
論文まとめ:SOLAR 10.7B: Scaling Large Language Models with Simple yet Effective Depth Up-Scaling


- タイトル:SOLAR 10.7B: Scaling Large Language Models with Simple yet Effective Depth Up-Scaling
- 著者:Dahyun Kim, Chanjun Park, Sanghoon Kim, Wonsung Lee, Wonho Song, Yunsu Kim, Hyeonwoo Kim, Yungi Kim, Hyeonju Lee, Jihoo Kim, Changbae Ahn, Seonghoon Yang, Sukyung Lee, Hyunbyung Park, Gyoungjin Gim, Mikyoung Cha, Hwalsuk Lee, Sunghun Kim(Upstage AI)
- カンファ:NAACL 2024
- 論文URL:https://arxiv.org/abs/2312.15166
- モデル:https://huggingface.co/upstage/SOLAR-10.7B-v1.0
目次
ざっくりいうと
- 大規模言語モデルを効率的にスケールアップするために、深さを増やすシンプルな手法「Depth Up-Scaling (DUS)」を提案。
- ベースモデルの層を複製・削除して連結し、追加の事前学習で性能を回復させる2段階の手法で、複雑なフレームワークの変更を不要に。
- 提案手法で開発した「SOLAR 10.7B」は、既存モデルを上回る性能を示し、Hugging Faceのベンチマークで高評価を獲得。
論文要約 By Gemini 1.5
この論文の内容を60秒で読めるように、以下の問いに一問一答で答えます。
- この論文において解決したい課題は何?
大規模言語モデル(LLM)を効率的にスケールアップし、同時にトレーニングや推論フレームワークの変更を最小限に抑えること。
- 先行研究だとどういう点が課題だった?
Mixture-of-Experts (MoE)のような既存のLLMスケールアップ手法は、トレーニングや推論フレームワークに複雑な変更が必要で、広く適用しにくい点が課題だった。
- 先行研究と比較したとき、提案手法の独自性や貢献は何?
Depth Up-Scaling (DUS)と呼ばれるシンプルな手法を提案。MoEのような複雑な変更を必要とせず、既存のフレームワークと容易に統合できる。また、SOLAR 10.7Bとその命令調整済みモデルを公開し、高い性能を実現。
- 提案手法の手法を初心者でもわかるように詳細に説明して
ベースモデルの層を複製し、複製したモデルと元のモデルからそれぞれ指定数(m)の層を削除した後、2つのモデルを連結することで層数を増やす「Depthwise Scaling」を行い、その後「Continued Pretraining」で追加学習を行うことで性能を回復させるという2段階の手法。
- 提案手法の有効性をどのように定量・定性評価した?
Hugging Face Open LLM Leaderboard で、ARC、HellaSwag、MMLU、TruthfulQA、Winogrande、GSM8Kの6つのタスクで評価し、既存のLLMと比較。命令追従能力の評価には、独自に作成した命令調整データセットとアライメント調整データセットを使用。
- この論文における限界は?
DUSにおけるハイパーパラメータ(m)の最適値探索が不十分。また、モデルのトレーニングと推論に必要な計算リソースが大きく、利用が制限される可能性がある。
- 次に読むべき論文は?
- Komatsuzaki et al. (2022): Sparse upcycling: Training mixture-of-experts from dense checkpoints. (先行研究であるMoEを用いたスケールアップ手法)
- Touvron et al. (2023): Llama 2: Open foundation and fine-tuned chat models. (比較対象のLLM)
- Jiang et al. (2023): Mistral 7b. (比較対象のLLM)
論文中に提示されているコードへのリンク:
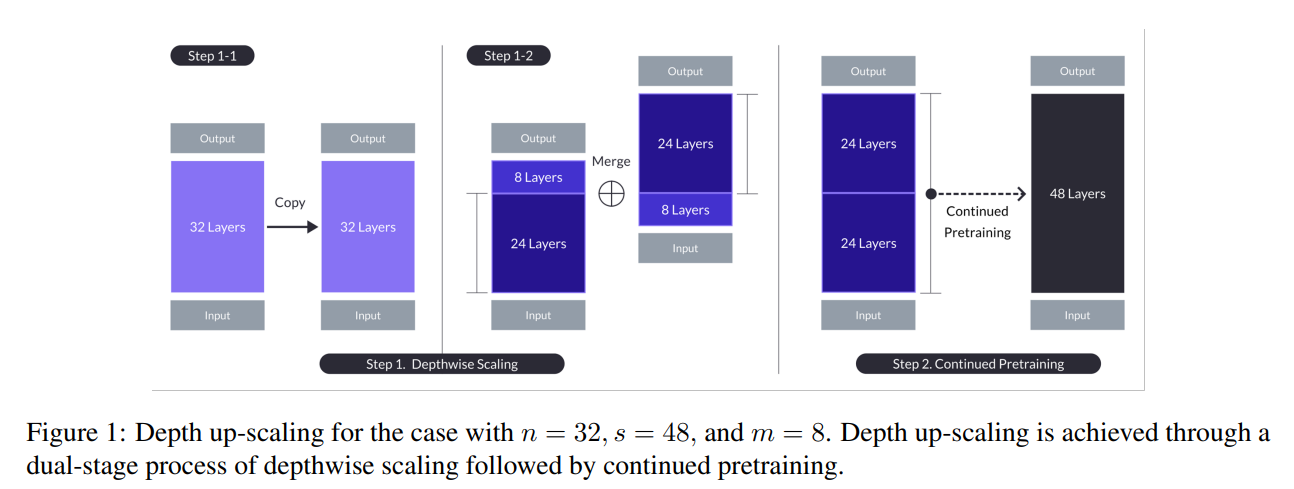
補足
追加の事前学習の意味
- がっちゃんこしたあとに追加の事前学習をする
- レイヤーのつなぎ目がレイヤー間の距離が大きい。普通につなげて追加事前学習したのでは、つなぎ目部分でレイヤー間の距離が大きすぎて回復できない
- 中間(先頭と末尾)を捨てて、つなぎ目の不一致を減らし、事前学習を継続しやすくする
- 32層のLLaMA2がベースで、Mixtral-8x7B-Instructを超える性能を出すのが一つの目標
訓練部分
- Instruct Tuning
- 数学のQAデータセットの合成
- GSM8Kなどのベンチマークデータセットの汚染を避けたい
- Mathデータセットからシード数学データを収集
- MetaMathと同様のプロセスを用いて、種となる数学データの質問と答えを言い換える
- 言い換えたQAデータセットを「Synth. Math-Instruct」という
- Alignment Tuning
- 人間や強力なAI(例:GPT4)の選好によりアライメントされるようにさらに微調整
- Synth Math-Instructデータは数学的能力を向上させるのに有効であることが実験的にわかっている
- したがって、言い換えられた質問に対する言い換えられた回答は、元の回答よりも良い回答であると推測される
- 「言い換えられた質問(プロンプト) – 言い換えられた回答(選択) – 元の回答(拒否)」となるDPOタプルを作成する
- これを「Synth. Math-Alignment」データセットという
結果
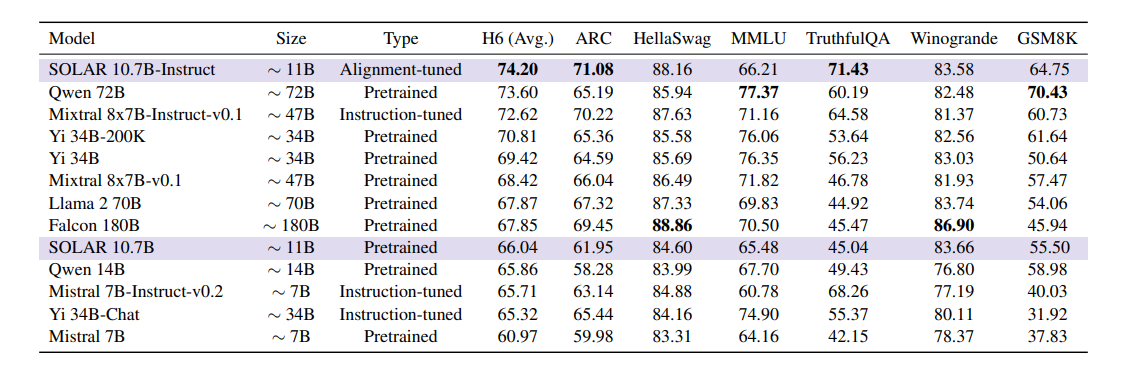
Depth Upscalingの効果はわかりやすく出ている
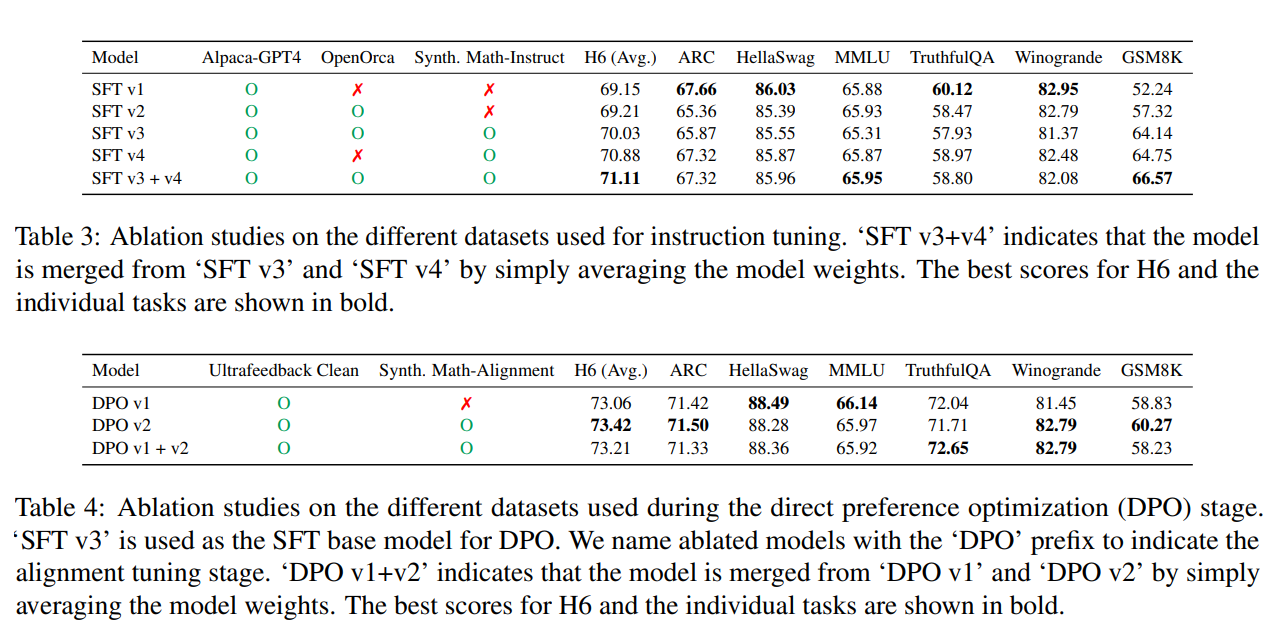
DPOはAlignment Tuning。DPO v1+v2はマージモデル
所感
- Depth Upscalingは面白い。これがLLM以外の基盤モデル一般で通じるのだろうか
- なぜこれがうまくいくのか、概念的な考証がなかった
- 別にモデルサイズを増やさなくても良くて、中でループバックして、その接続部分のAdapter層だけ追加するでもいけそうな気はする
- スケーリング則の観点から見たら違いが出る?
- DPOはほぼ性能差が誤差で、これが明確に効くという根拠がよくわからない。あんまりいい方法であるようには直感的には思えない
- GPTによる汚染がやや気になる
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー