
論文まとめ:Few-Shot Font Generation by Learning Fine-Grained Local Styles
Posted On 2022-08-04


- タイトル:Few-Shot Font Generation by Learning Fine-Grained Local Styles
- 論文URL:https://openaccess.thecvf.com/content/CVPR2022/html/Tang_Few-Shot_Font_Generation_by_Learning_Fine-Grained_Local_Styles_CVPR_2022_paper.html
- 著者:Licheng Tang, Yiyang Cai, Jiaming Liu, Zhibin Hong, Mingming Gong, Minhu Fan, Junyu Han, Jingtuo Liu, Errui Ding, Jingdong Wang
- カンファ:CVPR2022
目次
ざっくりいうと
- GANを使ってフォントを生成する研究
- 部首のような局所的な部分のスタイルに着目し、Cross Attentionを用いてターゲット-参照間の細かい表現を学習する
- 幅優先探索で部首の一致をみて、学習に有益なデータを参照データとして選択する工夫がある。SoTA達成
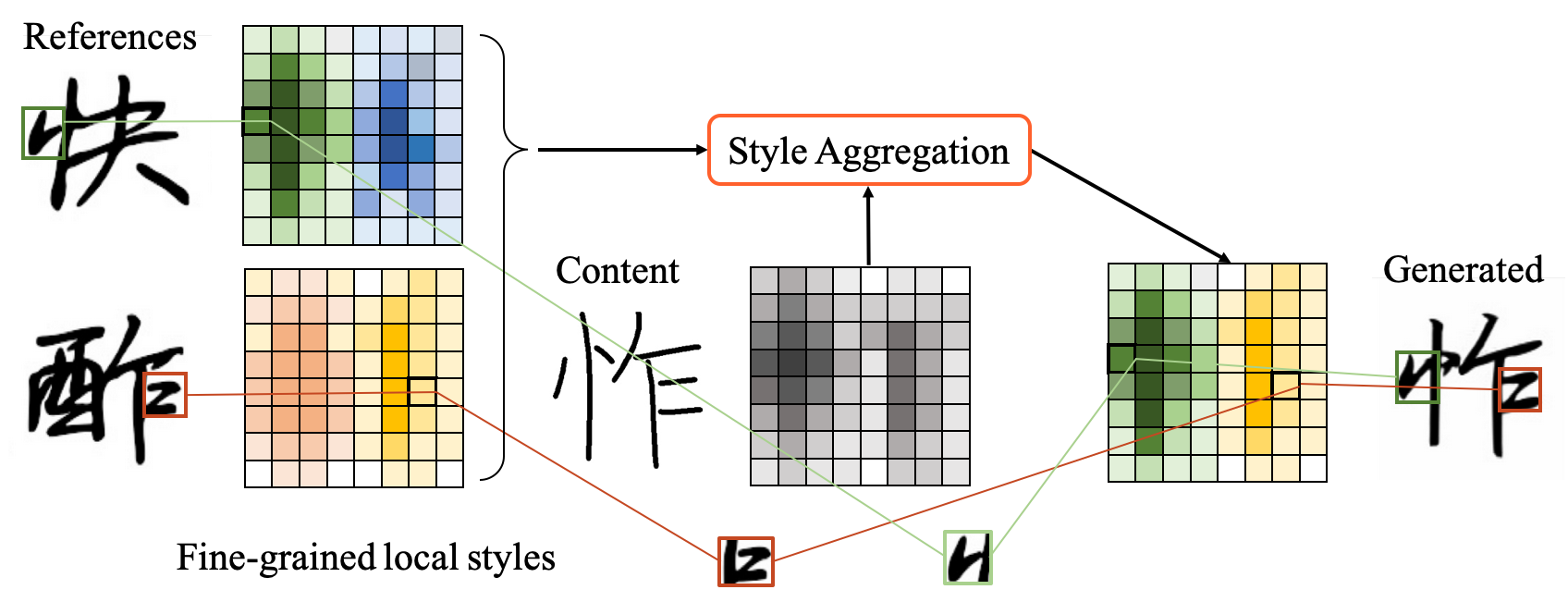
モチベーション
- 商用フォントでは、複数のレベルのスタイルを考慮する必要がある
- コンポーネント、ストローク、エッジの間のスタイルが、一貫性を持つように設計されている
- これまでの研究では、成分ごとのスタイルが中心で、細かなスタイルはほとんど無視されてきた
- コンテンツとスタイルは非常に密接に絡み合っているため、一般に用いられる明示的な離散化では、参照グリフと生成グリフ間のコンポーネント単位のスタイルの一貫性を保証することは困難
- 平たく言うと「部首」や「止めはね」の概念
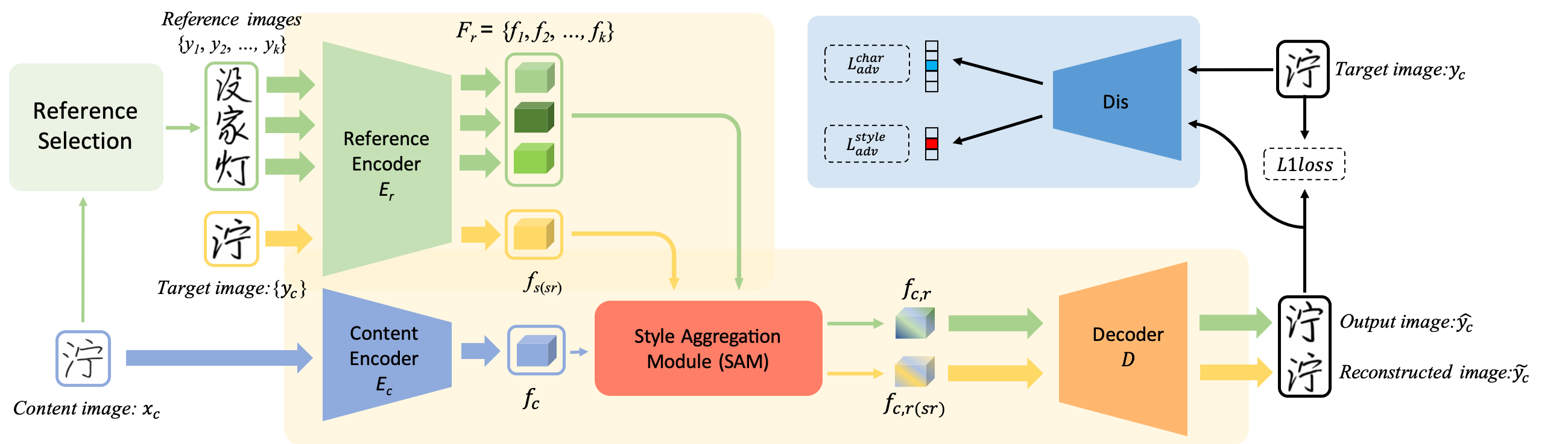
- ※この図では$y_c$と$x_c$が同一の文字であると書いてあるが、発展問題として未知の文字についても検証している
- 自己修復とは、$x_c$のフォント、スタイルとなるように復元したもの
手法
問題設定
- 参照文字のフォントは$L$個の、異なるフォント、スタイルからなる
Style Aggregation Module
Multi-Head Cross Attentionで実装している
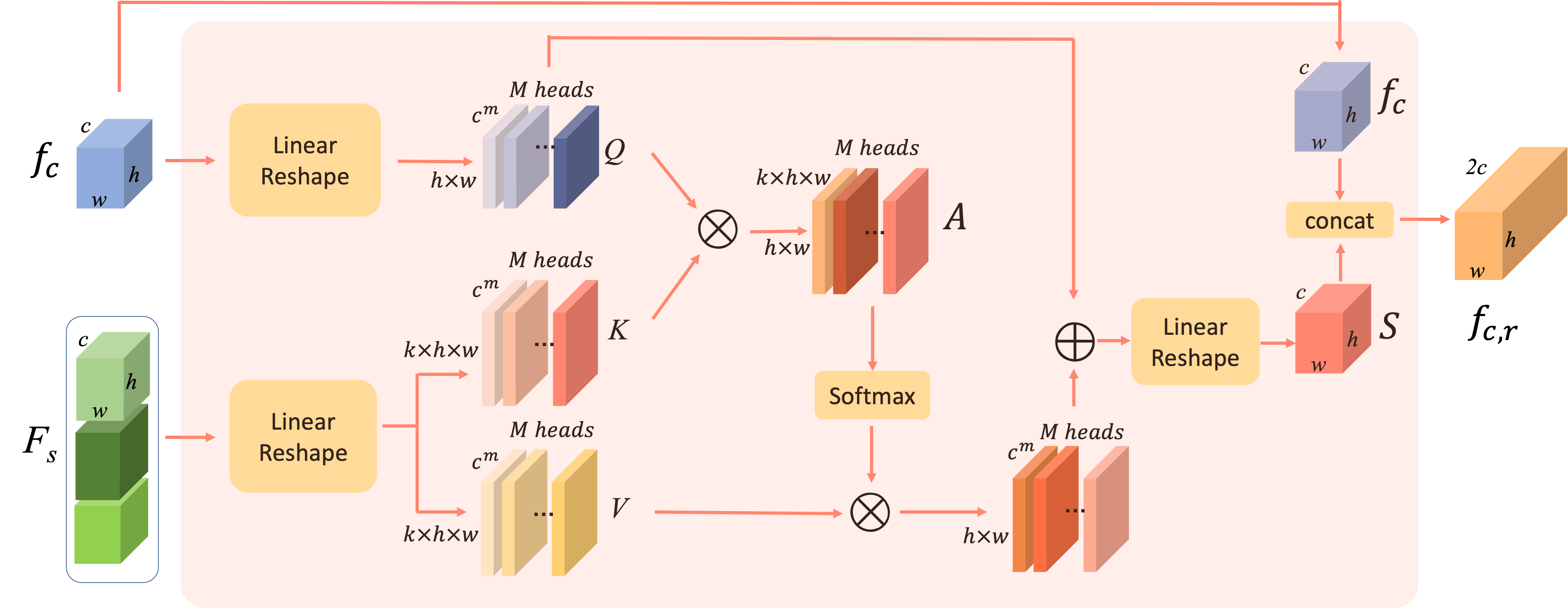
- $f_c$:Content Image$x_c$の特徴量
- $F_s$: Refernce Images$y_1, \cdots, y_k$の特徴量
Self Reconstruction
Cross Attentionの組み合わせを変えて(同一の文字の$y_c$)ブランチを作り、自分自身を再構成する出力$\tilde{y}_c$を作る
Refernce Selection
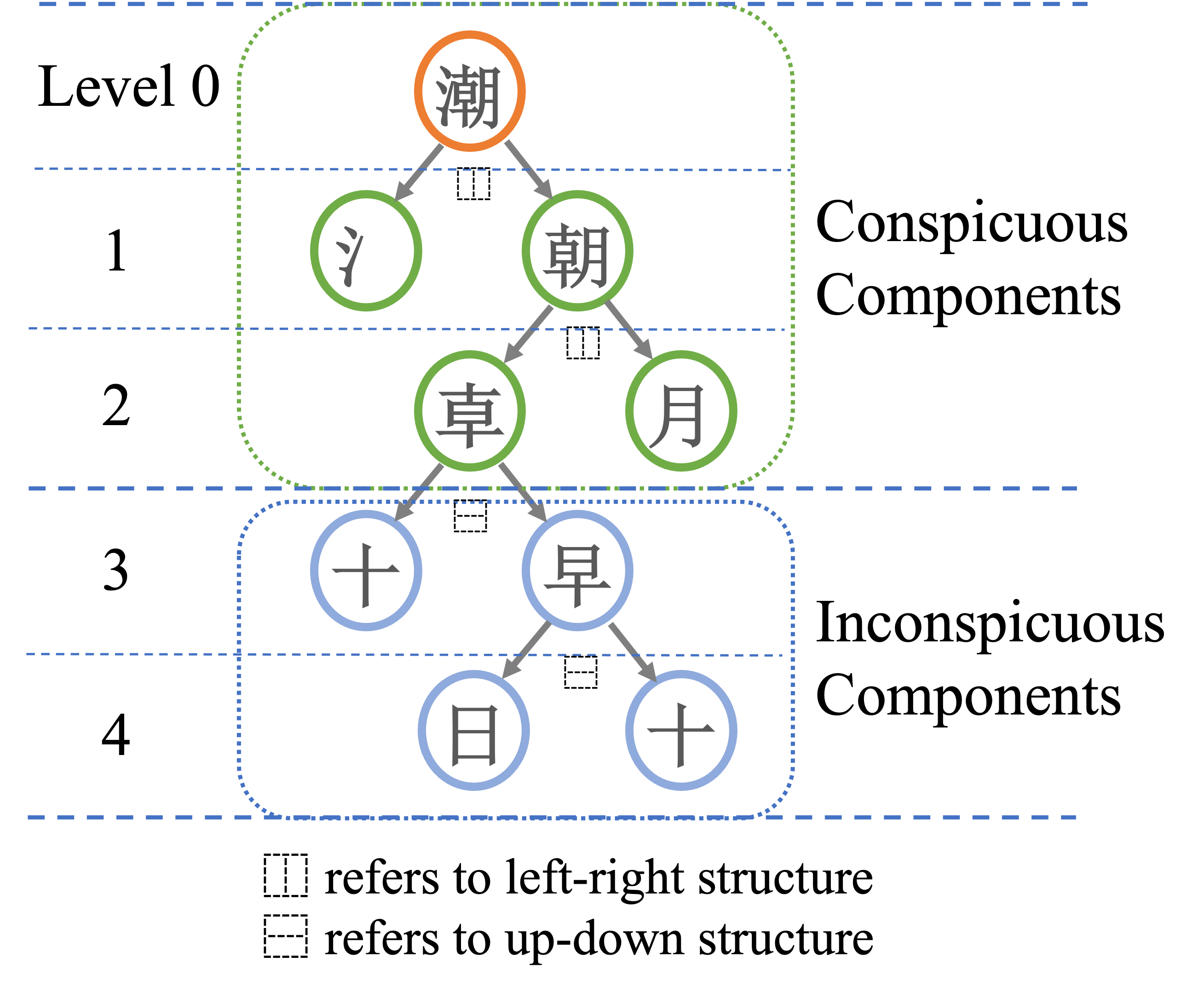
- 訓練でRefernce Imagesとして使う文字の探索にも工夫が入っている。幅優先探索で実装
- ランダムで文字を選択すると、部首が全く異なるため、部首ごとの特徴抽出の学習がほとんど進まない
- 部首が似ているような文字を、Refernce Imagesとして選択し、訓練するようなアルゴリズムを開発した
損失関数
- Adversarial LossとL1 Lossの組み合わせ
- AdvはMulti-head projection discriminatorのDの構造として計算
- L1はOutputとSelf Reconstructionの両方で計算

実験
データセット
- 407個のフォントから3396の中国語でよく使われる文字を選択肢
- Refernce Imagesは100個選択
- 新しい文字を生成するために必要なのは100個だから、Few-shotという主張
- 訓練データには397のフォント
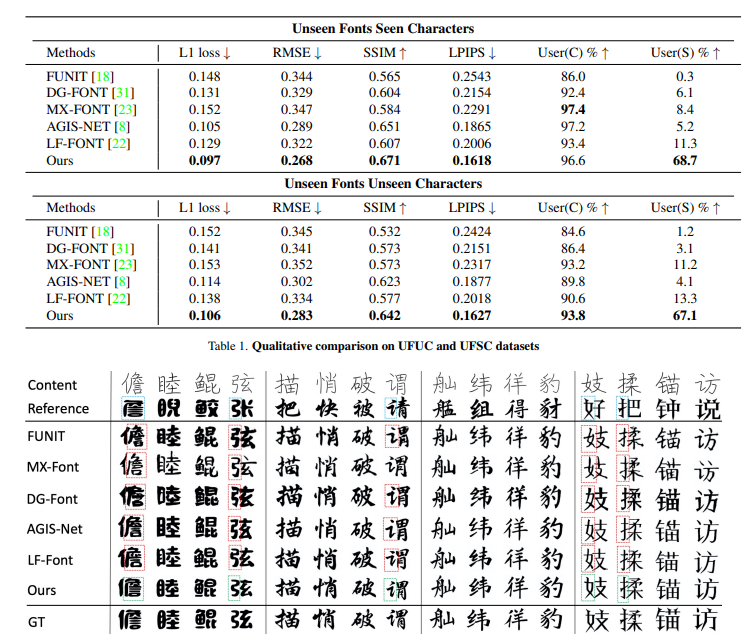
- Unseen Fonts Unseen Characters (UFUC)とUnseen Fonts Seen Characters (UFSC)で手法で比較
- UFUCはテストデータのフォント中の500文字、UFSCはテストデータのフォント中の2896文字
結果
既存手法との比較
既存手法は部首単位で見るとうまくいっていないことが多い
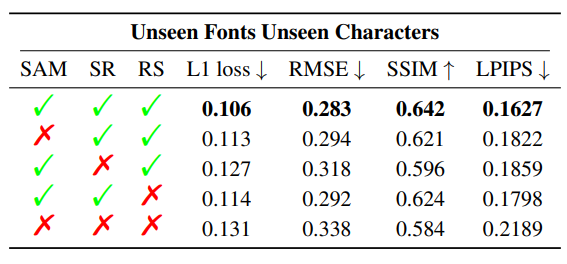
どの手法が効いているか?
- SAM : Style Aggregation Module
- SR : Self Reconstruction
- RS : Refernce Selection
一番効いているのがSelf Reconstruction(SR)。SAMとRSは同程度だが、SAMのほうがLPIPSで効いている(スタイル合成なので、Perception寄りのチューニングがされる?)
SRありなしの比較。SRがないと部首がかすれたり、Referenceの部首がそのまま伝播されることがある。

限界と悪影響
- 限界:限られたデータで学習するため、フォントの細部まで忠実に再現することはできない
- 悪影響:FSFontは手書き文字の模倣に使用できる可能性があるが、人間の専門家は、生成された手書き文字と実際の手書き文字の違いを見分けることができると主張
まとめと感想
- 論文はぱっと見難しいが、ネットワーク構成はよくあるタイプで、流れを読んで見るとそこまで難しくない
- これをFew-shotと呼んでいいのかは疑問が残る
- 最も効いていたのはSelf Reconstructionだが、Self Reconstructionとスタイル合成が同時にできたのは、ネットワーク構成をCross Attentionにしたからで、結局は「Cross Attentionが大事」ということではないだろうか
- DGFontのDeformable Convは結局いらないということで、ConvNetのみでも位置のアラインメントが取れてしまうというのが不思議
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー