
論文まとめ:Cosmos World Foundation Model Platform for Physical AI
Posted On 2025-01-17


- タイトル:Cosmos World Foundation Model Platform for Physical AI
- 著者:NVIDIAの方々
- 論文URL:https://arxiv.org/abs/2501.03575v1
- GitHub:https://github.com/NVIDIA/Cosmos
目次
ざっくりいうと
- 物理AIが学習データ不足で進化しづらい課題を解決するため、大規模な高品質動画をキュレーションし、テキスト生成でアノテーションを行うパイプラインを構築。
- 連続・離散両方の動画トークナイザー(Cosmos Tokenizer)を開発し、拡散モデルと自己回帰モデルからなる世界基盤モデル(WFM)を事前学習して物理シミュレーション能力を向上。
- 事後学習では、カメラ制御・ロボット操作・自動運転といった下流タスクに特化させることで、3D一貫性や物理的整合性を備えた動画生成や行動制御を実現。
背景
- AIのいくつかの分野が大きく進歩したが、物理AIはほとんど進化していない。物理AIの学習データをスケーリングが困難であるため
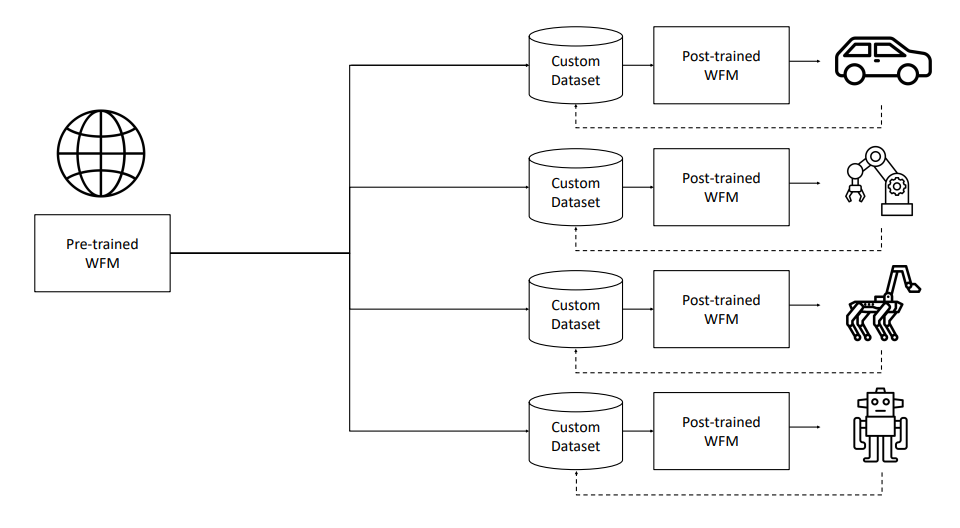
- 物理AI構築のためのCosmos世界基盤モデル(WFM)プラットフォームを提案
- 事前学習(拡散WFM)したWFMから、カスタムデータセットにより事後学習を行い、特化したWFMを作成(自己回帰、カメラ制御、ロボット操作、自律走行)
- 事前学習部分は、200万の動画から、2秒から60秒までの約1億クリップを抽出して、VLMでキャプションを付与し、動画生成の各線モデルを訓練
訓練コードとモデルが商用利用可能なライセンスで公開されている
世界基盤モデルとは
観測値と摂動を入力として、将来の観測値を予測するもの。摂動とは、物理AIによる行動、乱数、テキスト記述

現在のCOSMOS
現在のCOSMOSには以下の項目が含まれる

- ビデオキュレーター:高品質で動的な情報量の多いサブセットを学習用に見つける
- 動画のトークナイザー:圧縮率の異なる動画トークナイザーを開発。画像と動画の共同学習をしたい
- 世界基盤モデルの事前学習:拡散モデルと自己回帰モデルの両方を検討
- Text2World→Video2Worldの事前学習
- バニラな次トークン生成→テキスト条件付きVideo2World生成
- 世界基盤モデルの事後学習:ダウンストリームアプリケーションに応じてファインチューニング(例:カメラポーズを入力プロぷととし、ナビゲーション)。
- ガードレール機能もある
データキュレーション
高品質な動画データセットを作るためのキュレーションパイプライン
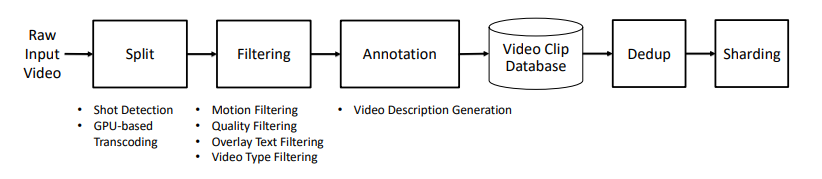
Splitting
長時間の動画をそのまま処理できないので区切る。物理的にもっともらしい映像内容の遷移を学習したい
- ショット検出:動画をシーン単位で分割(キッチンで二人が話している、サバンナでライオンがシマウマを追いかけている)。CVの古典的タスク。
- ShotBechという評価のOSSを作成:https://github.com/NVlabs/ShotBench
- 4つの手法を比較
- PySceneDetect : HSV空間のカラーヒストグラムの時間変化をしきい値処理。ディープでないのでしょぼい
- Panda 70M : CLIPの埋め込みを活用しフィルタリング。ImageBindやPysceneDetectとハイブリッドしており推論が複雑
- TransNetV2、AutoShot:エンドツーエンドのニューラルネットで100フレームの入力に対して、遷移フレームの確率を予測。TransNetV2がが良さそうとのこと
- トランスコーディング:エンコーダーガチ勢。動画のコーデックが大量にバラバラなので再エンコードする。スループットを上げないとやってられないので、
h264_nvencとして独自のエンコーダーに(徹底的に評価したと書いてある)

Filtering
- フィルタリングの目的:
- 品質の悪いデータの削除
- ファインチューニングに適した高品質のデータの選択
- WFM構築のためのデータ分布の調整
- 具体的には以下の3つのフィルタリングを行う
- モーションフィルタリング
- ビジュアル品質フィルタリング
- テキストフィルタリング
- モーションフィルタリング
- 目的:動いていない動画や、手持ちカメラのように急激にランダムに変わるモーションを削除。異なるカメラモーション(パン、ズーム、傾き)の動画にタグ付けする
- 実装:カスタムの分類器を作った。オプティカルフロー推定をして、新たに分類器を入れるのが一番精度が出る。
- ビジュアル品質フィルタリング
- 目的:ノイズ、ぼかし、露出不足・過多といって視覚的に見て品質の悪いデータを落としたい
- 実装:動画評価モデルを使用する。image aesthetic model (Schuhmann, 2022)を使い、評価スコアをベースに下位15%のクリップを削除。
- テキストフィルタリング
- 目的:過剰にテキストが入っている動画を削除したい
- 実装:InternVideo2(VLM)のEmbeddingをベースに、二値分類を訓練
Annotation
- 世界モデルの教師データや条件にテキストが必要。
- データに付与されているAlt テキストは品質が低く、異なるテキストスタイルやフォーマットに対応できない。VLMを使ってテキストキャプションを生成する。
- VFC, Qwen2-VL, VILAのVLMで比較したところ、VILAが正確な記述を生成することがわかった(内部の少量な人間の評価データにより判明)
- VILAに「Elaborate on the visual and narrative elements of the video in detail」というプロンプトを入れ、入力データからサンプリングされた8フレームを入れる。
- キャプションの平均長は559文字、97単語
- Tensor RTで量子化してバッチ処理したらスループットが速くなった
Deduplication
- 学習データの重複を削除する
- InternVideo2のEmbeddingを利用して、k=10000のk-MEANSを使う(RAPIDS、GPUで高速化)
- ペアワイズ距離を計算して重複を特定し削除。30%を削る
Shading
- 解像度、アスペクト比、長さに基づいて動画をシャード化
トークナイザー
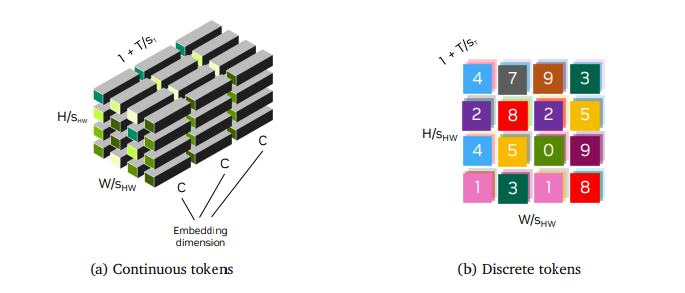
- トークナイザーには連続トークンと離散トークンがある
- 連続トークン化はStable DiffusionやVideoLDMのように、潜在拡散モデルで使われる
- 離散トークンはGPTのようなモデルに必要
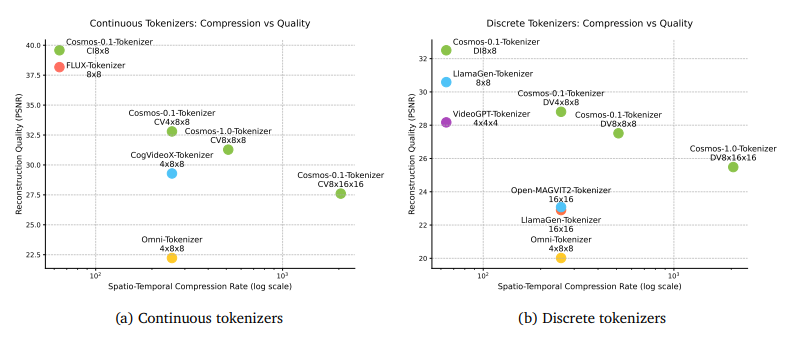
- 両方に対応したCosmos Tokenizerを独自に設計し、既存手法より圧縮率の評価が良かった
- ベンチマークのOSS:https://github.com/NVlabs/TokenBench
- 80GBのA100で、1080pで8秒、720pで10秒までの動画をワンショットでエンコード
- COSMOSトークナイザーがGitHubで公開されている:https://github.com/NVIDIA/Cosmos-Tokenizer
- 訳注:おそらくこのトークナイザーは世界モデル関係なく普通に有用

アーキテクチャー
- Encoder Decoder構造
- 時間的因果性を考慮したアーキテクチャー(時空間畳み込みと自己注意)
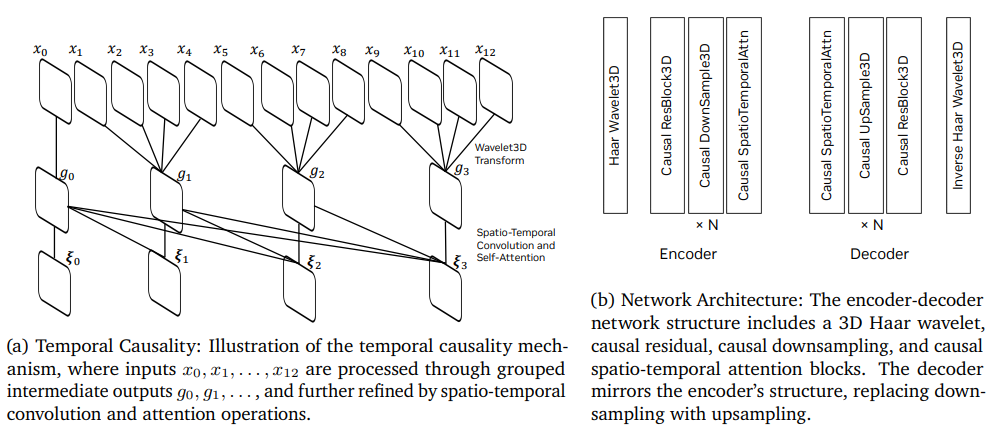
学習戦略
- 1段階目:ピクセルの再構成。L1ロスと、VGG-19の特徴量のPerceptual Loss
- 2段階目:オプティカルフロー損失。オプティカルフローの損失を下げるようにして時間的平滑性を取る
評価
復元性能が強く、速い。

WFMの事前訓練
- 拡散モデルと自己回帰の2つのWFMファミリーを構築
- 10000個のH100クラスタで3ヶ月で学習(←!?)
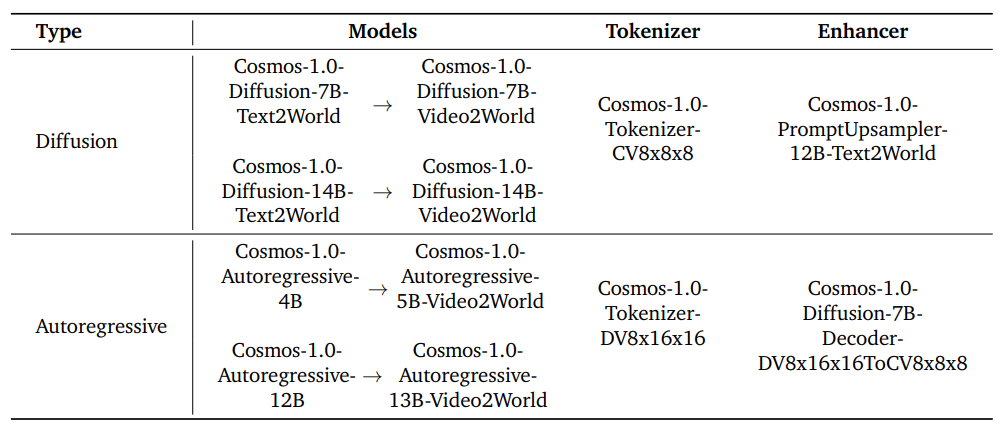
- 拡散モデル
- Text2World:テキストを条件として未来の映像を予測する
- Video2World:条件がテキスト
- モデルサイズが7Bと14B
- PromptUpsampler:人間のプロンプトをWFMが好むプロンプトに変換する。
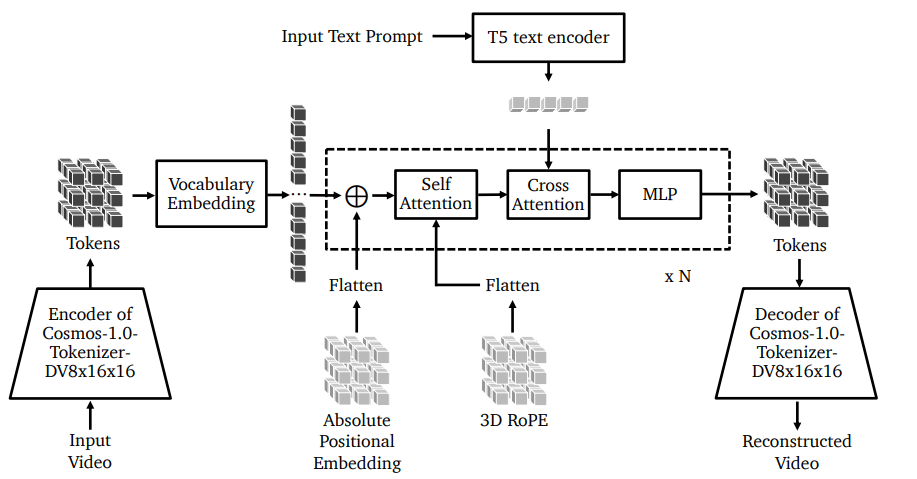
- 自己回帰モデル
- 最初に現在の動画観測に基づいて、将来の動画を予測(条件なし)
- Llama3スタイルのGPTだが、言語理解を伴わない
- 次に、Transfomerブロックを追加し、入力テキストの条件(T5 Embedding)をWFMに組み込む。
- Diffusion Decoder:トークナイザーの強い圧縮に対して望ましくない歪みに対処するため。離散トークンを連続トークンにマッピングするデコーダーを構築
拡散モデル版
アーキテクチャー
DiT(Diffusion Transformer)ベースのアーキテクチャー
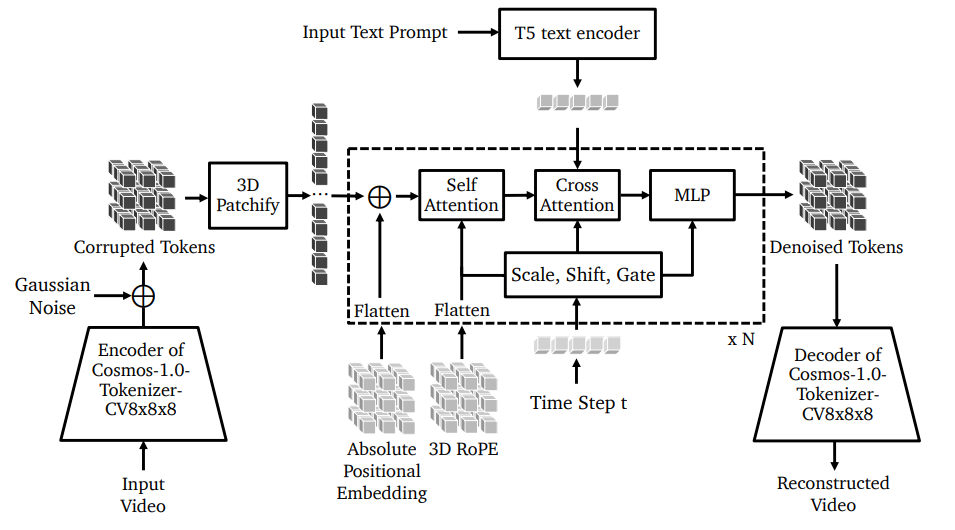
学習戦略
- 画像と動画を共同で学習
- 画像と動画データに対して推定された統計量を用いて潜在分布をアラインさせる、ドメイン固有の正則化スキームを採用
- プログレッシブ学習:低い解像度で学習し、次に高い解像度や長い動画で学習。コンテクスト長を長くしていく
- アスペクト比ごとにバケットを作り、1個のバケットからサンプリングする
- bf16とfp32のMixed Precision
- AdamWのβとeps係数を低くすることで、損失スパイクを大幅に減少可能
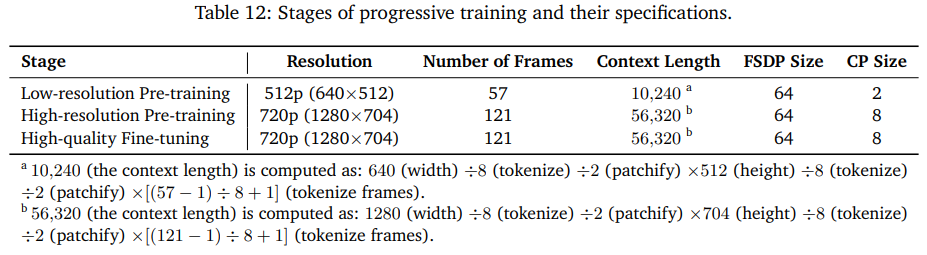
スケールアップ
- 何がVRAMを消費するか:モデルパラメーター、勾配、オプティマイザーの状態、活性化関数の値
- VRAM要件:拡散モデルの14Bの訓練時に280GB、プログレッシブの高解像度の場合は310GBのVRAMがいる。
- H100のVRAMは80GBで、複数GPUにマッピングするための戦略がいる
- 完全シャード並列(FSDP):メモリ効率を向上させる。
- モデルパラメーターや勾配、オプティマイザーをデバイス間でシャーディングして、必要なときだけパラメーターを収集、その後に解放
- 7Bモデルでは32、14Bモデルでは64のシャードを使う
- コンテクスト並列:ロングコンテクスト設定で、GPU間でどう分散させるか
- クエリとキーをシーケンス次元に沿ってチャンク分割
プロンプトアップサンプラー
- ユーザーからの短いプロンプトを、WFM好みの長いプロンプトに変換。図の下のようなプロンプト
- Mistral-NeMo-12B-Instructをファインチューニング

自己回帰版
アーキテクチャー
- 3D位置埋め込み
- 3次元回転位置埋め込み(RoPE)
- 3次元絶対位置埋め込み(APE)
- より良い制御のためのテキストのクロスアテンション
- QKNormalization
- Attentionにおいて、ドット積を計算する前にクエリ(Q)キー(K)ベクトル正規化することで、Attentionの不安定性に対応。ソフトマックスが飽和することを防ぎ、より効率的な学習を実現
- Z-loss:学習の安定性の向上が目的。ロジットのゼロからの偏差にペナルティを与え、勾配爆発や数値の不安定性を抑制
スケーリングアップ
- 訓練時に12Bモデルで192GBのVRAMが必要
- 複数GPUにマッピングするための戦略
- テンソル並列化(TP):入力または出力特徴次元のいずれかに沿って線形層の重みを分割し、GPU間通信を最小化
- シーケンス並列性(SP):シーケンス次元に沿ってコンテキストをさらに分割することで、Tensor Parallelismを拡張
学習戦略
- 第一段階:ビデオの予測をするための学習。17フレームをInputとして、未来の16フレームを予測
- RoPEのコンテクスト長を増やすために、時間次元のYaRN拡張を使用
- 第二段階:テキストの条件を追加。クロスアテンション層を追加
- クールダウン:事前学習後、LLMの学習方法と同様に、高品質なデータを用いてクールダウンフェーズを実施
リアルタイム生成へ向けた推論最適化
- PyTorchのgpt-fastの実装に従う
- https://github.com/pytorch-labs/gpt-fast
- Key-Valueキャシング、テンソル並列、torch.compileの組み合わせ
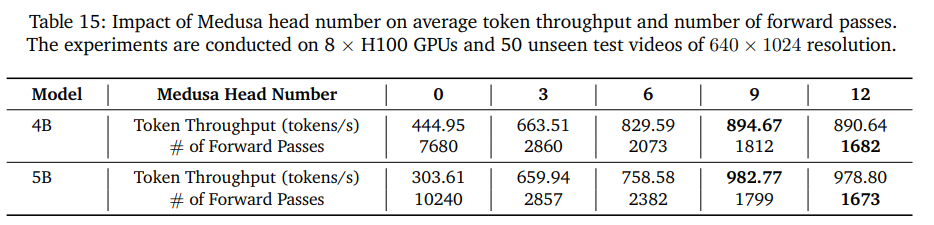
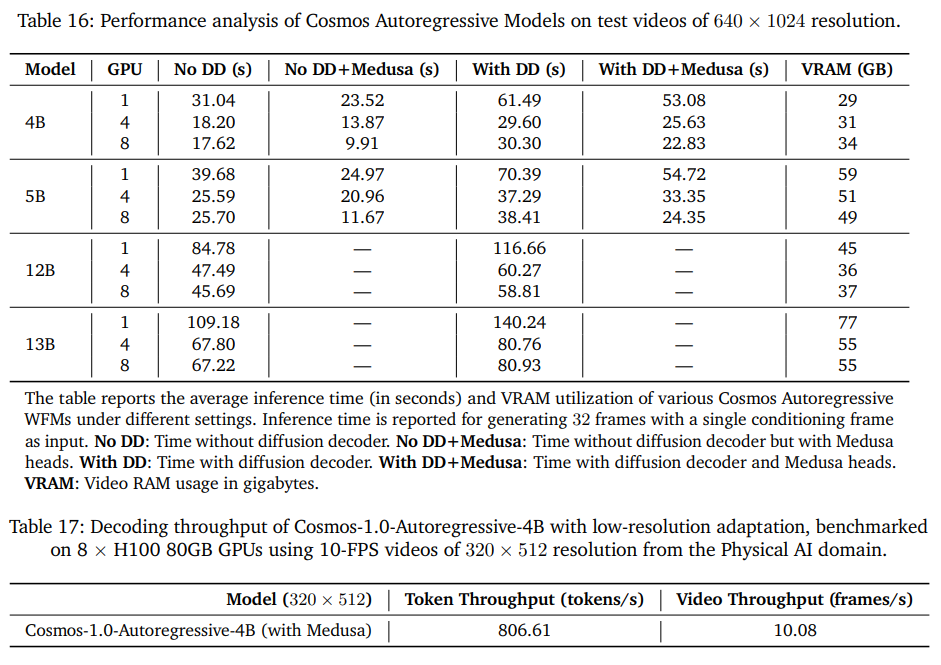
- トレーニングフリーの方法は限られているので、Medusaの投機的でコーディングフレームワークという、複数の後続トークンを並列に予測する学習ベースの手法を導入
- Medusaヘッド数による影響(上)
- 推論時のVRAM消費量(下)
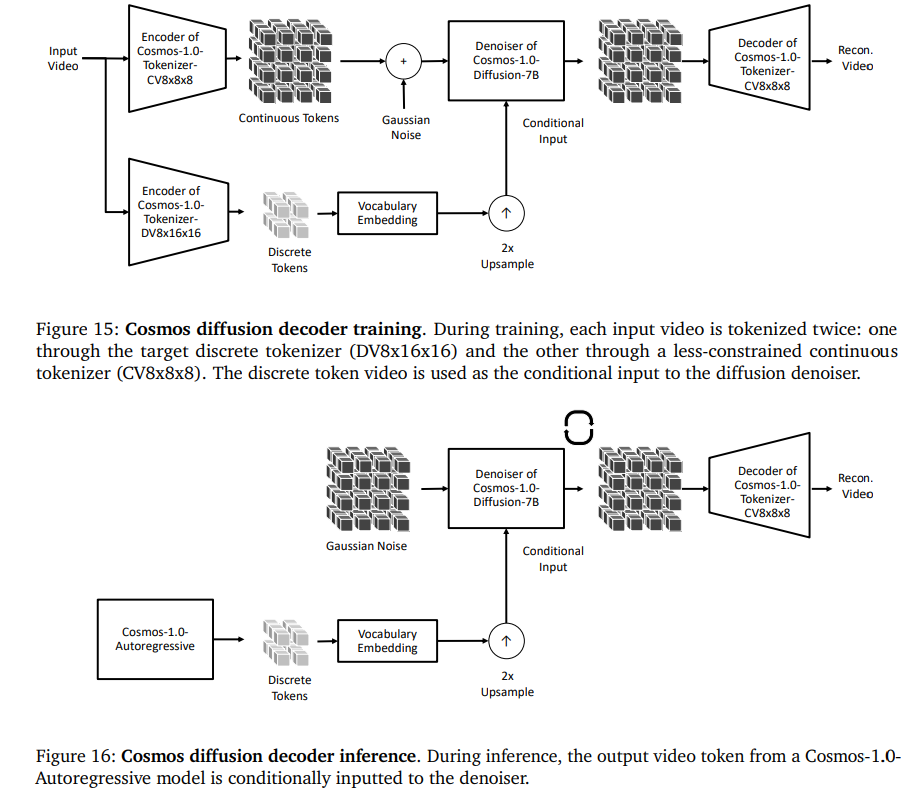
拡散デコーダー
- Cosmosトークナイザーは積極的な圧縮を行うための軽量なモデルで、トークン数を削減
- 積極的に削った結果、動画生成でぼやけたりアーティファクトにつながることがある
- 特に自己回帰では、離散トークン化によってリッチな動画表現をするためにわずかな値しか使われない→連続トークンにマッピングする必要がある
- 上が拡散デコーダーの訓練時、下が推論時
評価指標
- 幾何的整合性:生成された世界の3D一貫性を評価
- Sampson誤差:ある注目点から別のビューに対応するエピポーラ線までの距離の一次近似(上の画像の式)
- SuperPointとLightGlueを組み合わせて、フレームペアからキーポイントを検出し、OpenCVの8ポイントRANSACアルゴリズムを用いてFを推定
- カメラエピポーラ推定アルゴリズムの成功率
- 参考:エピポーラ幾何
- 3次元的な一貫性の評価:新しい視点を自己合成する能力の評価。3D Gaussian Splattingを使う
- Nerfstudioのライブラリのデフォルト設定を使い、3D Gaussian Splattingを使い、PSNR、SSIMを評価

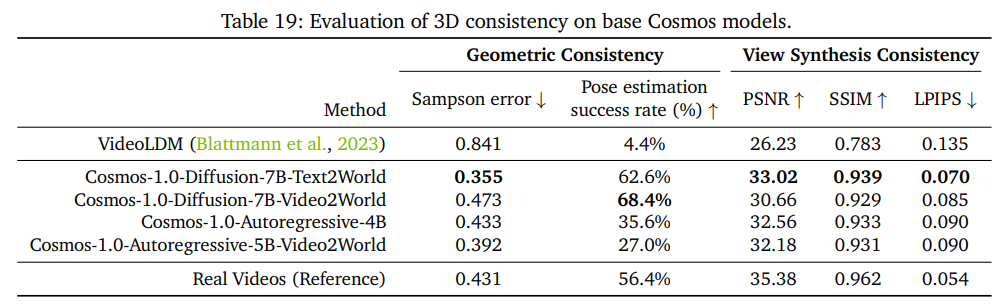
物理アラインメント
- 動画生成モデルが物理シミュレーションをできることを評価するにはどうしたらいいか?
- 物理シミュレーションエンジンを用いて、ベンチマークセットを設計する。ニュートン物理学と剛体力学に対するWFMの適合性をテスト
- 合成データの作成:PhysXとIssac Simを用いて、8個の物理的効果を評価するためのシナリオ作成。
- 自由落下物体(重力、衝突など)
- 傾斜した平面を転がる物体(重力、慣性モーメントなど)
- U字型の傾き(ポテンシャル、運動エネルギー)
- 安定したスタック(平衡状態にある物体のスタック)
- 不安定なスタック(重力、衝突など)
- ドミノ(運動量、衝突の移動)
- シーソーの両側にある物体(トルク、回転慣性)
- ジャイロスコープ:平らな面に回転(角運動量、等差運動)
- オブジェクトや背景はNVIDIAのOmniVerseのアセットを活用

WFMの事後訓練
特化したシチュエーションとして以下のシナリオによる事後訓練サンプルがある

カメラ制御のための事後訓練
- データセット
- 静的シーンの大規模動画データセットのDL3DV-10Kを使用
- カメラポーズのアノテーションを得るために、GLOMAPを用いてSfMする
- ファインチューニング
- カメラの潜在埋め込みを追加する。Plücker埋め込みを制御条件として追加
- 評価
- ビデオ品質:FID、FVD
- 3D一貫性:SfMライブラリを用いて、カメラ軌道誤差を定量化

ロボット操作のための事後訓練
- データセット
- 上、下、左、右というInstructionに対する予測ができればよい。Cosmos-1Xデータセットという内部データセットを作成
- 1x. TechというヒューマノイドであるEVEが、ナビゲーション、衣服の折りたたみ、テーブルの操作といった一人称動画での構成
- これにより、Instruction Tuningの問題として置き換えられる

自律走行のための事後訓練
- データセット
- 実走行シーンデータセットという内部データのキュレーション(2万時間のデータ)
- 前面、左、右、後面、後面左、後面右の6個のカメラ視点からなる
- 車の大きさ、天気、昼夜、車の速度、車の状態、周囲の状況(都市・田舎などOpenSteetの定義)のアノテーションがついている
- 多視点動画による動画生成ができるようなファインチューニングを行う
- 評価
- 事前訓練の評価指標を多視点に拡張すればOK
- 動画生成の定量評価
- マルチビューの一貫性(時間的サンプソン誤差、クロスビューのサンプソン誤差)
- カメラ軌道の考慮

ガードレール
ガードレール機能のパイプライン
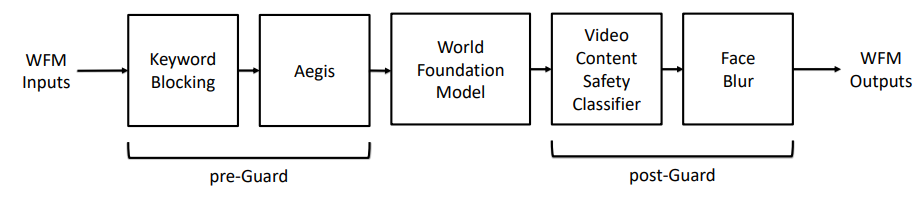
プレガード
- キーワードによるブロッキング:NGワード
- AGEISガードレール
- NVIDIAのAegis Content Safety DatasetでLlama-Guardをファインチューニングし、NVIDIAの13の安全リスクカテゴリーをカバー
- AGEIS 1.0に防御版と寛容版の二種類があり、防御版のほうがガードレールが厳しい
- フィルタリング例::暴力、性的、犯罪計画、武器、薬物乱用、自殺、児童性的虐待の物質、憎悪、嫌がらせ、脅迫、冒涜
ポストガード
- ビデオコンテンツ安全フィルタ:生成された動画の安全性について評価する
- アノテーションデータを収集
- 大量に動画をサンプリングし、VLMでクラスを決定
- エッジケースをカバーするために、WFMで合成ビデオを生成
- 人間のアノテーターによるゴールドスタンダードのラベルを提供
- 推論はSigLIPによる埋込を使って分類器を適用。どれかのフレームが安全でないとフラグ付けられたら、動画全体を安全でないとマーク
- 顔ぼかし:RetinaFaceで顔検出しぼかす
結論
データキュレーションパイプライン、連続・離散トークナイザーの設計、拡散・自己回帰世界基礎モデルのアー
キテクチャ、多様な下流物理AIタスクのための微調整プロセスなど、我々の包括的アプローチの概要を説明する。
注目すべきは、3D世界ナビゲーション、ロボット操作、3D一貫性と行動制御性の両方が要求される自律走行車シ
ステムなどの重要なアプリケーションに対する、事前に訓練された世界モデルの適応性を実証したことである。
- 限界:世界モデルが開発初期段階。物理シミュレーターとして信頼性はまだ不十分
- オブジェクト永続性の欠如、リッチダイナミクスの不正確さ、命令に従わない
- 重力、光の相互作用、流体力学などの基本的な物理原理を遵守しない
- 評価の課題
- 人間の身体的忠実性を評価するためのルールブックが存在しない。評価が個人の偏見や主観に影響されて困難
所感
- COSMOSの論文1本で75ページと非常に長く、実質論文7-8本ぶんぐらいのボリュームがあって非常に読むのが大変だった論文。ただ、読んで良かったと思った論文
- 世界モデルの論文を読んだが、1個のモデルで複数のモデルや要素が走っているコングロマリット状態。おそらく世界モデルそのものが有用というよりも、そこに出てくる個々のコンポーネントや概念が結構有効。
- 例えば、物理シミュレーションとして直接利用するよりも、パイプラインの個々のコンポーネントでやってるテクニックが、汎用的な動画処理のテクニックとして有効
- トークナイザーをEmbeddingモデルとして活用するのも良さそう。論文中でも「VLMのEmbeddingを使って…」となってるので、CosmosのトークナイザーもEmbeddingとして結構使われそうな気がする。
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー