 | laion2b_s13b_b90k | 2 0 1 2 devinci devinci 2 7 . 5 2 7 . 5 x 2 7 . 5 full suspension mountain bike 2 7 . 5 x 2 7 . 5 |
| coca_ViT-B-32 | mscoco_finetuned_laion2b_s13b_b90k | a couple of bananas that are on a table . |
| coca_ViT-B-32 | mscoco_finetuned_laion2b_s13b_b90k | a goat that is laying down on some dirt . |
| coca_ViT-B-32 | mscoco_finetuned_laion2b_s13b_b90k | a small bird on a rock near a small body of water . |
| coca_ViT-B-32 | mscoco_finetuned_laion2b_s13b_b90k | a bike parked up against a yellow wall . |
| coca_ViT-L-14 | laion2b_s13b_b90k | old shoes , black and white |
| coca_ViT-L-14 | laion2b_s13b_b90k | siberian husky puppies for sale in texas siberian husky puppies for sale in texas akc puppyfinder 1 3 3 3 |
| coca_ViT-L-14 | laion2b_s13b_b90k | a western diamondback rattlesnake ( crotalus atrox ) with a tongue stuck in its mouth |
| coca_ViT-L-14 | laion2b_s13b_b90k | cannondale f 5 0 0 |
| coca_ViT-L-14 | mscoco_finetuned_laion2B-s13B-b90k | a pair of shoes sitting on top of a wooden floor . |
| coca_ViT-L-14 | mscoco_finetuned_laion2B-s13B-b90k | two dogs playing in the dirt behind a chain link fence . |
| coca_ViT-L-14 | mscoco_finetuned_laion2B-s13B-b90k | a close up of a snake with its tongue hanging out . |
| coca_ViT-L-14 | mscoco_finetuned_laion2B-s13B-b90k | there is a bicycle that is parked on the ground . |
生成されたキャプションを見ていきます。MSCOCOでFine-tuningされたかどうかで結構はっきり分かれていて、FTありだと小綺麗なキャプションになっています。
ただ、ViT-B/32だとFT後でも「靴を平気な顔してバナナ」と言ったり、「犬を羊と勘違い」していたりまあダメですね。FTなしのほうが、ViT-B/32でも生成キャプションは汚くても、「new balance」と言ったり、「red – bellied black snake」ち言ったり、ゼロショットモデル特有の細かい表現を捉えているような印象はあります。
ViT-L/14のFT後だとそこそこ使えそうですが、black and white(白黒写真)が消えたり、シベリアンハスキーを「dog」と丸められたり、蛇の具体的な品種を「snake」と丸められたりなんか面白みの少ないキャプションという印象は拭えません。良くも悪くもCOCOっぽいキャプションです。
BLIP2の結果
BLIP2で本来想定された使い方はVQAですが、プロンプトのテキストをなしにすることで、キャプション生成っぽい使い方ができます。
プロンプトを、
- 何も入力しない
- 「Question: What is the caption for this image? Answer:」にする
- 「Question: What is this? Answer:」にする
で比較してみましょう。モデルはEmbeddingとったときのモデルだとキャプション生成できないので、一番軽い「blip2_opt」の「pretrain_opt2.7b」にします。
| model_name | prompt | caption |
|---|---|---|
| blip2_opt-pretrain_opt2.7b | [‘black and white photo of a pair of running shoes’] | |
| blip2_opt-pretrain_opt2.7b | [‘two dogs sniffing each other’] | |
| blip2_opt-pretrain_opt2.7b | [‘a snake with its mouth open on the ground’] | |
| blip2_opt-pretrain_opt2.7b | [‘a bicycle is parked against a wall in front of a yellow wall’] | |
| blip2_opt-pretrain_opt2.7b | Question: What is the caption for this image? Answer: | [‘Shoes’] |
| blip2_opt-pretrain_opt2.7b | Question: What is the caption for this image? Answer: | [‘Dogs’] |
| blip2_opt-pretrain_opt2.7b | Question: What is the caption for this image? Answer: | [‘garter snake’] |
| blip2_opt-pretrain_opt2.7b | Question: What is the caption for this image? Answer: | [‘mountain bike’] |
| blip2_opt-pretrain_opt2.7b | Question: What is this? Answer: | [‘Shoes’] |
| blip2_opt-pretrain_opt2.7b | Question: What is this? Answer: | [‘A dog’] |
| blip2_opt-pretrain_opt2.7b | Question: What is this? Answer: | [‘a garter snake’] |
| blip2_opt-pretrain_opt2.7b | Question: What is this? Answer: | [‘A bike’] |
プロンプトに何も入れないと普通のキャプション生成、QA形式で入れると短答になるそうです。このへんの使い分けはいいですね。
キャプション生成も個人的にはCoCaよりもこっちのほうが簡潔で(個人的には)好きです。キャプション生成の点で見ると、大規模言語モデルのパワーは強いですね。
まとめ
- ImageNetのゼロショット性能(Retrievalの性能)という点では、
- 訓練データ数のオーダーが違うので、(LAION提供の)CLIPのほうが(Saleforce提供の)BLIP2よりも性能がいい
- (LAION提供の)CLIPとCoCaはほぼ同程度
- キャプション生成の点で見ると、
- BLIP2のほうがCoCaよりも一方上に見える
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー