
論文まとめ:Diffusion Self-Distillation for Zero-Shot Customized Image Generation


- タイトル:Diffusion Self-Distillation for Zero-Shot Customized Image Generation
- 著者:スタンフォード大の方々
- カンファ:CVPR 2025
- 論文URL:https://arxiv.org/abs/2411.18616
- プロジェクトページ:https://primecai.github.io/dsd/
- デモ:https://huggingface.co/spaces/primecai/diffusion-self-distillation
LLMとVLMを活用してアイデンティティが一致する画像ペアデータを自動生成し、拡散モデルをファインチューニングする新手法を提案。これにより、追加学習の負担を抑えつつ、多様なコンテキストで参照画像の特性を保ったカスタマイズ画像が生成可能となった。
目次
要約
この論文「Diffusion Self-Distillation for Zero-Shot Customized Image Generation」について、各質問に簡潔に答えます。
・この論文において解決したい課題は何?
テキストから画像を生成する拡散モデルにおいて、特定のキャラクターや物体のアイデンティティを維持したまま、多様なコンテキストで画像生成を行うゼロショットカスタマイズの実現。
・先行研究だとどういう点が課題だった?
先行研究のゼロショット手法は、顔のアイデンティティ保存に限定されていたり、カスタマイズ性が低かった。また、ファインチューニング手法は計算コストが高く、個々の参照画像ごとに学習が必要だった。
・先行研究と比較したとき、提案手法の独自性や貢献は何?
事前学習済みのテキスト-画像拡散モデル、LLM、VLMを用いて、自動的にアイデンティティ保存型の画像ペアデータセットを生成し、それを用いてモデルをファインチューニングする手法(Diffusion Self-Distillation)を提案。これにより、ゼロショットでの高品質なカスタマイズが可能になり、先行研究の課題を克服。
・提案手法の手法を初心者でもわかるように詳細に説明して
事前学習済みの拡散モデルに、同じキャラクター/物体で構成された複数枚の画像グリッドを生成するようにプロンプトを与え、多様な画像を生成。
LLMを用いて多様なプロンプトを自動生成し、生成画像のバリエーションを増加。
VLMを用いて生成された画像グリッドの中から、アイデンティティが維持されている画像ペアを選別し、高品質なデータセットを構築。
選別された画像ペアを用いて、提案する並列処理アーキテクチャを持つ拡散モデルをファインチューニング。入力画像は最初のフレームとして扱われ、2フレーム目の出力画像が編集結果となる。
ファインチューニング後、単一の参照画像とテキストプロンプトを入力することで、アイデンティティを維持したカスタマイズ画像を生成。
・提案手法の有効性をどのように定量・定性評価した?
DreamBench++データセットを用いて、GPT-4oによる評価指標(コンセプト保存、プロンプト追従)とユーザー調査による定量評価を実施。さらに、様々なカスタマイズ例を提示することで定性評価も行った。コピーペースト効果を抑制するためのバイアス除去評価も実施。
・この論文における限界は?
主にキャラクター、物体、シーンのリライティングといったアイデンティティ保存編集に焦点を当てている。動画生成への拡張や、ControlNetとの統合による更なる制御性の向上は今後の課題。
・次に読むべき論文は?
DreamBooth: https://arxiv.org/abs/2208.12242 (パーソナライズ画像生成の先行研究)
ControlNet: https://arxiv.org/abs/2302.05543 (拡散モデルへの追加制御手法)
IP-Adapter: https://arxiv.org/abs/2308.16455 (画像プロンプトを用いた先行研究)
DreamBench++: https://arxiv.org/abs/2310.17171 (パーソナライズ画像生成の評価用データセット)

補足
- ある画像をベースに、プロンプトベースで編集して拡張して画像生成するモデル
- 事前学習に工夫しましたというもの
- LoRAやDreamBooth:カスタマイズのための事前学習はするが、要素ごとに画像生成モデルを訓練するためコストが重い
- IP AdapterやInstant ID:訓練はいらなくなるが、所詮Attentionレベルの小細工なのでお一貫性やカスタマイズ性が低い
- カスタマイズに特化したファインチューニングをしました
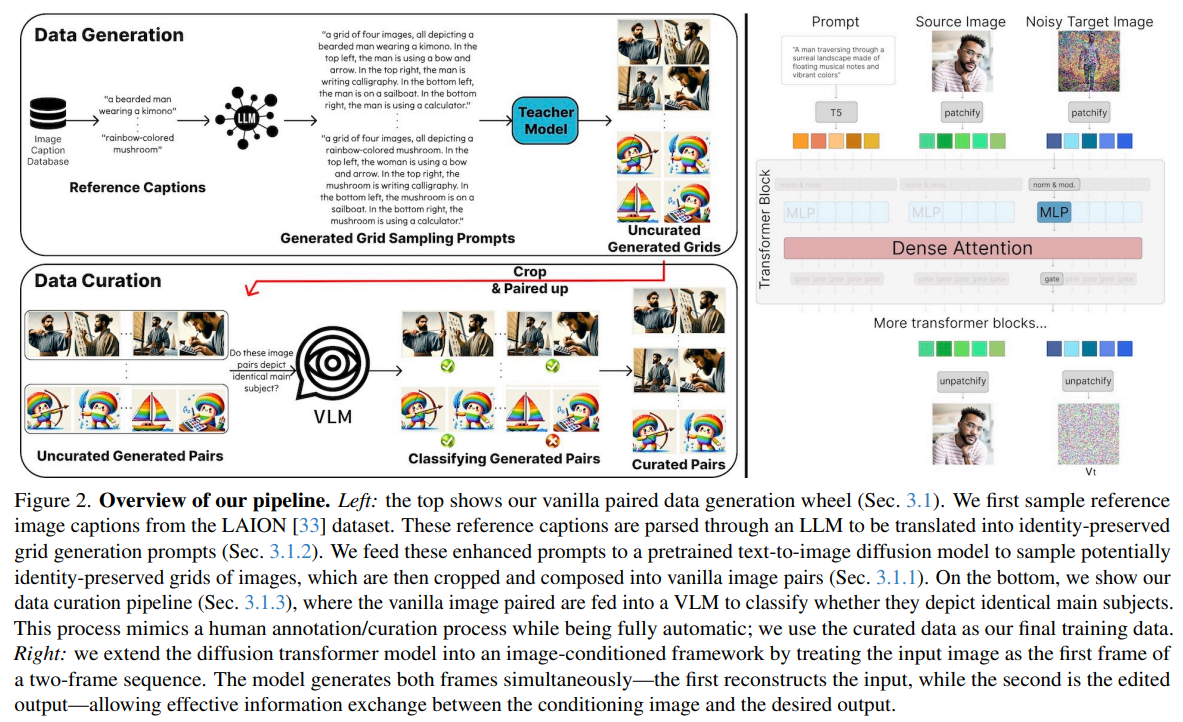
手法
- 教師モデルによるバニラデータ生成
- SD3やFluxのような最新鋭のText to Imageモデルを使ってグリッド生成。グリッド生成することで画像生成モデルそのものの同一性維持能力が出る
- プロンプト:“a grid of 4 images representing the same < object/character/scene/etc. >”, “an evenly separated 4 panels, depicting identical < object/character/scene/etc. >”
- LLMによるプロンプト生成
- そもそもLLMにプロンプト生成させると多様性が低い。ゼロショットだと、GPT-4oは車やロボットを好み反復的な出力になる
- LAIONデータセットの画像のキャプションを参照データとして使い、参照データを入れてLLMにプロンプト生成させる。一貫性のある複数画像生成のヒット率が大幅に上がる
- VLMでキュレーション
- CoTを使い、VLMでペア画像間に関連があるかを調べる
- 編集前・編集後の画像ペアができるので、これを自己蒸留のための学習データとする
- 画像生成部分
- 動画生成モデルからヒントを得て、2フレームの動画生成と考える。2フレーム目が編集後のほしい画像
- 1フレーム目はIDマッピング、2フレーム目は条件付き編集のターゲット
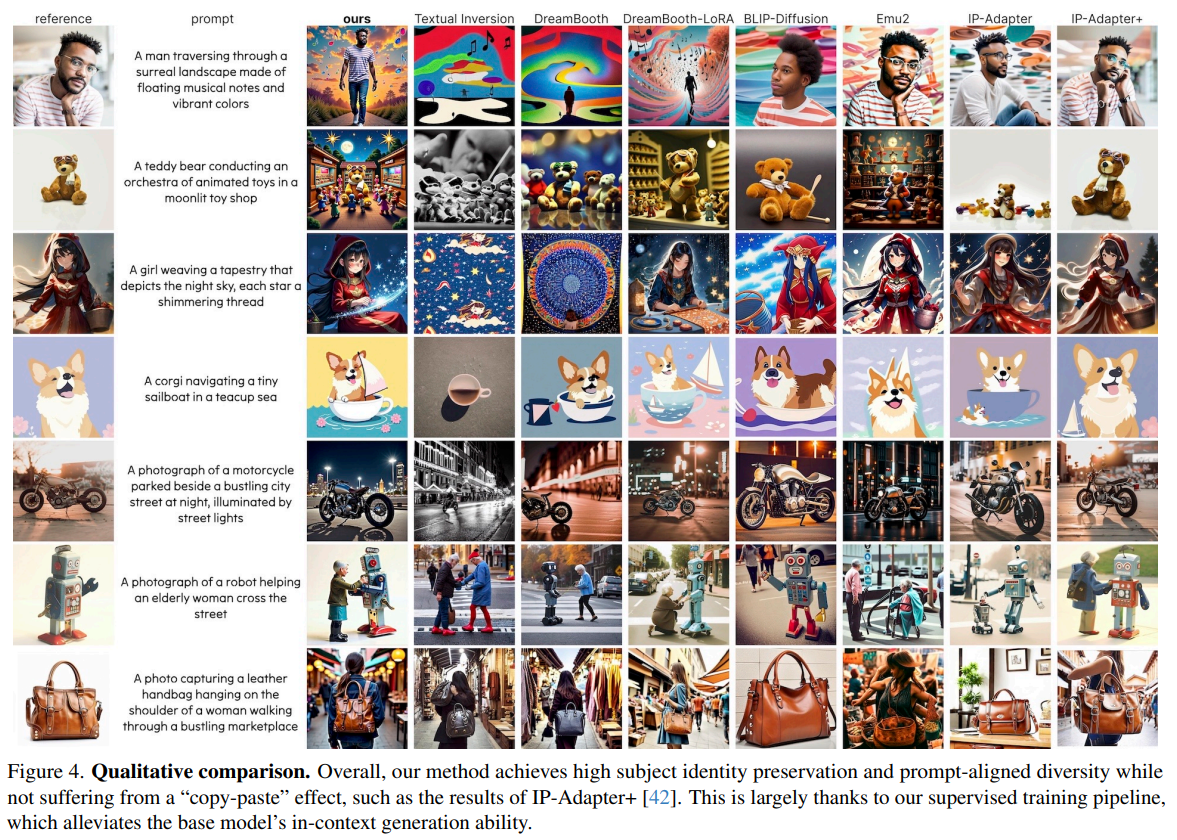

実験条件
- Flux 1.0 DevをStudent Teacherモデルとして使用
- プロンプト生成にはGPT-4o、キュレーションとキャプション付にはGemini 1.5を使用
- H100 80GBを88枚使い、ランク512のLoRAを学習
- データセット
- Flux 1.0 Devから生成された400kのペア画像
- 完全自動化されており、人手の介入は必要ない
- 評価
- GPTベースのLLM as judge、人間の評価の両方を使用(DreamBench++)
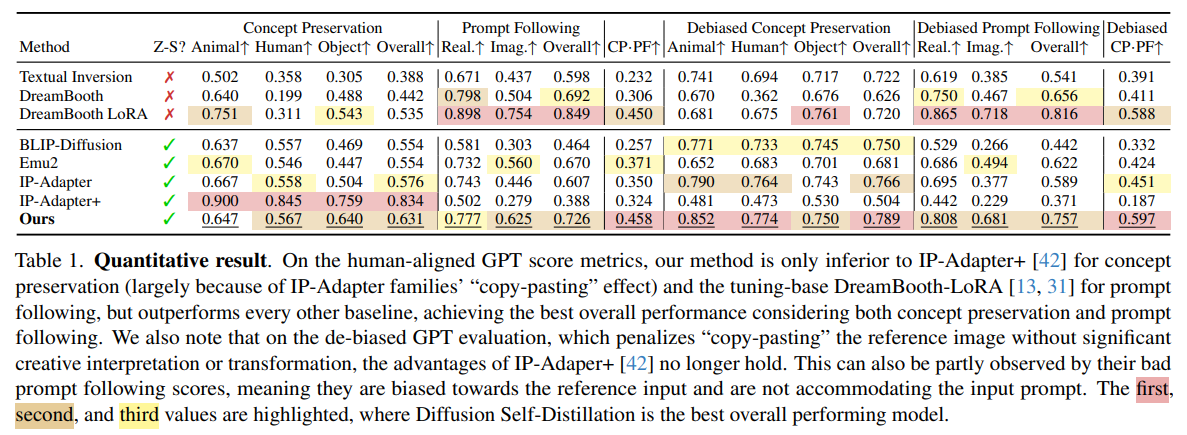
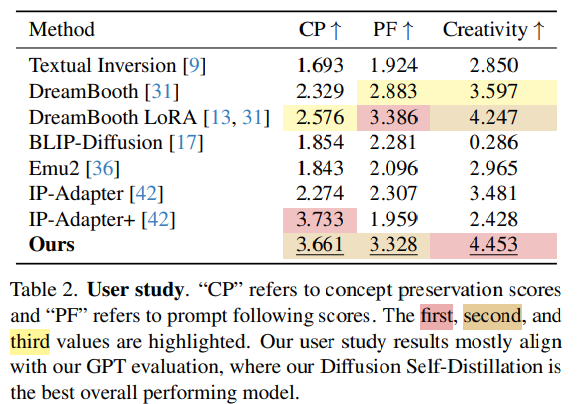
全体的に
- やってることはかなり面白いしなるほど感あるけど、GPTとGeminiを使ってるのはどうなんだ?感
- 自動生成されたデータまで公開してるのは面白い
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー