
論文まとめ:Generative Multimodal Pretraining with Discrete Diffusion Timestep Tokens


- タイトル:Generative Multimodal Pretraining with Discrete Diffusion Timestep Tokens
- URL:https://arxiv.org/abs/2504.14666
- GitHub:https://github.com/selftok-team/SelftokTokenizer/
- カンファ:CVPR 2025 Best Student Paper Honorable Mention
目次
論文要約 By Gemini
・この論文において解決したい課題は何?
MLLM(Multimodal Large Language Models)において、テキストと画像を統一的に扱えるようにし、特に画像生成の品質を向上させること。既存のMLLMは、画像の詳細な情報を保持することが苦手で、高品質な画像生成が難しい。
・先行研究だとどういう点が課題だった?
既存のMLLMは、画像情報を空間的なトークンとして扱っている。しかし、空間的なトークンは言語のような再帰的な構造を持たないため、LLMが学習しにくく、テキストとの連携がうまくいかない。また、既存の手法では、画像生成においてSDXLのような専門モデルに性能が及ばない。
・先行研究と比較したとき、提案手法の独自性や貢献は何?
Diffusion Timestep Token(DDT)という新しい画像トークンを提案。DDTは、拡散モデルの時間ステップを利用して、画像のノイズ除去過程で失われる情報を再帰的に補償する。これにより、LLMが言語のように画像を扱えるようになり、テキストと画像の連携が向上。結果として、画像生成、画像編集、視覚的理解のタスクで優れた性能を発揮。
・提案手法の手法を初心者でもわかるように詳細に説明して
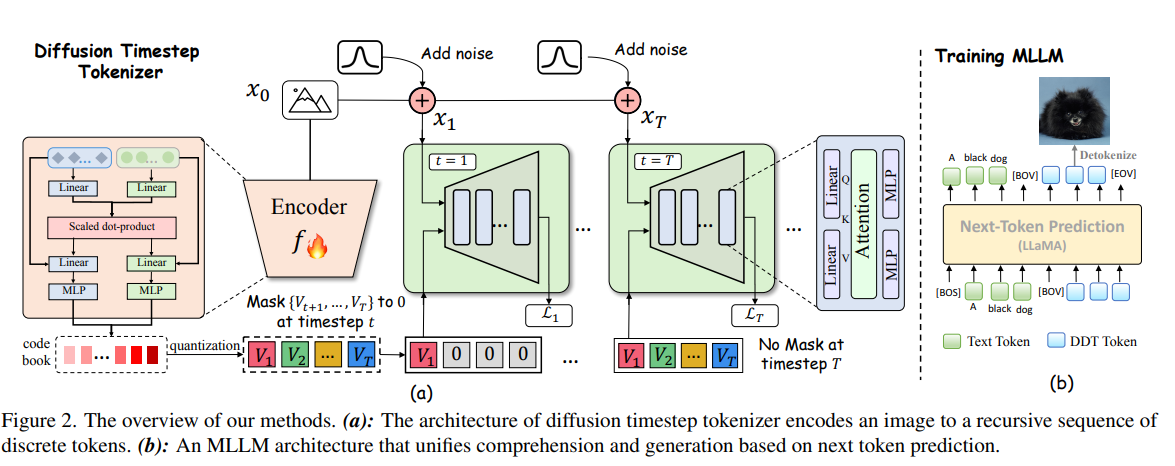
1. DDTトークナイザー: 画像にノイズを加えていく拡散過程を逆算し、ノイズ除去に必要な情報を段階的にトークン化。時間ステップが進むにつれて失われる情報を補うように、トークンを追加していく。
2. MLLMの学習: 画像をDDTトークンに変換し、テキストと組み合わせてLLMで学習。テキストと画像のトークンを交互に予測することで、両者の関係性を学習。
3. 画像生成: LLMが生成したDDTトークンを拡散モデルのデコーダーに入力し、ノイズから画像を再構築。
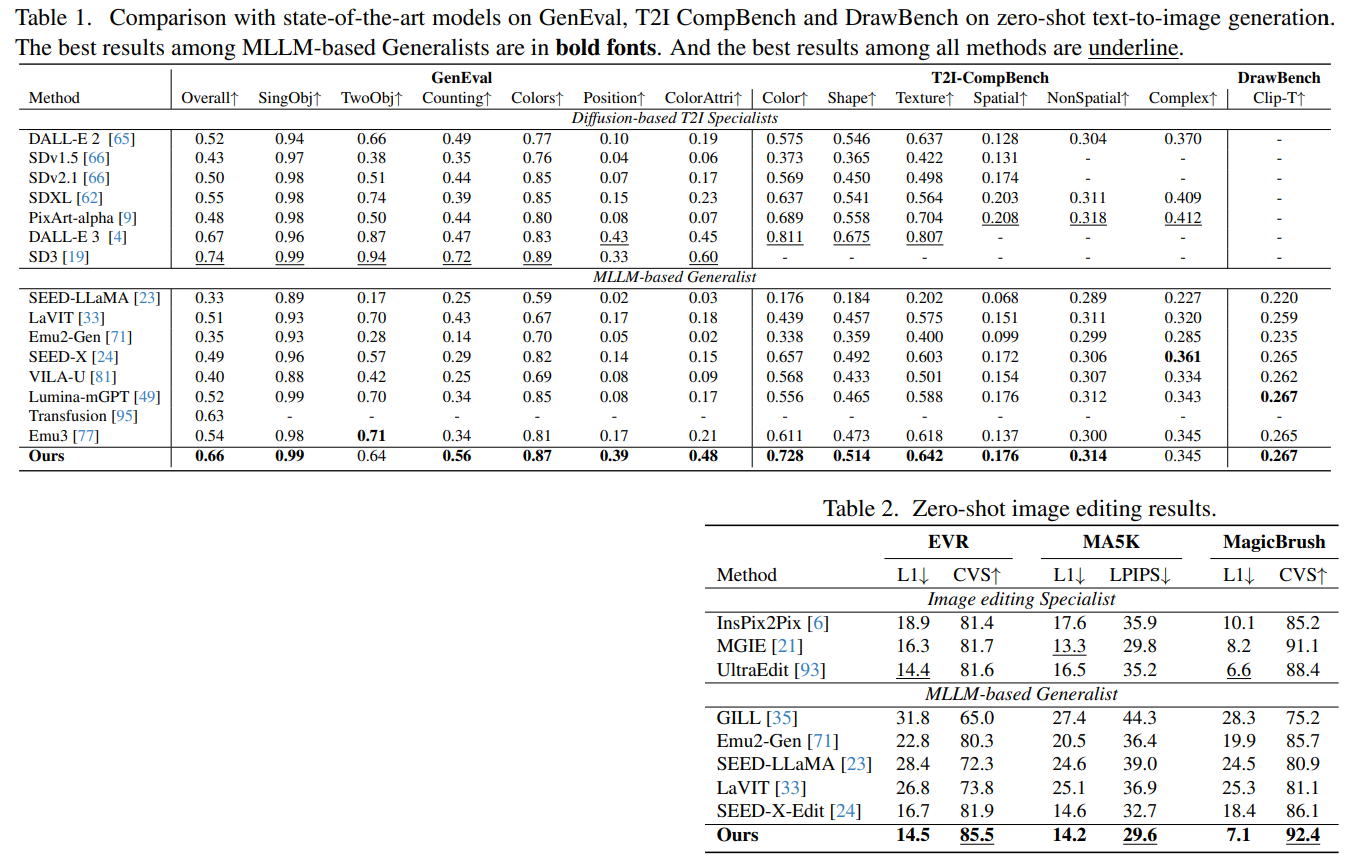
・提案手法の有効性をどのように定量・定性評価した?
* 定量評価: GenEval、T2I-CompBench、DrawBenchなどのベンチマークで、テキストからの画像生成性能を評価。EVR、MA5k、MagicBrushなどのデータセットで、画像編集性能を評価。VQAなどのデータセットで、視覚的理解性能を評価。
* 定性評価: 生成された画像の品質や、編集結果の自然さを視覚的に評価。DDTトークンが画像の属性を適切に表現しているかを分析。
・この論文における限界は?
DDTトークナイザーがImageNetデータセットのみで学習されているため、オープンなドメインの画像に対する再構築性能が低い。そのため、生成される画像の美的品質に改善の余地がある。
・次に読むべき論文は?
論文中で引用されている以下の論文を読むと、より理解が深まるでしょう。
- SDXL: 高解像度画像生成のための潜在拡散モデルに関する論文。
- VQGAN: ベクトル量子化を用いた画像生成モデルに関する論文。
- LLaVA: 視覚的な指示チューニングによる大規模言語モデルの改善に関する論文。
・論文中にコードが提示されていれば、それをリンク付きで示してください
論文中に直接コードは提示されていませんが、プロジェクトページへのリンクがあります。
- プロジェクトページ: https://DDT-LLaMA.github.io/
このプロジェクトページで、コードやモデルが公開される可能性があります。
もう少し深堀り
- テキストと画像を統一的に扱う目的
- マルチモーダルタスク(理解/生成)を単一の自動回帰フレームワークで実現
- 「この写真に写っている犬の種類は何か? [IMG]」のような理解に関するユーザーの質問や、「この写真 [IMG] をスケッチに変えて」のような生成に関する質問に対し、モデルは適切なテキストまたは画像トークンを順次予測
- 異なるモダリティ間のギャップ(多対一の理解 vs 一対一の生成)を埋める
- DDTトークンによる「視覚言語」を構築し、テキストと画像を翻訳可能にする
- MLLMがSDXLなど専門モデルに劣る理由
- 画像の空間的視覚トークンは言語の「再帰的構造」を持たない ⇒ LLMにとって習得困難
- 現行のトークナイザはImageNet 256×256のみで学習されており、解像度・データ量で専門モデルに及ばない(本研究の制約。EMUはInternVLDやLaionのような大規模データで訓練)
- 再帰的構造の導入に拡散モデルを使う理由
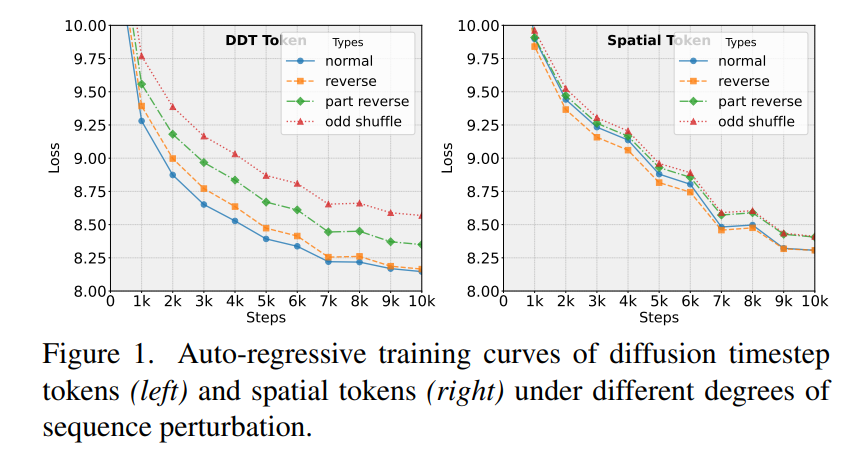
- 拡散の順方向プロセスで段階的に加わるノイズを、DDTトークンが再帰的に補償
- トークンが「詳細を積み重ねる」構造を持ち、人間言語と同様の順序依存性を獲得
- 従来のマルチ解像度手法との関係
- 画像ピラミッド等のマルチスケール表現には直接の比較・議論はない
- DDTトークンのコアは「言語的階層性」を持つ再帰性で、単なる解像度変化以上の意味的階層を実現
- デコーダー(生成側)アーキテクチャ
- U-Netではなく、トランスフォーマーベースのMMDiT(Multimodal Diffusion Transformer)を採用
- ノイズ画像とDDTトークン列を入力し、段階的にデノイズして元画像を再構築
- 画像トークン化とデコードの流れ
- 拡散の順方向でノイズを付加
- 各ステップで失われる属性を再帰的に補償するDDTトークンを生成
- トークン列とノイズ画像をデコーダーに与え、詳細から全体へ段階的に復元
- DDTトークナイザーの学習要件
- 専用のエンコーダー、量子化器、MMDiTデコーダーを含む独立学習プロセス
- ImageNet 256×256を用い、再構築損失でエンドツーエンド訓練
- 約32 GPU×1週間のリソースでトレーニング

Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー